


442
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享面向对象设计与构造课程第一单元的主题是表达式,经历了三次迭代式的作业。第一次作业引入表达式、项、因子等概念,要求我们实现表达式的括号展开。首先对要求进行分析,可以把作业分为三个步骤:表达式解析、进行运算、输出要求形式。通过前置的引导,我了解到递归下降这一概念。通过学习指导书与公众号,我明白了词法、文法等概念,以及模板式的Lexer、Parser两个类的基本内容与实现方式,可以将输入的表达式解析为Exp(式子)/Term(项)/Power(幂)/Var(单变量)/Con(常数)等层次化的类结构,这些类继承于父类Factor(或接口,因人而异),这种继承的关系便于统一化管理。
详细来说存储结构的设计,首先摆在面前一个表达式,也就是Exp类,它包含由 + 连接的许多(或一个)Term,于是它拥有一个HashSet(我第一次作业使用是Arraylist,由于是无序的,所以后来修改成Hashset),里面存的是terms。Term是由Power由 * 连接,于是它拥有一个Hashset,里面存的是powers。Power包括底数和指数,底数是Factor(可能是Exp或Var或Con),指数是Con(我用一个ArrayList,但它只有两项,这里有待商榷,可能使用两个变量而非数组更正常)。Var存x/y/z, Con存一个整数(我是使用String来存)。这就完成一个闭环,递归的终止条件是最后的Power的底数是Var/Con。
对于如何进行运算,依赖于我们得到的层次化结构,已经可以对于运算的步骤更为清楚了解,解析方法叫做递归下降,自然可以想到递归式地进行运算,表达式展开的运算无非是一个核心,即去括号,那我们可能需要重新定义各个层次因子类的加法,乘法、乘方等运算,或者是像实验一中一样,设计了Operate算子类,Add,Mult等类继承它。我在学习了上一届博客后,选择使用Poly类这个规范化类,解析出的Exp等类均实现一个toPoly方法,顶层的toPoly方法调用下层的toPoly方法,运算则使用Poly类中定义的addPoly, mulPoly等方法实现,达到拆括号目的。Poly拥有一个<HashMap<HashMap<String, Integer>>, BigInteger>的结构,它恰好代表一个多元多项式。结构的value代表多项式的系数,结构的key是一个hashmap,举个例子,它存了类似<x,1>、<y,2>、<z,3>的东西就代表x^1*y^2*z^3, 由于是string的键,这也适用与后续迭代的sin(x)或sin((sin(y)+1))等不同的底数的储存。
private final HashMap<HashMap<String, Integer>, BigInteger> map;
public Poly() {
this.map = new HashMap<>();
}
我们把表达式转化为Poly形式后,既然明白它代表一个多项式,那么遍历这个map就容易得到poly的字符串形式,即toString方法。
总体来看第一次作业,之所以选择<HashMap<HashMap<String, Integer>>, BigInteger>这样的一个容器存储标准化的Poly,因为它很好地描述了多项式的结构(当然后续迭代中我也发现了它存在的不足)。而Map最大的优点就是合并同类项,相同键时,通过重新定义merge方法的函数参数可以容易达成底数指数相同,系数相加这样的多项式运算逻辑。相比之下MulPoly方法则实现难度较大,由于对于java语言包括hashmap容器是第一次学习,不够熟悉,因此我认为该方法是这次作业中实现的一大难点,需要思考与查找资料来完成,但是其中的道理仍然是嵌套Map的逻辑,即把两个乘数的不同底数放到一个键集中,相同底数则指数相加。第一次作业耗费我第一周中30余小时的时间编写,总体是由于寒假没有进行有效的预习,也没有选上先导课进行系统性的基础学习,只是凭着在学校里对于java的一些耳濡目染,因此最初难以下手,甚至一度认为无法按时提交。第一次作业的完成告诉我一个道理,花费足够时间是可以完成似乎不可能的任务。
public Poly mulPoly(Poly other) {
Poly answer = new Poly();
for (HashMap<String, Integer> i : other.map.keySet()) {
for (HashMap<String, Integer> j : this.map.keySet()) {
HashMap<String, Integer> map0 = new HashMap<>();
for (String k : i.keySet()) {
//do sth.
}
for (String l : j.keySet()) {
//do sth.
}
if (answer.map.get(map0) == null) {
//do sth.
} else {
//do sth.
}
}
}
return answer;
}
后续的迭代,我均是以前一次为基础进行增量,所加内容不多但是很有效,这也反映了Poly的普适性。第二次作业加入三角函数因子和自定义函数。三角函数可以看作一种不同的因子,我设计一个类Sc,可以描述一个三角函数的类型与它的括号里的表达式因子,它的toPoly方法则是把描述它的唯一的String,类似<<"sin((cos(x)))",1>,>这样的东西作为new出的poly对象的map的键集。这里存在一个缺陷,就是对于三角的平方和优化、二倍角优化等,由于使用String作为键,没有想出好的合并方式。我想若这里使用Exp或Factor为键,可能有更加方便的合并方式。
对于自定义函数,则是读入时将其转化为Func类的对象,存到全局变量的Map里面,后续解析时候进行替换。使用了正则表达式方法解析一个函数式子。
Pattern funcPattern = Pattern.compile("([fgh])\\(([xyz,]+)\\)=(.+)");
第三次作业加入了求导因子和通过函数定义函数的输入。求导初看似乎很困难,因为这是新的一种运算逻辑,不同于Add/Mul。开始碰到的问题是类似:对于一个term, 求导却可能得到一个exp。第二次实验的代码给与了一种解决思路,返回一个Factor,涉及到derive/merge/expand/clone等方法。但我编写hw3时还未进行实验, 我的思路是使用String类作为规范化对象(最初是想对规范化的Poly设计一个类似mul的计算方法实现求导,但后来发现对于Poly类设计一个求导方法对我来说似乎难以实现)。对于每个层次化结构设计一个De方法,返回将该对象求导后的字符串形式,此时再次解析即可获得其Poly形式。这里最核心的思想可能是复用,即多次使用已有的代码达成新的目的,对于得到的String再次进行Parse,亦或是对于新增要求的自定义函数的解析后再转化为Func,都使用了这种思想。也许是因此,我的后两次作业并未花费过多时间。
public String de(String type) {
StringBuilder answer = new StringBuilder();
for (Term i : this.terms) {
answer.append("+" + i.de(type));
}
return answer.toString();
}
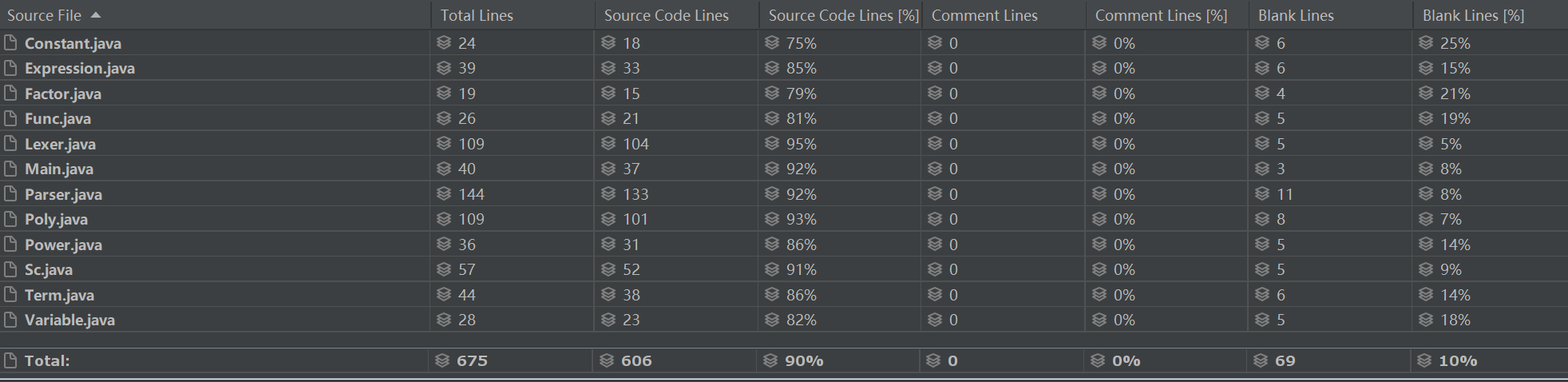
看到核心代码600余行,主要是解析类200余行、不同因子类300余行、Poly类100余行三个大部分。
| Complexity metrics | 认知复杂度 | 基本复杂度 | 模块设计复杂度 | 圈复杂度 | 类平均圈复杂度 | 类最大圈复杂度 | 类总圈复杂度 | |
| Class | Method | CogC | ev(G) | iv(G) | v(G) | OCavg | OCmax | WMC |
| Lexer | Lexer.Lexer(String) | 0 | 1 | 1 | 1 | 5.6 | 10 | 28 |
| Lexer.next() | 14 | 2 | 7 | 11 | ||||
| Lexer.now() | 0 | 1 | 1 | 1 | ||||
| Lexer.simple(String) | 16 | 1 | 6 | 10 | ||||
| Lexer.simple0(String) | 18 | 1 | 5 | 8 | ||||
| Main | Main.main(String[]) | 4 | 1 | 4 | 4 | 3 | 3 | 3 |
| Parser | Parser.Parser(Lexer) | 0 | 1 | 1 | 1 | 2.88 | 10 | 23 |
| Parser.getArgs() | 1 | 1 | 2 | 2 | ||||
| Parser.parseDe() | 2 | 2 | 2 | 2 | ||||
| Parser.parseExpression() | 1 | 1 | 2 | 2 | ||||
| Parser.parseFactor() | 12 | 10 | 10 | 10 | ||||
| Parser.parseFunc() | 1 | 1 | 2 | 2 | ||||
| Parser.parsePower() | 1 | 1 | 2 | 2 | ||||
| Parser.parseTerm() | 1 | 1 | 2 | 2 | ||||
| Constant | ex.Constant.Constant(String) | 0 | 1 | 1 | 1 | 1 | 1 | 4 |
| ex.Constant.de(String) | 0 | 1 | 1 | 1 | ||||
| ex.Constant.getVal() | 0 | 1 | 1 | 1 | ||||
| ex.Constant.toPoly() | 0 | 1 | 1 | 1 | ||||
| Expression | ex.Expression.addTerm(Term) | 0 | 1 | 1 | 1 | 2 | 3 | 8 |
| ex.Expression.de(String) | 1 | 1 | 2 | 2 | ||||
| ex.Expression.isConst(String) | 2 | 3 | 3 | 3 | ||||
| ex.Expression.toPoly() | 1 | 1 | 2 | 2 | ||||
| Factor | ex.Factor.de(String) | 0 | 1 | 1 | 1 | 1 | 1 | 4 |
| ex.Factor.getVal() | 0 | 1 | 1 | 1 | ||||
| ex.Factor.toPoly() | 0 | 1 | 1 | 1 | ||||
| ex.Factor.toString() | 0 | 1 | 1 | 1 | ||||
| Func | ex.Func.Func(String, String[]) | 1 | 1 | 2 | 2 | 1.33 | 2 | 4 |
| ex.Func.getExp() | 0 | 1 | 1 | 1 | ||||
| ex.Func.getParas() | 0 | 1 | 1 | 1 | ||||
| Poly | ex.Poly.Poly() | 0 | 1 | 1 | 1 | 4.17 | 13 | 25 |
| ex.Poly.Poly(BigInteger) | 0 | 1 | 1 | 1 | ||||
| ex.Poly.addPoly(Poly) | 0 | 1 | 1 | 1 | ||||
| ex.Poly.mulPoly(Poly) | 22 | 1 | 8 | 8 | ||||
| ex.Poly.setMap(HashMap<String, Integer>, BigInteger) | 0 | 1 | 1 | 1 | ||||
| ex.Poly.toString() | 26 | 5 | 10 | 13 | ||||
| Power | ex.Power.addFactor(Factor) | 0 | 1 | 1 | 1 | 2 | 3 | 6 |
| ex.Power.de(String) | 1 | 2 | 2 | 2 | ||||
| ex.Power.toPoly() | 4 | 2 | 3 | 3 | ||||
| Sc | ex.Sc.Sc(Expression, boolean) | 0 | 1 | 1 | 1 | 3 | 6 | 9 |
| ex.Sc.de(String) | 2 | 2 | 2 | 2 | ||||
| ex.Sc.toPoly() | 14 | 1 | 8 | 8 | ||||
| Term | ex.Term.addPower(Power) | 0 | 1 | 1 | 1 | 2 | 4 | 8 |
| ex.Term.de(String) | 6 | 1 | 4 | 4 | ||||
| ex.Term.getPowers() | 0 | 1 | 1 | 1 | ||||
| ex.Term.toPoly() | 1 | 1 | 2 | 2 | ||||
| Variable | ex.Variable.Variable(String) | 0 | 1 | 1 | 1 | 1.33 | 2 | 4 |
| ex.Variable.de(String) | 2 | 2 | 1 | 2 | ||||
| ex.Variable.toPoly() | 0 | 1 | 1 | 1 |
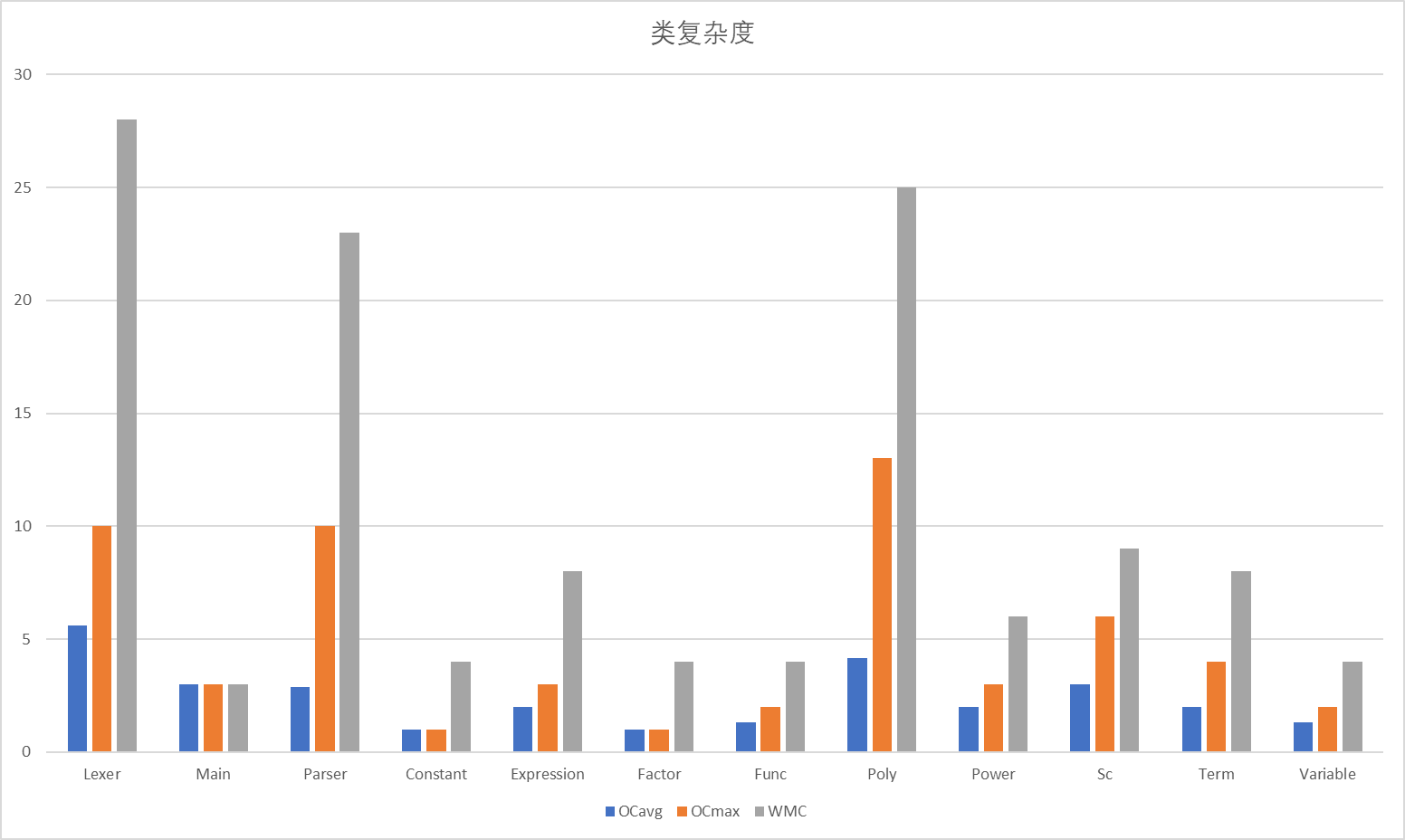
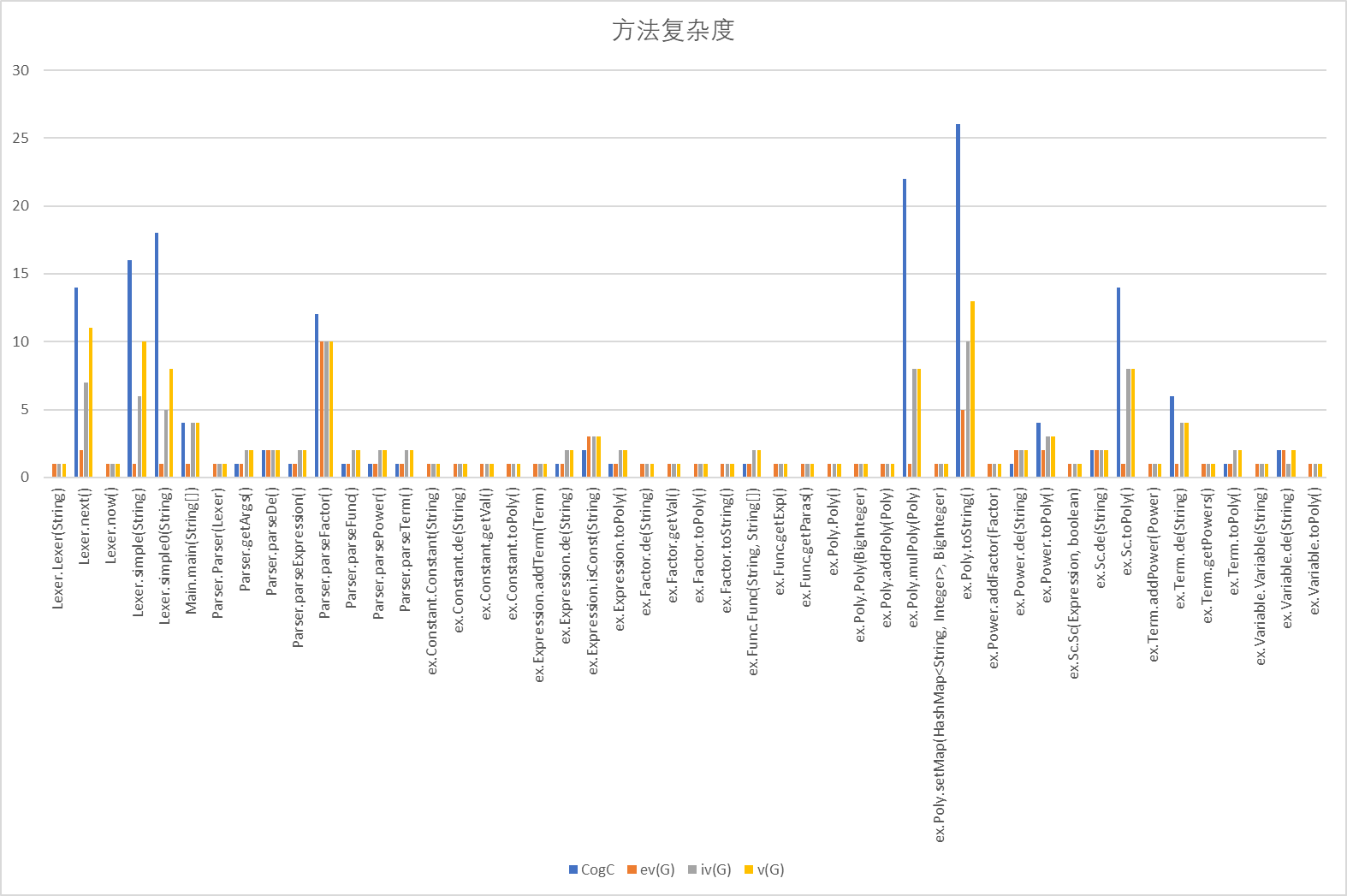
对于类的复杂度,Lexer/Parser/Poly三个类的圈复杂度较高(注:圈复杂度数量上表现为线性无关的路径条数,表示对任何给定代码进行测试、维护或故障排除的难度),三次作业的bug分布似乎也可以印证这一点。同时,这也意味着这三个类与其它类的耦合度较高。我想可以把表达式的Simple作为一个单独的类,把Poly的功能分配给因子类们来更好地实现高内聚低耦合。
大多数方法的复杂度较低,Lexer的化简方法、Poly的toString方法、Lexer的next方法的认知复杂度与圈复杂度较高,是由于为了解析题目的输入格式、满足题目的格式化输出与从输入字符串获得单个原子,若不看题目自然较难理解其化简的意义与为何要如此输出。
Sc的toPoly方法的认知复杂度较高,是由于进行了双层括号与单层括号的判断,也是满足题目要求与优化需求。
Poly的mulPoly方法认知复杂度较高,由于进行了双层嵌套HashMap的遍历,上文已经提到过。
ParseFactor的四项复杂度均为较高,由于Factor的种类较为丰富,而后续的fuc、de等都是处于这一因子层,添加代码较多。
public Factor parseFactor() {
if (lexer.now().equals("(")) {
lexer.next();
Expression expression = parseExpression();
lexer.next();
return expression;
} else if (lexer.now().matches("[xyz]")) {
String var = lexer.now();
lexer.next();
return new Variable(var);
} else if (lexer.now().matches("-?[0-9]+")) {
String num = lexer.now();
lexer.next();
return new Constant(num);
} else if (lexer.now().equals("sin")) {
lexer.next();
lexer.next();
Expression exp = parseExpression();
if (exp.isConst("sin")) {
lexer.next();
return new Constant("0");
}
lexer.next();
return new Sc(exp, true);
} else if (lexer.now().equals("cos")) {
lexer.next();
lexer.next();
Expression exp = parseExpression();
if (exp.isConst("cos")) {
lexer.next();
return new Constant("1");
}
lexer.next();
return new Sc(exp, false);
} else if (lexer.now().matches("[fgh]")) {
return parseFunc();
} else if (lexer.now().equals("d")) {
return parseDe();
} else {
System.out.print("is that an apple?");
System.exit(1);
return null;
}
}
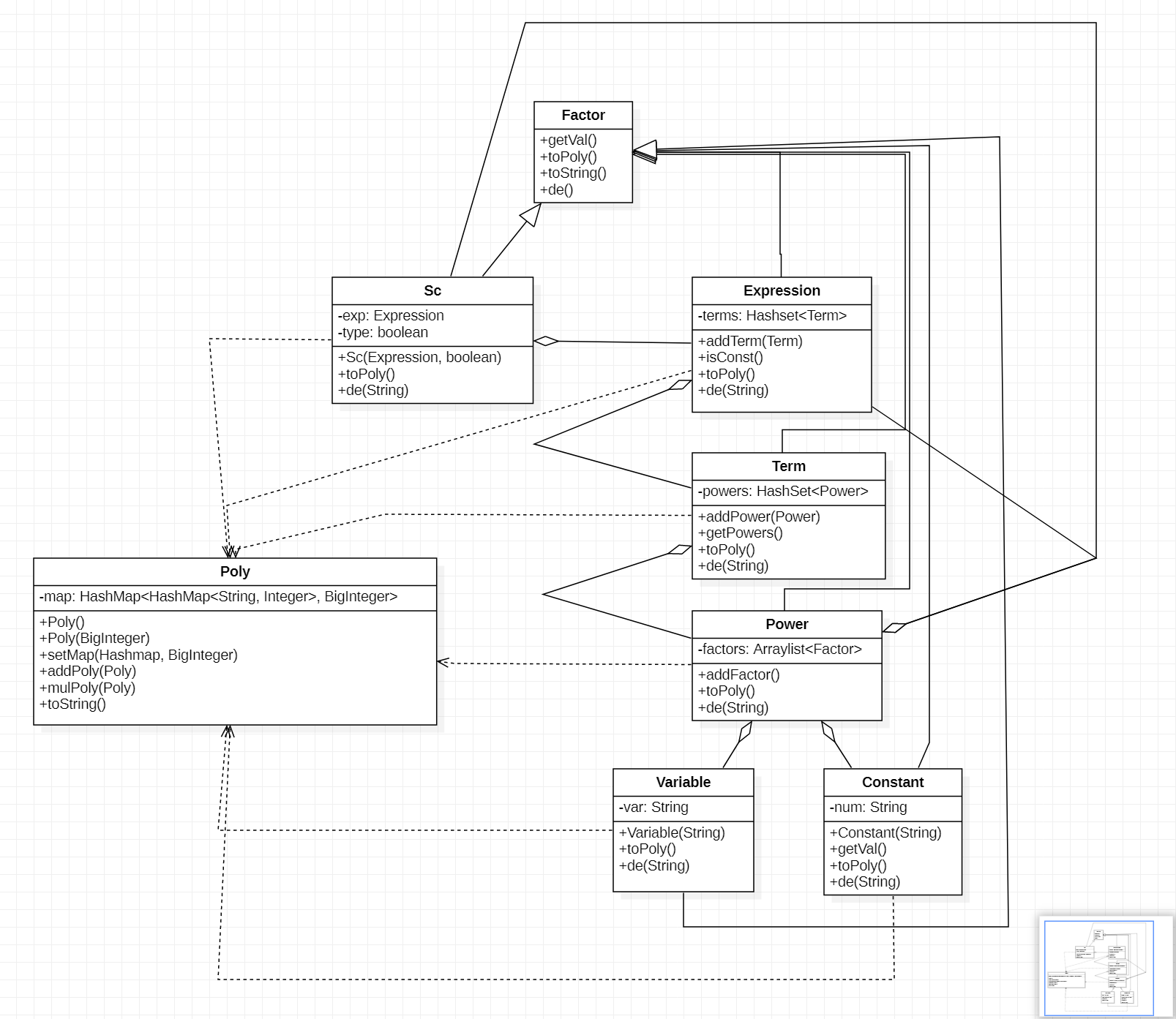
该类图表示了各因子类与Poly类的属性、方法、以及它们的类间关系。解析类等由于实现大同小异,故不再绘制。可以看到每个因子类均实现了toPoly方法和de方法,以及它们自己的构造方法、添加元素方法、获取值方法等。Poly类则是实现了加法和乘法的运算方法和输出的toString方法。
优点:类间层次化结构较清晰,以Factor类作为父类,所有的部分结构都是其子类,较好地描述了表达式的各个部分的属性,并能够进行表达式运算。运算方法集成为Poly的运算,代码规模较小。<HashMap<HashMap<String, Integer>>, BigInteger>的结构使得迭代易于进行。
缺点:Poly的结构对于复杂的嵌套三角函数的存储时依旧是字符串,不能很好体现嵌套结构。求导时使用形式化的字符串转化,多次调用解析类,增加了时间复杂度。难以进行平方和优化。HashSet的使用没有体现出其去重和索引查找的特性,且遍历速度不如ArrayList,感觉这里也可以考虑使用HashMap先处理项内的合并。自定义类没有实现hashcode和equals方法,如果实现的话可能可以直接在项内处理三角函数平方和化简等。
hw1中bug是对于负号的处理,把括号后负号后的数字当成只有一位了,以至于11*-11算出是10。修复方法是把负号与数字看为一体,把 - 全部替换为 +(-1) * 。
hw2的bug是运用了正则表达式化简了多余的括号,导致把不配对的括号消去了。它的修复是把去括号的步骤放在了生成阶段。
hw3强测和互测都没有出现bug。
对比分析出现了bug的方法和未出现bug的方法在代码行和圈复杂度上的差异,发现出现bug的方法代码行数较长,圈复杂度也较高,这告诉我们要简化代码,且降低圈复杂度,写出代码应该简洁美观,高内聚低耦合。
共hack成功3次,使用看似容易出bug的例子,比如sin(0)**0, 1+++1 。是否结合被测程序的代码设计结构来设计测试用例?是的,比如一个同学hw1使用正则表达式替换消除多余的加减号,发现它无法消除三个连续加号,于是我使用1+++1hack他。前两次都没有评测机。第三次看到讨论区有一个评测机,于是使用,奇怪的是测出了tle的样例,hack时候却说不满足合法性检测,可能是cost太高了,又或许是没有掌握评测机的正确用法,于是只有hw3没有hack成功一次。
学到面向对象的知识,面向对象的特点继承、封装、多态,设计模式如工厂模式(定义了一个创建对象的抽象方法,由子类决定要实例化的类,工厂方法模式将对象的实例化推迟到子类)。学到java知识,Hashmap、Hashset、Arraylist等容器、String、StringBuilder类与字符串处理、构造方法。学到对象间关系,如关联、聚合、组合、依赖、泛化、实现。 学到递归下降这一种解析式子的方法,递归的过程是建立了一颗树,它是循环调用parsexxx方法的递归。
学到Hash类容器重写储存在里面的对象的hashcode、equals方法,我没有重写,因为表达式里遇到相同的两个数字还是不同的两个对象,这样的hashcode是根据内存地址(也有随机数等生成方法),所以hashset失去了本来的意义,如果重写则可以实现查找功能等。而Poly中由于String类本身就有重写的hashcode和equals方法使得合并同类项顺利进行。值得一提的是,当输入类似sin((x+y)) + sin((y+x)) 的时候,程序仍然可以把它们合并输出成2sin((y+x))。奇怪的是Map的键应该是无序储存的,为什么进行多次输入输出都得到这里是可以合并的呢?搜索得知:当key为String对象时,HashMap的遍历之所以是有序的,是因为String计算出来的hashCode值是有序的。
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Aclass aobj = (Aclass) o;
if (age != aobj.age) return false;
return name != null ? name.equals(aobj.name) : aobj.name == null;
}
@Override
public int hashCode() { //return name.hashCode() + age;
int result = name != null ? name.hashCode() : 0;
result = 31 * result + age;
return result;
}
//网上一个重写的例子
学习了正则表达式捕获、匹配的用处。
//import java.util.regex.Matcher;
//import java.util.regex.Pattern;
private final Pattern numberPattern = Pattern.compile("[0-9]+");
Matcher matcher = numberPattern.matcher(expression);
if (matcher.find()) {
String string = matcher.group(0);
return new Num(Integer.parseInt(string));
} else {
return new Num(parameters.get(expression));
}
学习了迭代器Iterator的使用,如果要双重遍历一个集合比如HashSet, 是可以使用两个Iterator,而不是只能存在一个。
public String de(String type) {
StringBuilder answer = new StringBuilder();
for (Power i : this.powers) {
Iterator<Power> iterator = this.powers.iterator();
HashSet<Power> remain = new HashSet<>();
while (iterator.hasNext()) {
Power now = iterator.next();
if (!now.equals(i)) {
remain.add(now);
}
}
Term late = new Term();
late.getPowers().addAll(remain);
answer.append("(" + i.de(type) + ")*(" + late + ")+");
}
answer.append("0");
return answer.toString();
}
总之,我最大的感受就是学习知识很重要,如果没有语法基础、设计方法做支撑,空谈架构只能产生不切实际的幻想而无法付诸实现的无能为力,即使查找资料仍然会产生很多困惑。而编写代码的过程又好像自己是上帝在创造一个新事物一样,看到结果正确的瞬间会收获快乐。

而编写代码的过程又好像自己是上帝在创造一个新事物一样,看到结果正确的瞬间会收获快乐。
不断创作和尝试。



