


442
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享读入一系列自定义函数的定义以及一个包含幂函数、三角函数、自定义函数调用、求导算子的表达式,输出恒等变形展开所有括号后的表达式。
\t自定义函数相关(相关限制见“公测数据限制”)
求导算子相关(相关限制见“公测数据限制”)
其中
{} 表示允许存在 0 个、1 个或多个。[] 表示允许存在 0 个或 1 个。() 内的运算拥有更高优先级,类似数学中的括号。| 表示在多个之中选择一个。(。式子的具体含义参照其数学含义。
若输入字符串能够由“表达式”推导得出,则输入字符串合法。
附描述的不完善之处:未在任何地方说明函数定义与调用的参数数量需一致。
第一次作业需要完成的任务为:读入一个包含加、减、乘、乘方以及括号(其中括号的深度至多为 1 层)的多变量表达式,输出恒等变形展开所有括号后的表达式。
以形式化表述与表达式的数学含义为依据,直接对表达式进行解析并储存于表达式树中,并引入多项式类完成表达式的计算。
BigInteger 系数为值的 HashMap,重写单项式类的 hashCode 与 equals 方法实现单项式等价的判断,完成新项的直接插入。单项式类使用 String 而非三个数以分别保存 x、y、z 的指数,增强可拓展性。重写父类与子类的 toString 方法以实现自定义的输出化简。测试过程中发现优先级设置上的一些问题,主要原因是正负号的优先级与加减号不同,与幂的优先级产生了冲突,于是我根据前一个符号为操作数还是运算符来判定 +- 是正负号还是加减号,顺利解决了问题。而在与同学交流后发现大部分的同学都是使用正则替换来加入 $1$ 或 $0$ 以消除判断,这也值得借鉴,但感觉不够优雅(x)助教们也强调了正则替换的危险性,于是我仍沿用本身的思路。
修完后,在强测与互测中并未查出 bug。
在互测中 hack 到了房友的三个 bug,原因分别是未处理尾随空格、乘法后续项的解析长度有误、计算过程未合并导致超时。
第一次作业作为三次作业的基础,其重要性是不言而喻的。一个优秀的架构不仅能减少重构的风险,还具有更强的可拓展性,也更容易修复 bug,因此我在思考架构上花费的时间较长,但这也是值得的,为我后续增量开发的轻松奠定了基础。
第二次作业中需要完成的任务为:读入一系列自定义函数的定义以及一个包含幂函数、三角函数、自定义函数调用的表达式,输出恒等变形展开所有括号后的表达式。
Function 类存储函数 args 和 expr,使用 functions HashMap 实现从函数名到 Function 的映射,加入继承第一次作业节点 Node 类的 FuncNode 在每次函数调用时解析 Function 以规避树的拷贝问题,并实现了参数的替换方法。String 存储未知量,便直接将三角函数括号内部分进行解析并与其组成字符串,将其当作未知量处理,轻松解决。在强测与互测中并未查出 bug。
在互测中 hack 到了房友的多个 bug,原因包含未处理尾随空格、未考虑函数定义中等号左侧可能出现 \t 的问题、三角函数的指数为 $0$ 时无法正确处理、函数调用参数为幂函数时无法正确处理。
主要难度在于自定义函数的参数代入,在这方面表达式树有很大优势,可以直接将解析好的函数表达式中对应参数替换为实参解析得到的根节点。由于周末感染甲流没有精力完成三角函数优化,仅做了一些设想。
第三次作业中需要完成的任务为:读入一系列自定义函数的定义以及一个包含幂函数、三角函数、自定义函数调用、求导算子的表达式,输出恒等变形展开所有括号后的表达式。
在强测与互测中并未查出 bug。
在互测中 hack 到了房友的一个 bug 和指导书的一个 bug:
TLE 或 MLE。在此感谢 zyt 于 OO 群指出相关可能性与和我的数据交流。由于表达式树的优越性和优化摆烂了,非常轻松地完成了本次作业,并未感受到老师一直在说的”第三次作业最难“。
因第三次作业提交的代码并未达到理想情况,且存在未完成的三角函数优化,在提交截止后我又进行了一些修整,以下分析对象为修整后代码。
| Source file | Total Lines | Source Code Lines |
|---|---|---|
| ExpressionTree.java | 289 | 260 |
| MainClass.java | 14 | 13 |
| MultivariatePolynomial.java | 159 | 142 |
| Tools.java | 29 | 26 |
| Total | 491 | 441 |
可以看到,利用栈与表达式树的方法代码量较小。
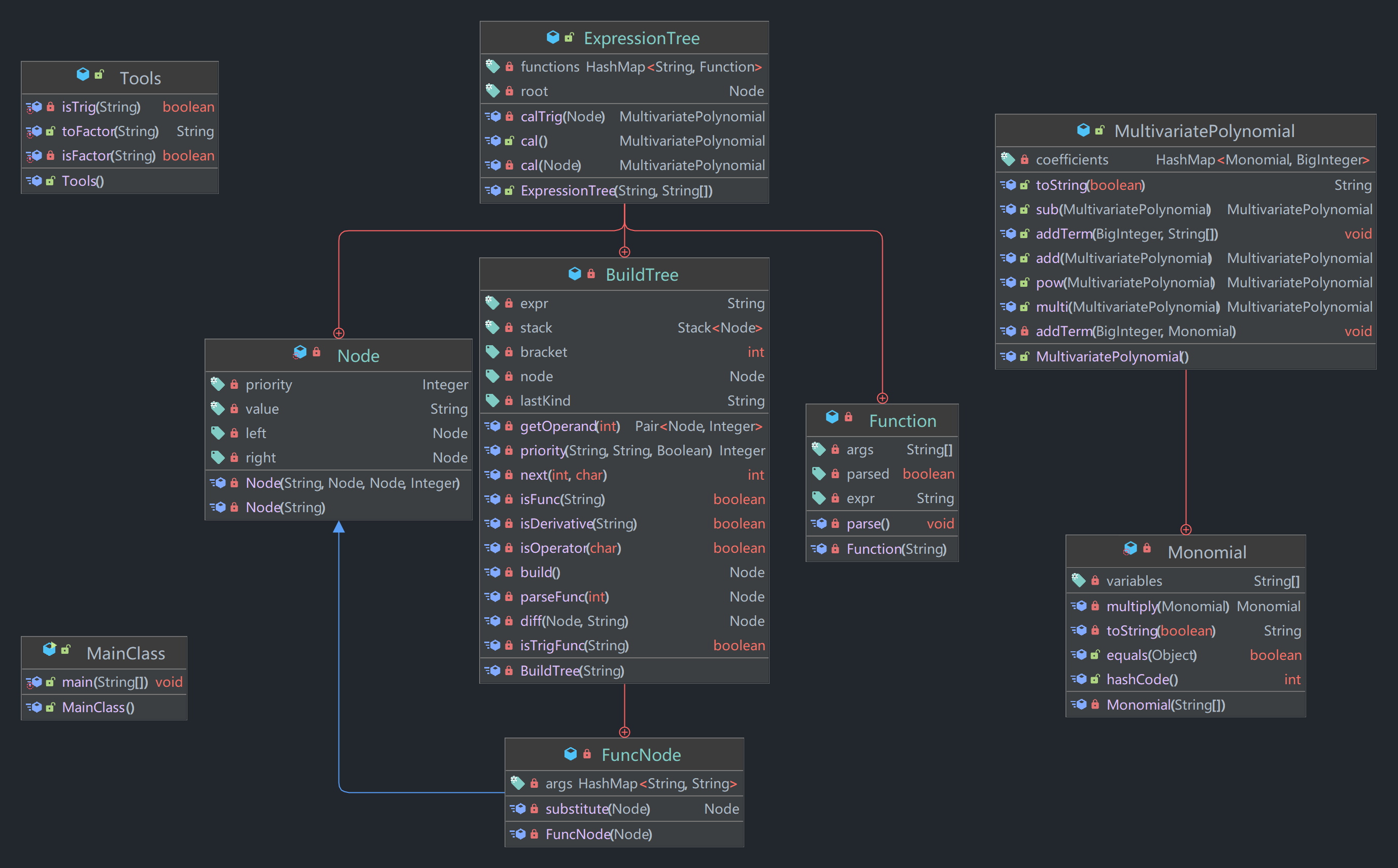
主要架构已在前文介绍。
| Method | CogC | ev(G) | iv(G) | v(G) |
|---|---|---|---|---|
| ExpressionTree.BuildTree.build() | 23.0 | 7.0 | 13.0 | 15.0 |
| ExpressionTree.BuildTree.BuildTree(String) | 0.0 | 1.0 | 1.0 | 1.0 |
| ExpressionTree.BuildTree.diff(Node, String) | 10.0 | 1.0 | 1.0 | 7.0 |
| ExpressionTree.BuildTree.FuncNode.FuncNode(Node) | 0.0 | 1.0 | 1.0 | 1.0 |
| ExpressionTree.BuildTree.FuncNode.substitute(Node) | 4.0 | 3.0 | 2.0 | 3.0 |
| ExpressionTree.BuildTree.getOperand(int) | 7.0 | 1.0 | 6.0 | 7.0 |
| ExpressionTree.BuildTree.isDerivative(String) | 0.0 | 1.0 | 1.0 | 1.0 |
| ExpressionTree.BuildTree.isFunc(String) | 0.0 | 1.0 | 1.0 | 1.0 |
| ExpressionTree.BuildTree.isOperator(char) | 1.0 | 1.0 | 1.0 | 3.0 |
| ExpressionTree.BuildTree.isTrigFunc(String) | 1.0 | 1.0 | 2.0 | 2.0 |
| ExpressionTree.BuildTree.next(int, char) | 7.0 | 1.0 | 4.0 | 6.0 |
| ExpressionTree.BuildTree.parseFunc(int) | 2.0 | 1.0 | 3.0 | 3.0 |
| ExpressionTree.BuildTree.priority(String, String, Boolean) | 8.0 | 7.0 | 4.0 | 11.0 |
| ExpressionTree.cal() | 0.0 | 1.0 | 1.0 | 1.0 |
| ExpressionTree.cal(Node) | 13.0 | 1.0 | 3.0 | 8.0 |
| ExpressionTree.calTrig(Node) | 12.0 | 1.0 | 5.0 | 7.0 |
| ExpressionTree.ExpressionTree(String, String[]) | 1.0 | 1.0 | 2.0 | 2.0 |
| ExpressionTree.Function.Function(String) | 0.0 | 1.0 | 1.0 | 1.0 |
| ExpressionTree.Function.parse() | 0.0 | 1.0 | 1.0 | 1.0 |
| ExpressionTree.Node.Node(String) | 0.0 | 1.0 | 1.0 | 1.0 |
| ExpressionTree.Node.Node(String, Node, Node, Integer) | 0.0 | 1.0 | 1.0 | 1.0 |
| MainClass.main(String[]) | 1.0 | 1.0 | 2.0 | 2.0 |
| MultivariatePolynomial.add(MultivariatePolynomial) | 1.0 | 1.0 | 2.0 | 2.0 |
| MultivariatePolynomial.addTerm(BigInteger, Monomial) | 3.0 | 1.0 | 3.0 | 3.0 |
| MultivariatePolynomial.addTerm(BigInteger, String...) | 0.0 | 1.0 | 1.0 | 1.0 |
| MultivariatePolynomial.Monomial.equals(Object) | 6.0 | 6.0 | 2.0 | 6.0 |
| MultivariatePolynomial.Monomial.hashCode() | 1.0 | 1.0 | 2.0 | 2.0 |
| MultivariatePolynomial.Monomial.Monomial(String...) | 0.0 | 1.0 | 1.0 | 1.0 |
| MultivariatePolynomial.Monomial.multiply(Monomial) | 0.0 | 1.0 | 1.0 | 1.0 |
| MultivariatePolynomial.Monomial.toString(boolean) | 12.0 | 1.0 | 9.0 | 10.0 |
| MultivariatePolynomial.multi(MultivariatePolynomial) | 3.0 | 1.0 | 3.0 | 3.0 |
| MultivariatePolynomial.MultivariatePolynomial() | 0.0 | 1.0 | 1.0 | 1.0 |
| MultivariatePolynomial.pow(MultivariatePolynomial) | 5.0 | 3.0 | 4.0 | 5.0 |
| MultivariatePolynomial.sub(MultivariatePolynomial) | 1.0 | 1.0 | 2.0 | 2.0 |
| MultivariatePolynomial.toString(boolean) | 16.0 | 5.0 | 11.0 | 13.0 |
| Tools.isFactor(String) | 1.0 | 1.0 | 2.0 | 2.0 |
| Tools.isTrig(String) | 7.0 | 1.0 | 4.0 | 6.0 |
| Tools.toFactor(String) | 1.0 | 1.0 | 1.0 | 2.0 |
| Total | 147.0 | 63.0 | 106.0 | 145.0 |
| Average | 3.868 | 1.658 | 2.789 | 3.816 |
CogC = Cognitive complexity(认知复杂度)
ev(G) = Essential cyclomatic complexity(基本圈复杂度)
iv(G) = Design complexity(设计复杂度)
v(G) = cyclonmatic complexity(圈复杂度)
复杂度超标主要在于表达式树类的建树方法及多项式类的 toString 方法。建树方法包含多种不同符号的处理,为表达式解析的核心方法;toString 方法包含输出时的各类小优化,特判较多。
自测为使用评测机对大量随机生成数据和针对性构造数据进行测试。
感谢[睿睿](TobyShiの博客 (toby-shi-cloud.github.io))提供的自动化测试工具与(我不知道blog链接)的 xc 哥哥的数据生成,我对其进行了些许魔改并持之以恒地push睿睿,使其更符合需求,能够自动完成多 java 文件的打包、投喂,包含自定义数据与随机数据多种模式。
评测机在 OO,至少在第一单元十分重要。即使无法完成正确性判断(虽然利用 sympy 包实现并不困难),也至少要实现自动多数据多文件投喂并输出,这能极大地增加你的自测与 Hack 效率。而数据生成器于第一单元反而是次要的,因为形式化表述较为严谨的特征,特殊及不同形式的数据往往很容易根据其来构造,只需要每种类型构造一些简单的例子就足够使用(根据 Hack 经验,多数成功 Hack 的样例都可以缩短到十几个到几个字符)
如前文所述,Hack 的数据主要在于对形式化表述与 cost 机制的理解和其特殊点的使用,比如 0**0、---1 等,将这些基本的特殊内容与新增要求组合便能顺利找到绝大部分 bug;同样,从相反的方向出发,攻击代码对输出表达式的优化也是另一种优秀的方法。灵活使用以上两种方法与评测机的随机测试,我找到了所有房友在互测中被发现的所有 bug,甚至发现了指导书的不完善之处。
你说得对,但是

/*TODO*/
根据我的不完全统计,我可能是极少数没有使用标准的递归下降方法的有效作业。除去和同学讨论的不便外,却也为我带来了不一样的体验。
在三次迭代中,我深深体会了优秀的架构的重要性,也体会到了面向对象程序设计强大的可维护性、可重用性与可拓展性。
课程组的助教与老师们好,注意到老师们一直在强调 OO 先导课的重要性,希望在下一届能将该课程开放给所有希望选课的人,而不是限定了名额后在下一学期质问选不到课的同学为什么不选课,并在第四周的课上放上一页PPT简单地写上几个大字:不能忽视先导课的价值




