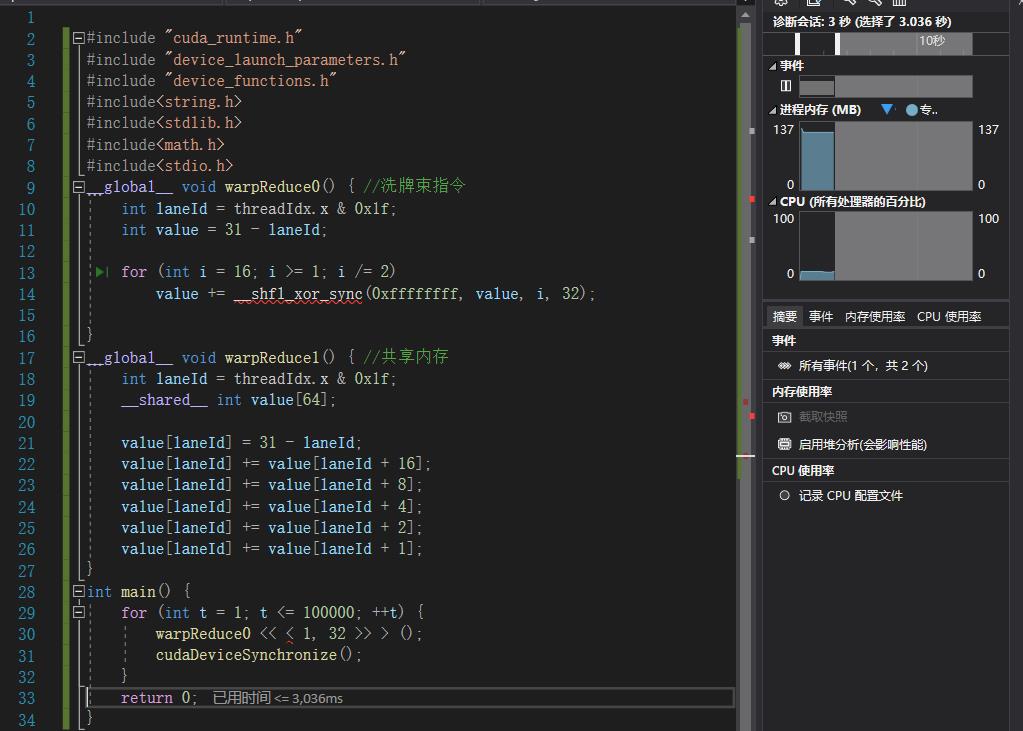
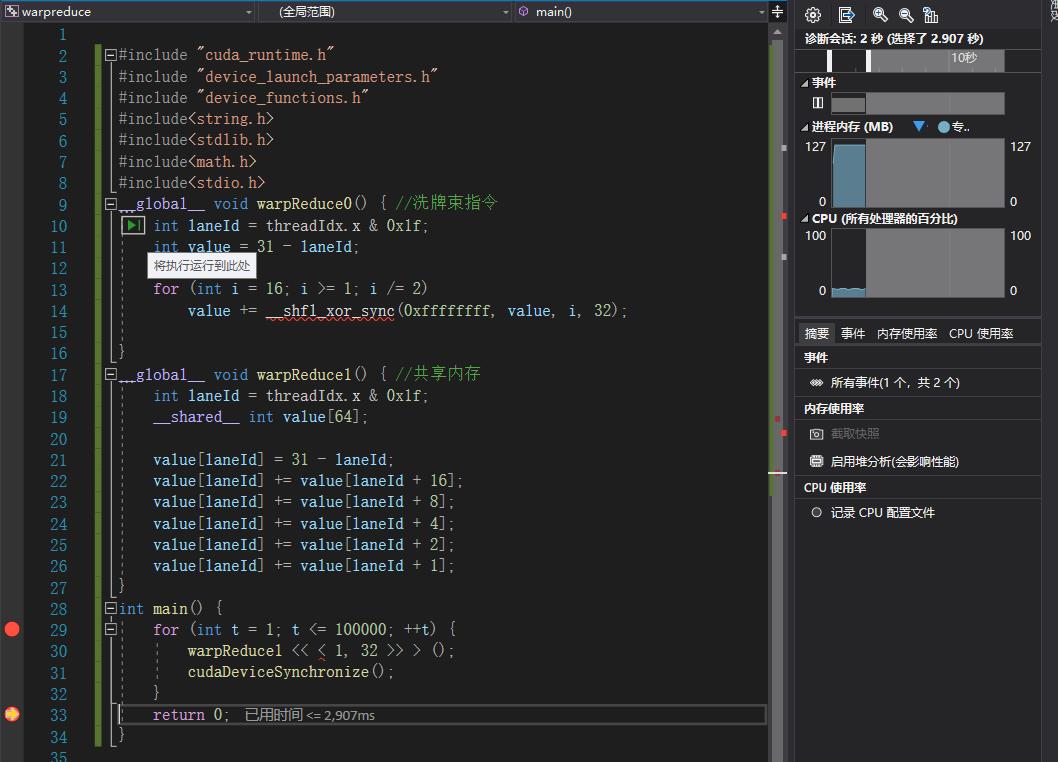
我做了一个测试,分别用洗牌束指令与共享内存进行归约计算,一个block内,循环做100000次,结果如下:
为什么洗牌束指令的速度不如shared memory?按照cuda操作指南的描述,洗牌束指令应该更快的,是程序有问题么?
591
社区成员
2,925
社区内容
加载中
试试用AI创作助手写篇文章吧



 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享