


1,274
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享我们在做项目或者研发产品时,部署的程序一般都是二进制文件,甚至还会进行一些混淆(如果jar文件、前端的js文件等),这样可以尽量避免第三方未授权就对我们的程序进行分析,对我们的程序也是一种保护。但是在大数据时代,我们的分析模型大部分都是以sql源文件的方式进行部署发布的,没有任何的保护措施,在某些情况下,我们想要对我们的sql模型进行保护,防止被第三方轻易窃取。
为了更好的保护我们的sql文件,需要做到以下几点:
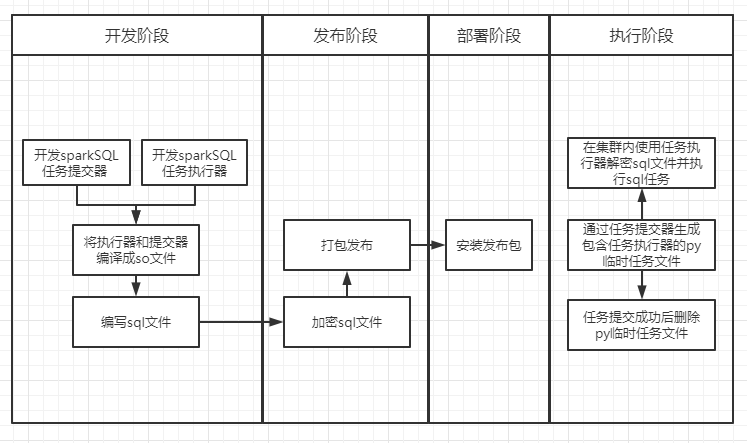
运行在集群内的sql文件解密工具和sql执行工具。部分code(省略解密部分):
import logging
import platform
import sys
# 判断python版本
IS_PYTHON3 = True
if int(sys.version[0]) < 3:
IS_PYTHON3 = False
IS_PYTHON3
# 根据平台选择并加载打包后的sql加密文件及对应的解密库
if platform.machine() == 'aarch64':
if IS_PYTHON3:
sys.path.append('./deps/pycryptodome-3.14.1-py3.8-linux-aarch64.egg')
else:
sys.path.append('./deps/pycryptodome-3.14.1-py2.7-linux-aarch64.egg')
else:
if IS_PYTHON3:
sys.path.append('./deps/pycryptodome-3.14.1-py3.8-linux-x86_64.egg')
else:
sys.path.append('./deps/pycryptodome-3.14.1-py2.7-linux-x86_64.egg')
# 引入解密库
try:
from Crypto.Cipher import AES
from Crypto.PublicKey import RSA
from Crypto import Random
except ImportError as e:
print('Error! Not support AES. Need install: pip install pycryptodome')
sys.exit(1)
def _load_data(sql_file):
'''加载并解密sql文件'''
# 省略解密过程
pass
# 执行sql文件
def main(_spark_session, _sql_file, _start_dt, _end_dt=None):
'''执行sql文件以处理指定账期的数据
:param _spark_session: spark会话
:param _sql_file: 待执行的sql文件
:param _start_dt: 开始账期
:param _end_dt: 结束账期
'''
_spark = _spark_session
_spark_conf = _spark.conf
hql_debug = _spark_conf.get("spark.debug", "false")
debug = True if hql_debug == "true" else False
#pyspark的日志级别强制改为INFO,因为设置成DEBUG, pyspark框架会打印完整SQL
#level = logging.DEBUG if debug else logging.INFO
level = logging.INFO
logging.basicConfig(format="[%(asctime)s] [%(levelname)s] %(message)s", level=level)
start_dt = _start_dt
end_dt = _start_dt
if _end_dt:
end_dt = _end_dt
cycle_len = 1 if not _end_dt else (datetime.datetime.strptime(end_dt, '%Y%m%d') - datetime.datetime.strptime(start_dt, '%Y%m%d')).days + 1
logging.info("当前参数周期ID:%s,%s" % (start_dt, end_dt))
logging.debug("===cycle_len: %d" % cycle_len)
# 加载并解密sql文件
s0 = _load_data(_sql_file)
# 剔除sql文件中的注释
sql_line_lst = []
for sql_line in s0.split('\n'):
if not sql_line.strip().startswith('--'):
if sql_line.strip().strip('\n'):
sql_line_lst.append(sql_line)
if len(sql_line_lst) > 0:
s0 = '\n'.join(sql_line_lst).strip().strip('\n')
# 拆分每个sql语句
sql_list = s0.split(';')
# 逐个语句执行
i = 0
for sql_item in sql_list:
# 替换变量
if sql_item.find("$") >= 0:
sql_item = paramProcess(sql_item, start_dt, end_dt)
sql_item = sql_item.strip().strip('\n')
i = i + 1
logging.info("===SQL-%d: " % i)
logging.info("===" + sql_item.split('\n')[0] + ";")
_spark.sql(sql_item)
1)主要步骤:
2)code:
#!/usr/bin/env python
# -*- coding: utf8 -*-
from __future__ import print_function
from __future__ import unicode_literals
import os
import sys
import logging
import tempfile
import subprocess
import time
IS_PYTHON3 = True
if int(sys.version[0]) < 3:
IS_PYTHON3 = False
# python2
try:
from ConfigParser import ConfigParser
from ConfigParser import NoOptionError
import io
# python3
except ImportError:
from configparser import ConfigParser
from configparser import NoOptionError
class MyConfigParser(ConfigParser):
def __init__(self, defaults=None):
ConfigParser.__init__(self, defaults=defaults)
def optionxform(self, optionstr):
return optionstr
def __exit_handler(signum, frame):
'''程序退出信号捕获函数'''
if IS_PYTHON3:
logging.warning('Catch exit signal: %d, will exit.' % signum)
else:
logging.warn('Catch exit signal: %d, will exit.' % signum)
sys.exit(1)
def find_files(base, suffix):
for root, ds, fs in os.walk(base):
for f in fs:
if f.endswith(suffix):
fullname = os.path.join(root, f)
yield fullname
def main():
# 程序开始时间
time_start = time.time()
msg = """Invalid arguments, Usage:
%s <sql_file> <YYYYMM>
or
%s <sql_file> <YYYYMMDD>
or
%s <sql_file> <YYYYMMDD> <YYYYMMDD>
or
%s <sql_file> <YYYYMMDDHH>
or
%s <sql_file> <YYYYMM> "<driver_memory=4g executor_memory=12g executor_cores=3 num_executors=5 if_avoid_small_files=true if_run_from_break_point=true>"
or
%s <sql_file> <YYYYMMDD> "<driver_memory=4g executor_memory=12g executor_cores=3 num_executors=5 if_avoid_small_files=true if_run_from_break_point=true>"
or
%s <sql_file> <YYYYMMDD> <YYYYMMDD> "<driver_memory=4g executor_memory=12g executor_cores=3 num_executors=5 if_avoid_small_files=true if_run_from_break_point=true>"
or
%s <sql_file> <YYYYMMDDHH> "<driver_memory=4g executor_memory=12g executor_cores=3 num_executors=5 if_avoid_small_files=true if_run_from_break_point=true>"
""" \
% (sys.argv[0], sys.argv[0], sys.argv[0], sys.argv[0], sys.argv[0], sys.argv[0], sys.argv[0], sys.argv[0])
if len(sys.argv) != 3 and len(sys.argv) != 4 and len(sys.argv) != 5:
print(sys.argv)
print(msg)
sys.exit(1)
if len(sys.argv) == 3:
if len(sys.argv[2]) != 6 and len(sys.argv[2]) != 8 and len(sys.argv[2]) != 10:
print(msg)
sys.exit(1)
if len(sys.argv) == 4:
if len(sys.argv[2]) == 8 and (len(sys.argv[3]) == 8 or '=' in sys.argv[3]):
pass
elif (len(sys.argv[2]) == 6 or len(sys.argv[2]) == 10) and '=' in sys.argv[3]:
pass
else:
print(msg)
sys.exit(1)
if len(sys.argv) == 5:
if len(sys.argv[2]) == 8 and len(sys.argv[3]) == 8 and '=' in sys.argv[4]:
pass
else:
print(msg)
sys.exit(1)
deploy_mode = "cluster"
driver_memory = "4g"
executor_memory = "12g"
executor_cores = 3
num_executors = 5
hql_tools_debug = "false"
if_avoid_small_files = "true"
if_run_from_break_point = "false"
if_use_kerberos = "false"
init_bash_env_path = ""
debug = os.getenv('hql_tools_package_debug', 'false').lower() == 'true'
custom_args = ""
if len(sys.argv) > 3:
if len(sys.argv) > 4:
custom_args = sys.argv[4]
if '=' in sys.argv[3]:
custom_args = sys.argv[3]
for arg in custom_args.split():
pairs = arg.split('=')
if pairs[0] == 'hql_tools_debug':
hql_tools_debug = pairs[1].lower()
break
debug = debug if debug else hql_tools_debug == 'true'
level = logging.DEBUG if debug else logging.INFO
logging.basicConfig(format="[%(asctime)s] [%(levelname)s] %(message)s", level=level)
if not IS_PYTHON3 and sys.getdefaultencoding() != 'utf-8':
reload(sys)
sys.setdefaultencoding('utf-8')
import signal
# 捕获终止信号
signal.signal(signal.SIGTERM, __exit_handler)
# 捕获键盘中断信号(Ctrl + C)
signal.signal(signal.SIGINT, __exit_handler)
# 本脚本所在目录
current_dir = os.path.split(os.path.realpath(sys.argv[0]))[0]
sql_file = os.path.join(current_dir, sys.argv[1])
logging.debug("===sql_file: %s" % sql_file)
if not os.path.exists(sql_file):
logging.error("sql file %s not exist" % sql_file)
sys.exit(1)
exec_file = os.path.join(current_dir, "exec_tools.so")
logging.debug("===exec_file: %s" % exec_file)
if not os.path.exists(exec_file):
logging.error("%s not exist" % exec_file)
sys.exit(1)
zip_file = os.path.join(current_dir, "Crypto.zip")
logging.debug("===zip_file: %s" % zip_file)
if not os.path.exists(zip_file):
logging.error("%s not exist" % zip_file)
sys.exit(1)
# 日志目录
log_dir = os.path.join(current_dir, 'logs')
# 日志文件
log_file = os.path.join(log_dir, 'log.out')
# 备份日志文件
log_file_bak = os.path.join(os.path.dirname(log_file), os.path.basename(log_file) + '.bak')
logging.info('Start...')
log_file_bak = os.path.join(os.path.dirname(log_file_bak), '.' + os.path.basename(log_file_bak) + '.swp')
config_file = os.path.join(current_dir, "config.ini")
logging.debug("===config_file: %s" % config_file)
if not os.path.exists(config_file):
logging.error("config file %s not exist" % config_file)
sys.exit(1)
conf = MyConfigParser()
conf.read(config_file)
deploy_mode = conf.get("spark", "mode")
driver_memory = conf.get("spark", "driver_memory")
executor_memory = conf.get("spark", "executor_memory")
executor_cores = conf.get("spark", "executor_cores")
num_executors = conf.get("spark", "num_executors")
tmp_if_avoid_small_files = ""
try:
tmp_if_avoid_small_files = conf.get("other_options", "if_avoid_small_files")
except NoOptionError:
pass
if_avoid_small_files = if_avoid_small_files if tmp_if_avoid_small_files == "" else tmp_if_avoid_small_files.lower()
tmp_if_run_from_break_point = ""
try:
tmp_if_run_from_break_point = conf.get("other_options", "if_run_from_break_point")
except NoOptionError:
pass
if_run_from_break_point = if_run_from_break_point if tmp_if_run_from_break_point == "" else tmp_if_run_from_break_point.lower()
args_dict = {}
for arg in custom_args.split():
pairs = arg.split('=')
args_dict[pairs[0]] = pairs[1]
for key, value in args_dict.items():
if key == 'deploy_mode':
deploy_mode = value
elif key == 'driver_memory':
driver_memory = value
elif key == 'executor_memory':
executor_memory = value
elif key == 'executor_cores':
executor_cores = value
elif key == 'num_executors':
num_executors = value
elif key == 'if_avoid_small_files':
if_avoid_small_files = value.lower()
elif key == 'if_run_from_break_point':
if_run_from_break_point = value.lower()
if deploy_mode != "cluster":
logging.error("程序仅支持yarn cluster模式,请在配置文件%s中设置mode=cluster" % config_file)
sys.exit(1)
py_file = tempfile.mktemp(suffix='.py')
text_context = """#!/usr/bin/env python
# -*- coding: utf8 -*-
from __future__ import print_function
import sys
from pyspark.sql import SparkSession
if __name__ == "__main__":
"""
text_spark_session = ""
items = conf.items('spark_session')
for item in items:
if item[1].isdigit():
text_spark_session = text_spark_session + ".config('%s', %s)" % (item[0], item[1])
else:
text_spark_session = text_spark_session + ".config('%s', '%s')" % (item[0], item[1])
text_context = text_context + """
_spark = SparkSession.builder.appName('""" + os.path.split(py_file)[-1] + """')""" + text_spark_session + """.enableHiveSupport().getOrCreate()
_sc = _spark.sparkContext
sys.path.append('.')
import exec_tools
"""
if len(sys.argv) > 3 and len(sys.argv[2]) == 8 and len(sys.argv[3]) == 8:
main_text = " exec_tools.main(_spark_session=_spark, _sql_file='%s', _start_dt='%s', _end_dt='%s')" % (
sys.argv[1], sys.argv[2], sys.argv[3])
else:
main_text = " exec_tools.main(_spark_session=_spark, _sql_file='%s', _start_dt='%s')" % (
sys.argv[1], sys.argv[2])
text_context = text_context + main_text + """
_spark.stop()
"""
tmp_if_use_kerberos = ""
try:
tmp_if_use_kerberos = conf.get("other_options", "if_use_kerberos")
except NoOptionError:
pass
if_use_kerberos = if_use_kerberos if tmp_if_use_kerberos == "" else tmp_if_use_kerberos.lower()
tmp_init_bash_env_path = ""
try:
tmp_init_bash_env_path = conf.get("other_options", "init_bash_env_path")
except NoOptionError:
pass
init_bash_env_path = init_bash_env_path if tmp_init_bash_env_path == "" else tmp_init_bash_env_path
if if_use_kerberos == "true" and init_bash_env_path == "":
logging.error("if_use_kerberos is true, but init_bash_env_path not configured!")
sys.exit(1)
if IS_PYTHON3:
with open(py_file, mode='w', encoding='utf-8') as f:
f.write(text_context)
else:
with io.open(py_file, mode='w', encoding='utf-8') as f:
f.write(text_context)
random_file = tempfile.mktemp()
if IS_PYTHON3:
with open(random_file, mode='w', encoding='utf-8') as fw, open(log_file_bak, mode='r', encoding='utf-8') as fr:
for line in fr:
fw.write(line)
else:
with io.open(random_file, mode='w', encoding='utf-8') as fw, io.open(log_file_bak, mode='r', encoding='utf-8') as fr:
for line in fr:
fw.write(line)
command_text = conf.get("spark", "spark_file") \
+ " --queue " + conf.get("spark", "queue") \
+ " --master " + conf.get("spark", "master") \
+ " --deploy-mode " + deploy_mode \
+ " --driver-memory " + driver_memory \
+ " --executor-memory " + executor_memory \
+ " --executor-cores " + executor_cores \
+ " --num-executors " + num_executors \
+ " --conf spark.sql.file=" + os.path.split(sql_file)[-1] \
+ " --conf spark.random.file=" + os.path.split(random_file)[-1] \
+ " --conf spark.config.file=" + os.path.split(config_file)[-1] \
+ " --conf spark.yarn.dist.archives=" + zip_file + "#deps" \
+ " --conf spark.yarn.appMasterEnv.PYTHONPATH=deps" \
+ " --conf spark.executorEnv.PYTHONPATH=deps"
items = conf.items('spark_conf')
for item in items:
if (item[1].strip() != "" and "kerberos" not in item[0]) \
or (item[1].strip() != "" and "kerberos" in item[0] and if_use_kerberos == "true"):
command_text = command_text + " --conf " + item[0] + "=" + item[1]
if debug:
command_text = command_text + " --conf spark.debug=true"
if if_avoid_small_files == "true":
command_text = command_text + " --conf spark.if.avoid.small.files=true"
else:
command_text = command_text + " --conf spark.if.avoid.small.files=false"
if if_run_from_break_point == "true":
command_text = command_text + " --conf spark.if.run.from.break.point=true"
else:
command_text = command_text + " --conf spark.if.run.from.break.point=false"
command_text = command_text + " --files " + sql_file + "," + random_file + "," + config_file \
+ " --py-files " + exec_file + "," + zip_file \
+ " " + py_file + " " + sys.argv[1] + " " + sys.argv[2]
if len(sys.argv) > 3 and len(sys.argv[2]) == 8 and len(sys.argv[3]) == 8:
command_text = command_text + " " + sys.argv[3]
if if_use_kerberos == "true":
command_text = "source " + init_bash_env_path + " && " + command_text
logging.debug("===command: %s" % command_text)
process = subprocess.Popen(command_text, stdout=subprocess.PIPE, stderr=subprocess.STDOUT, shell=True)
for stdout_line in iter(process.stdout.readline, b''):
logging.info(stdout_line.decode('utf-8').strip('\n'))
# if stdout_line.find("Uploading resource file:/tmp/spark-") > -1:
if stdout_line.decode('utf-8').find("Submitted application application_") > -1:
if os.path.isfile(py_file):
os.remove(py_file)
if os.path.isfile(random_file):
os.remove(random_file)
process.stdout.close()
code = process.wait()
code = code if code == 0 else 1
# 程序结束时间
time_end = time.time()
# 程序运行时间(s)
time_elapsed = int(time_end - time_start)
if code == 0:
logging.info('Execute success. Cost %d seconds.' % time_elapsed)
else:
logging.error('Execute failure. Cost %d seconds.' % time_elapsed)
sys.exit(code)
将任务执行器exec_tools.py和任务提交器hql_tools.py编译成so文件,防止加密解密过程泄露。
from __future__ import print_function
from distutils.core import setup
from distutils.extension import Extension
from Cython.Distutils import build_ext
import sys
PY3 = True
if int(sys.version[0]) < 3:
PY3 = False
ext_modules = [
Extension("hql_tools", ["hql_tools.py"]),
Extension("exec_tools", ["exec_tools.py"]),
]
for e in ext_modules:
e.cython_directives = {'language_level': "3" if PY3 else "2"}
setup(
name='hql_tools',
cmdclass={'build_ext': build_ext},
ext_modules=ext_modules
)
#!/bin/bash
export ;PYTHON_INTERPRETER=${PYTHON_INTERPRETER:-python}
CURR_DIR=$(cd $(dirname $0);pwd)
ARCH=$(arch)
OUTPUT_DIR=$CURR_DIR/so/$ARCH
log_info ()
{
echo "[`date +"%Y-%m-%d %H:%M:%S"`] $* "
}
log_error ()
{
echo -e "\033[31m[`date +"%Y-%m-%d %H:%M:%S"`] $*\033[0m"
}
cd $CURR_DIR
$PYTHON_INTERPRETER setup.py build_ext --inplace
if [ $? -eq 0 ];then
log_info "Build so success."
if [ ! -e "$OUTPUT_DIR" ];then
mkdir -p "$OUTPUT_DIR"
fi
if [ -e "$OUTPUT_DIR/hql_tools.so" ];then
rm -f "$OUTPUT_DIR/*.so"
fi
log_info "Copy so file to $OUTPUT_DIR"
cp *.so "$OUTPUT_DIR"
rm -fr *.so *.c build
else
log_error "Build so failed!"
fi
1)步骤
2)code(省略加密过程)
#!/usr/bin/env python
#encoding:utf-8
# 文件名 : package.py
from __future__ import print_function
import os
import sys
import logging
import random
import base64
import time
import py_compile
import shutil
from Crypto.Cipher import AES
PY3 = True
if int(sys.version[0]) < 3:
PY3 = False
debug = os.getenv('hql-tools.package.debug','false').upper() == 'TRUE'
def _generatefile_names(in_dir, out_files):
'''生成目录下所有文件名列表,并输出到out_files参数'''
for root, dirs, files in os.walk(in_dir):
# 遍历文件
for f in files:
out_files.append(os.path.join(root, f))
def __exit_handler(signum, frame):
'''程序退出信号捕获函数'''
if PY3:
logging.warning('Catch exit signal: %d, will exit.' % signum)
else:
logging.warn('Catch exit signal: %d, will exit.' % signum)
sys.exit(1)
def _enc(key, text):
'''根据密钥对文本进行加密
:param key: str 加密密钥
:param text: str 待加密文本
:return str 加密后的文本
'''
# 省略加密过程
pass
def _find_files(base, suffixes):
for root, ds, fs in os.walk(base):
for f in fs:
if '.' + f.split('.')[-1] in suffixes:
fullname = os.path.join(root, f)
yield fullname
def _find_files_from_name(base, name):
for root, ds, fs in os.walk(base):
for f in fs:
if f == name:
fullname = os.path.join(root, f)
yield fullname
def package(py_client_version, py_server_version, client_arch, server_arch, in_dirs):
'''将输入目录下的所有文件打包'''
# 设置日志配置信息
logging.basicConfig(format="[%(asctime)s] [%(levelname)s] %(message)s", level=logging.INFO)
import signal
# 捕获终止信号
signal.signal(signal.SIGTERM, __exit_handler)
# 捕获键盘中断信号(Ctrl + C)
signal.signal(signal.SIGINT, __exit_handler)
# 本脚本所在目录
current_dir = os.path.dirname(sys.argv[0])
# 支持的架构列表
archs = []
# 遍历so目录,给每个架构打包一个结果
so_dir = os.path.join(current_dir, 'so')
for root,dirs,files in os.walk(so_dir):
if len(dirs) > 0:
archs = dirs
break
if len(archs) == 0:
logging.error('No arch found in %s' % so_dir)
return -1
#考虑到客户端架构和服务端机构可能不一样,所以需要针对客户端服务器架构组合分别打包(针对so和zip)
#目前就两种架构x86_64和aarch64,所以需要打4个包
#架构组合,客户端架构-服务器架构
# archs_pair = []
# for arch_client in archs:
# for arch_server in archs:
# archs_pair.append(arch_client + '-' + arch_server)
#客户端和服务端cpu架构通过命令行参数传入,不再考虑所有组合
archs_pair = [client_arch + "-" + server_arch]
name = 'hql-tools-' + py_client_version + '-' + py_server_version
# 输出目录
out_root_dir= os.path.join(current_dir, 'out')
out_dir = os.path.join(out_root_dir, name)
out_data_dir = os.path.join(out_dir, 'logs')
if os.path.exists(out_dir): shutil.rmtree(out_dir)
if not os.path.exists(out_data_dir): os.makedirs(out_data_dir)
# 将execute_hql.sh/config.ini复制过去
shutil.copy(os.path.join(current_dir, 'execute_hql.sh'), out_dir)
shutil.copy(os.path.join(current_dir, 'config.ini'), out_dir)
out_file_name = os.path.join(out_data_dir, '.sql.dat')
key = '123456' # 加密密钥,根据自己的设计进行隐藏处理
with open(out_file_name, 'w') as fout:
idx_in_dir = 0
for in_dir in in_dirs:
idx_in_dir += 1
file_names = []
_generatefile_names(in_dir, file_names)
dir_name = os.path.dirname(in_dir)
for line in _generate_file_content_iter(out_dir, key, file_names, len(dir_name)+1, len(in_dirs), in_dir, idx_in_dir):
fout.write(line)
fout.write('\n')
execute_hql_file_name = 'execute_hql.py'
execute_hql_file = os.path.join(current_dir, execute_hql_file_name)
out_execute_hql_file = os.path.join(out_dir, execute_hql_file_name)
if os.path.exists(out_execute_hql_file): os.remove(out_execute_hql_file)
out_execute_hql_file += 'o'
if os.path.exists(execute_hql_file):
py_compile.compile(execute_hql_file,out_execute_hql_file,doraise=True)
else:
logging.error('File not exists: ' + execute_hql_file)
# 给每个架构生成压缩包
for arch_pair in archs_pair:
for f in _find_files(out_dir, ['.so','.egg','.zip']):
os.remove(f)
arch_client = arch_pair.split('-')[0]
arch_server = arch_pair.split('-')[1]
for f in _find_files(os.path.join(so_dir, arch_server, py_server_version), ['.so','.egg','.zip']):
shutil.copy(f, out_dir)
for f in _find_files_from_name(os.path.join(so_dir, arch_client, py_client_version), 'hql_tools.so'):
shutil.copy(f, out_dir)
compress_file_name = shutil.make_archive(os.path.join(out_root_dir,'%s-%s' % (name, arch_pair)), 'gztar', out_root_dir, name)
logging.info('Output compress file: %s' % compress_file_name)
# 清理中间结果
if not debug: shutil.rmtree(out_dir)
else: shutil.copy(os.path.join(os.path.join(current_dir, 'build_so'), 'hql_tools.py'), out_dir)
def _load_file_content(file_name):
with open(file_name, 'r') as fin:
return fin.read()
def _generate_file_content_iter(out_dir,key,file_names, parent_dirname_len, len_in_dir, in_dir, idx_in_dir):
'''将文件名对应的文件内容加密并返回 -> str'''
idx = 0
size = len(file_names)
for file_name in file_names:
idx += 1
logging.info('[ %d/ %d ] [%s] [ %d/%d ] Process file: %s' % ( idx_in_dir, len_in_dir, in_dir, idx, size, file_name ))
content = _load_file_content(file_name)
short_file_name = file_name[parent_dirname_len:]
out_file_name = os.path.join(out_dir, short_file_name)
out_file_dir = os.path.dirname(out_file_name)
if not os.path.exists(out_file_dir): os.makedirs(out_file_dir)
if len(content) > 0:
# 先生成一个替换文件
out_content = '1' * random.randint(1000,10000) #rsa.exportKey()
with open(out_file_name, 'w') as fout:
fout.write(_enc(str(time.time()),_enc(str(time.time()), out_content)))
# 再输出加密内容
data = _enc(key, short_file_name.replace('/','\\').ljust(1024) + content)
yield data
if __name__ == "__main__":
if len(sys.argv) < 6 \
or (sys.argv[1] !='py27' and sys.argv[1] !='py38')\
or (sys.argv[2] !='py27' and sys.argv[2] !='py38')\
or (sys.argv[3] !='aarch64' and sys.argv[3] !='x86_64')\
or (sys.argv[4] !='aarch64' and sys.argv[4] !='x86_64'):
print('Invalid arguments. ')
print(('Usage: %s <py_client_version> <py_server_version> <client_arch> <server_arch> <in_dir1> [in_dir2] ...' % sys.argv[0]))
print("<py_client_version> in 'py27/py38'")
print("<py_cluster_version> in 'py27/py38'")
print("<client_arch> in 'aarch64/x86_64'")
print("<server_arch> in 'aarch64/x86_64'")
sys.exit(1)
if (PY3 and sys.argv[1] =='py27') or (not PY3 and sys.argv[1] =='py38'):
version = sys.version
version = version[0:version.find('(')]
print("py_client_version " + sys.argv[1] + " not accord with the python interpreter version " + version)
sys.exit(1)
if not PY3 and sys.getdefaultencoding() != 'utf-8':
reload(sys)
sys.setdefaultencoding('utf-8')
py_client_version = sys.argv[1]
py_server_version = sys.argv[2]
client_arch = sys.argv[3]
server_arch = sys.argv[4]
in_dirs = sys.argv[5:]
package(py_client_version, py_server_version, client_arch, server_arch, in_dirs)
cd build_so
OLD_DIR=$(pwd)
#如果是编译成python2的so包,则这里解释器设置成python2的,如果是编译成python3的so包,则这里解释器设置成python3的
export ;PYTHON_INTERPRETER=python
bash build_so.sh
python package.py <py_client_version> <py_server_version> <client_arch> <server_arch> <待加密目录1> <待加密目录2>...


