



82,269
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享过去的2021年可能是过去二十年来数据库领域创业最疯狂的一年。借着Snowflake、Confluent等明星数据库公司上市,以及美联储继续大放水的东风,各路投资机构都在2021年选择了加紧在数据库赛道的布局,将热钱撒向了那些刚刚起步的数据库初创公司们。
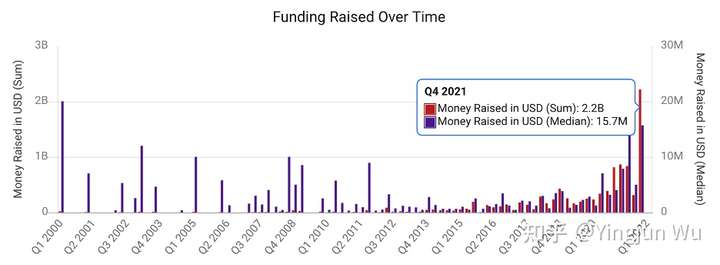
上图展示了过去二十年中数据库初创企业的融资情况(不完全统计)。红色柱代表着所有数据库初创企业在一个季度中一共募集到的资金,而紫色柱代表了平均资金募集量。单在2021年第四季度,全球数据库初创企业就募集到了22亿美金的资金。很显然,这从数据层面印证了数据库领域在2021年的火热。
在过去的一年里,我聊过了许多投资人、数据库从业者以及有创业动机的伙伴。我发现,不少投资人都是趁着这股热潮从其他方向(比如消费等)转战数据库方向,对该方向尚未有深厚的理解;不少数据库从业者也是因为信息不对称的缘故,对整个数据库创业的行业发展暂时欠缺全局的视野,对数据库创业敬而远之;而不少有在数据库领域创业想法的朋友看不清当下局势,对是否出来创业犹豫不决。趁着元旦这几天假期,我就把过去一年在数据库领域的投融资情况粗略梳理一下,抛砖引玉,供大家参考。
申明:本文无法覆盖所有过去一年的行业动态,且很大程度上带有主观色彩,信息与洞见可能会十分片面,并不构成对任何人的投资、跳槽、创业的建议。另外,本文故意不含盖任何尚未官宣的投融资情况,如需八卦,请考虑私聊 :-)
接下来,我们就依次按OLTP、OLAP、streaming这三大细分领域来总结一下2021。
OLTP领域应该是大家最熟悉的数据库赛道了。这个赛道起步较早,该领域的三家领跑者:CockroachDB、PingCAP、以及 Yugabyte,都已经发展了五六个年头,产品形态趋于完善。而在2021年,这三家公司又不约而同的进行了大规模融资:CockroachDB从估值50亿美金的F轮中募集了2.78亿美金;PingCAP完成了估值30亿美金的E轮融资;Yugabyte也从C轮融资中募集了1.88亿美金,将估值推向13亿美金。很显然,OLTP数据库是几乎所有用户的刚需,而云原生OLTP数据库也是云上用户的必要需求。但至今为止市场上还并不存在一家第三方云原生OLTP数据库公司进行IPO,因此想象空间很大。尽管前景无限光明,但是在OLTP这个赛道上,目前为止,大量用户还是更加倾向于云厂商自身所提供的服务,例如AWS的RDS以及Aurora。除了成熟度之外,云厂商所提供的服务也有自身独特的优势。一方面,三家初创公司CockroachDB、PingCAP、Yugabyte(至少在早期)都一致选择了类Google Spanner架构来构建数据库。而Spanner架构产生的原因是为了更好的服务要求全球化、强一致性、大数据量的用户。这类用户本身一般就是大型企业,数量十分有限,因此竞争会异常激烈。相比之下,云厂商所提供的服务,例如AWS Aurora,采用的是shared everything架构,这种架构能够很好的服务于数据量在128TB以下的用户。而根据长尾分布,这类用户属于市场的大多数,在价格相当且性能等其他方面没有硬伤的情况下,用户可能会更加倾向于使用云厂商自身的服务。另一方面,云厂商所提供的RDS或者Aurora服务本身就是基于行业标准MySQL与PostgreSQL开发,用户可以无缝的将私有化部署的MySQL与PostgreSQL服务迁到线上,实现几乎零成本迁移。而三家初创公司所选的Spanner架构要求厂商自己实现对MySQL或者PostgreSQL的SQL支持。如果实现不完善,很容易带来一定的迁移成本,让用户感到畏惧。还有一方面,OLTP应用一般对性能极其敏感,而这种性能的瓶颈往往在于存储访问。而提升存储访问性能正是云厂商擅长的:他们可以通过定制化新硬件、使用底层接口等手段大幅降低访问延迟,从而达到性价比的提升。综上,要想在OLTP这个赛道上从云厂商口中抢下客户,必然道路艰辛。
但这些挑战并不意味着虎口夺食毫无可能。毕竟,上述提到的三家初创公司已经在过去的几年内部分证明了自己的商业能力。类Spanner系统更加偏向的是资源充沛的大中型客户,而这类客户付费能力极强,每单都能产生数十万甚至上百上千万美金的收入。相信估值50亿美金的CockroachDB已经为资本市场证明了这一点。相比于云厂商,创业公司也能够更加灵活的改变自己的玩法。例如,PingCAP就不再称自己为OLTP数据库,而是包装自己为HTAP数据库,将触手同时伸至实时交易与分析两大块场景。此外,三家公司均采用开源策略,这也会推动品牌形象的传播。大胆预测一下,在未来的一到三年内,在OLTP这个赛道上,我们应该能够见到成功IPO的公司。
OLAP这个领域已经火出天际了。自从Snowflake于2020年9月IPO以来,股价尽管经历过低谷,但是总体仍然保持高速增长趋势,目前市值已经超过1000亿美金,几乎接近IBM的1200亿美金市值。要知道,整个数据库行业的老大Oracle目前市值为2400亿美金,其最新季度营收为104亿美金,但Snowflake的季度营收仅为3.34亿美金,两者差距30多倍。显然,投资者们都太疯狂了,Snowflake不应该有这么高的估值。但是,仔细看一下数据,就似乎能够理解这疯狂背后的逻辑:Oracle的季度营收相比去年同期上涨6%,而Snowflake上涨了110%!更重要的一点是,Snowflake的净收入留存率(NRR)达到了惊人的173%,也就是说,假设去年的一个用户在Snowflake上花了1块钱,那么今年这个用户就会花掉1.73块钱!要知道,在软件服务领域,NRR中位数也不过就在100%左右,能做到125%已经算是个相对不错的数字了。
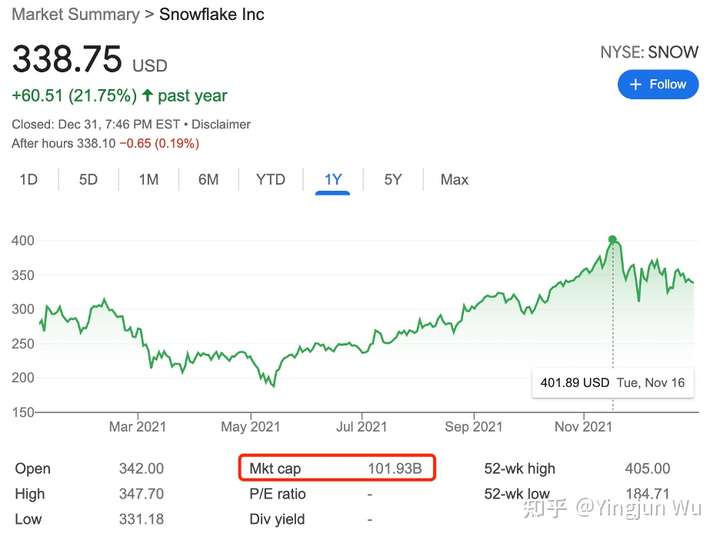
看到了Snowflake 的成功,一级市场的投资人们都异常兴奋的拿着热钱寻找着下一个Snowflake。毫无疑问,Databricks是最有可能成功的一个。Databricks于2021年8月宣布了自己高达380亿美金估值的H轮融资。拿着自己账上的几十亿美金现金,Databricks也对外宣示要通过大力投入自己的lakehouse来挑战Snowflake的地位。其中之一的动作就是在11月份性能“碰瓷”Snowflake。不谈数据是否可靠,不得不说Databricks想在OLAP(数据仓库)领域完全赶上甚至反超Snowflake应该还有很长的路要走,毕竟Databricks的lakehouse(不算Spark部分)才研发了两三年,但Snowflake的开发已经经历了八九个年头。开发周期的长短会直接决定功能完备性,而用户很难去选择一款功能欠缺的产品。除去功能完备性外,易用性也是Snowflake能够战胜其他竞品的秘诀。毕竟要知道,大多数公司并不具备很强的工程能力,产品简单好用,文档通俗易懂,往往要比性能本身更能起到决定性作用。当然,Databricks完全可以从至少两大方面吸引到用户。一方面是所谓的open format,也就是开放文件格式。几乎没有用户愿意被厂商绑定,因为一旦被绑定,那么厂商就获得了定价权,之后想要迁移也会付出很高的代价。Databricks使用公开文件格式至少能够先“骗”不愿意被绑定的用户上船,之后再通过其他手段让用户长期使用自己的产品。另一方面就是多功能多语言平台的集成。Databricks的lakehouse底层可以无缝连接到Spark上去。如果有数据科学家想要使用lakehouse上的数据,他们无需经过复杂的系统导入导出,直接用他们最喜欢的语言,比如Python,进行数据的操作。当然Snowflake在这方面也有对策,就是自己的Snowpark项目。与此同时,Snowflake自身联合了数家专注于机器学习的厂商来去打造自己的data cloud。因此Databricks是否真的能够在这个市场上达到Snowflake的高度,还需通过时间来证明。
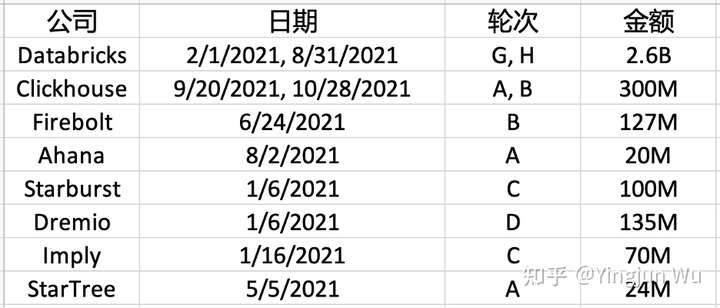
Databricks所推销的lakehouse是数据湖与数据仓库的结合。数据湖强调以极低的成本存储大量的数据,而数据仓库强调对大量数据进行高性能的处理。Lakehouse顾名思义就是想汲取各方所长,用更低的成本处理更大量的数据。这个愿景听上去过于美好,瞬时间各路初创公司都开始叫卖自己的lakehouse。粗略总结一下,做lakehouse一共有三种路线。第一种路线是从传统MPP数据库开始改成lakehouse。典型代表是几家基于Clickhouse创业的公司,包括了ClickHouse Inc以及Firebolt。ClickHouse Inc是Yandex的核心团队出来做的公司,具有正统性,因此刚出来就连续完成了两轮融资,手头拿了3亿美金,并且将估值直接推上20亿美金。Firebolt是以色列团队出来做的魔改版ClickHouse,在2021年也完成了B轮1.27亿美金的融资。他们将ClickHouse作为内核引擎,但是他们的官网上却几乎没有提及这一点,似乎比较希望洗脱跟ClickHouse的关联。第二种路线是从查询引擎开始做lakehouse。典型代表是几家核心产品基于Presto的创业公司,包括了Starburst Data与Ahana。这两家也是在2021年分别完成了C轮1亿美元与A轮2000万美元的融资。第三种路线就是直接从数据湖入手做lakehouse。这类的公司包括了由Apache Iceberg创始团队出来做的Tabular,以及另一家还处于stealth mode的公司。除了这三类公司外,我们同时也看到了Dremio这种到达了D轮的中后期公司,他们融得了1.35亿美金打造自己的lakehouse。Lakehouse这个故事实在动人,以至于国内也出现了近十家做类似事情的团队。由于绝大多数团队都没有发布正式的融资新闻,不少还处于stealth mode,我们就不在这里展开讨论了。至于结果如何、哪个团队会以哪种形式胜出,也许只有时间能够告诉我们答案了。
无论是数据仓库还是lakehouse,都是在强调如何在大规模数据集上高效的做复杂查询。这类系统的查询延迟短则秒级,长则分钟级,但总的来说用户一般更多的倾向于将这类系统做离线分析。而现在OLAP领域内一大趋势就是构建高吞吐、低延迟的系统。这类系统可以允许实时的将前端应用所产生的数据直接接入,并直接进行低延迟查询,而返回出的查询结果可以直接反馈给前端应用的用户。这类系统的典型代表是Apache Druid与Apache Pinot。基于这两个系统打造核心产品的公司,Imply与StarTree,也分别在2021年获得了7000万美金与2400万美金的融资。尽管从定位上来讲,这类低延迟OLAP数据库与数据仓库或lakehouse有所差别,但可以预见,在未来的3-5年甚至更短的时间内,大概率会有所重合。实质上,这样的重合哪怕在今天这个时间点就已经存在了,就好比大家对于ClickHouse与Firebolt的定位一样。在这里就不详细展开了。
总之,OLAP市场的竞争无论是在国内还是国外都已经呈现出白热化趋势。相比于OLTP市场,OLAP市场的好处在于系统并不是高度标准化。对于OLAP领域的创业公司来说,如何找到合适的市场定位相比于技术本身更会决定公司的归宿。
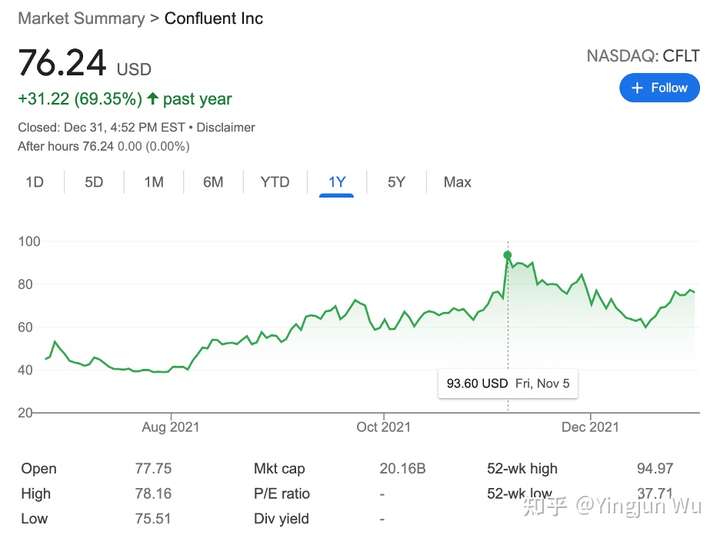
流处理领域于2021年见证了核心产品基于Apache Kafka的商业公司Confluent的上市。自六月上市以来,Confluent的股价已经上涨了将近70%,市值超过200亿美金。尽管面临着Amazon Kinesis的强力竞争,Confluent的最新季度盈利相比去年同期上涨了67%,而他们的云服务收入上涨了245%。相比于OLAP市场,流处理市场是一个更加年轻的市场,但Confluent的成功很显然还是证明了这一市场的潜力。
流处理平台可以分成两大类,一类是消息通信平台,其代表系统为Apache Kafka;另一类是流计算平台,其代表为Apache Flink。
消息通信平台的作用往往是用来存储、缓冲新流入的数据。作为消息通信平台的事实标准,Kafka被广泛的使用在各大公司中。但由于是大数据时代的产物,其存算耦合的架构带来了很高的经济成本,而这一劣势在云平台部署上造成了更大的问题。因此新一代消息通信平台广泛的采用了存算分离(或类似)的架构来降低成本。典型的系统包括了Apache Pulsar与Redpanda。这两个系统背后的公司StreamNative与Vectorized分别在2021年融得了2370万美金与1250万美金。存算分离的架构在降低成本的同时也给系统定位带来潜在转变:之前由于高昂的成本,用户通常只在Kafka内部存放短暂的数据,例如7天的数据;而Pulsar与Redpanda的存算分离架构直接将大规模数据直接存放在廉价存储上,使得长期存储数据变成可能,而这一转变将有潜力将这类系统的定位由之前的消息通信平台变为数据终端,也就是说,自己本身就成为数据库。如果这一定位转换得以实现,无疑将对数据库市场的竞争带来更多的不确定性。
除了消息通信平台,流计算平台也是一个最近兴起的赛道。尽管Confluent有基于Kafka的流计算引擎KsqlDB,尽管Apache Flink已经成为这一赛道的事实领跑者,但新兴的流计算平台仍然激起了不少人的兴趣。一方面,KsqlDB强耦合于Kafka,且不支持诸多复杂查询操作,这使得用户无法灵活高效的开发应用。另一方面,Flink作为大数据时代的产物,其提供的Java API为非工程师背景的用户设置了相当高的门槛。尽管Flink SQL提供了大数据SQL接口,但这一特性尚不成熟,更重要的是,Flink SQL并不能根本上改变Flink是个大数据系统的形象。这一局面给创业公司们带来了一些机会。其中,Materialize基于成熟的timely dataflow引擎为用户提供了pgSQL接口,大幅降低了系统使用的门槛。这家公司在2021年也完成了6000万美金的C轮融资。另外,Decodable这家公司也尝试为用户提供SQL接口来解决流式ETL问题。这类公司的崛起让我们对流处理市场未来的发展充满期待。
文章来源:https://zhuanlan.zhihu.com/p/452628664

