



442
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享OO第一单元的主题是对表达式进行括号展开并做化简,从hw1到hw3,进行迭代式、增量式的开发。从开发过程来看,这三次作业是递进式的,一次比一次功能完善,一次比一次考虑的东西更多。如果一上来就直接奔着第三次作业的目标来写,上千行的代码量对于我一个没有上过OO先导课的人来说实在是万分头疼,阶梯式的难度分解,将整个开发过程的难度很好的拆分了。实际上在日后工作中的开发也是一样,客户的需求并非一开始就完全是明确的,而是在使用的过程中会逐步提出新的要求,课程组采用增量式的设计,很好地模拟了这一实际情况。
第一次作业的训练目标是通过对表达式结构进行建模,完成多变量多项式的括号展开,初步体会层次化设计的思想。这次作业的任务是读入一个包含加、减、乘、乘方以及括号(其中括号的深度至多为 1 层)的多变量表达式,输出恒等变形展开所有括号后的表达式。
第一次作业虽然要求很少,但却是三次作业的核心,如果能在第一次作业建立起一个良好的架构,就有可能在第二次和第三次的作业中只需要做很少的修改甚至不修改,并且再增添一些新的功能就能够符合新的要求了。在实际的工程开发中,这样的“留有余地”是很重要的,在设计一个程序时,我们的目光不能够仅仅局限于当前的要求中,还要在最大的程度上考虑到日后的更新迭代的问题,给代码的维护留一条后路。因为在面对一个实际问题时,我们很多时候不能够一次性把所有情况全部考虑到位,因此就会产生各种各样的BUG,这是常态。一个程序员不能因为害怕出BUG就蹑手蹑脚,否则他将寸步难行。但是,在面对可能出现的BUG,要留有后路,建立起良好的代码规范以便日后的反复查阅和修改。
回到第一次作业本身,这次作业的核心,其实在课上和指导书上都已经介绍得很详细了,就是将一个表达式的层次化结构用程序语言解析出来,然后自下而上地一步一步地将这个大问题分解后逐个击破。表达式的层次结构,大体上可以分为三层——expr(表达式)、term(项)、factor(因子)。但是有一点需要注意,就是factor中是可以嵌套expr的,这也就形成了递归调用的关系。面对这样的关系,大多数同学都采用的是递归下降的方法,我也不例外。但、我在实际的操作中遇到了一些问题。
当我在实现乘除和加减的时候,我发现不同的因子要实现乘除和加减的合并需要写多个方法,或许是缺乏面向过程编程的经验,我尝试写了但是却卡在了那里。后来我进行了这样的思考,有没有一种办法,可以将不同因子之间的合并统一起来———无论是数字因子,还是幂函数因子,抑或是表达式因子。
我最终从幂函数的形式上找到了答案。一个幂函数是由系数,底数和指数三部分组成的,而在第一次作业中,化简到最后,表达式一定是由若干个化简过后的项组成。这些化简过后的项的形式一定是系数*底数1**指数1*底数2**指数....我们把这样的项称为element(元素)。而仔细观察这个所谓的element,它其实是可以再度被拆分的———一个元素是由一个系数和若干个简单幂函数组成的。而所谓简单密函数,就是底数**指数这样的形式,我们把这种形式抽象出来称为一个类,这就是power(简单幂函数)。
有了这样的拆分,问题就得到了简化,无论是常数,还是幂函数它们其实都可以归结为element,常数就是所有指数都为0的element,简单幂函数就是指数为1的element。于是我们所有的加减乘除操作都可以基于这个最小单元--element来实现。因为每一级解析出来的式子都可以用一个element的列表来记录。我们只需要实现对这个列表的加减乘以及乘方的操作即可(我把这些操作都集成在了一个figure类中实现,这个类中全是静态方法)于是在parseFactor、parseTerm、pasreExpr三个解析层次中,我们要返回的实际上始终是一个element表。在parseFactor中我们做最细致的运算,解析element然后处理乘方,在parseTerm中我们对parseFactor中返回上来的element表进行乘运算,在parseExpr中,我们对parseTerm返回上来的element表进行加减运算。
两个Element列表的乘法,最后是落到两个Element的乘法上的,在做完乘法后,再把它们加到一起。两个Element列表的加法实际上也是如此。在实现加法和乘法的时候,为了不篡改原来的数据,我首先进行了一次深拷贝,当然减法和乘方也要有这样一个操作。
不过,我对减法和乘法的实现,并不是直接进行实现的,而是采用了间接的办法。对于减法来说,我的实现办法其实将减数的系数反转,再调用一次加法;对于乘方来说,我没有用快速幂对其进行优化,而是单纯地写了一个循环,反复调用乘法。
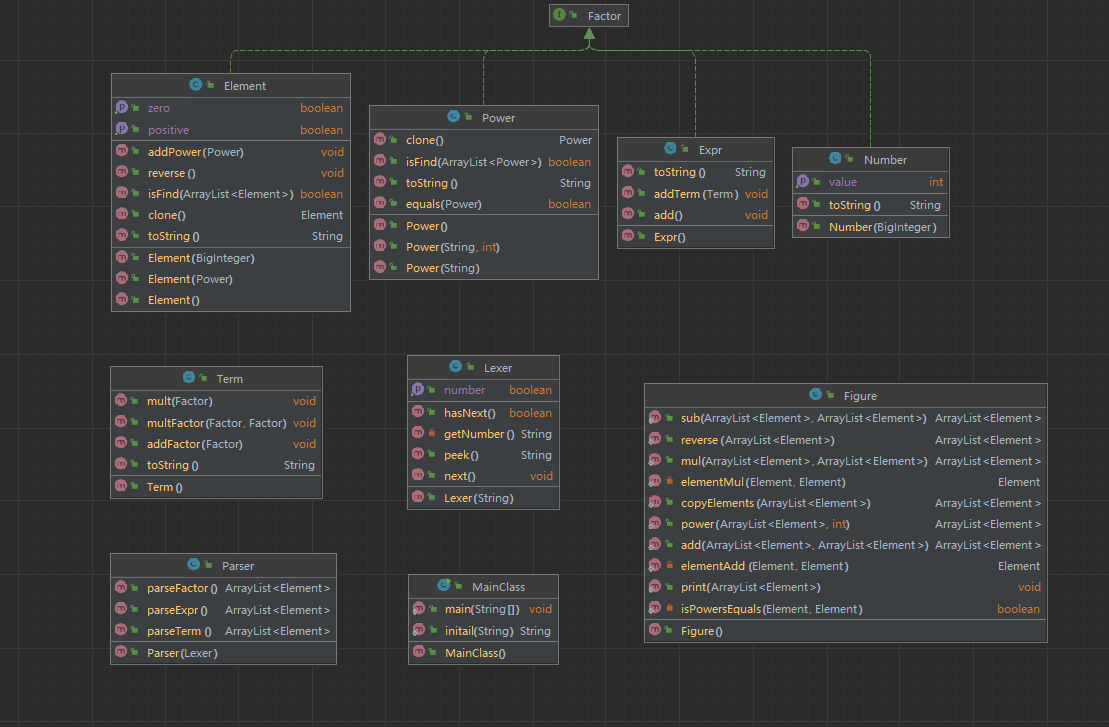
这里可以看到在第1次作业中我使用了Expr、Term、Factor这三个类来描述层次化关系,但是在基于元素表的架构中,这些类中实际存放的都应该是element表,所以在后面的作业中我直接舍弃了这些类(笑)
| 方法名 | CogC | ev(G) | iv(G) | v(G) |
|---|---|---|---|---|
| expr.Element.addPower(Power) | 0.0 | 1.0 | 1.0 | 1.0 |
| expr.Element.clone() | 1.0 | 1.0 | 2.0 | 2.0 |
| expr.Element.Element() | 0.0 | 1.0 | 1.0 | 1.0 |
| expr.Element.Element(BigInteger) | 0.0 | 1.0 | 1.0 | 1.0 |
| expr.Element.Element(Power) | 0.0 | 1.0 | 1.0 | 1.0 |
| expr.Element.isFind(ArrayList) | 6.0 | 4.0 | 3.0 | 4.0 |
| expr.Element.isPositive() | 0.0 | 1.0 | 1.0 | 1.0 |
| expr.Element.isZero() | 0.0 | 1.0 | 1.0 | 1.0 |
| expr.Element.reverse() | 0.0 | 1.0 | 1.0 | 1.0 |
| expr.Element.toString() | 8.0 | 1.0 | 5.0 | 5.0 |
| expr.Power.clone() | 0.0 | 1.0 | 1.0 | 1.0 |
| expr.Power.equals(Power) | 1.0 | 1.0 | 2.0 | 2.0 |
| expr.Power.isFind(ArrayList) | 4.0 | 3.0 | 3.0 | 4.0 |
| expr.Power.Power() | 0.0 | 1.0 | 1.0 | 1.0 |
| expr.Power.Power(String) | 0.0 | 1.0 | 1.0 | 1.0 |
| expr.Power.Power(String,int) | 0.0 | 1.0 | 1.0 | 1.0 |
| expr.Power.toString() | 2.0 | 1.0 | 3.0 | 3.0 |
| Figure.add(ArrayList,ArrayList) | 8.0 | 4.0 | 6.0 | 6.0 |
| Figure.copyElements(ArrayList) | 1.0 | 1.0 | 2.0 | 2.0 |
| Figure.elementAdd(Element,Element) | 0.0 | 1.0 | 1.0 | 1.0 |
| Figure.elementMul(Element,Element) | 6.0 | 4.0 | 4.0 | 4.0 |
| Figure.isPowersEquals(Element,Element) | 10.0 | 6.0 | 4.0 | 7.0 |
| Figure.mul(ArrayList,ArrayList) | 3.0 | 1.0 | 3.0 | 3.0 |
| Figure.power(ArrayList,int) | 2.0 | 2.0 | 3.0 | 3.0 |
| Figure.print(ArrayList) | 14.0 | 4.0 | 6.0 | 6.0 |
| Figure.reverse(ArrayList) | 1.0 | 1.0 | 2.0 | 2.0 |
| Figure.sub(ArrayList,ArrayList) | 0.0 | 1.0 | 1.0 | 1.0 |
| Lexer.getNumber() | 8.0 | 4.0 | 6.0 | 7.0 |
| Lexer.hasNext() | 0.0 | 1.0 | 1.0 | 1.0 |
| Lexer.isNumber() | 0.0 | 1.0 | 1.0 | 1.0 |
| Lexer.Lexer(String) | 0.0 | 1.0 | 1.0 | 1.0 |
| Lexer.next() | 3.0 | 2.0 | 3.0 | 4.0 |
| Lexer.peek() | 0.0 | 1.0 | 1.0 | 1.0 |
| MainClass.initail(String) | 2.0 | 1.0 | 5.0 | 5.0 |
| MainClass.main(String[]) | 0.0 | 1.0 | 1.0 | 1.0 |
| Parser.parseExpr() | 8.0 | 1.0 | 6.0 | 6.0 |
| Parser.parseFactor() | 10.0 | 3.0 | 7.0 | 7.0 |
| Parser.Parser(Lexer) | 0.0 | 1.0 | 1.0 | 1.0 |
| Parser.parseTerm() | 1.0 | 1.0 | 2.0 | 2.0 |
| Total | 111.0 | 77.0 | 115.0 | 122.0 |
| Average | 2.176470588235294 | 1.5098039215686274 | 2.2549019607843137 | 2.392156862745098 |
在Figure中的有些方法其实是不应该放在其中的,比如elementAdd和elementMul 这两个是单独对元素的操作,应该抽离出来,放置在element类中。然而笔者在当时一心只想先过了弱测和中测,便搁置下来,一直到后面也没有优化(恼)。
在公测中我被检测出一个BUG,这个BUG是来自比较两个元素是否相同时,判断条件出了问题,是一个较为细节的问题,修改时仅修改了对应的方法中的几行代码。这类细小的问题总是会常常出现,当它出现时,不要气馁,我们沉下心来将其修复即可。
第二次作业相较于第一次作业而言,新增了三角函数和自定义函数。我们逐个进行分析。
在第一次架构的基础上,要增加三角函数(当然,在我们的作业中,只考虑sin和cos),只需要修改我们的最小操作单元,也就是我们的element,原先我们的element中,只含有一个简单幂函数的list,现在我们要把三角函数添加进去,对于三角函数而言,它的结构是sin(表达式)或者是cos(表达式),我们要做的就是在三角函数类中设计一个属性,把表达式的信息储存下来,根据我们第一次作业的架构分析,这实际上就是需要储存一个element的表。
另一方面,sin和cos的结构是高度相似的,我们可以抽象出一个tri类作为它们的父类,然后sin和cos再去继承这个tri父类。
自定义函数实际上是由三个部分组成的————函数名/函数头,形参列表,函数表达式。我们要如何去储存这个结构呢。这个问题其实从数学上就能够找到答案。在数学的定义中,我们是如何确定一个函数的唯一性的呢,答案是通过函数名,我们在定义数学的函数时,函数的名字其实是独一无二的,通过它可以找到唯一的一个函数,这是一种一一映射关系。在java中,我们要如何去反映这种一一映射的关系呢,我的办法是采用一个hashMap。用函数名作为它的key,形参列表和函数表达式作为value。事实上,无论是形参列表还是函数表达式,我们的储存形式其实都是String。因此我们可以用一个String的ArrayList作为这个value值。
对于自定义函数的化简,在这次作业中,我们是采用直接替换的方法。即不对这个自定义函数本身做任何的化简,而是在最终的表达式中,将自定义函数的形参依次用实参进行替换。然后再对这个替换后的表达式进行化简。对于所有自定义函数的操作,我们都放到Func这个类中。
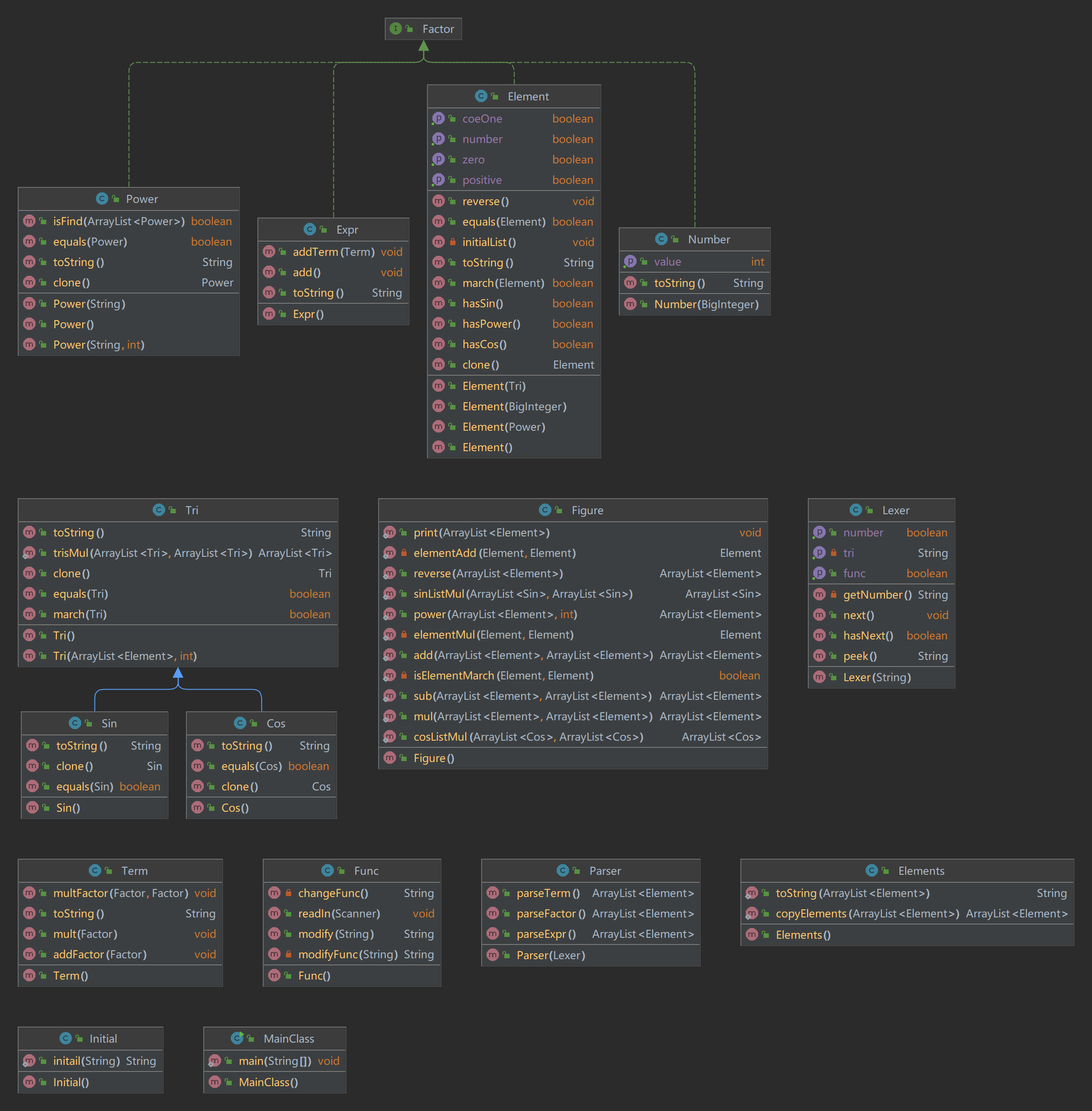
在第二次作业中,我对一些功能进行了优化重组,把原来的一些属于Figure类的计算方法迁移到了一个新的类Elements类中,把属于element的list的计算方法放到一个表示element的List的类中,按照这个思想,其实Figure这个类就可以完全可以取缔了,把计算方法迁移到Elements和Element类中,不但如此,number类也是可以直接去掉的,因为对于Number的处理已经蕴含在Element类当中了,然而笔者没有足够的时间来做这件事:(。
另外需要指出的是,在本次作业中,笔者新添了一个Initial类,这个类的主要功能,是对读入的表达式进行一个预处理,去掉一些空白字符,然后把乘方符号**改为用^来储存,方便后续操作。
| 方法名 | CogC | ev(G) | iv(G) | v(G) |
|---|---|---|---|---|
| expr.Cos.clone() | 0.0 | 1.0 | 1.0 | 1.0 |
| expr.Cos.Cos() | 0.0 | 1.0 | 1.0 | 1.0 |
| expr.Cos.equals(Cos) | 0.0 | 1.0 | 1.0 | 1.0 |
| expr.Cos.toString() | 1.0 | 1.0 | 2.0 | 2.0 |
| expr.Element.clone() | 3.0 | 1.0 | 4.0 | 4.0 |
| expr.Element.Element() | 0.0 | 1.0 | 1.0 | 1.0 |
| expr.Element.Element(BigInteger) | 0.0 | 1.0 | 1.0 | 1.0 |
| expr.Element.Element(Power) | 0.0 | 1.0 | 1.0 | 1.0 |
| expr.Element.Element(Tri) | 2.0 | 1.0 | 3.0 | 3.0 |
| expr.Element.equals(Element) | 1.0 | 2.0 | 1.0 | 2.0 |
| expr.Element.hasCos() | 3.0 | 3.0 | 1.0 | 3.0 |
| expr.Element.hasPower() | 3.0 | 3.0 | 1.0 | 3.0 |
| expr.Element.hasSin() | 3.0 | 3.0 | 1.0 | 3.0 |
| expr.Element.initialList() | 0.0 | 1.0 | 1.0 | 1.0 |
| expr.Element.isCoeOne() | 0.0 | 1.0 | 1.0 | 1.0 |
| expr.Element.isNumber() | 3.0 | 3.0 | 4.0 | 5.0 |
| expr.Element.isPositive() | 0.0 | 1.0 | 1.0 | 1.0 |
| expr.Element.isZero() | 0.0 | 1.0 | 1.0 | 1.0 |
| expr.Element.march(Element) | 26.0 | 14.0 | 9.0 | 16.0 |
| expr.Element.reverse() | 0.0 | 1.0 | 1.0 | 1.0 |
| expr.Element.toString() | 33.0 | 2.0 | 18.0 | 18.0 |
| expr.Elements.copyElements(ArrayList) | 1.0 | 1.0 | 2.0 | 2.0 |
| expr.Elements.toString(ArrayList) | 14.0 | 4.0 | 6.0 | 6.0 |
| expr.Power.clone() | 0.0 | 1.0 | 1.0 | 1.0 |
| expr.Power.equals(Power) | 1.0 | 1.0 | 2.0 | 2.0 |
| expr.Power.isFind(ArrayList) | 4.0 | 3.0 | 3.0 | 4.0 |
| expr.Power.Power() | 0.0 | 1.0 | 1.0 | 1.0 |
| expr.Power.Power(String) | 0.0 | 1.0 | 1.0 | 1.0 |
| expr.Power.Power(String,int) | 0.0 | 1.0 | 1.0 | 1.0 |
| expr.Power.toString() | 2.0 | 1.0 | 3.0 | 3.0 |
| expr.Sin.clone() | 0.0 | 1.0 | 1.0 | 1.0 |
| expr.Sin.equals(Sin) | 0.0 | 1.0 | 1.0 | 1.0 |
| expr.Sin.Sin() | 0.0 | 1.0 | 1.0 | 1.0 |
| expr.Sin.toString() | 1.0 | 1.0 | 2.0 | 2.0 |
| expr.Tri.clone() | 0.0 | 1.0 | 1.0 | 1.0 |
| expr.Tri.equals(Tri) | 10.0 | 7.0 | 3.0 | 7.0 |
| expr.Tri.march(Tri) | 9.0 | 6.0 | 3.0 | 6.0 |
| expr.Tri.toString() | 0.0 | 1.0 | 1.0 | 1.0 |
| expr.Tri.Tri() | 0.0 | 1.0 | 1.0 | 1.0 |
| expr.Tri.Tri(ArrayList,int) | 0.0 | 1.0 | 1.0 | 1.0 |
| expr.Tri.trisMul(ArrayList,ArrayList) | 6.0 | 1.0 | 4.0 | 4.0 |
| Figure.add(ArrayList,ArrayList) | 8.0 | 4.0 | 6.0 | 6.0 |
| Figure.cosListMul(ArrayList,ArrayList) | 6.0 | 4.0 | 4.0 | 4.0 |
| Figure.elementAdd(Element,Element) | 0.0 | 1.0 | 1.0 | 1.0 |
| Figure.elementMul(Element,Element) | 10.0 | 5.0 | 5.0 | 5.0 |
| Figure.isElementMarch(Element,Element) | 27.0 | 14.0 | 10.0 | 17.0 |
| Figure.mul(ArrayList,ArrayList) | 3.0 | 1.0 | 3.0 | 3.0 |
| Figure.power(ArrayList,int) | 2.0 | 2.0 | 3.0 | 3.0 |
| Figure.print(ArrayList) | 0.0 | 1.0 | 1.0 | 1.0 |
| Figure.reverse(ArrayList) | 1.0 | 1.0 | 2.0 | 2.0 |
| Figure.sinListMul(ArrayList,ArrayList) | 6.0 | 4.0 | 4.0 | 4.0 |
| Figure.sub(ArrayList,ArrayList) | 0.0 | 1.0 | 1.0 | 1.0 |
| Func.changeFunc() | 31.0 | 8.0 | 15.0 | 16.0 |
| Func.Func() | 0.0 | 1.0 | 1.0 | 1.0 |
| Func.modify(String) | 2.0 | 1.0 | 4.0 | 4.0 |
| Func.modifyFunc(String) | 4.0 | 1.0 | 3.0 | 3.0 |
| Func.readIn(Scanner) | 9.0 | 1.0 | 6.0 | 6.0 |
| Initial.initail(String) | 2.0 | 1.0 | 5.0 | 5.0 |
| Lexer.getNumber() | 8.0 | 4.0 | 6.0 | 7.0 |
| Lexer.getTri() | 0.0 | 1.0 | 1.0 | 1.0 |
| Lexer.hasNext() | 0.0 | 1.0 | 1.0 | 1.0 |
| Lexer.isFunc() | 1.0 | 1.0 | 3.0 | 3.0 |
| Lexer.isNumber() | 0.0 | 1.0 | 1.0 | 1.0 |
| Lexer.Lexer(String) | 0.0 | 1.0 | 1.0 | 1.0 |
| Lexer.next() | 7.0 | 2.0 | 4.0 | 6.0 |
| Lexer.peek() | 0.0 | 1.0 | 1.0 | 1.0 |
| MainClass.main(String[]) | 0.0 | 1.0 | 1.0 | 1.0 |
| Parser.parseExpr() | 8.0 | 1.0 | 6.0 | 6.0 |
| Parser.parseFactor() | 12.0 | 3.0 | 9.0 | 9.0 |
| Parser.Parser(Lexer) | 0.0 | 1.0 | 1.0 | 1.0 |
| Parser.parseTerm() | 1.0 | 1.0 | 2.0 | 2.0 |
| Total | 286.0 | 162.0 | 224.0 | 258.0 |
| Average | 3.4457831325301207 | 1.9518072289156627 | 2.6987951807228914 | 3.108433734939759 |
可以看到新添的三角函数类,和自定义函数处理类中的方法复杂度都不是太高。
笔者在第二次作业的公测中被测出的BUG在事实上和第一次作业中出现的BUG是一样的(逃)。这回是在比较Sin和Cos的时候出了问题,没有考虑到列表为空的情况是会直接跳过去的,于是在方法的最开始加一行判断,来查看列表的长度是不是为0。
第三次作业相较第二次作业而言,多了求导因子,以及在函数定义的时候产生的互相嵌套定义。
求导因子的形式是形如dx(表达式)的样子。根据形式化分析处理的思想,对这一级运算的处理,应该放在parseFactor这个方法当中。在lexer解析到求导算符d后,先记录下究竟是对哪个变量求导,然后再调用parseExpr的方法解析括号中的表达式,根据我们第一次作业的架构,这将返回一个Element的列表。然后我们就可以将这个Element表作为输出,进行求导运算,当然,结果也是返回一个Element的列表。
对于求导因子的实现,主要又分了两级,第一级是对每个Element进行求导,由于每个Element是由很多个因子相乘得到的,这里就要用到求导的乘法法则。第二级是在每个因子的求导中,需要采用链式法则来处理像Sin和Cos的因子。因为Sin和Cos内部又是表达式(Element表),这样就形成了一个递归调用,逐级化简的格局。
在这次作业,自定义函数的定义中会含有求导算子,除此之外,还会嵌套其他的自定义函数。特别是求导因子,例如f(x) = dx(x)(这个函数实际上是一个常数--1) 这样的,如果不先化简,直接替换进去就会产生问题,例如f(sin(x)),如果直接替换进去就会变成dx(sin(x)) = cos(x)。面对这种情况,直接对输入的表达式进行字符替换就不是一个很好的选择了。先对自定义函数进行化简,再进行替换,成为一个更好的选择。当然,对自定义函数进行化简的这个过程,就可以直接调用parseExpr方法了。
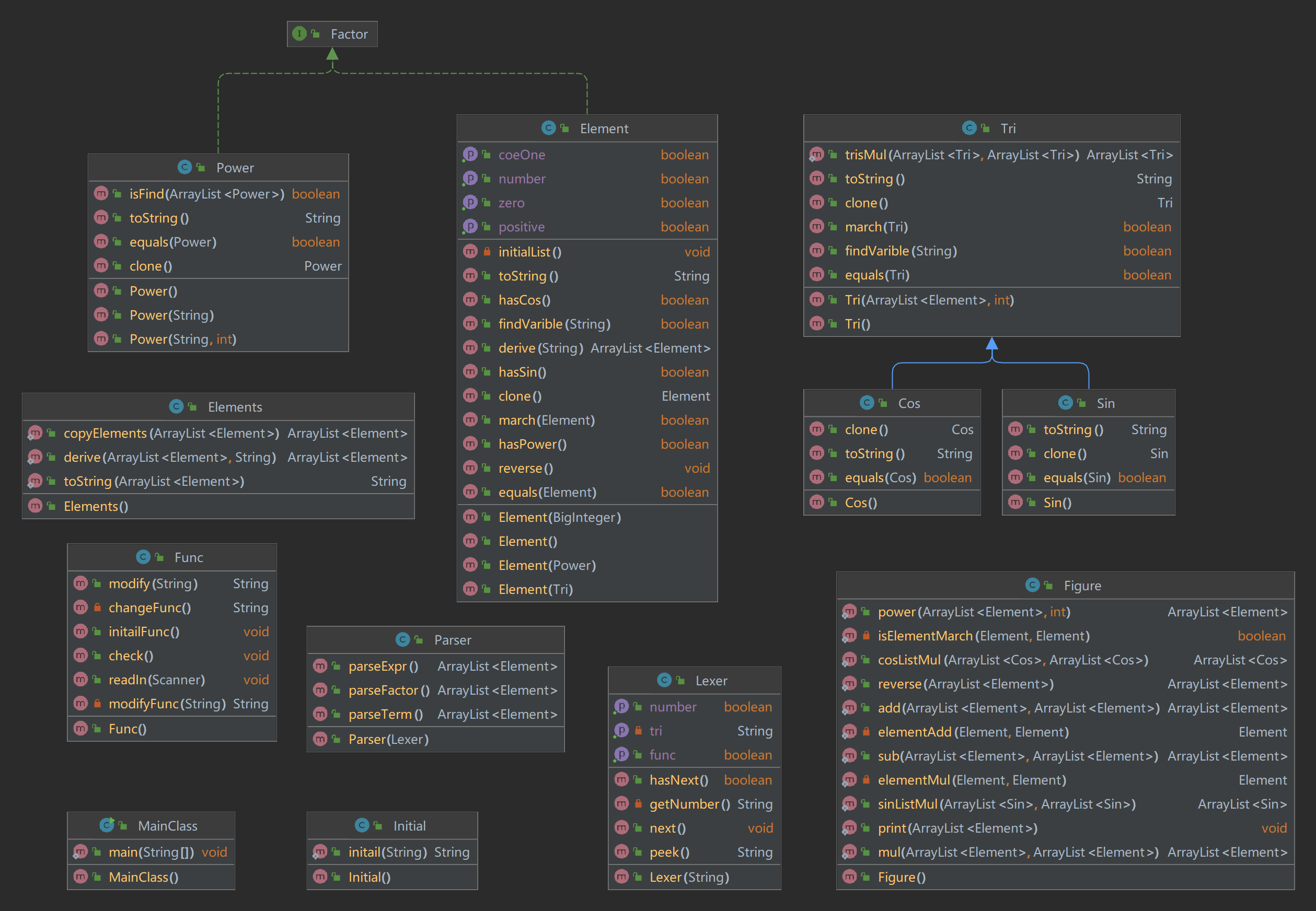
这回笔者终于是取缔了Number类等没有用上的类了,在func类中,增加了一个initialFunc来对自定义函数进行化简。除此之外最大的修改是增加了求导的相应方法。
| 方法名 | CogC | ev(G) | iv(G) | v(G) |
|---|---|---|---|---|
| Cos.clone() | 0.0 | 1.0 | 1.0 | 1.0 |
| Cos.Cos() | 0.0 | 1.0 | 1.0 | 1.0 |
| Cos.equals(Cos) | 0.0 | 1.0 | 1.0 | 1.0 |
| Cos.toString() | 1.0 | 1.0 | 2.0 | 2.0 |
| Element.clone() | 3.0 | 1.0 | 4.0 | 4.0 |
| Element.derive(String) | 41.0 | 14.0 | 18.0 | 18.0 |
| Element.Element() | 0.0 | 1.0 | 1.0 | 1.0 |
| Element.Element(BigInteger) | 0.0 | 1.0 | 1.0 | 1.0 |
| Element.Element(Power) | 0.0 | 1.0 | 1.0 | 1.0 |
| Element.Element(Tri) | 2.0 | 1.0 | 3.0 | 3.0 |
| Element.equals(Element) | 1.0 | 2.0 | 1.0 | 2.0 |
| Element.findVarible(String) | 10.0 | 8.0 | 4.0 | 8.0 |
| Element.hasCos() | 3.0 | 3.0 | 1.0 | 3.0 |
| Element.hasPower() | 3.0 | 3.0 | 1.0 | 3.0 |
| Element.hasSin() | 3.0 | 3.0 | 1.0 | 3.0 |
| Element.initialList() | 0.0 | 1.0 | 1.0 | 1.0 |
| Element.isCoeOne() | 0.0 | 1.0 | 1.0 | 1.0 |
| Element.isNumber() | 3.0 | 3.0 | 4.0 | 5.0 |
| Element.isPositive() | 0.0 | 1.0 | 1.0 | 1.0 |
| Element.isZero() | 0.0 | 1.0 | 1.0 | 1.0 |
| Element.march(Element) | 26.0 | 14.0 | 9.0 | 16.0 |
| Element.reverse() | 0.0 | 1.0 | 1.0 | 1.0 |
| Element.toString() | 33.0 | 2.0 | 18.0 | 18.0 |
| Elements.copyElements(ArrayList) | 1.0 | 1.0 | 2.0 | 2.0 |
| Elements.derive(ArrayList,String) | 1.0 | 1.0 | 2.0 | 2.0 |
| Elements.toString(ArrayList) | 14.0 | 4.0 | 6.0 | 6.0 |
| Figure.add(ArrayList,ArrayList) | 8.0 | 4.0 | 6.0 | 6.0 |
| Figure.cosListMul(ArrayList,ArrayList) | 6.0 | 4.0 | 4.0 | 4.0 |
| Figure.elementAdd(Element,Element) | 0.0 | 1.0 | 1.0 | 1.0 |
| Figure.elementMul(Element,Element) | 10.0 | 5.0 | 5.0 | 5.0 |
| Figure.isElementMarch(Element,Element) | 27.0 | 14.0 | 10.0 | 17.0 |
| Figure.mul(ArrayList,ArrayList) | 3.0 | 1.0 | 3.0 | 3.0 |
| Figure.power(ArrayList,int) | 2.0 | 2.0 | 3.0 | 3.0 |
| Figure.print(ArrayList) | 0.0 | 1.0 | 1.0 | 1.0 |
| Figure.reverse(ArrayList) | 1.0 | 1.0 | 2.0 | 2.0 |
| Figure.sinListMul(ArrayList,ArrayList) | 6.0 | 4.0 | 4.0 | 4.0 |
| Figure.sub(ArrayList,ArrayList) | 0.0 | 1.0 | 1.0 | 1.0 |
| Func.changeFunc() | 31.0 | 8.0 | 15.0 | 16.0 |
| Func.check() | 1.0 | 1.0 | 2.0 | 2.0 |
| Func.Func() | 0.0 | 1.0 | 1.0 | 1.0 |
| Func.initailFunc() | 1.0 | 1.0 | 2.0 | 2.0 |
| Func.modify(String) | 2.0 | 1.0 | 4.0 | 4.0 |
| Func.modifyFunc(String) | 4.0 | 1.0 | 3.0 | 3.0 |
| Func.readIn(Scanner) | 9.0 | 1.0 | 6.0 | 6.0 |
| Initial.initail(String) | 2.0 | 1.0 | 5.0 | 5.0 |
| Lexer.getNumber() | 8.0 | 4.0 | 6.0 | 7.0 |
| Lexer.getTri() | 0.0 | 1.0 | 1.0 | 1.0 |
| Lexer.hasNext() | 0.0 | 1.0 | 1.0 | 1.0 |
| Lexer.isFunc() | 1.0 | 1.0 | 3.0 | 3.0 |
| Lexer.isNumber() | 0.0 | 1.0 | 1.0 | 1.0 |
| Lexer.Lexer(String) | 0.0 | 1.0 | 1.0 | 1.0 |
| Lexer.next() | 7.0 | 2.0 | 4.0 | 6.0 |
| Lexer.peek() | 0.0 | 1.0 | 1.0 | 1.0 |
| MainClass.main(String[]) | 0.0 | 1.0 | 1.0 | 1.0 |
| Parser.parseExpr() | 8.0 | 1.0 | 6.0 | 6.0 |
| Parser.parseFactor() | 13.0 | 3.0 | 10.0 | 10.0 |
| Parser.Parser(Lexer) | 0.0 | 1.0 | 1.0 | 1.0 |
| Parser.parseTerm() | 1.0 | 1.0 | 2.0 | 2.0 |
| Power.clone() | 0.0 | 1.0 | 1.0 | 1.0 |
| Power.equals(Power) | 1.0 | 1.0 | 2.0 | 2.0 |
| Power.isFind(ArrayList) | 4.0 | 3.0 | 3.0 | 4.0 |
| Power.Power() | 0.0 | 1.0 | 1.0 | 1.0 |
| Power.Power(String) | 0.0 | 1.0 | 1.0 | 1.0 |
| Power.Power(String,int) | 0.0 | 1.0 | 1.0 | 1.0 |
| Power.toString() | 2.0 | 1.0 | 3.0 | 3.0 |
| Sin.clone() | 0.0 | 1.0 | 1.0 | 1.0 |
| Sin.equals(Sin) | 0.0 | 1.0 | 1.0 | 1.0 |
| Sin.Sin() | 0.0 | 1.0 | 1.0 | 1.0 |
| Sin.toString() | 1.0 | 1.0 | 2.0 | 2.0 |
| Tri.clone() | 0.0 | 1.0 | 1.0 | 1.0 |
| Tri.equals(Tri) | 10.0 | 7.0 | 3.0 | 7.0 |
| Tri.findVarible(String) | 3.0 | 3.0 | 2.0 | 3.0 |
| Tri.march(Tri) | 9.0 | 6.0 | 3.0 | 6.0 |
| Tri.toString() | 0.0 | 1.0 | 1.0 | 1.0 |
| Tri.Tri() | 0.0 | 1.0 | 1.0 | 1.0 |
| Tri.Tri(ArrayList,int) | 0.0 | 1.0 | 1.0 | 1.0 |
| Tri.trisMul(ArrayList,ArrayList) | 6.0 | 1.0 | 4.0 | 4.0 |
| Total | 332.0 | 181.0 | 239.0 | 278.0 |
这一回最引人注目的是Element类中新增的这个求导函数derive,它的复杂度实在是太高了,这是因为笔者做了一件很不好的事情,我在Element类中的这个求导函数derive类中顺便把sin和cos的求导工作给做了,实际上,这应该再拆分到sin和cos当中去。
第三次作业的公测BUG是在处理自定义函数的时候出现的。原本我采用的是先读入完所有的自定义函数以后,再遍历hashMap依次对这些自定义函数进行化简。可是我忘记了一件事,hashMap在底层储存的时候和ArrayList是不一样的,储存进去的元素是不能够保持原有的顺序的。这就出现了问题 例如这样一个例子:
2
g(x) = x**2
f(x) = dx(g(x))
f(x) + g(x)
在这个例子中,按照读入的顺序应该是先解析g(x),再解析f(x),可是到了遍历hashMap的时候,先取出来的却有可能是f(x),但f(x)中嵌套的g(x)还没解析呢!所以f(x)的解析当然出现了问题。对于这个问题的解决,我采用了边读入边解析的办法,这样就能够保证自定义函数按顺序解析。
总的来说,第一单元的OO作业对于我来说,其实是一个挺艰难的过程,每一次都是从周中一直写写到快DDL截止才做出来。现在回头看看我堆出来的堪称屎山的代码,心中依然有些五味杂陈。不管怎么说,我至少“活下来”了,保证温饱问题永远是第一步(笑),保证了基本的生存问题以后,接下来才能想怎么过得更好(指优化)。 问题总是要一步一步解决的,逃避解决不了问题~


6

写的很好,受益匪浅,对我很有帮助


