


79,500
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享前言:openGauss内核虽然源于PostgreSQL,但是华为在多个维度进行了深度的改进。本文从源目录的组织结构入手来研究openGauss,笔者在不断深入的研究中不禁惊叹于openGauss先进且合理的源码组织结构,这里面体现了华为对于数据库架构和技术的深刻理解,值得我们反复品味和学习!
从源码入手是研究一款开源数据库的重要方法之一,对源代码的理解可以从宏观和微观两个层面入手。为了避免陷入局部代码之中,第一步我们应该抛开微观层面上具体的代码和实现细节,从宏观层面上的目录和组织结构入手,来窥探整个数据库的架构和实现逻辑,以及开发人员在实现层面的考量。对源代码的全局结构有了清晰的认识之后,我们便可以对查询优化、存储、事务、进程管理、内存管理等各个功能模块的代码进行深入的研究。
openGauss内核源于PostgreSQL 9.2.4版本,因此本文中我们通过对比的方式来探寻openGauss和PostgreSQL在源码目录和组织结构的异同。
首先我们需要弄清楚openGauss的产品定位,以及它和PostgreSQL的关系,这有助于我们理解openGauss的整个源码体系和结构。openGauss是华为于2020年6月开源的单机版GaussDB。华为决定自主研发GaussDB时为什么选择了PG,而不是其他的开源数据库如MySQL,我们或许可以从GaussDB的发展历程中寻找答案。
GaussDB并非是一个产品,而是一系列产品的统称,目前GaussDB产品线主要包括GaussDB T (OLTP)和GaussDB A (OLAP)。其中GaussDB T的前身是GaussDB 100,是华为自2007年开始在自研内存数据库基础上全面改造而来的一款分布式数据库,此前华为由于在电信计费领域的需求而自主研发了一款内存数据库。GaussDB A的前身是GaussDB 200,是华为自2011年开始基于PostgreSQL 9.2.4自主研发的一款具备多模分析及混合负载能力的大规模并行处理分布式数据库,支持行列混合存储以及线程化,支持高达2048节点的集群规模,提供PB(Petabyte)级数据分析能力、多模分析能力和实时处理能力。
openGauss内核虽然源于PostgreSQL,但华为在开发过程中结合企业级场景需求,通过C++语言(PostgreSQL是用C语言写的)对80+%的数据库内核代码进行了重构,修改和新增了70万行核心代码。着重在整体架构、数据库内核三大引擎 (优化器、执行引擎、存储引擎)、事务、以及鲲鹏芯片等方面做了大量的深度优化。
例如,通过引入向量化引擎和编译执行引擎等从多个维度重构了执行引擎,通过列存及自适应压缩等全新重构了存储引擎。除了数据库内核,在高可用、数据库安全和AI特性方面,openGauss数据库也做了极大的增强。PG11.3版本数据库中共有290个数据库参数,而openGauss目前有500多个数据库参数,每个参数对应一个数据库内核功能,所以可以看到华为对PG的内核做了非常大的改造和增强。
做数据库内核开发的技术难度很大,哪怕开发团队对内核架构与机制的制定上出现了丝毫的问题,上线后都极有可能会出现后果严重。有时一旦确定项目无法进行下去,甚至可能需要推倒重来。所以基于一款已经成熟的开源数据库进行自主研发就是一个很好的选择。那为什么选择PG而不是在互联网公司已经得到广泛使用的MySQL,可能是华为在调研分析后看中了PG各方面优秀的特性:
我觉得GaussDB发展的10年历程说明华为选择PG是一个十分正确的选择。目前PG的用户增长迅速,生态发展的也比MySQL要好,这说明越来越多的公司和开发者都意识到PG的确是一款优秀的开源数据库。其实在早年间,也有一些公司曾在MySQL上进行自主研发,比如阿里巴巴之前在MySQL社区版的基础上做了大量的性能与功能的优化改进,自主研发了AliSQL用于支撑淘宝双十一等业务,但相比PG来说,这样二次研发的成功案例要少很多。
至此我们理清了openGauss和PostgreSQL的联系,接下来我们一起通过对比二者源代码的组织结构,来窥探二者在数据库架构和实现方面的异同,这样对比学习的方式有助于同时加深我们的二者的认识。
本文中我们进行对比的源代码版本分别是PostgreSQL 9.2.4 (发布于2013年4月4日,截至2020年7月9日PG已更新到14beat2版本)和openGauss 2.0.1 (截至2020年7月9日发布的最新版)。
进入PostgreSQL和openGauss的源码目录后,可以看到第一级目录下都有一个src目录,该目录就是数据库源代码目录。本文中我们重点关注src目录下的代码结构,因为src目录是整个数据库的核心代码。
了解传统的关系数据库管理系统(RDBMS)的架构能帮助我们更好地理解源代码的各个模块和其组织结构,下图显示了一个RDBMS的架构和主要组件。
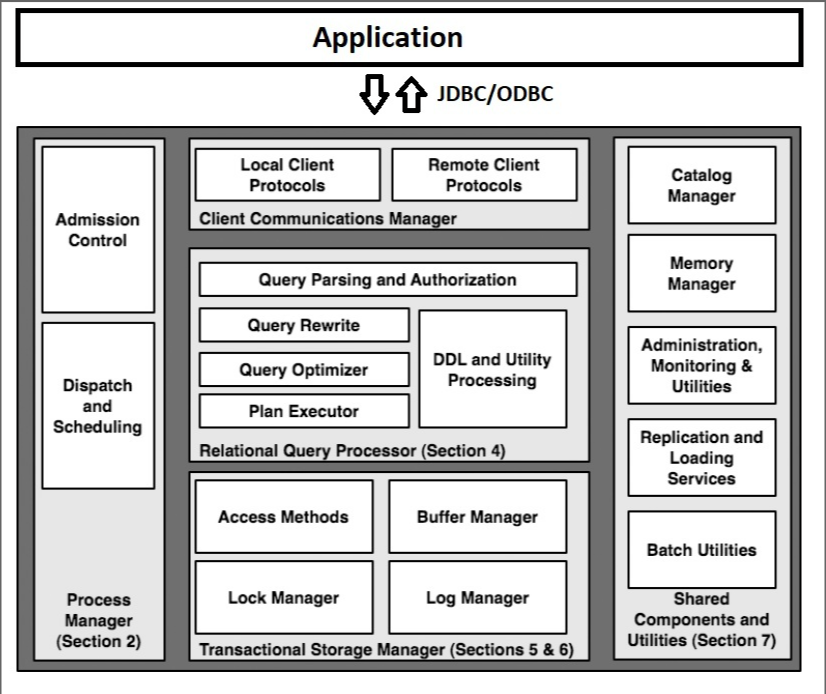
图片来源于经典论文: Hellerstein, J. M., Stonebraker, M., & Hamilton, J. (2007). Architecture of a Database System. Foundations and Trends® in Databases, 1(2), 141-259.
图中显示了一个RDBMS包含的5个主要的功能模块:
考虑一个简单而典型的数据库查询应用实例-“查询某次航班的所有旅客名单”,这个操作所引发的的查询请求大致按如下方式进行处理: 1. 机场登机口的PC机(客户端)调用API与DBMS的客户端通信管理器(Client Communications Manager)建立网络连接; 1. 在收到客户端的请求后,DBMS必须为之分配一个计算线程。系统必须确保该线程的数据以及控制输出是通过通信管理器与客户端连接的,这些工作由进程管理器(Process Manager)来管理。 2. 分配控制进程之后,接下来便可以通过关系查询处理器(Relational Query Processor)来处理查询了。该模块会检查用户是否有查询权限,然后将用户的SQL语句编译为查询计划,并将查询计划交给查询执行器来执行。 3. 在查询计划的底层,会有若干操作从数据库请求数据。这些操作通过事务和存储管理器(Transactional Storage Manager)读取数据并保证事务的“ACID”性质。此外还有一个缓冲管理器,用来控制内存缓冲区和磁盘之间的数据传输。 4. 最后,查询处理器将数据库的数据组织成结果元组,结果元组生成后被放入客户通信管理器的缓冲区中,然后该通信管理器将结果发送给调用者。
上述例子我们没有提到共享组件和工具(Shared Components and Utilities), 但它们对于一个功能完整的DBMS是十分重要的,这些组件独立运行于任何查询,它们使数据库保持稳定性和整体性。比如目录管理器和内存管理器在传输数据时被作为工具来调用,在认证、解析以及查询优化过程中,查询处理器都会用到目录。同样,内存管理器也广泛应用于整个DBMS运行过程中的动态内存分配和释放。
PostgreSQL-9.2.4\src
├─backend (后端代码,包括解析器、优化器、执行器、存储、命令、进程等)
├─bin (psql等命令的代码)
├─include (头文件)
├─interfaces (前端代码)
├─makefiles (平台相关的make的设置值)
├─pl (存储过程语言的代码)
├─port (平台移植相关的代码)
├─template (平台相关的设置值)
├─test (测试脚本)
├─timezone (时区相关代码)
├─tools (开发工具和文档)
└─tutorial (教程)
openGauss-2.0.1\src
├─bin (gsql等命令的代码)
├─common (公共功能模块代码)
├─gausskernel (高斯内核代码)
├─include (头文件)
├─lib (库文件,包括)
├─makefiles (平台相关的make的设置值)
├─test (测试脚本)
└─tools (开发工具和文档)
与PostgreSQL相比,openGauss在src目录下的组织方式有以下变化:
接下来我们会对以上的变化进行详细的说明。
由于PostgreSQL采用C/S(客户机/服务器)模式结构,客户端为前端(Frontend),服务器端为后端(Backend),所以PostgreSQL的backend目录是整个数据库服务的核心代码目录。
openGauss对PG的backend目录进行了功能上的细化分类,将optimizer、executor、storage等高斯内核的核心功能组件移动到新建的gausskernel目录下,其他一些公共功能模块则被移动到新建的common目录下。
PostgreSQL-9.2.4\src
├─backend (后端源码目录)
│ ├─access (各种数据的存储访问方法,如支持堆、索引等数据存取)
│ ├─bootstrap (支持Bootstrap运行模式,用来创建初始的模板数据库)
│ ├─catalog (系统目录)
│ ├─commands (执行非计划查询的SQL命令,如创建表命令等)
│ ├─executor (执行器,执行生成的查询计划)
│ ├─foreign (FDW:Foreign Data Wrapper处理)
│ ├─lib (共同函数)
│ ├─libpq (处理与客户端通信库函数,几乎所有的模块都依赖它)
│ ├─main (主程序模块,负责将控制权转到Postmaster进程或Postgres进程)
│ ├─nodes (定义系统内部用到的节点、链表等结构,以及处理这些结构的函数)
│ ├─optimizer (优化器,根据查询树创建最优的查询路径和查询计划)
│ ├─parser (解析器,将SQL查询转化为内部查询树)
│ ├─po
│ ├─port (平台兼容性处理相关的函数)
│ ├─postmaster (监听用户请求的进程,并控制Postgres进程的启动和终止)
│ ├─regex (正规表达式库及相关函数)
│ ├─replication (流复制)
│ ├─rewrite (查询重写)
│ ├─snowball (全文检索相关)
│ ├─storage (存储管理,包括内存、磁盘、缓存等管理)
│ ├─tcop (Postgres服务进程的主要处理部分,调用parser、optimizer、executor和commands中的函数来执行客户端提交的查询)
│ ├─tsearch (全文检索)
│ └─utils (各种支持函数,如错误报告、各种初始化操作等)
openGauss-2.0.1\src
├─common (公共功能模块代码)
│ ├─backend
│ │ ├─catalog
│ │ ├─client_logic
│ │ ├─lib
│ │ ├─libpq
│ │ ├─nodes
│ │ ├─parser
│ │ ├─pgxc_single
│ │ ├─po
│ │ ├─port
│ │ ├─regex
│ │ ├─snowball
│ │ ├─tsearch
│ │ └─utils
│ ├─interfaces
│ ├─pgxc
│ ├─pl
│ ├─port
│ ├─template
│ ├─timezone
│ └─tutorial
openGauss-2.0.1\src
├─gausskernel (高斯内核)
│ ├─bootstrap
│ ├─cbb
│ ├─dbmind (AI4DB和DB4AI功能模块)
│ ├─optimizer
│ ├─process (进程和线程管理模块)
│ ├─runtime (执行器模块)
│ ├─security
│ └─storage
openGauss对gausskernel内核部分代码进行了较大的变动,而内核又是数据库最核心最重要的部分,所以我们需要重点关注内核部分的源代码结构。PostgreSQL中的内核代码都在backend目录下,而openGauss的内核代码则主要在gausskernel目录下(从gausskernel的名称就可以看出来)。
openGauss之所以创建gausskernel目录,我想可能有以下几点原因: 1. 创建内核目录彰显了openGauss对于内核的重视,而不是像PG一样将所有的功能模块都放到backend目录下; 2. 突出华为在数据库内核方面所作的重大改进和优化工作; 3. 单独将内核部分代码单独提出来可以方便项目开发和后期代码维护。
gausskernel在代码目录的组织结构上主要有以下变化:
openGauss将PG的backend目录的公共功能模块都统一移动到新建的common目录下,这样做的原因可能有两点: 1. openGuass认为这些模块是数据库系统共有的公共组件或者功能模块,比如PG中backend目录下的catalog、lib、libpq等模块; 2. openGuass基本都保留了这些模块的接口和公共函数代码,所以openGauss与现有的PG生态兼容性较好。openGauss仅对这些代码做了适当优化,所以单独创建common目录可以和gausskernel这样修改较大的模块区分开来。
注意openGauss也有backend目录,但是该目录只保留了一些公用的功能模块,并且被移动到了common目录下。
PostgreSQL-9.2.4\src
├─backend
│ ├─commands
│ ├─optimizer
│ │ ├─geqo (遗传算法查询优化)
│ │ ├─path (使用parser的输出创建查询路径)
│ │ ├─plan (优化path输出生成查询计划)
│ │ ├─prep (处理特殊的查询计划)
│ │ └─util (优化器支持函数)
│ ├─rewrite
openGauss-2.0.1\src
├─gausskernel (高斯内核)
│ ├─optimizer
│ │ ├─commands
│ │ ├─geqo
│ │ ├─path
│ │ ├─plan
│ │ ├─prep
│ │ ├─rewrite
│ │ └─util
openGuass在优化器目录中的变化主要是将PG中和optimzier同一目录级别的commands和rewrite移动到optimzier目录下,这说明openGauss将命令模块和查询重写模块归为优化器的一部分。
在架构层面PostgreSQL是多进程架构,为了提高并发度,openGauss将其进一步优化成了多线程架构,openGauss属于单进程多线程模型的数据库。
PostgreSQL-9.2.4\src
├─backend
│ ├─postmaster
│ ├─tcop
openGauss-2.0.1\src
├─gausskernel
│ ├─process
│ │ ├─datasource
│ │ ├─globalplancache
│ │ ├─job
│ │ ├─main
│ │ ├─postmaster
│ │ ├─stream
│ │ ├─tcop
│ │ └─threadpool (线程池)
从上面的对比可以看出,openGauss在gausskernel目录下新建了process目录,将PG的postmaster和tcop目录移动到process目录下,并且增加了很多的其他的功能模块,比如线程池threadpool模块等。
PostgreSQL-9.2.4\src
├─backend
│ ├─executor
openGauss-2.0.1\src
├─gausskernel
│ ├─runtime
│ │ ├─codegen (代码生成)
│ │ │ ├─codegenutil
│ │ │ ├─executor
│ │ │ ├─llvmir (LLVM动态编译)
│ │ │ └─vecexecutor
│ │ ├─executor
│ │ └─vecexecutor (向量化执行引擎)
│ │ ├─vecnode
│ │ ├─vecprimitive
│ │ └─vectorsonic
从上面的对比可以看出,openGauss在gausskernel目录下新建了runtime目录,将PG的executor目录移动到runtime目录下,并且增加了codegen和vecexecutor两个目录。codegen目录中用到了业界流行的开源编译框架LLVM,用于生成高性能的代码来进一步提升性能;vecexecutor目录则包含了向量化执行引擎的相关代码,用于提升SQL引擎的计算性能。
代码生成和向量化执行是当前学术界和工业界用于提升SQL计算引擎性能的两种有效方法,而这两种方法在openGauss中都已经实现了。
openGauss将从backend目录下的access目录移动到gausskernel/storag目录下,这是因为对数据的访问是和数据库的存储结构密切相关的。数据一般存储在磁盘上的,所以数据在磁盘上组织形式决定了访问数据的效率,比如是堆文件还是顺序文件,以及读取时是顺序读取还是通过索引来读取。
PostgreSQL-9.2.4\src
├─backend
│ ├─access
│ │ ├─common (公共存取函数)
│ │ ├─gin
│ │ ├─gist (可自定义的存取方法)
│ │ ├─hash (哈希用于存取表)
│ │ ├─heap (堆用于存取表)
│ │ ├─index (索引存取表)
│ │ ├─nbtree (Lehman and Yao的btree管理算法)
│ │ ├─spgist
│ │ └─transam (事务管理器)
openGauss-2.0.1\src
├─gausskernel
│ └─storage
│ ├─access
│ │ ├─cbtree
│ │ ├─common
│ │ ├─dfs
│ │ ├─gin
│ │ ├─gist
│ │ ├─hash
│ │ ├─hbstore
│ │ ├─heap
│ │ ├─index
│ │ ├─nbtree
│ │ ├─obs
│ │ ├─psort
│ │ ├─redo
│ │ ├─rmgrdesc
│ │ ├─spgist
│ │ ├─table
│ │ └─transam
PostgreSQL-9.2.4\src
├─backend
│ ├─storage
│ │ ├─buffer (行存储共享缓冲区模块)
│ │ ├─file (文件操作和虚拟文件描述符模块)
│ │ ├─freespace (行存储空闲空间模块)
│ │ ├─ipc (进程间通信模块)
│ │ ├─large_object (大对象模块)
│ │ ├─lmgr (锁管理模块)
│ │ ├─page (页面模块)
│ │ └─smgr (存储介质管理模块)
openGauss-2.0.1\src
├─gausskernel
│ └─storage
│ ├─access
│ ├─buffer
│ ├─bulkload (外表批量导入模块)
│ ├─cmgr (列存储只读共享缓冲区模块)
│ ├─cstore (列存储访存模块)
│ ├─dfs (外表服务器连接模块)
│ ├─file
│ ├─freespace
│ ├─ipc
│ ├─large_object
│ ├─lmgr
│ ├─mot (内存引擎模块)
│ ├─page
│ ├─remote (备机页面修复模块)
│ ├─replication
│ └─smgr
从上面的对比可以看出,openGauss在storage目录的变化主要包括:
openGauss-2.0.1\src
├─gausskernel
│ ├─security
│ │ ├─gs_policy
│ │ ├─iprange
│ │ └─keymanagement
openGauss在gausskernel目录下新建了security目录,用于存放数据库安全的相关功能模块的代码,比如安全认证、角色管理、审计与追踪以及数据加密等模块的源代码。
AI与数据库结合是近年的研究热点,据我所知,即使最新版的PostgreSQL和MySQL目前仍然不具备这样的功能,可以说openGauss在这个领域走在了业界前列。AI与数据库结合的相关源代码都在dbmind目录下。值得注意的是dbmind位于gausskernel下说明华为是将数据库的AI能力作为未来数据库内核的一种基础能力来进行构建的。
openGauss-2.0.1\src
├─gausskernel
│ ├─dbmind (AI4DB和DB4AI模块)
│ │ ├─deepsql (DB4AI: 库内AI算法)
│ │ │ └─madlib_modules (开源的MADlib机器学习框架)
│ │ └─tools (AI4DB工具集)
│ │ ├─anomaly_detection (数据库指标采集、预测与异常监控)
│ │ ├─index_advisor (索引推荐)
│ │ ├─predictor (AI查询时间预测)
│ │ ├─sqldiag (慢SQL诊断发现)
│ │ └─xtuner (参数调优与诊断)
AI和数据库结合一般可分为AI4DB与DB4AI两个方向:

