590
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享#include "cuda_runtime.h"
#include "device_launch_parameters.h"
#include <time.h>
#include <iostream>
#include <iomanip>
#include <stdio.h>
const int cnTheadPerBlock = 256;
const int cnElementSz = 33*1024;
bool initialize(float* pfHostA, float* pfHostB, float& fHostC);
__global__ void dot(float* pfDeviceA, float* pfDeviceB, float* pfPartC) {
__shared__ float fCache[cnTheadPerBlock];
int nIDx = threadIdx.x + blockIdx.x * blockDim.x;
int nCacheNo = threadIdx.x;
float fTemp = 0.0;
while (nIDx < cnElementSz) {
fTemp += pfDeviceA[nIDx] * pfDeviceB[nIDx];
nIDx += blockDim.x*gridDim.x;
}
fCache[nCacheNo] = fTemp;
__syncthreads();
int i = blockDim.x /2;
while (i!=0) {
if (nCacheNo < i)
fCache[nCacheNo] += fCache[nCacheNo + i];
__syncthreads();
i /= 2;
}
if (nCacheNo == 0)
pfPartC[blockIdx.x] = fCache[0];
}
int main()
{
float afHostA[cnElementSz], afHostB[cnElementSz], fHostC;
for (int n = 0; n < cnElementSz; n++) {
afHostA[n] = static_cast<float>(n);
afHostB[n] = static_cast<float>(2 * n);
}
clock_t tFormer1 = clock();
initialize(afHostA, afHostB, fHostC);
clock_t tPoster1 = clock();
double dT1 = static_cast<double>(tPoster1 - tFormer1) / CLOCKS_PER_SEC;
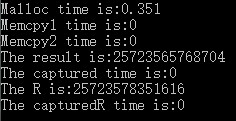
std::cout << "The result is:" << std::fixed << std::setprecision(0) << fHostC << std::endl;
std::cout << "The captured time is:" << dT1 << std::endl;
clock_t tFormer2 = clock();
float fTempR = 0.0;
for (int n = 0; n < cnElementSz; n++) {
fTempR += 2.0f*static_cast<float>(n)* static_cast<float>(n);
}
clock_t tPoster2 = clock();
double dT2 = static_cast<double>(tPoster2 - tFormer2) / CLOCKS_PER_SEC;
std::cout << "The R is:" << std::fixed << std::setprecision(0) << fTempR << std::endl;
std::cout << "The capturedR time is:" << dT2 << std::endl;
return 0;
}
bool initialize(float* pfHostA, float* pfHostB, float& fHostC) {
float* pfDeviceA, * pfDeviceB, *pfPartC, *pfHostC;
pfHostC = NULL;
pfHostC = (float*)(malloc((cnElementSz / cnTheadPerBlock) * sizeof(float)));
clock_t tMallocF = clock();
if (cudaSuccess != cudaMalloc(((void**)&pfDeviceA), cnElementSz*sizeof(float)) ||
cudaSuccess != cudaMalloc(((void**)&pfDeviceB), cnElementSz*sizeof(float)) ||
cudaSuccess != cudaMalloc(((void**)&pfPartC), (cnElementSz/cnTheadPerBlock)*sizeof(float)) ) {
std::cerr << "cudaMalloc failed!" << std::endl;
return false;
}
clock_t tMallocP = clock();
double dTimeML = static_cast<double>(tMallocP - tMallocF)/CLOCKS_PER_SEC;
std::cout << "Malloc time is:" << dTimeML <<std::endl;
clock_t tMemcpyF1 = clock();
if (cudaSuccess != cudaMemcpy(pfDeviceA, pfHostA, cnElementSz * sizeof(float), cudaMemcpyHostToDevice) ||
cudaSuccess != cudaMemcpy(pfDeviceB, pfHostB, cnElementSz * sizeof(float), cudaMemcpyHostToDevice)) {
std::cerr << "cudaMemcpy failed!" << std::endl;
return false;
}
clock_t tMemcpyP1 = clock();
double dTimeMC1 = static_cast<double>(tMemcpyP1 - tMemcpyF1) / CLOCKS_PER_SEC;
std::cout << "Memcpy1 time is:" << dTimeMC1 << std::endl;
dot << <cnElementSz / cnTheadPerBlock, cnTheadPerBlock >> > (pfDeviceA, pfDeviceB, pfPartC);
clock_t tMemcpyF2 = clock();
if (cudaSuccess != cudaMemcpy(pfHostC, pfPartC, (cnElementSz / cnTheadPerBlock) * sizeof(float), cudaMemcpyDeviceToHost)) {
std::cerr << "cudaMemcpy failed!" << std::endl;
return false;
}
clock_t tMemcpyP2 = clock();
double dTimeMC2 = static_cast<double>(tMemcpyP2- tMemcpyF2) / CLOCKS_PER_SEC;
std::cout << "Memcpy2 time is:" << dTimeMC2 << std::endl;
fHostC = 0.0;
for (int n = 0; n < (cnElementSz / cnTheadPerBlock); n++) {
fHostC += pfHostC[n];
}
free(pfHostC);
cudaFree(pfDeviceA);
cudaFree(pfDeviceB);
cudaFree(pfPartC);
return true;
}