



82,262
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享随着现代信息数据的快速增长,数据库的数据量也不断增长。对于庞大的数据如何管理呢?从数据库角度看,分区表无疑是一种很好的选择。
对于很多业务,只会访问最近几天或几个月的数据,对于之前的数据很少甚至几乎不访问,这就形成了热数据和冷数据。使用分区表可以隔离开热数据和冷数据,加快访问速度。最典型的就是按照时间分区,每个分区设置一个时间段,在此时间段内的数据存储在此分区中,这样在数据处理的过程中可以筛掉大量的冗余数据。
如何从普通表转换为分区表呢?这不得不提分区表的一个黑科技了–分区交换技术。
分区交换技术:将一个分区和一个普通表的数据进行交换,达到快速导入数据进入分区表的目的。
分区交换技术原理和约束:分区交换技术并不是用常规的insert、select语句进行数据导入导出的,而是通过修改数据对象的数据物理位置,所以实际执行速度非常快,不用担心阻塞业务。对于数据交换的两个表需要保证约束一致,否则数据导入后将会毫无意义。数据交换后,普通表和分区的统计信息变得不可靠,需要对普通表和分区重新执行analyze。
分区交换的主要步骤如下:
1.准备源表和新的分区表
2.基于源表元数据创建分区表以及相关索引、约束等
3.使用分区交换的语法将普通表的数据导入到分区表中
4.收集统计信息。
openGauss的分区交换使用方法
语法如下
ALTER TABLE [ schema. ] table
EXCHANGE { partition_extended_name }
WITH TABLE [ schema. ] table
[ { WITH | WITHOUT } VALIDATION ] [VERBOSE]
VALIDATION代表是否要对数据进行检查,如果有数据不满足分区要求会进行报错处理。如果不指定VALIDATION子句,则默认进行VALIDATION。
如果确认所有数据都满足分区要求才可以指定WITHOUT VALIDATION,否则数据将不可用。
如果不指定VERBOSE选项,则对不符合目标分区的记录,进行报错处理,不自动重路由至其他目标分区。如果指定VERBOSE,会将不符合目标分区的记录路由到对应的分区,如果不存在对应的分区才进行报错处理。
●建表准备数据
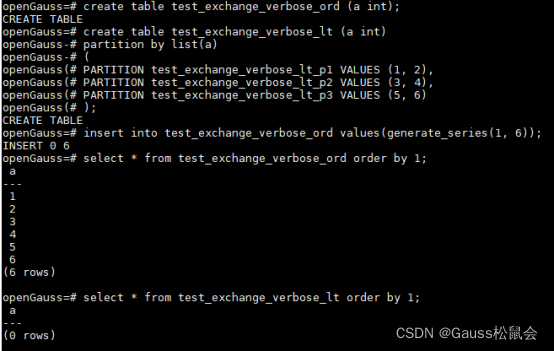
●进行数据交换

●查看交换结果
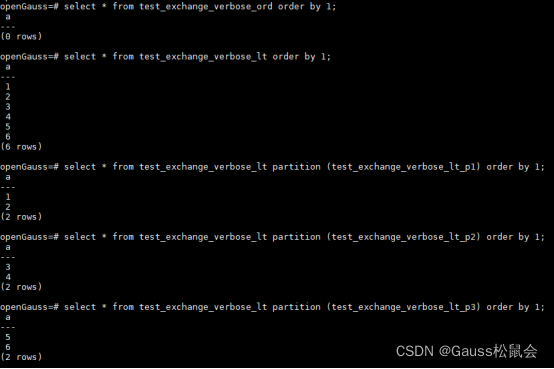
经过上面的例子,我们可以看到分区交换技术可以实现数据的快速导入导出,这可以为用户切换分区表管理数据业务提供性能更优的数据管理策略,是openGauss在数据库工程实践上的又一次积极探索。

