


233
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享近年来,随着深度学习的快速发展,简单易用、性能稳定、开发高效的深度学习框架越来越被科研和工业界人员所需要。其中,TensorFlow和Pytorch则是目前深度学习的主流框架。在语音领域,基于C++开发的Kaldi工具因集成了语音相关的大量算法,成为了语音领域的主流开发工具。但是,Kaldi对神经网络的支持有限,形式不够灵活,很难满足目前深度学习研究的需求。因此,对于声纹识别任务,不少研究人员开始使用其他深度学习框架代替Kaldi进行神经网络的开发与训练。
为了方便进行声纹识别相关的研究,厦门大学智能语音实验室(XMUSPEECH)团队经过近两年的开发,基于Kaldi和PyTorch推出了一套高效、易于开发扩展的声纹识别开源工具—ASV-Subtools。目前,该工具已在GitHub上发布。关于该工具的介绍论文(ASV-Subtools: Open Source Toolkit for Automatic Speaker Verification),已被语音顶会ICASSP2021录用。
文:童福川 赵淼
实验室网址:http://speech.xmu.edu.cn
工具介绍
ASV-Subtools充分结合了Kaldi 在语音信号和后端处理的高效性以及PyTorch 开发和训练神经网络的便捷灵活性。除了集成Kaldi本身提供的脚本外,该工具还基于Kaldi封装了很多实用、高效的脚本,其中包括数据集处理、数据扩增、特征提取、静音消除、Kaldi模型训练、x-vector加速提取、后端打分和指标计算等。此外,基于PyTorch的神经网络训练框架,该工具还提供了大量高层框架和神经网络训练相关的脚本,这也是ASV-Subtools的核心内容。这些脚本不仅可替代Kaldi的模型训练,而且其输入输出数据流与Kaldi完全兼容,可方便开发者灵活配置。
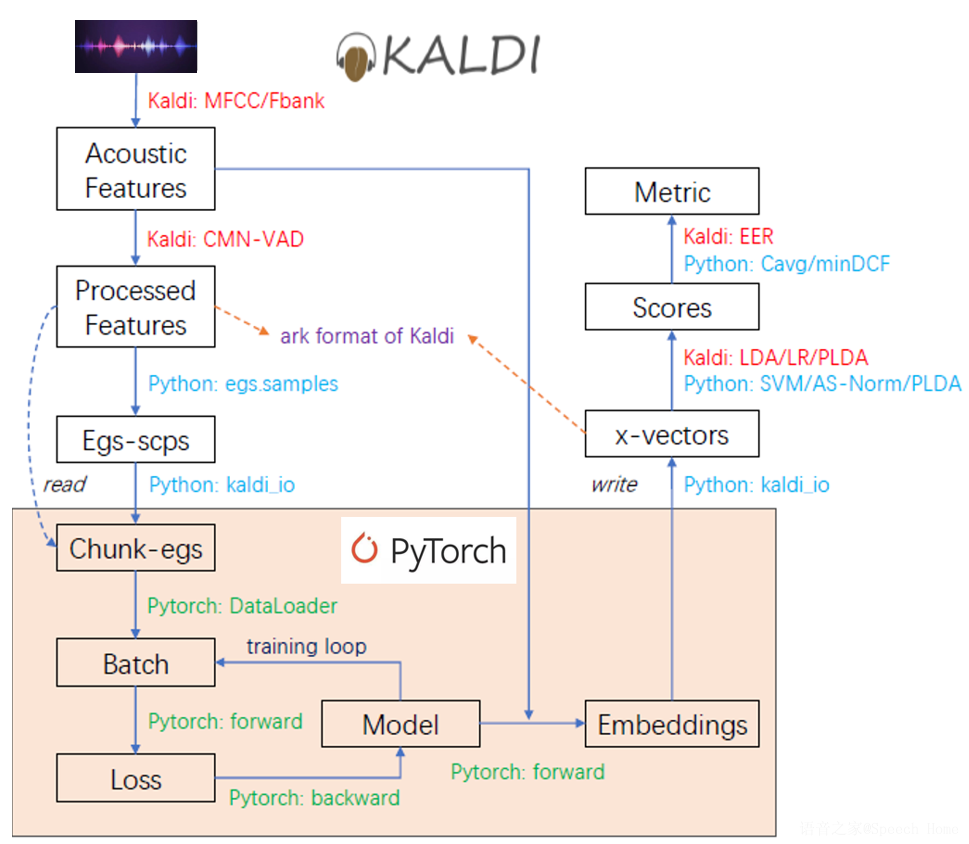
图1 ASV-Subtools中的数据处理流程
图1显示了ASV-Subtools中的数据处理流程。首先,一段语音由Kaldi提取声学特征(如MFCC,Fbank),并进行倒谱均值归一化和静音消除(CMN-VAD)后,存贮为Kaldi支持的ark格式文件(egs)。然后,ASV-Subtools通过对每条样本进行切片采样,组成等长度的数据块(chunk-egs),读入Pytorch进行网络训练。值得一提的是,除了常规的按序采样,ASV-Subtools还提供了说话人均衡采样来解决说话人不均衡问题。网络训练完之后,ASV-Subtools将提取出来的x-vector 写为ark格式文件,利用Kaldi进行后端处理并进行相似度判别打分。其中,PyTorch与Kaldi的数据交流是通过kaldi_io接口实现的,如果开发人员使用其他工具提取语音特征,也可以简单地更换为其他接口送入网络进行训练。
前端训练框架
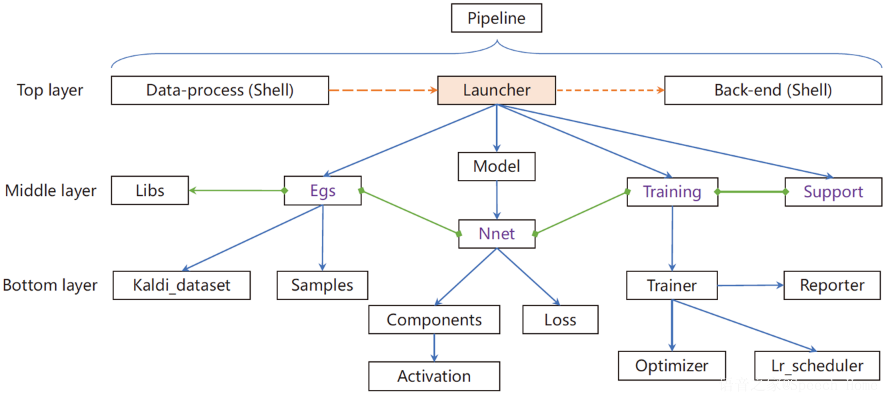
图2 ASV-Subtools框架结构
ASV-Subtools整体框架结构如图2所示。首先,最上层为训练流程,包含数据预处理(Data-process)、训练启动器(Launcher)和后端(Back-end)三个部分。框架中层主要是训练相关的高层组件,均包含在训练框架的核心库libs中,如样本(egs)、模型(model)、训练(training)和额外支持工具(support)。其中,ASV-Subtools提供了大量模型组件(nnet),方便开发者进行网络配置,当然,用户也可直接选择使用PyTorch提供的原生组件进行构建。最后,框架的底层为基于Python实现的各个基本对象,如对应到Kaldi映射目录的Kaldi_dataset,采样方法samples,模型基本组件components、activation和loss,训练有关的训练流程trainer,训练进度显示reporter,优化器以及学习率综合配置等。
后端优化
考虑到数据集的规模往往较为庞大,该工具对所有数据集处理脚本均进行了速度优化,如代码上的时间复杂度优化或使用多进程进行提速。此外,由于后端处理有很多可能的复杂组合,用于后端打分的训练集、注册集和测试集之间也有较多种处理方法,为了用户灵活配置,ASV-Subtools中实现了一个高效的打分脚本(scoreSet.sh):当给定数据处理顺序,该脚本通过图的深度遍历方法自动将整个打分过程连接起来。具体如图3所示,该脚本围绕注册集、测试集和打分三条线进行搜索,并自动将当前处理的输出送入到下一个处理中,并最终完成打分。这极大地方便了用户进行后端调试,无需每次重写代码。
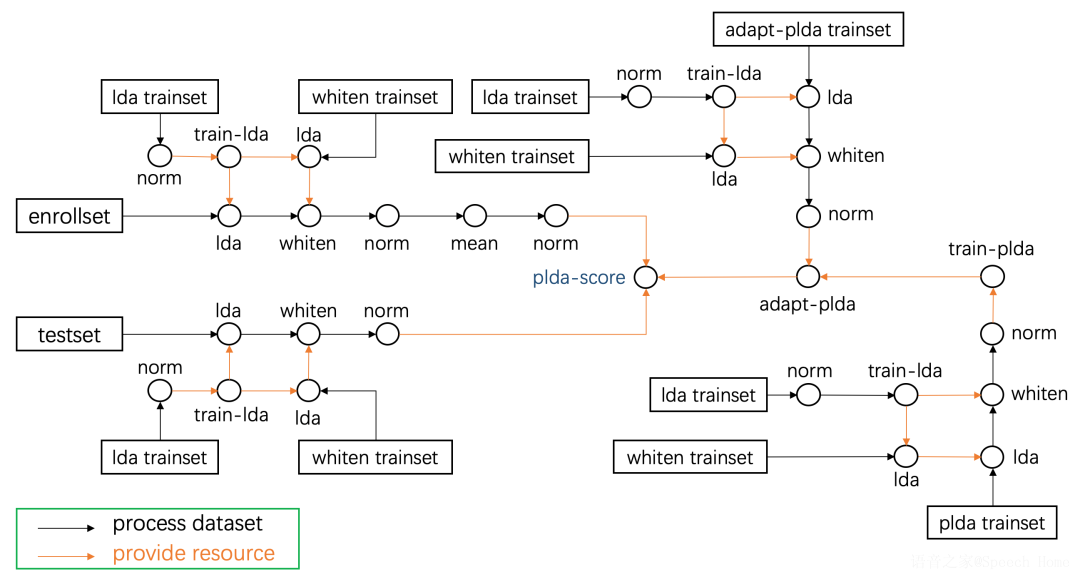
图3 后端打分集脚本原理示意图
四大特性
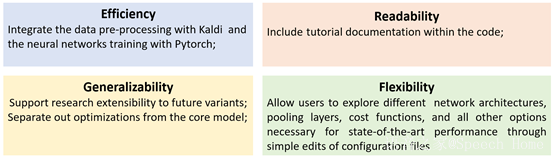
ASV-Subtools的设计理念在于代码高度复用的同时保持模块分化和开发自由。因此,体现出以下四个特点:
高效性:集成Kaldi和PyTorch各自的优点,实现完整的深度声纹识别系统;
可读性:代码中包括了注释说明和教程文档,增加了代码可读性,方便用户轻松上手;
通用性:将核心模块分离出来,支持扩展到新的模型。最新架构,如SE-block、ECAPA-TDNN,可以使用Torch内部的标准组件轻松扩展到ASV-Subtools中;
灵活性:用户只需通过简单地编辑配置文件,就能探索不同的网络架构、池化层、损失函数以及其他组件,实现最优异的性能。
基线结果
目前为止,ASV-Subtools已开发了众多声纹识别中常用的算法和网络架构,其中,使用一维卷积等价实现的标准x-vector网络,在同等训练集下训练同样的声纹识别模型,相对使用Kaldi工具,效果可整体提升10%~20%。该工具还改进了原始的SpecAugment数据扩增方法,实验表明,改进后的方法在VoxCeleb1数据集上能提升10%的性能;此外,ASV-Subtools还集成了多种PLDA自适应的技术,解决现实情况下域不匹配的问题,并提供了多种实验配置的运行示例,且在GitHub上展示了基于VoxCeleb数据集的基线结果。
如:VoxCeleb1上的测试结果:
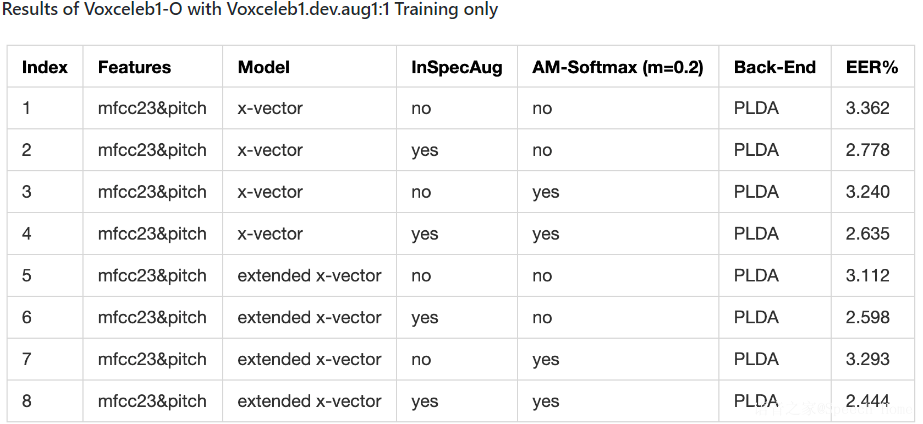
VoxCeleb2上ResNet34模型的测试结果:
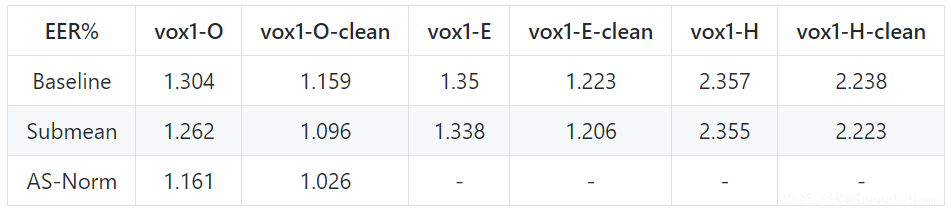
读者可以在GitHub上获得更多测试结果和详细的实验配置。大量实验结果表明ASV-Subtools显示出稳定性和可靠性。感兴趣的读者赶紧上手试试吧!
GitHub:https://github.com/Snowdar/asv-subtools
参考文献:
Fuchuan Tong, Miao Zhao, Jianfeng Zhou, Hao Lu, Zheng Li, Lin Li, Qingyang Hong, “ASV-Subtools: Open Source Toolkit for Automatic Speaker Verification”, ICASSP 2021.
