


11,999
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享目录
pip install pandas
pip install xlrd 只能操作xls文件
pip install OpenpyXL
pip install xlwings 操作xlsx文件
文件信息
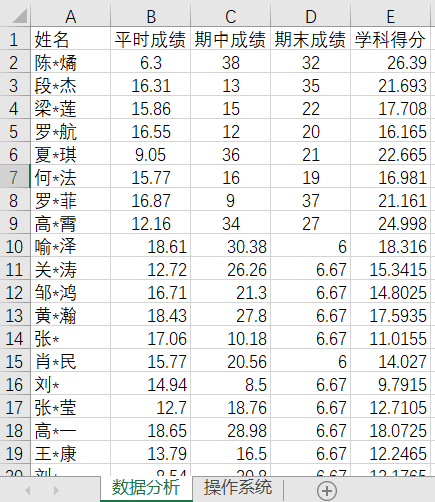
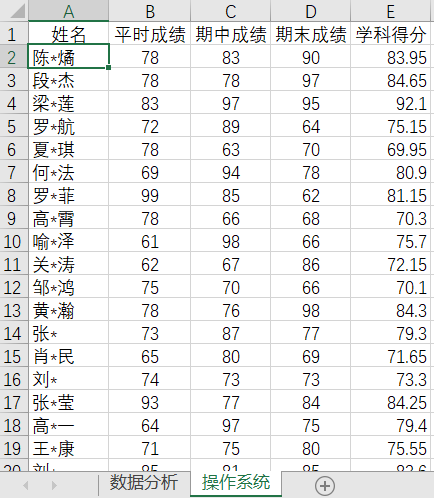
import pandas as pd
# 1:读取指定行
# 读取指定的单行,数据会存在列表里面
# 这个会直接默认读取到这个Excel的第一个表单
df = pd.read_excel('测试.xlsx')
# 0表示第一行 这里读取数据并不包含表头,要注意哦!
data = df.loc[0].values
print("读取指定行的数据:\n{0}".format(data))
# 读取指定的多行,数据会存在嵌套的列表里面
# 读取指定多行的话,就要在loc[]里面嵌套列表指定行数
data = df.loc[[1,2]].values
print("读取指定行的数据:\n{0}".format(data))
# 读取指定的行列
# 读取第一行第二列的值,这里不需要嵌套列表
data = df.iloc[1,2]
print("读取指定行的数据:\n{0}".format(data))
# 读取指定的多行多列值
# 读取第一行第二行的title以及data列的值,这里需要嵌套列表
data = df.loc[[1,2],['title','data']].values
print("读取指定行的数据:\n{0}".format(data))
# 获取所有行的指定列
# 读所有行的title以及data列的值,这里需要嵌套列表
data=df.loc[:,['title','data']].values
print("读取指定行的数据:\n{0}".format(data))
# 获取行号并打印输出
print("输出行号列表",df.index.values)
# 获取列名并打印输出
print("输出列标题",df.columns.values)
# 获取指定行数的值
# 这个方法类似于head()方法以及df.values方法
print("输出值",df.sample(3).values)
# 获取指定列的值
print("输出值\n",df['data'].values)
运行结果
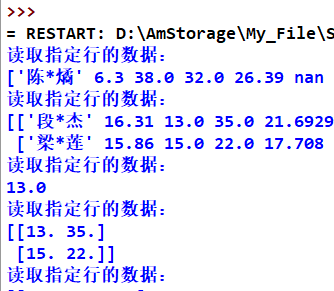
附上关于pands.read_excel函数的具体用法 https://blog.csdn.net/leenuxcore/article/details/106407522
pandas的另外一些函数 https://blog.csdn.net/weixin_38546295/article/details/83537558
xlrd只能操作xls文件
import xlwings as xw
filename = "D:/AmStorage/My_File/SCDN_test/file/grade.xlsx"
# 建立链接
app = xw.App(visible=False,add_book=False)
app.dispaly_alerts = False
app.screen_updating = False
# 打开工作薄
wb = app.books.open(filename)
# 获取两个工作表
sht0 = wb.sheets[0]
sht1 = wb.sheets[1]
# 读取工作表1里面的数据,单个读取
sht1.range('A1').value
# 多个读取
sht1.range('A2:A4').value
# 多个读取
sht1.range(1,2).value
# 获取工作表的行列数
info = sht1.used_range
nrows = info.last_cell.row
ncols = info.last_cell.column
# 加上 option 读取二维的数据
# allData = sht.range('a1:e24').options(ndim=2).value
# 和上面读取的内容一样
allData = sht1.range((1,1),(nrows,ncols)).options(ndim=2).value
# 输出数据
for dt in allData:
print(dt)
# 关闭文件
wb.close()
运行结果
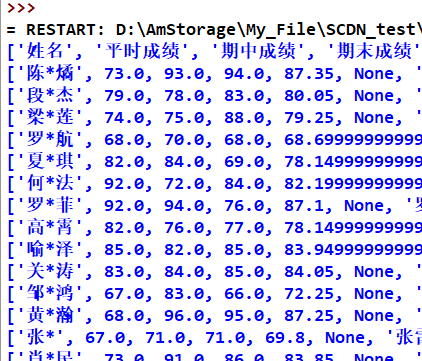
参考
https://blog.csdn.net/sanmi8276/article/details/108023125
https://blog.csdn.net/lh_hebine/article/details/104559382
import openpyxl as op
file = "D:/AmStorage/My_File/SCDN_test/file/grade.xlsx"
# 加载工作薄文件
wb = op.load_workbook(file)
# 获取工作表信息
wb_list = wb.sheetnames
# 获取第一个工作表信息
sht0 = wb[wb_list[0]]
# 得到工作表的区间
sht0.dimensions
# 指定单元格的值
sht0['A2'].value
sht0.cell(2,2).value
# 输出
# 单元格区间的引用
area1 = sht0['A1:C3']
# 输出单元格区间的各值,先遍历行再遍历列
for cell_rows in area1:
for cell_cols in cell_rows:
print(cell_cols.value)
wb.close()
openpyxl应用的参考
https://blog.csdn.net/qq_44614026/article/details/108083958
总结
各个库的函数操作大致相同,打开了文件要关闭,不然打开xlsx文件会显示文件正在打开
openpyxl库中的value显示的居然是原本信息,有公式显示的是公式,另外两个则不是




