


12,388
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享为了方便对网络模型的训练损失、验证精度等结果进行展示,以及对不同模型之间的结果进行对比分析,数据可视化的工作就显得尤为重要。
昇思MindSpore Vision套件对外提供了相关的数据可视化API,可以方便开发者在做网络模型实验、学习、更好的助力科研等工作。
下面将对昇思MindSpore Vision套件所提供的数据可视化API的功能以及应用场景进行介绍
源代码链接(点击“阅读原文”即可进入):
https://gitee.com/mindspore/vision/blob/master/docs/visualization_of_experience.ipynb
实验数据可视化
topn_accuracy_chart
函数topn_accuracy_chart主要用于绘制在不同AI框架下,模型精度的对比。
参数说明
【accuracy_data】用于绘制折线图的模型数据,其中数据包括不同AI框架下的模型精度。
【save_path】图表的保存路径。
【ylim】图表y坐标的刻度范围。
【figsize】图表的尺寸。
【title】图表的标题。
【xlabel】图表x坐标的标签。
【ylabel】图表y坐标的标签。
样例
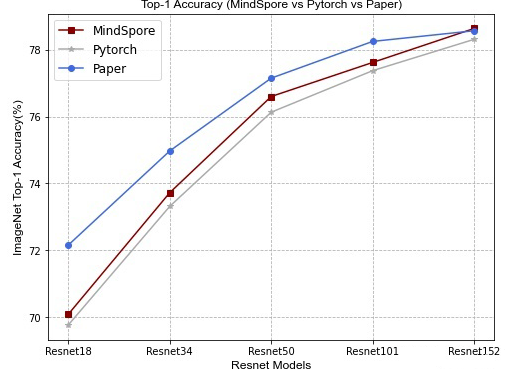
以下样例绘制了Resnet系列模型分别在MindSpore、Pytorch、Paper下的模型精度对比。结论如下:
基于MindSpore框架下训练的Resnet系列模型,在ImageNet验证数据集的精度要比Pytorch略高。
import numpy as np
from mindvision.utils.charts import * # pylint: disable=W0401
accuracy_data = {
'MindSpore': {
'Resnet18': 70.078,
'Resnet34': 73.72,
'Resnet50': 76.6,
'Resnet101': 77.62,
'Resnet152': 78.638},
'Pytorch': {
'Resnet18': 69.758,
'Resnet34': 73.31,
'Resnet50': 76.13,
'Resnet101': 77.374,
'Resnet152': 78.312},
'Paper': {
'Resnet18': 72.15,
'Resnet34': 74.97,
'Resnet50': 77.15,
'Resnet101': 78.25,
'Resnet152': 78.57}
}
topn_accuracy_chart(accuracy_data=accuracy_data,
figsize=(8, 6),
title='Top-1 Accuracy (MindSpore vs Pytorch vs Paper)',
xlabel='Resnet Models',
ylabel='ImageNet Top-1 Accuracy(%)')
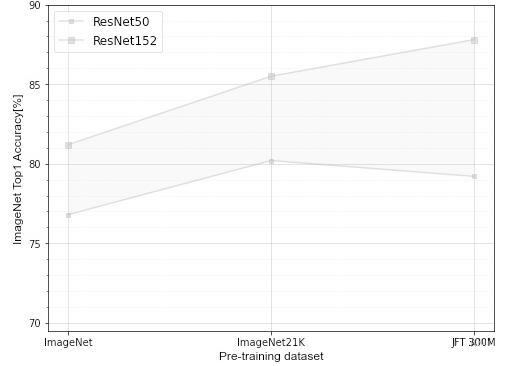
accuracy_on_dataset_chart_v1
函数accuracy_on_dataset_chart_v1主要用于绘制在不同预训练数据集上模型精度的区间范围。
参数说明
【accuracy_data】用于绘制折线图的模型数据,其中数据包括不同预训练数据集的模型精度和marker的大小。
【save_path】图表的保存路径。
【ylim】图表y坐标的刻度范围。
【figsize】图表的尺寸。
【title】图表的标题。
【xlabel】图表x坐标的标签。
【ylabel】图表y坐标的标签。
样例
以下样例绘制了Resnet系列模型分别在ImageNet、ImageNet21K、JFT-300M预训练数据集训练,然后在ImageNet数据集上进行finetune后的Top1精度的区间范围。
accuracy_data = {
'ResNet50': {
'accuracy': {
'ImageNet': 76.8,
'ImageNet21K': 80.2,
'JFT-300M': 79.2,
},
'marker_size': 4
},
'ResNet152': {
'accuracy': {
'ImageNet': 81.2,
'ImageNet21K': 85.5,
'JFT-300M': 87.8,
},
'marker_size': 6
}
}
accuracy_on_dataset_chart_v1(accuracy_data=accuracy_data,
ylim=[69.5, 90],
figsize=(8, 6),
xlabel='Pre-training dataset',
ylabel='ImageNet Top1 Accuracy[%]')
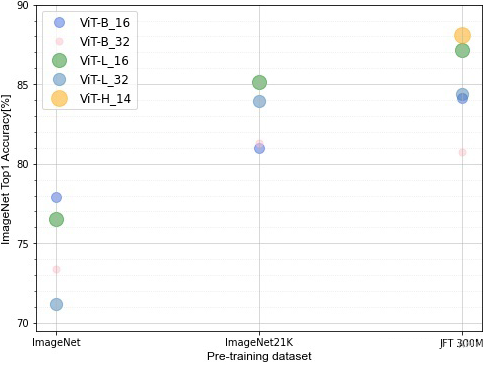
accuracy_on_dataset_chart_v2
函数accuracy_on_dataset_chart_v2主要用于绘制在不同预训练数据集上模型精度的对比。
参数说明
【accuracy_data】用于绘制点状图的模型数据,其中数据包括不同预训练数据集的模型精度和marker的大小。
【save_path】图表的保存路径。
【ylim】图表y坐标的刻度范围。
【figsize】图表的尺寸。
【title】图表的标题。
【xlabel】图表x坐标的标签。
【ylabel】图表y坐标的标签。
样例
以下样例绘制了ViT系列模型分别在ImageNet、ImageNet21K、JFT-300M预训练数据集训练,然后在ImageNet数据集上进行finetune后的Top1精度对比。
accuracy_data = {
'ViT-B_16': {
'accuracy': {
'ImageNet': 77.91,
'ImageNet21K': 80.99,
'JFT-300M': 84.15,
},
'marker_size': 100
},
'ViT-B_32': {
'accuracy': {
'ImageNet': 73.38,
'ImageNet21K': 81.28,
'JFT-300M': 80.73,
},
'marker_size': 50
},
'ViT-L_16': {
'accuracy': {
'ImageNet': 76.53,
'ImageNet21K': 85.15,
'JFT-300M': 87.12,
},
'marker_size': 200
},
'ViT-L_32': {
'accuracy': {
'ImageNet': 71.16,
'ImageNet21K': 83.97,
'JFT-300M': 84.37,
},
'marker_size': 150
},
'ViT-H_14': {
'accuracy': {
'JFT-300M': 88.12,
},
'marker_size': 250
}
}
accuracy_on_dataset_chart_v2(accuracy_data=accuracy_data,
ylim=[69.5, 90],
figsize=(8, 6),
xlabel='Pre-training dataset',
ylabel='ImageNet Top1 Accuracy[%]')
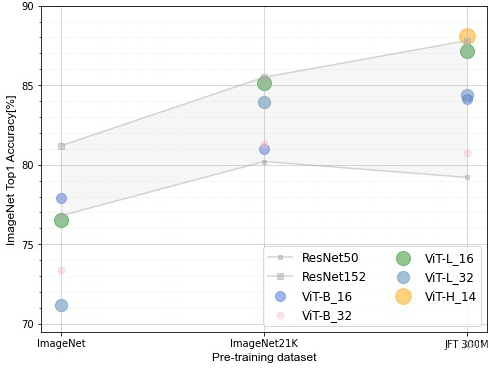
accuracy_on_dataset_chart_v3
函数accuracy_on_dataset_chart_v3主要用于绘制在不同预训练数据集上不同模型架构之间的精度对比。
参数说明
【line_models_data】用于绘制折线图的模型数据,其中数据包括不同预训练数据集的模型精度和marker的大小。
【scatter_models_data】用于绘制点状图的模型数据,其中数据包括不同预训练数据集的模型精度和marker的大小。
【save_path】图表的保存路径。
【ylim】图表y坐标的刻度范围。
【figsize】图表的尺寸。
【title】图表的标题。
【xlabel】图表x坐标的标签。
【ylabel】图表y坐标的标签。
样例
以下样例绘制了Resnet系列模型和ViT系列模型分别在ImageNet、ImageNet21K、JFT-300M预训练数据集训练,然后在ImageNet数据集上进行finetune后的Top1精度对比。结论如下:
1、其中图表的阴影部分代表了ResNet50和Resnet152的精度范围。
2、ViT系列的模型在中小型数据集预训练的效果不好,精度全面不如ResNet系列的模型。
3、随着预训练数据集的增大,ViT系列的模型精度表现越来越好。
line_models_data = {
'ResNet50': {
'accuracy': {
'ImageNet': 76.8,
'ImageNet21K': 80.2,
'JFT-300M': 79.2,
},
'marker_size': 4
},
'ResNet152': {
'accuracy': {
'ImageNet': 81.2,
'ImageNet21K': 85.5,
'JFT-300M': 87.8,
},
'marker_size': 6
}
}
scatter_models_data = {
'ViT-B_16': {
'accuracy': {
'ImageNet': 77.91,
'ImageNet21K': 80.99,
'JFT-300M': 84.15,
},
'marker_size': 100
},
'ViT-B_32': {
'accuracy': {
'ImageNet': 73.38,
'ImageNet21K': 81.28,
'JFT-300M': 80.73,
},
'marker_size': 50
},
'ViT-L_16': {
'accuracy': {
'ImageNet': 76.53,
'ImageNet21K': 85.15,
'JFT-300M': 87.12,
},
'marker_size': 200
},
'ViT-L_32': {
'accuracy': {
'ImageNet': 71.16,
'ImageNet21K': 83.97,
'JFT-300M': 84.37,
},
'marker_size': 150
},
'ViT-H_14': {
'accuracy': {
'JFT-300M': 88.12,
},
'marker_size': 250
}
}
accuracy_on_dataset_chart_v3(line_models_data=line_models_data,
scatter_models_data=scatter_models_data,
ylim=[69.5, 90],
figsize=(8, 6),
xlabel='Pre-training dataset',
ylabel='ImageNet Top1 Accuracy[%]')
accuracy_model_size_chart
函数accuracy_model_size_chart主要用于绘制在不同大小的预训练数据集上模型之间的精度对比。
参数说明
【accuracy_data】用于绘制折线图的模型数据,其中数据包括不同大小的预训练数据集的精度。
【size_unit】数据集大小的单位。
【save_path】图表的保存路径。
【ylim】图表y坐标的刻度范围。
【figsize】图表的尺寸。
【title】图表的标题。
【xlabel】图表x坐标的标签。
【ylabel】图表y坐标的标签。
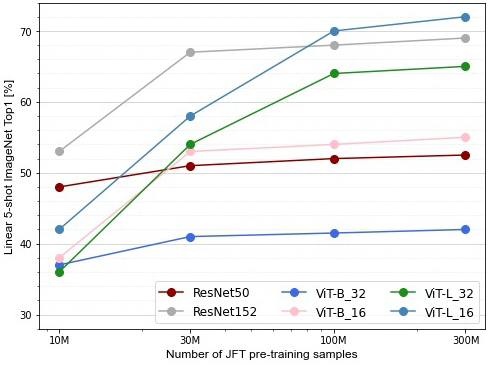
样例
以下样例绘制了Resnet系列模型和ViT系列模型分别在10M、30M、100M、300M的JFT-300M预训练数据集训练,将ImageNet数据集1000类中的每一类随机采样5张图片作为验证数据集,然后将不同大小预训练数据集的预训练模型作为特征提取层,在验证数据集上直接进行精度对比。结论如下:
1、在预训练数据集比较少的情况下ViT系列模型的精度不如ResNet系列。
2、随着预训练数据集的增多,ViT系列模型的精度越来越高,效果要比ResNet系列要好。
accuracy_data = {
'ResNet50': {
10: 48,
30: 51,
100: 52,
300: 52.5
},
'ResNet152': {
10: 53,
30: 67,
100: 68,
300: 69
},
'ViT-B_32': {
10: 37,
30: 41,
100: 41.5,
300: 42
},
'ViT-B_16': {
10: 38,
30: 53,
100: 54,
300: 55
},
'ViT-L_32': {
10: 36,
30: 54,
100: 64,
300: 65
},
'ViT-L_16': {
10: 42,
30: 58,
100: 70,
300: 72
}
}
accuracy_model_size_chart(accuracy_data=accuracy_data,
size_unit='M',
ylim=[28, 74],
figsize=(8, 6),
xlabel='Number of JFT pre-training samples',
ylabel='Linear 5-shot ImageNet Top1 [%]')
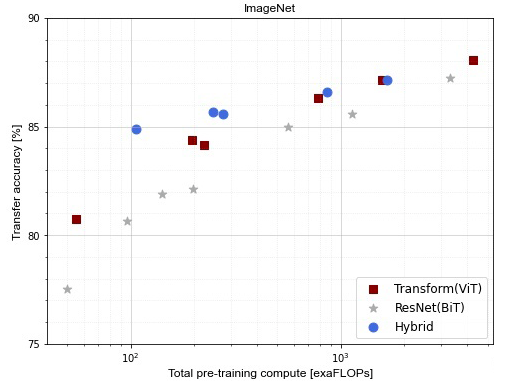
accuracy_model_flops_chart
函数accuracy_model_flops_chart主要用于绘制在不同的计算复杂度下,不同架构的模型之间的精度对比。
参数说明
【accuracy_data】用于绘制点状图的模型数据,其中数据包括不同架构下的模型,以及模型的计算复杂度和精度。
【save_path】图表的保存路径。
【ylim】图表y坐标的刻度范围。
【figsize】图表的尺寸。
【title】图表的标题。
【xlabel】图表x坐标的标签。
【ylabel】图表y坐标的标签。
样例
以下样例绘制了Transform、ResNet、Hybrid三种不同网络架构下的模型,在不同计算复杂度下的精度对比。其中所有的模型精度都是在JFT-300M预训练数据集进行预训练,然后在ImageNet数据集进行finetune后的Top1精度。结论如下:
1、在同等的计算复杂度下,Transformer架构的模型精度要比ResNet架构的模型精度高,所以ViT系列的模型比较便宜。
2、在模型比较小的情况下,Hybrid架构的模型精度最高,但是随着模型越来越大,精度就和Transformer架构的模型差不多,甚至不如它。
3、Transformer架构的模型扩展性比较强,随着模型越来越大,精度没有呈现饱和的趋势。
accuracy_data = {
'Transform(ViT)': {
"vit-B_32_7": {55: 80.73},
"ViT-B_16_7": {224: 84.15},
"ViT-L_32_7": {196: 84.37},
"ViT-L_16_7": {783: 86.30},
"ViT-L_16_14": {1567: 87.12},
"ViT-H_14_14": {4262: 88.08}
},
'ResNet(BiT)': {
"ResNet50x1_7": {50: 77.54},
"ResNet50x2_7": {199: 82.12},
"ResNet101x1_7": {96: 80.67},
"ResNet152x1_7": {141: 81.88},
"ResNet152x2_7": {563: 84.97},
"ResNet152x2_14": {1126: 85.56},
"ResNet200x3_14": {3306: 87.22}
},
'Hybrid': {
"R50x1+Vit-B_32_7": {106: 84.90},
"R50x1+Vit-B_16_7": {274: 85.58},
"R50x1+Vit-L_32_7": {246: 85.68},
"R50x1+Vit-L_16_7": {859: 86.60},
"R50x1+Vit-L_16_14": {1668: 87.12}
}
}
accuracy_model_flops_chart(accuracy_data=accuracy_data,
ylim=[75, 90],
figsize=(8, 6),
title='ImageNet',
xlabel='Total pre-training compute [exaFLOPs]',
ylabel='Transfer accuracy [%]')
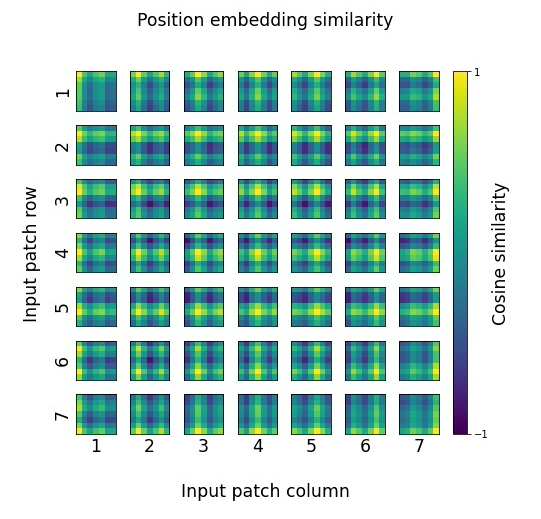
pos_embedding_cosine_chart
函数pos_embedding_cosine_chart主要用于绘制图像patches之后的位置编码之间的余弦相似度。
参数说明
【pos_embedding】位置编码。
【save_path】图表的保存路径。
【title】图表的标题。
【xlabel】图表x坐标的标签。
【ylabel】图表y坐标的标签。
【colorbar_label】图表彩条的标签。
样例
以下样例绘制了ViT-B_32模型预训练好的位置编码之间的余弦相似度。下载好的位置编码的维度为(1, 50, 768),该函数会先将数据维度进行压缩,然后去除掉最开始用来分类token的位置编码,只保留图像patches之后的位置编码,然后进行图像绘制。结论如下:
每一个位置编码都和自己的同一行或者同一列有较高的余弦相似度,说明图像的同一行或者同一列具有较强的位置关系。
pos_embedding = np.load('./data/pos_embedding.npy')
pos_embedding_cosine_chart(pos_embedding=pos_embedding,
title='Position embedding similarity',
xlabel='Input patch column',
ylabel='Input patch row',
colorbar_label='Cosine similarity')

MindSpore官方资料
官方QQ群: 486831414
官网: https://www.mindspore.cn/
Gitee: https : //gitee.com/mindspore/mindspore
GitHub: https://github.com/mindspore-ai/mindspore
官方论坛: https://bbs.huaweicloud.com/forum/forum-1076-1.html


