


234
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享2021年2月19日,出门问问联合西北工业大学音频语音与语言处理研究组推出面向产品和工业界的端到端语音识别开源工具 WeNet。WeNet 自发布以来,因为其简洁性、易用性和产品优先 (Production First and Production Ready) 的定位,受到了广泛的关注、使用和好评。截止目前为止,该项目在 Github 上有八百多star,有三个微信交流群超过千人活跃讨论,官方公众号“WeNet步行街”也有上千粉丝关注。
WeNet 项目 Github 主页:https://github.com/wenet-e2e/wenet
自首次发布以来,WeNet 也在不断的进步和完善。今天,我们正式发布 WeNet 1.0,WeNet 的第一个正式版本,总结 WeNet 自首次发布以来的重大更新,并展望 WeNet 的未来发展。
西北工业大学计算机学院教授、博士生导师、音频语音与语言处理研究组(ASLP@NPU)负责人谢磊表示:和其他语音识别相关工具包“大而全”的理念不同,正如 WeNet 名字中所表达的,WeNet 是面向大众都可以快速学习和在实际应用部署的工具包,具有鲜明的“小而精”的特色。WeNet 基于SOTA 的深度学习模型架构,具备数据准备、模型训练、工程部署整条易用的链路,同时融合了面向实际应用的各种特性,比如面向领域适配增加了语言模型的支持,又如时间戳和端点检测等功能的支持等。据我了解,很多高校都已经使用 WeNet 作为学习和科研工具,同时众多公司也在实际产品中应用 WeNet 作为重要部署工具。
如果用简单的几个词总结 WeNet 1.0 的特性的话,我们想到了“更快、更高、更强、更有生产力”。
更快:WeNet 1.0 中支持了多机多卡的分布式训练,训练更快;解码时也可以做历史chunk限制,解码更快。
更高:更高的识别率。WeNet 1.0 中升级 U2 算法到 U2++,识别率更高,并支持了语言模型,进一步 提高识别率。
更强:更强大的功能。WeNet 完善了标准数据集的支持;支持了时间戳、n-best、对齐、endpoint 等识别强相关任务;并建立了系统的文档。
更有生产力:在 x86 server 和 on-device android的基础上,结合语言模型支持、gRPC 支持、n-best、时间戳、endpoint 等的支持,WeNet 1.0 已经构建了一个完整完善的语音识别所需的方方面面的能力,也有工业界应用的典型案例。
以下是 WeNet 1.0 的 具体更新的总结和介绍,我们分为模型及其训练、数据集支持、生产力三方面介绍。文末也会讨论一下关于 WeNet 未来的一些发展思路。
模型及其训练
模型层面的第一个重大更新是 U2++ 双向建模,其结构如下图所示。核心思想是同时利用标注序列的前向和后向信息训练模型,在解码时同时利用双向的 decoder 进行 re-score。实验证明,该方法在各个数据集上都能取得一致性的5%~8%的相对错误率的下降。
更多细节请见:WeNet更新:U2++ 双向 re-score
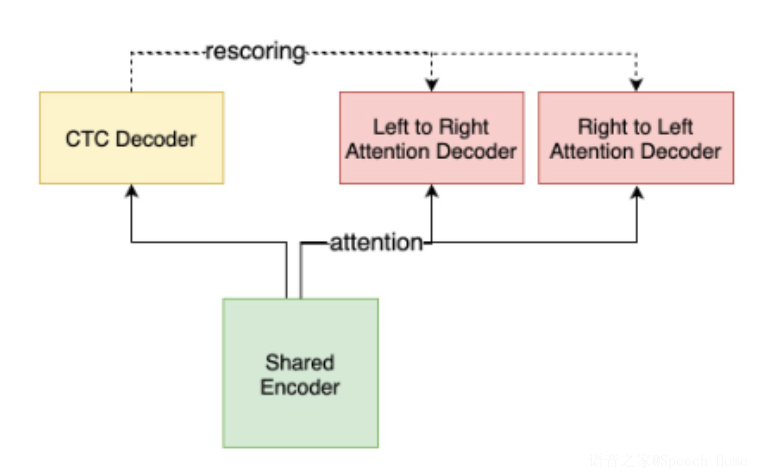
模型层面的第二个支持是动态left chunk训练,经过该方式训练的模型,可以在解码时限定仅能看到有限个历史的chunk,以减少解码时的内存和计算量。
在训练上,WeNet 1.0 支持了分布式的多机多卡训练,在保证模型精度的条件下,做到了几乎无损的线性加速。
详情请见:WeNet更新:支持多机并行训练
数据集支持
WeNet 1.0 中支持了5个标准数据集,并开放了预训练的模型,具体如下表格所示:
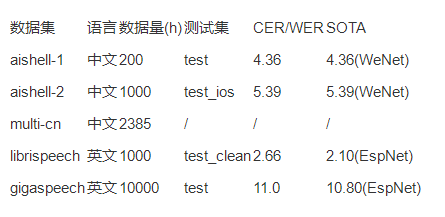
其中SOTA表示当前业界论文或者工具包在该数据集上给出的最佳识别结果。可以看到,WeNet 1.0 在以上标准数据集上均能取得业界最好或者相近的识别率,进一步说明了其算法和工具的可靠性。
其中,multi-cn是所有中文开源数据的合集,依靠该数据集2385小时的数据和所提供的预训练模型,开发者可以接近零成本搭建语音识别服务,并且在安静标准的语音下能给出比较准确的识别率。
关于该数据集的具体组成和更新详见:WeNet 更新:支持中文开源1385h数据集并开放预训练模型
关于 aishell-2 数据集的更新详见:WeNet更新:支持AISHELL-2数据集并开放预训练模型
gigaspeech 是陈果果等最近开放的超大规模的1万小时英文数据集,详见:https://arxiv.org/pdf/2106.06909.pdf
生产力
我们一直强调,WeNet 的核心设计思想和设计理念是产品第一,产品优先,这也是 WeNet 1.0 中更新内容最多、功能最多,同时也是最重要的更新。
语言模型在语音识别中发挥着重要功能,能否快速的进行领域内语言模型的更新和迭代,对产品至关重要。WeNet 1.0 中支持了语言模型,开发者可以根据自己的实际场景和需求选择是否使用语言模型,如下图所示。
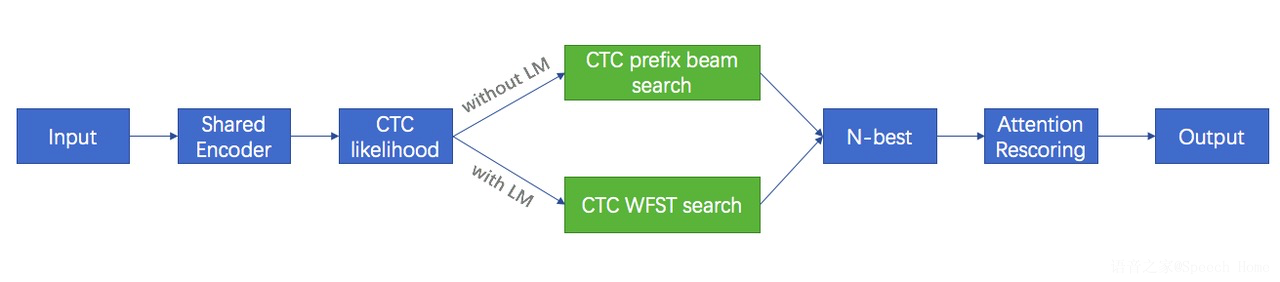
关于语言模型的更新详见:WeNet 更新:支持语言模型
除了语言模型之外,时间戳、n-best 和 endpoint 等特性也在语音识别系统中有着特定的应用,如通过 endpoint 自动检测支持实时长语音的识别。
关于时间戳、n-best 和 endpoint 的更新详见:
在云侧 server 语音识别中,喜马拉雅的语音团队贡献了更适合企业使用和部署的 gRPC 方案,详见:喜马拉雅:基于 WeNet 和 gRPC 的语音识别微服务架构的设计和应用
此外,关于云侧 server 和 端侧的 android,WeNet 1.0 也进一步完善了功能,增强了稳定性。
关于未来
相信很多朋友会很关注 WeNet 下一步的发展方向和功能,我们也在思考这些问题,但目前还没有特别清晰的答案。自深度学习在语音识别中应用以来,我们看到,每过一两年,语音识别的神经网络的架构都在变,目前的语音识别仍有赖于海量的数据,这离语音识别的终极形态还有很长很远的路要走,也就离语音识别的终极解决方案和终极工具很远。
但我们也在思考,在这些变化中,WeNet 能做什么,应该怎么去发展。我想借用雷军的互联网七字“专注、极致、口碑、快”来说明 WeNet 以后发展的一些思路。
专注:WeNet 会专注在语音识别这个任务上。和其他工具如 EspNet 和 SpeechBrain 等支持语音任务类型更多的工具不同,WeNet 追求小而美,小而精。若确有非常好的其他语音任务可以拓展, WeNet 会单独组建其他项目来支持。
极致:WeNet 会一如既往的坚持 “Production First and Production Ready”,追求极致的产品力,同时也追求项目和工程上的极致。
口碑:这里其实想更多的表达有效、高效的沟通和反馈所形成的闭环、正能量和口碑。目前 WeNet 通过交流群、公众号、Github Issue 等众多的渠道进行沟通和讨论,覆盖很全面,时效性很高,社区也很活跃。未来也会进一步强化高效的沟通、更多的渠道和更完善的文档。
快:天下武功,唯快不破。正如上面所说,每过一两年,语音识别的神经网络架构、甚至语音识别的架构都在变。而 WeNet 会做的是,根据产品第一的原则甄选并快速跟进。
