


442
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享本次作业首先采用递归下降的方法读取表达式,并在读取的过程中预处理完自定义函数和求导因子,将结果作为表达式因子存入,之后对总表达式进行递归展开,得到消去所有不必要括号的表达式,最后将其进行化简处理,笔者在本单元只实现了合并简单同类项,合并系数和指数,以及判断项是否为零的化简方式。
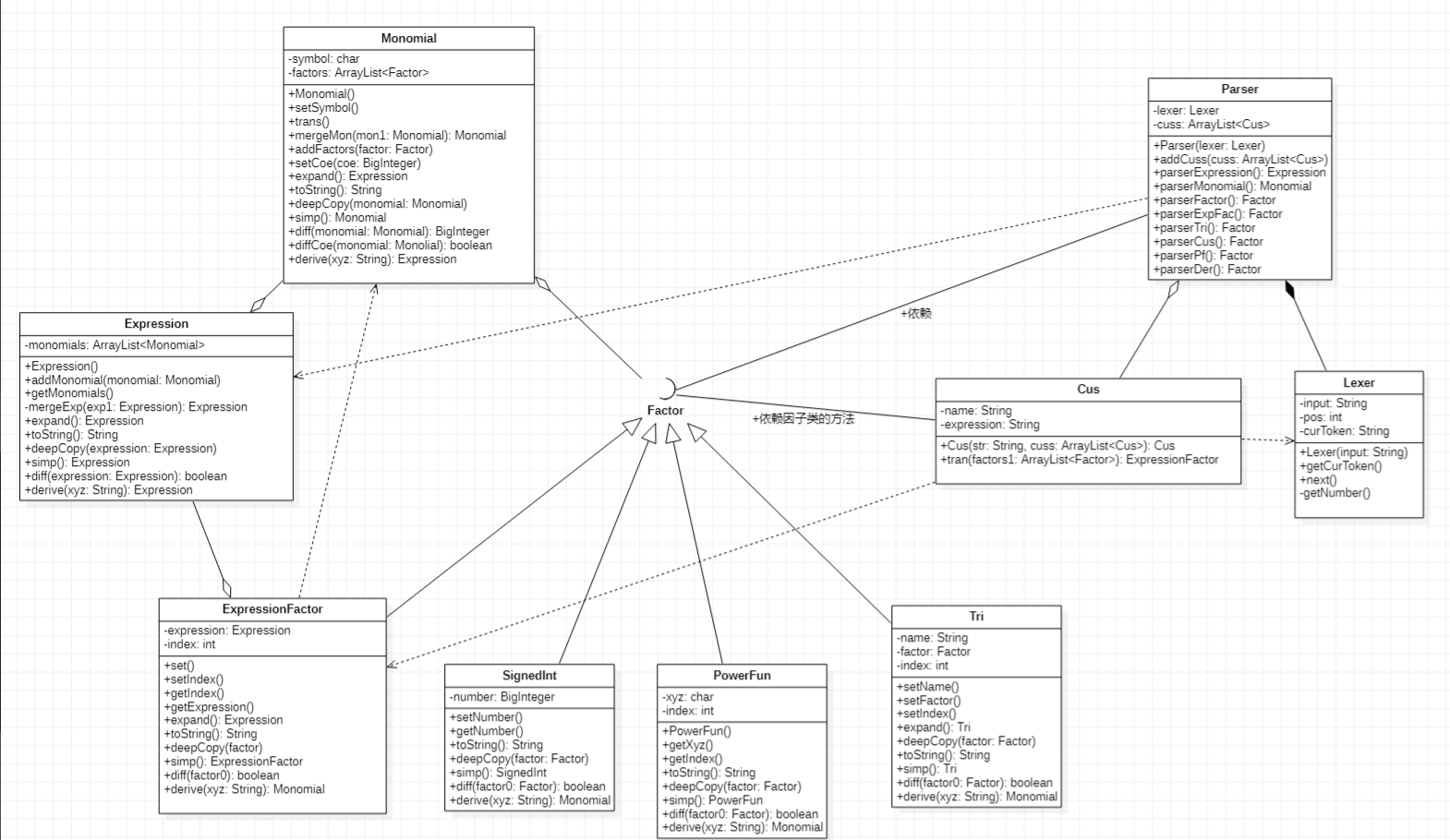
其中,lexer和parser类负责递归下降解析,对题目分析后可知,表达式由若干项组成,项由若干因子组成,可以直接使用ArrayList进行存储,再针对每一种因子构造子类,并对每一个因子类实现化简、深克隆、比较等方法,以实现化简、求导等操作的递归调用。Cus类存储了自定义函数的模板,同时实现了调用自定义函数功能,考虑到自定义函数调用可以在读取时直接代入,因此在parser类中加入Cus数组,放置已经定义过的自定义函数模板,在解析时直接完成调用。
由于每一种类的设计目的都比较简单直接,在初步设计以及迭代时构思较为简便,可拓展性比较强,但由于每一种处理方法都要在各个类中实现一遍,在修改时容易产生遗漏。
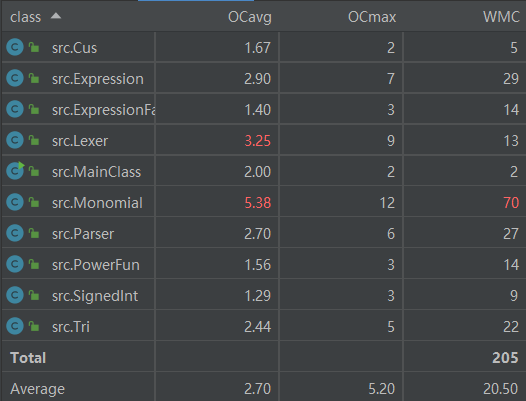
从类复杂度角度分析,Monomial的复杂度过高,可能时由于在多项式展开、化简和求导过程中都需要多次进行嵌套循环遍历和递归。
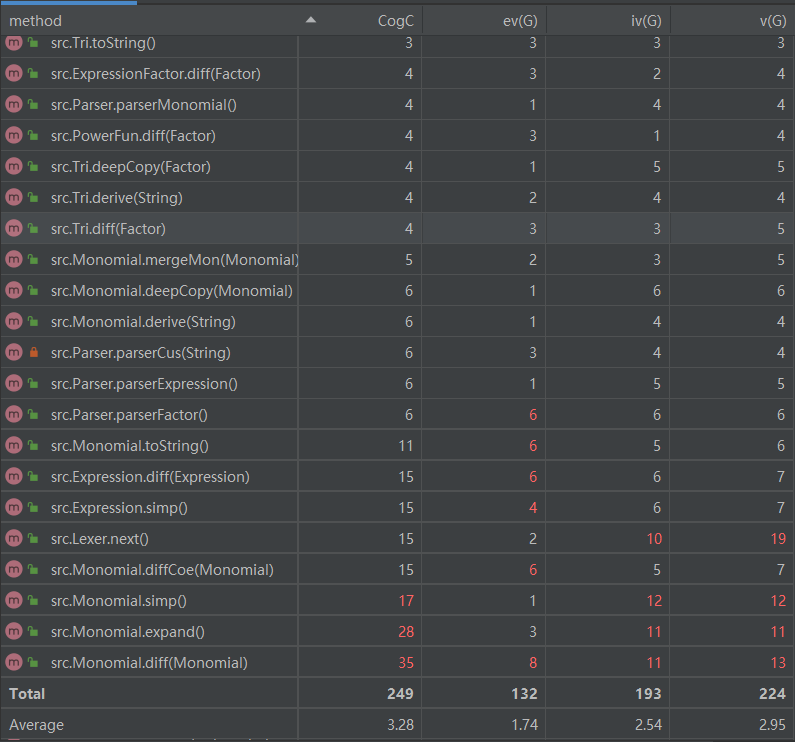
复杂度较高的方法主要集中在Monomial类中。
第一次作业大致确定了设计框架,第二次作业主要新增了Cus类和Tri类,以实现自定义函数和三角函数的相应功能,第三次作业对各个类新增求导方法,以完成求导因子的处理。
本次架构设计最大的问题就是很多问题没有在设计之初考虑清楚,导致之后的迭代开发复杂了不少。比如在设计项的属性时,笔者只是简单地将因子简单地堆放在一起,但如果能够考虑到每一个项都会有系数,将这个共性提取出来,额外添加一个系数属性,就会在进行合并同类项、求导等操作时容易很多,不用每次都傻乎乎地遍历一遍找系数。
此外,笔者还在第二次作业时经历了一次重构。由于第一次作业比较简单,当时的设计是各方法间均以字符串形式进行传参,而且字符串的生成方式是高度耦合在处理操作之中的,比如展开表达式时,返回的字符串结果是在展开过程中逐步生成的(由于当时参考了第一次训练的写法),而这种方式难以解决后续的复杂问题。重构后,用toString单独实现类转字符串,将这一操作从展开、化简等处理中剥离,同时,笔者顺便将化简部分从化简字符串重构为化简表达式类,相比之下,后者不需要考虑很多特殊情况,更容易实现迭代,但由于与之前的展开方法关联程度较高,容易出现关联性的bug。
| bug编号 | 所在作业 | 所在类 | 所在方法 | 原因简述 |
|---|---|---|---|---|
| 1 | 二 | Tri | Tri.expand() | 未对嵌套三角函数内因子展开 |
| 2 | 二 | Monomial | Monomial.simp() | 返回结果时漏掉了表达式因子 |
| 3 | 三 | Tri | Tri.derive() | 高幂次三角函数求导结果错误 |
| 4 | 三 | Monomial | Monomial.derive() | 未能正确找到其他因子 |
由于第一次作业的bug出现部分被重构掉了,未在此展示。
笔者在进行分析前一直觉得这几个bug出现的原因仅仅是自己的疏忽,很多基本功能出现了漏写或错写的问题,例如化简时,默认了展开后的表达式中不存在表达式因子,然而第二次作业中,三角函数的因子就可以使表达式因子,因而出现了问题。而分析后发现出现bug的方法和类确实与复杂度更高的方法和类有所重合,可能在设计上的简化确实会降低出现疏忽的概率。
由于笔者上学期选修了OO先导课,对于Java和递归下降有所了解,因此上手难度着实小了很多,然而依然犯了很多本不应该犯的错误。一是没有经过充分构思架构就开始动手,导致之后的迭代变得过于复杂;二是有很多细节没有考虑周全,很多方法没有考虑全所有情况,导致和后续迭代产生了难以预料的冲突;三是没有充分且系统地构造测试数据。


