


11,102
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享在上一次呢,我们已经了解电子表格的一些特点,结构属性等,那么我们这次就来学习一下如何使用python读写excel文件以及对数据的处理。
昨天我们介绍了电子表格的特性以及几种python处理excel文件的库,他们都有各自的优缺点,有了这个铺垫,我们就可以上手动一动电子表格了,这次我们以xlrd/xlwt为例来动手实践一下
要做的事情
我们在上次留了任务中的第一条
设计并制作多个电子表格对应多个学科,每个学科一个独立表格文件,用于保存全班同学每人每个学科平时成绩评分、期中考得分、期末考得分、学科得分。其中学科得分计算方法:(期中+期末)/ 2 x 0.7+平时成绩x0.3
想象一下如果是一名辅导员,你这里现在有很多不同科目学生成绩的表格,你需要将它们汇总起来,只需要每个学生每个科目最后的总成绩,如果一条一条地去复制粘贴是不是效率极其低,而且还容易出错。
那么我们要做的就是用python将这些表格中的最终学科成绩提取出来,汇总到一个最终的表格里面。
同样的我们没有初始数据,如果要一条一条的写几十条数据,写好多表格,是不是也特别繁琐,那么我们是不是也可以用python生成我们要的示例表格呢。
我们今天要做的就是这两件事情。
那么我们就开始吧!
安装第三方库
首先我们需要在终端(windows命令行)安装需要的xlrd xlwt库
pip install xlrd
pip install xlwt
然后创建我们的项目,我们应该有一个代码文件 app.py 以及存放我们的电子表格的目录 excel文件夹,创建完之后是这个样子的。
第二件事情示例表格数据生成
首先我们分析一下我们都需要生成什么数据
我们初步先拟定生成四个表格,分别是
'大学物理', '高等数学', '大学英语', 'Python程序设计'
每个表格的内容都是相同的,存放着学生姓名,期中、期末成绩,平时成绩以及学科成绩。
那么我们需要生成的数据就是姓名和成绩了,
姓名用几个姓氏和几个常见的名字的汉字,从姓里面随机挑一个字,名字里面随机挑两个,这样就生成了姓名了
成绩就更简单了,生成0-100(百分制)之间的随机数就可以了
我们要生成多少个就循环多少次即可:
在代码中导入随机函数的库
import random
def generate_name():
first_name = '赵钱孙李周吴郑王冯陈褚卫蒋沈韩杨朱秦尤许何吕施张孔曹严华金魏陶姜'
last_name = '豫章故郡洪都新府星分翼轸地接衡庐襟三江而带五湖'
first_name = random.choice(first_name)
last_name = "".join(random.choice(last_name) for i in range(2))
return first_name + last_name
测试函数的话可以用print方法打印一下
print(generate_name())
def generate_grade():
return random.randint(0, 100)
生成表格写入数据
我们使用xlwt来创建和写入表格
import xlwt
wb = xlwt.Workbook()
sheet = wb.add_sheet(‘sheet1’)
向表格中写数据
sheet.write(‘row’,’col’,’data’)
期中row代表第几行,col代表第几列,data代表要写进表格的内容,这里要注意下标从0开始
那么我们给表格写入表头就可以这样写
sheet.write(0, 0, '姓名')
sheet.write(0, 1, '期中成绩')
sheet.write(0, 2, '期末成绩')
sheet.write(0, 3, '平时成绩')
sheet.write(0, 4, '学科得分')
那么从表中第二行开始我们随机生成姓名成绩写入进去,我们是不是就得到了想要的数据表,我们就随机写入50个吧
for index in range(1, 50):
mid = generate_grade() #期中成绩
fin = generate_grade() #期末成绩
usual = generate_grade() #平时成绩
subj = int((mid + fin) * 0.35 + usual * 0.3) #计算学科成绩并取整
sheet.write(index, 0, generate_name())
sheet.write(index, 1, mid)
sheet.write(index, 2, fin)
sheet.write(index, 3, usual)
sheet.write(index, 4, subj)
最后我们保存表格到本地即可
wb.save('高等数学.xls')
这样就生成了一个我们要的数据表了,那么是不是这样写四遍,保存的时候把文件名更改是不是就可以生成四个我们要的表格了?
是,但不完全是。可以,但也不完全可以。
如果我们需要的是一个班的各科学生成绩呢,这样生成的表格里面人名单对不上呀,而且这样写四遍多麻烦。
那么我们是不是可以把共同的代码部分提取出来,写一个函数,把我需要的数据当作参数传进去,这样就很灵活了, 来 直接上代码:
def generate_grade_excel(course, name_list):
wb = xlwt.Workbook()
sheet = wb.add_sheet('sheet1')
sheet.write(0, 0, '姓名')
sheet.write(0, 1, '期中成绩')
sheet.write(0, 2, '期末成绩')
sheet.write(0, 3, '平时成绩')
sheet.write(0, 4, '学科得分')
for index in range(1, len(name_list)+1):
mid = generate_grade()
fin = generate_grade()
usual = generate_grade()
subj = int((mid + fin) * 0.35 + usual * 0.3)
sheet.write(index, 0, name_list[index - 1])
sheet.write(index, 1, mid)
sheet.write(index, 2, fin)
sheet.write(index, 3, usual)
sheet.write(index, 4, subj)
wb.save(dir_path + '/' + course + '.xls')
我们把姓名提前生成50个,在调用函数的时候当作参数传入进去,还有我们的科目名也当作一个参数,是不是生成的四个表格就可以保持人名单相同,文件名不同了
注:dir_path是一个全局变量,在函数外部声明,值为dir_path=’./excel’指的是我们保存excel文件的这个文件夹
具体调用这里我们写了一个函数,在里面生成了一个里面有50个名字的list,以及遍历一个放着科目的list 将其当作参数传递给我们上面的创建表格的函数
def create_tables():
namelist = [generate_name() for i in range(50)]
for i in ['大学物理', '高等数学', '大学英语', 'Python程序设计']:
generate_grade_excel(i, namelist)
然后我们再调用create_tables函数就可以生成了
create_tables()
现在才是真正的可以了
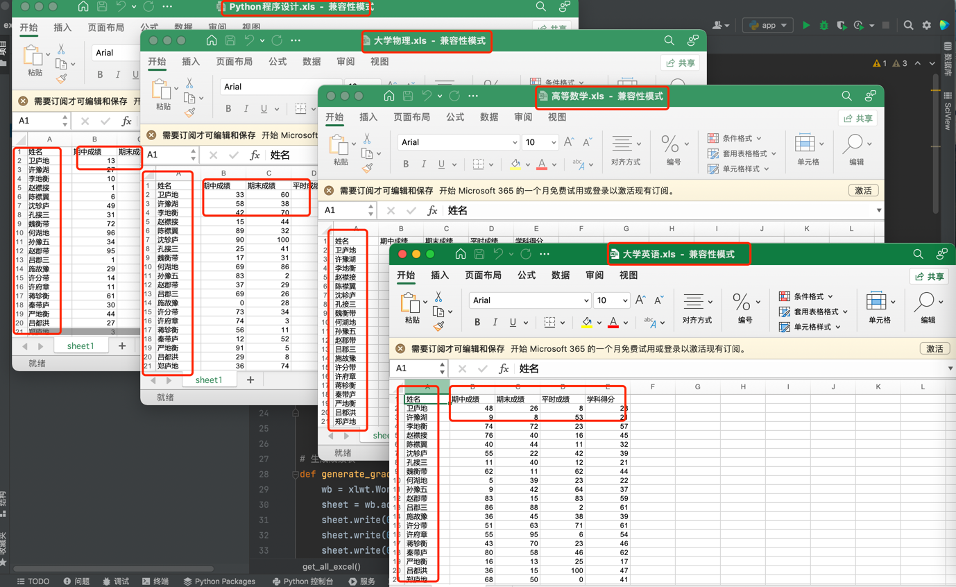
代码执行后的生成数据样子:

第一件事情
读取我们之前生成的表格,提取我们需要的学科成绩,将其汇总到一个表格
首先呢,我们需要在我们的excel文件夹中遍历查找所有的表格文件,虽然我们这里是写了四个表格文件,但是实际中我们可能用到的不止四个,比如你这学期课表排的满满的,期末的时候不就多了几张表格吗 - -!
我们之前也学习过python处理文件目录,这里就不过多赘述了,直接上代码。
import os
def get_all_excel(walk_path):
file_list = []
for root_dir, sub_dir, files in os.walk(r'' + walk_path):
for file in files:
if file.endswith(file_type):
file_name = os.path.join(root_dir, file)
file_list.append(file_name)
return file_list
注:file_type和之前的file_path是一样的,都是全局变量,file_type = ‘xsl’
调用该函数即可,返回值是这个文件夹下的表格文件路径的一个列表。
file_list = get_all_excel(file_path)
接下来呢我们去遍历file_list 读取文件就好了
flag
我们读取到的文件内容应该是要放到一个集合里面,集合里面键名是学生姓名,值则是一个存放学生成绩的列表列表,大概长这样:
{
‘张三’:[43, 23, 46, 67],
‘李四’:[43, 23, 46, 67],
‘王五’:[43, 23, 46, 67],
}
因为我们代码执行是顺序执行的,所以读取文件也是顺序读取的,只要我们按file_list的顺序去在表头写好科目类别即可
首先我们定义一个存放学生成绩的集合
stu = {}
因为我们的文件名是类似于‘../excel/高等数学.xsl’所以我们要在文件名中,把科目类别提取出来,后面要用到
cursor = [os.path.basename(file).replace('.xls', '') for file in file_list]
然后我们遍历file_list ,使用xlrd打开文件读取我们要的数据,写入到stu中
xlrd读文件的步骤是类似于xlwt的写文件:
打开文件
获取工作表sheet 这里我们默认的是sheet下标为0的,也就是第一个
通过sheet.cell(row, col).value读取单元格的值,row col代表行列
sheet.nrows是表格的行数
列数则为ncols
直接上代码:
for file in file_list:
wb = xlrd.open_workbook(file)
sheet = wb.sheet_by_index(0)
for index in range(1, sheet.nrows):
stu.setdefault(sheet.cell(index, 0).value, []).append(sheet.cell(index, 4).value)
我们在这里读取了每一行的第一列和最后一列,也就是我们之前创建表格的时候的姓名列和学科成绩列,放在了stu中
那么下面我们就可以用xlwt创建一个汇总表,然后写入表头,遍历stu,然后写入到汇总表中。
wb = xlwt.Workbook()
sheet = wb.add_sheet('sheet1')
sheet.write(0, 0, '姓名')
sheet.write(0, 1, cursor[0])
sheet.write(0, 2, cursor[1])
sheet.write(0, 3, cursor[2])
sheet.write(0, 4, cursor[3])
index = 1
for name, grades in stu.items():
sheet.write(index, 0, name)
sheet.write(index, 1, grades[0])
sheet.write(index, 2, grades[1])
sheet.write(index, 3, grades[2])
sheet.write(index, 4, grades[3])
index = index + 1
wb.save('汇总成绩.xls')
最后将文件汇总的所有代码封装到一起就大功告成了
def summary():
file_list = get_all_excel(dir_path)
stu = {}
cursor = [os.path.basename(file).replace('.xls', '') for file in file_list]
for file in file_list:
wb = xlrd.open_workbook(file)
sheet = wb.sheet_by_index(0)
for index in range(1, sheet.nrows):
stu.setdefault(sheet.cell(index, 0).value, []).append(sheet.cell(index, 4).value)
wb = xlwt.Workbook()
sheet = wb.add_sheet('sheet1')
sheet.write(0, 0, '姓名')
sheet.write(0, 1, cursor[0])
sheet.write(0, 2, cursor[1])
sheet.write(0, 3, cursor[2])
sheet.write(0, 4, cursor[3])
index = 1
for name, grades in stu.items():
sheet.write(index, 0, name)
sheet.write(index, 1, grades[0])
sheet.write(index, 2, grades[1])
sheet.write(index, 3, grades[2])
sheet.write(index, 4, grades[3])
index = index + 1
wb.save('汇总成绩.xls')
为了保证我们读取数据的干净,汇总成绩表不要与成绩表一起放在excel文件夹中
任务:
安装环境,将上面的代码运行起来,多执行几遍,观察生成的表格。将生成表格和汇总表格的函数分开运行,生成表格后改几个相同姓名的数据,然后再执行表格汇总的函数
在黄色flag标记处的程序是有缺陷的,
python中的字典有一个特性是key值唯一,如果key值不唯一时,后面写入的值会覆盖掉前面的值。
比如
stu = {‘zhang’: 60}
stu[‘zhang’] = 30
stu[‘zhang’] = 20
那么最后字典stu中key为zhang的值就是20
如果将学生姓名作为key值,学生姓名有重名情况,那么本程序就会发生一些错误,
请同学们完善改造本程序。比如在生成表格时,多生成一个学号的列,汇总时也以学号为依据。

Day7练习作业:
详细阅读学习任务,完成任务的执行,并完善改造程序
作业提交
你可以这样做(任选其一):
1.将实验过程中的操作步骤、遇到的问题、你的思考和想法整理成文字帖提交
2.录一个操作过程的视频放在帖子中提交
3.把你完成操作的代码结果拍照,照片放在帖子中提交
提交作业步骤:
1.进入 Python 全栈技术社区
2.点击右侧 “发帖子”,发布练习作业的内容,频道选择【7天学习】(标题格式:7天学习—dayX—标题)
3.进入Day7学习任务帖,点击“提交任务”按钮
4.填入发布作业的帖子链接后,确定提交
作业提交截止时间:
2021/9/26 19:00



