


11,737
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享很高兴,我们昇思MindSpore团队和赵捷老师、陈雷老师合作的论文《Apollo: Automatic Partition-based Operator Fusion through Layer by Layer Optimization》也入选了。
同时这篇论文也是昇思MindSpore团队与赵捷老师合作的第三篇论文,前两篇论文分别发布在Micro 2020、PLDI 2021:
01
《53年来国内唯三,MindSpore加速昇腾芯片论文获国际顶会MICRO最佳论文提名》
链接:https://zhuanlan.zhihu.com/p/333394142
02
《PLDI 2021论文分析(一):AKG-NPU上算子自动生成技术探索》
链接:https://zhuanlan.zhihu.com/p/384191216
前面的论文主要聚集于自动算子编译技术,而Apollo则主要是围绕自动算子融合优化展开。当前,这些对应技术已经全部落地昇思MindSpore,并共同支撑了图算融合加速引擎这个重要的性能优化特性。
当然,我们的所有代码实现也是全部开源,欢迎小伙伴们围观讨论。
从另外一方面,以上论文历程也基本代表了昇思MindSpore图算融合团队近几年所走过的技术历程:先从自动算子调度生成起步,然后逐步延伸到自动算子融合优化领域,最后进行二者的技术整合和整体协同创新。
对于一个团队来说,一个技术方向能够持续投入3年以上,特别是这个技术在中间很长一段时间可能都没有产出,还是需要很大决心和耐心的。所以很庆幸能够一路坚持下来,逐步将图算融合打造成为国内首个全自研的自动算子融合加速引擎,并在一些关键性能上大幅超越XLA。
那么,来分享一下论文的具体介绍吧。
算子融合优化一直是AI网络最重要的单卡性能优化手段,也是最容易立竿见影的性能优化手段。
01
从硬件性能角度看
算子融合主要是解决AI处理器所面临的两方面的性能难题:内存墙和并行墙问题。这也是不同AI处理器中普遍性存在的两个关键性性能问题。
内存墙问题主要是访存瓶颈引起。算子融合主要通过对计算图上存在数据依赖的“生产者-消费者”算子进行融合,从而提升中间Tensor数据的访存局部性,以此来解决内存墙问题。这种融合技术也统称为“Buffer融合”。在很长一段时间,Buffer融合一直是算子融合的主流技术。
早期的AI框架,主要通过手工方式实现固定Pattern的Buffer融合。首先通过手工编写融合算子实现,然后再手工实现对应的融合Pass,进行融合pattern匹配和替换修改。
但随着不同AI模型的快速演进和多样化,大家很快发现这种方式的不足:无法泛化!即只能针对特定网络中特定算子组合Pattern进行融合优化。面对网络结构越来越复杂、越来越多样化的快速发展趋势,这种方式只能望洋兴叹了。
为了解决手工融合无法泛化的问题,以XLA、TVM、MLIR等为代表的AI编译技术框架开始转向自动Buffer融合优化技术。
02
从算子生成角度看
早期的自动Buffer融合基本是等价于Loop Fusion,即把相邻的存在数据依赖的算子进行Loop空间深度融合,使得中间tensor数据访问退化为局部变量、甚至寄存器变量,从而大幅减少访存开销。
Loop Fusion虽然优化效果显著,但它有一个明显的限制:相邻算子节点是否可融合受限于待融合算子的Loop循环是否可以进行有效的循环合并。
这个限制条件的存在,使得融合子图规模难以进一步放大。但随着AI芯片计算能力的快速发展,内存墙问题越来越突出,这个限制条件逐渐成为限制融合技术发展的关键因素。
为了突破这个限制条件,阿里的小伙伴们提出了非常棒的AStitch技术,使用Stitch的方式将相互依赖算子通过层次化的存储媒介进一步“缝合”在一起。而不再依赖融合算子循环空间的深度合并。
随着Rammer的发布,通过算子融合解决并行墙问题进入大家的视野。并行墙问题主要是由于芯片多核增加与单算子多核并行度不匹配引起。随着芯片并行核数的快速堆叠,AI网络单个算子节点的并行度难以有效利用这么多多核资源。在推理场景这个问题更加明显。
为此,Rammer提出一种将计算图中的算子节点进行并行编排,从而提升整体计算并行度。特别是对于网络中存在可并行的分支节点,这种方式可以获得较好的并行加速效果。为了区别于Buffer融合,这种融合方式我们姑且称为 “并行融合”吧。
如上所述,当前的自动算子融合优化技术本质上走上了两条有点割裂的技术方向:用于解决内存墙的Buffer融合以及用于解决并行墙的并行融合。
那么,我们是否有可能把这些不同的融合优化技术进行有机结合,发挥各自的优势,从而达到更优的融合优化效果呢?
这个问题正是Apollo(图算融合)试图解决的核心问题。Apollo为此提出了“多层规约融合”优化技术,完美地把Loop Fusion、Stitch Fusion、并行融合等不同优化角度的融合技术纳入统一的框架之下,并实现了非常好的融合优化效果。
将以上所述的算子融合技术演进和发展历程做个简单总结,大概如下图所示:
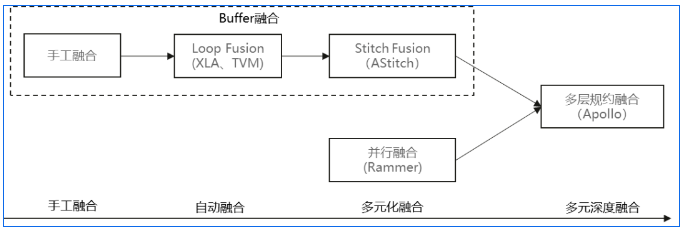
为了实现不同算子融合方式的协同组合,Apollo设计了一个开放式多层规约式融合架构(如下图所示)。将不同的融合方式实现为不同的Layer,然后通过对不同Layer进行逐层规约合并,从而得到最终的融合算子子图,并获得最佳的融合性能收益。
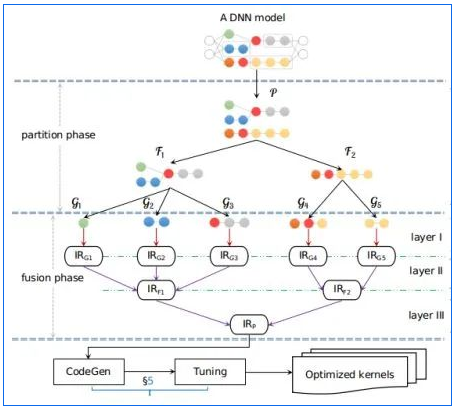
在分层规约融合之前,我们首先通过Partition将输入的计算图拆为为最基本的micro-graphs,将每个micro-graph作为最基本的算子schedule单位,然后以micro-graph为起点,进行多层规约融合。在Apollo论文中,我们介绍了3层设计,分别对应融合功能:
【layer I】通过Polyhedral自动schedule技术对micro-graph进行Loop Fusion和schedule优化;
【layer II】在layer I得到的融合算子IR基础上,识别其中存在数据依赖、且可以做进一步Stitch Fusion的融合算子IR,然后进行Stitch Fusion的规约合并;
【layer III】在layer II得到的融合算子IR基础上,识别其中的无依赖融合算子IR,然后根据并行规则,然后进行并行融合的规约合并。
通过以上多层次规约合并之后,将最终得到的融合算子IR进行codegen,并生成对应融合算子kernel。
以上多层规约融合依赖于灵活的IR合并以及修改,所以IR选择是一个非常重要的设计考虑。
在算子层,考虑到与AKG的对接需求,我们采用了与AKG一致的Halide IR。Halide IR在成熟度以及灵活性还是非常有优势,也有非常丰富的功能基础设施,非常方便我们实现不同融合算子的IR规约合并等修改。
在图层IR选择上,我们没有选择类似XLA的独立HLO IR,而是采用了更简单的、直接复用MindSpore IR(MindIR)的设计思路。
这种IR原生设计为我们接下来的工作带来了诸多好处,比如:
直接消减了MindSpore前端框架向Apollo的IR映射和转换工作;
方便白盒化方式不同层的融合策略分析以及子图合并等;
直接复用MindSpore的已有公共优化和基础设施,大大减少代码开发量。
如前所述,图算融合Apollo已经完全落地MindSpore,并作为图算融合加速引擎功能供用户使用。在昇思MindSpore的一些具体网络模型中,Apollo发挥了关键的性能优化作用。
在昇思MindSpore 1.3版本发布在Bert GPU网络中,Apollo实现3.1~3.6倍的性能加速,并实现了对XLA的整体领先。
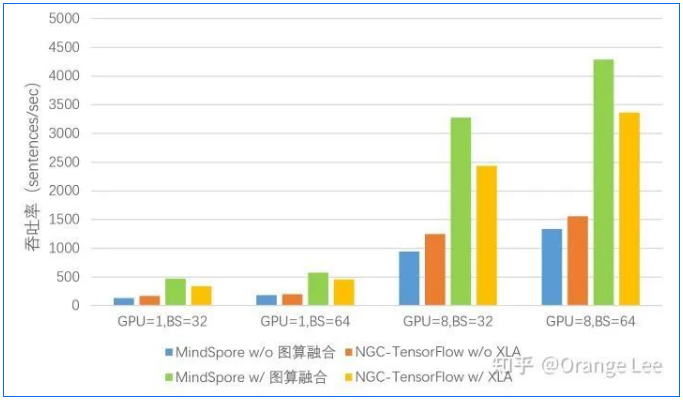
(图源:《国产深度学习框架MindSpore训练性能评测 —— by 中科大ADSL实验室》链接:https://zhuanlan.zhihu.com/p/350343159)
在昇思MindSpore 1.6版本发布的GNN网络中,Apollo实现了3~4倍的性能加速。值得一提的是,针对GNN网络特点,我们基于Apollo的多层规约融合框架,实现了基于索引的非规则内存访问算子融合优化技术。自动识别GNN模型运行任务特有执行pattern并进行融合和kernel level优化。
相较于其他框架对常用算子进行定制优化的方案更加灵活,更具扩展性,能够覆盖现有框架中已有的算子和新组合算子的融合优化。也间接证明的Apollo多层规约融合框架的良好扩展性。
另外,我们也对多达50+网络做了广泛的验证。Apollo平均性能提升:NLP类96.4%↑;推荐类136.6%↑; CV类30.7%↑。
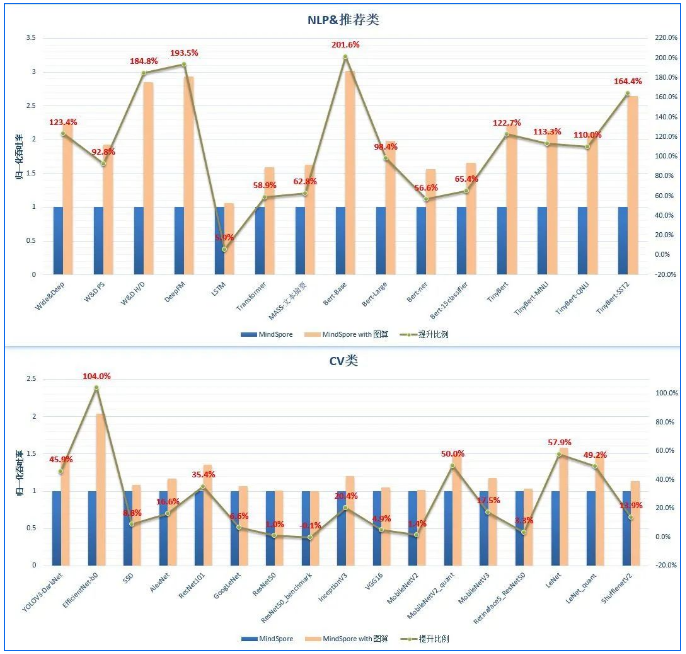
图算融合Apollo通过多层规约融合架构,实现了不同融合方式的结合,并获得显著的融合性能收益。这种融合架构设计具有较好的扩展性和弹性。
未来随着算力的快速发展,并受限于摩尔定律等工艺限制,AI芯片的内存墙以及并行墙问题会越加凸显。Apollo的多层规约融合是我们试图解决这个问题所做的系统性技术尝试。
当然这个思路还是有很多待改进之处,希望与业界同行以及小伙伴进行更多的交流以及讨论!
最后也要感谢已经离开团队的淡孝强(@dxq)在这里面的贡献!
(1)昇思MindSpore图算融合是一支学术研究与商业落地并重的团队,目前还有很多技术问题尚待攻克。欢迎对算子编译融合感兴趣的同学投递简历加入我们(请私信~)!
(2)欢迎对昇思MindSpore和图算融合技术感兴趣的团队或个人参与我们的社区开发,与我们一起进步!
[1] Tianqi Chen, Thierry Moreau, Ziheng Jiang, Lianmin Zheng, Eddie Yan, Haichen Shen, Meghan Cowan, Leyuan Wang, Yuwei Hu, Luis Ceze, et al. TVM: An automated end-to-end optimizing compiler for deep learning. OSDI'18.
[2] Zhen Zheng, Xuanda Yang Pengzhan Zhao, Guoping Long,Kai Zhu, Feiwen Zhu, Wenyi Zhao, Xiaoyong Liu, Jun Yang, Jidong Zhai, et al. AStitch: Enabling a New Multi-dimensional Optimization Space for Memory-Intensive ML Training and Inference on Modern SIMT Architectures. ASPLOS 2022.
[3] Lingxiao Ma, Zhiqiang Xie et al. Rammer:Rammer: Enabling Holistic Deep Learning Compiler Optimizations with rTasks. OSDI 2020.
[4] Jie Zhao, Bojie Li, et al. 2021. AKG: Automatic Kernel Generation for Neural Processing Units using Polyhedral Transformations. PLDI 2021.
[5] Jie Zhao,Peng Di. 2020. Optimizing the Memory Hierarchy by Compositing Automatic Transformations on Computations and Data. MICRO-53.
[6] 图算融合加速引擎介绍.
https://www.mindspore.cn/docs/zh-CN

MindSpore官方资料
官方QQ群: 486831414
官网: https://www.mindspore.cn/
Gitee: https : //gitee.com/mindspore/mindspore
GitHub: https://github.com/mindspore-ai/mindspore
官方论坛: https://bbs.huaweicloud.com/forum/forum-1076-1.html


