





442
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享本次作业需要解析一个含有至多一层括号、可能含有xyz变量的表达式,最终输出不含括号的化简表达式。
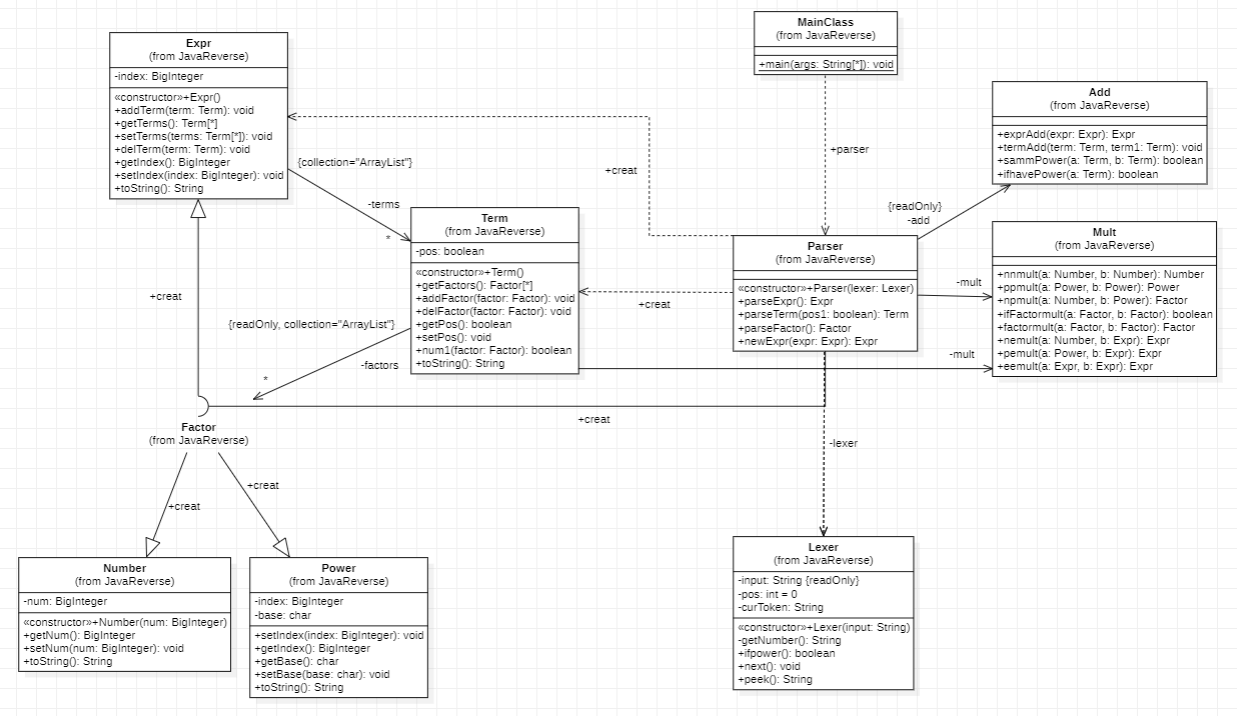
Parser中Expr-Term-Factor逐级分析,最终得到结果,要说明的是,对于嵌套函数,会在Factor层面递归到Expr层面。乘法会在Term层面进行,在Term每读取到一个Factor时都会进行乘法。加法会在Expr层面进行,将得到的表达式合并同类项。
MainClass:程序入口,对读入的字符串初步处理,去除" "和“\t”,并调用Lexer和Parser产生结果。 Lexer:词法分析器,将字符串中读取的字符根据不同情况返回数值。Parser:语法分析器,最复杂的程序,依次进行因子、项、表达式的处理。Mult:乘法器,统一定义了需要用到的各种乘法函数。Add:加法器,统一定义了化简中需要的函数。Factor:定义的接口,Term、Power、Expr类均从Factor实现。Number:数字因子类型,只含有记录具体数字的num变量。Power:未知量因子类型,含有底数base(只会为xyz其中之一)、指数index。Term:项因子,本次作业中并不从Factor实现,含有表达正负的pos和Factor类型数组(表示项中的因子)。Expr:表达式因子,也是最高层的因子,含有表示指数的index和Term类型数组(表示各项)。这种架构好处在于:
缺点也很多:

如图所示,代码主要集中在Mult、Add、Parser三个类中,这也是由于分类过少,功能函数集中在同一类的结果。
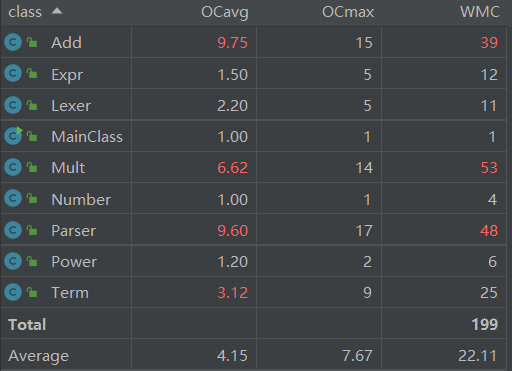
跟代码规模分析的结论一致。
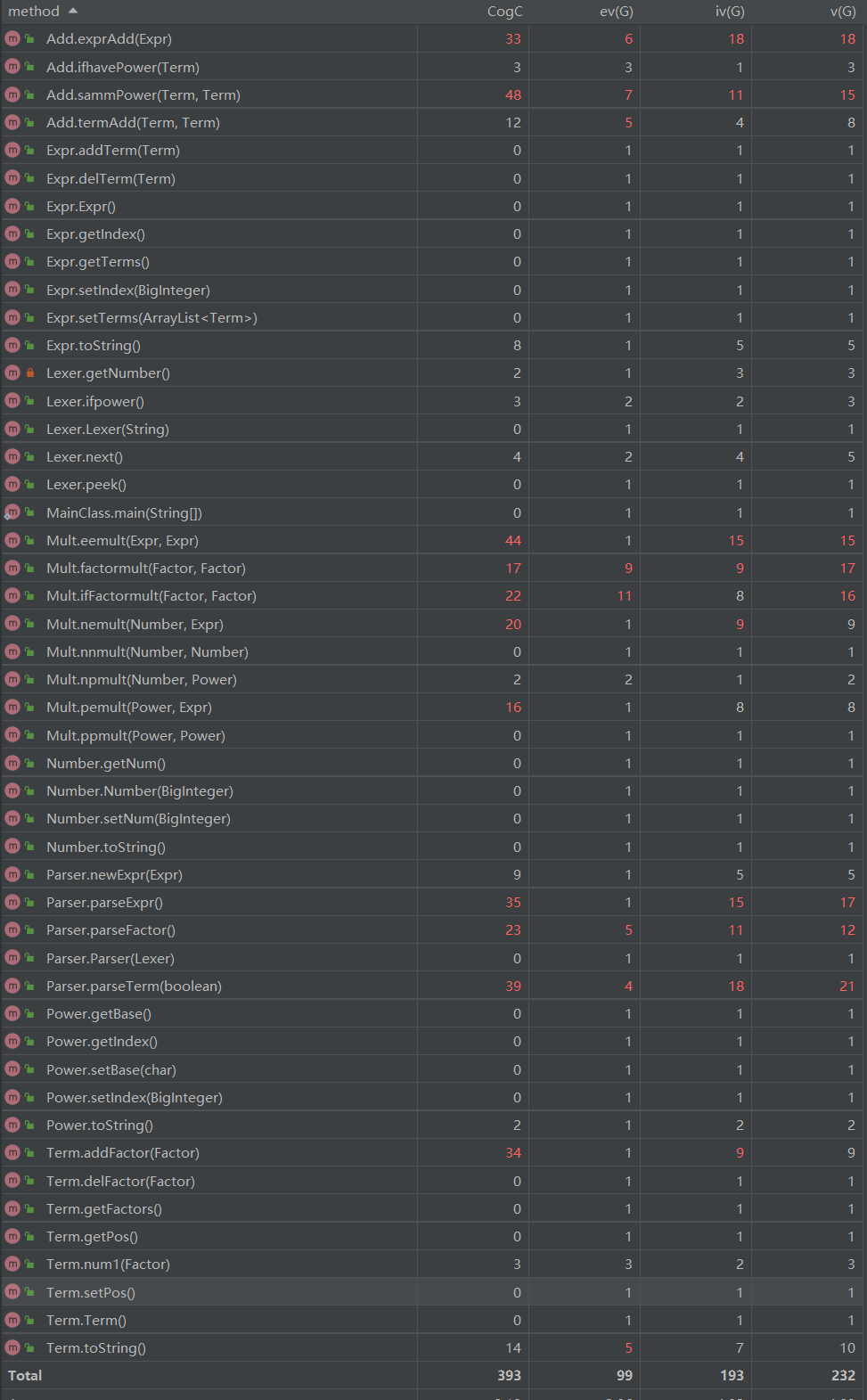
如图所示,复杂度较高的函数有
exprAdd:也就是在表达式层面化简的主函数,包含内容较多。sammPower:用来比较项的未知量是否完全一样的函数,有两个相同的三层嵌套循环,发杂度较高,可以将一个循环写成函数再使用。eemult:表达式乘表达式函数,调动的函数最多,考虑的情况最多。 parserExpr:分析表达式的函数,要考虑到返回的Term类型,复杂度较大。parserTerm:分析项的函数,复杂度高主要是因为乘法也在其中进行。addFactor:给项添加因子的函数,由于因子种类很多,因此代码量较大。 第一次作业查出的bug较少,是eemult和nemult中的符号错误问题,本来修改符号的层次在Term上不小心提前到Factor上,导致重复修改。
本次作业在上一次的基础上增加了自定义函数和三角函数以及嵌套括号。
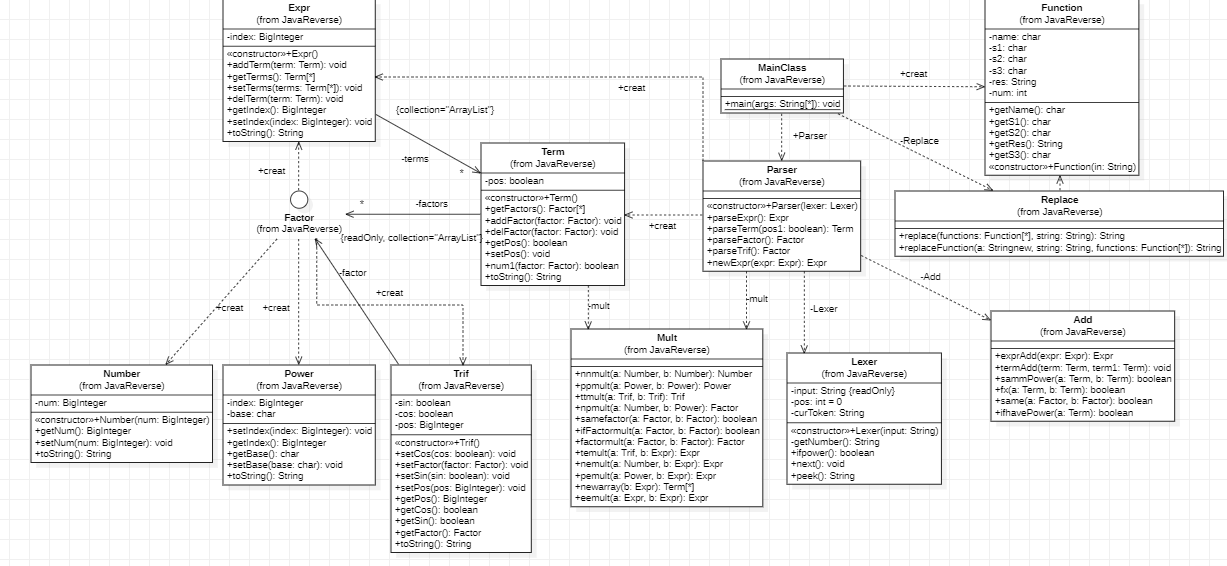
第二次作业是在第一次的基础上的,对于自定义函数,我是使用了字符串替换。先读取函数的函数名、自变量和函数主体,然后在要化简的表达式中直接替换,再将替换后的的字符串交给Parser处理。对于三角函数,我新定义了一种Trif类,含有指数、判断正余弦的变量和Factor类型的内容。而嵌套括号在第一次时就可以解决。
MainClass:程序入口,对读入的字符串初步处理,去除" "和“\t”,将表达式通过repalceFunction替换后再调用Lexer和Parser产生结果。 Replace:字符串替换的类,含有替换所用的函数。Lexer:词法分析器,将字符串中读取的字符根据不同情况返回数值。Parser:语法分析器,最复杂的程序,依次进行因子、项、表达式的处理。Mult:乘法器,统一定义了需要用到的各种乘法函数。Add:加法器,统一定义了化简中需要的函数。Factor:定义的接口,Term、Power、Expr类均从Factor实现。Number:数字因子类型,只含有记录具体数字的num变量。Power:未知量因子类型,含有底数base(只会为xyz其中之一)、指数index。Trif:三角函数因子类型,含有指数pos和判断正余弦的变量以及内容物factor。Term:项因子,并不从Factor实现,含有表达正负的pos和Factor类型数组(表示项中的因子)。Expr:表达式因子,也是最高层的因子,含有表示指数的index和Term类型数组(表示各项)。 相较于上次实验,本次的改动对原有部分改变很小,只是增加了新的类型,而自定义函数在开始解析前就已经替换,这样的好处有:把自定义函数处理与主函数分开,避免影响主函数出现bug,使Parser不至于过分复杂;坏处有:自定义函数只是简单的替换,在下次作业中,无法处理求导因子,还需改进,由于大体分出两个处理部分,代码量大,复杂度高。
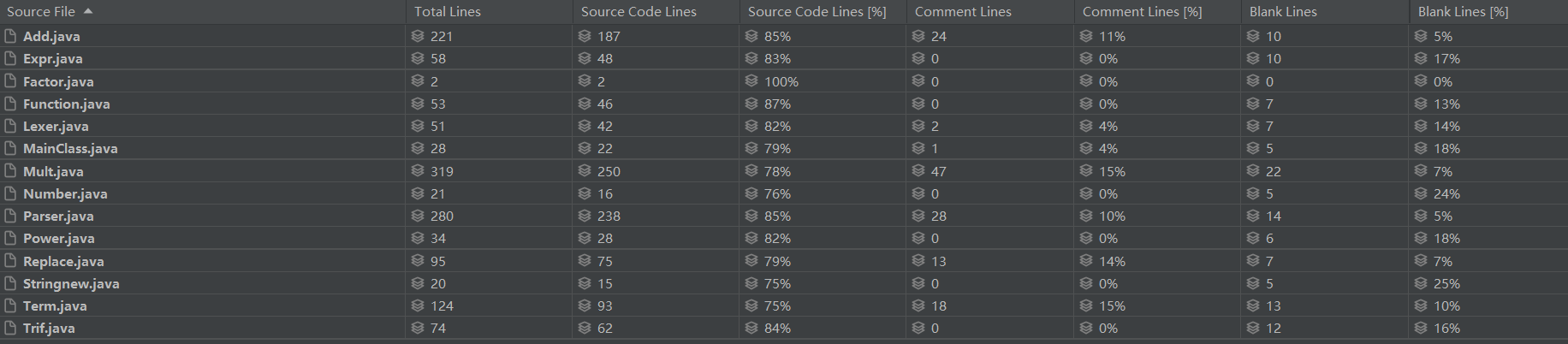
如图所示,代码主要集中在Mult、Add、Parser和Replace类中,说明分类过少,功能函数集中在同一类,Replace的代码量也说明了不在主程序中替换会增多操作。
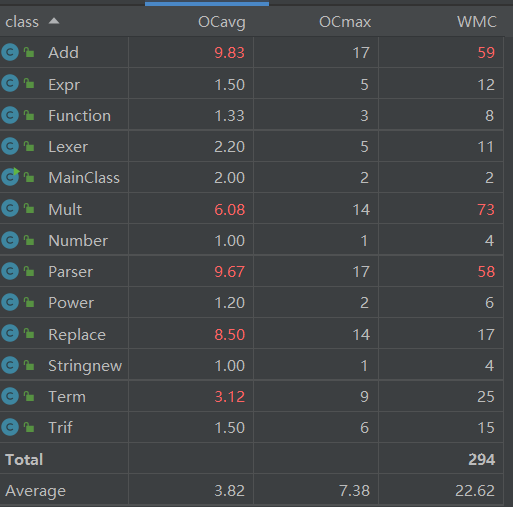
跟代码规模分析的结论一致。
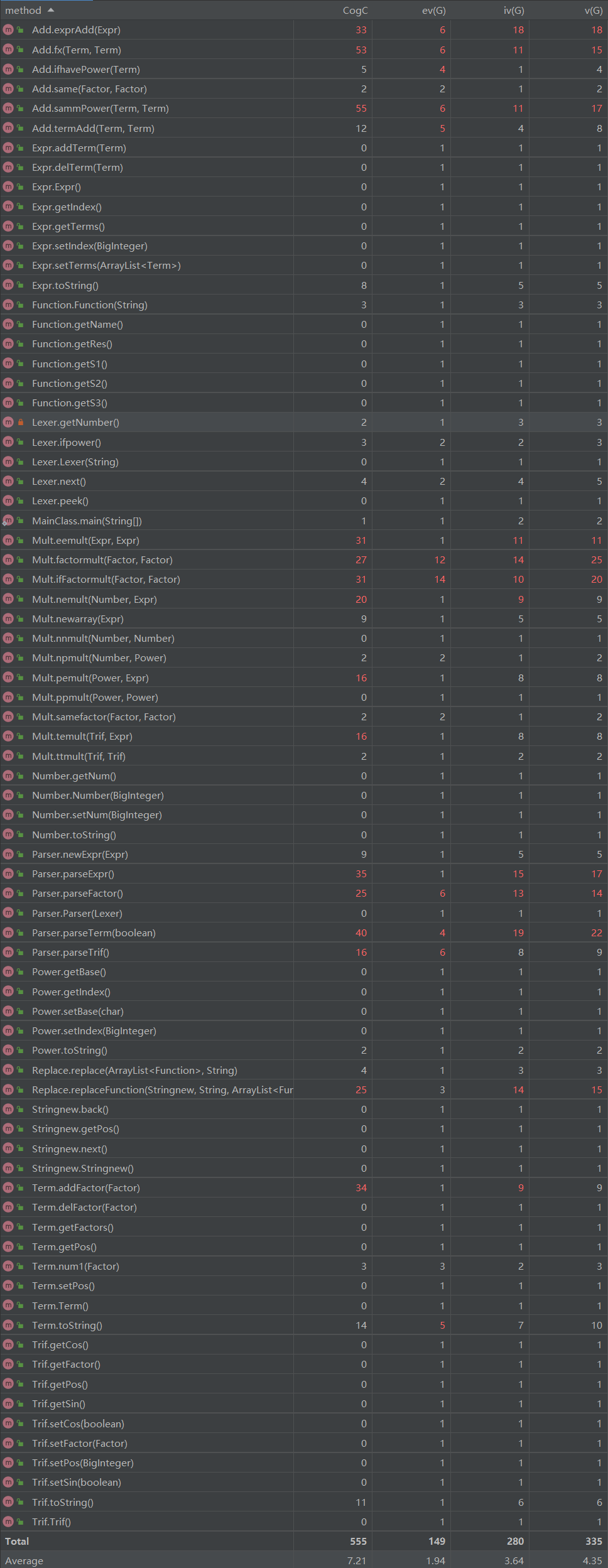
如图所示,复杂度较高的函数有
exprAdd:也就是在表达式层面化简的主函数,包含内容较多。sammPower:用来比较项的未知量是否完全一样的函数,有两个相同的三层嵌套循环,发杂度较高,可以将一个循环写成函数再使用。eemult:表达式乘表达式函数,调动的函数最多,考虑的情况最多。 parserExpr:分析表达式的函数,要考虑到返回的Term类型,复杂度较大。parserTerm:分析项的函数,复杂度高主要是因为乘法也在其中进行。addFactor:给项添加因子的函数,由于因子种类很多,因此代码量较大。强测试和互测中共有两个bug,首先是Trif读取内容时使用了parserFactor,所以如果读取Term时会报错,因此可以直接改为parserExpr。另外一个发生在乘法中,当Term中含有多个Expr因子时可能无法完全乘开,需要将if改成while进行循环即可。这两个错误都发生在复杂度高的函数中,也说明这样的函数不利于检查纠错。
本次作业在前两次的基础上增加了导数因子和嵌套函数。
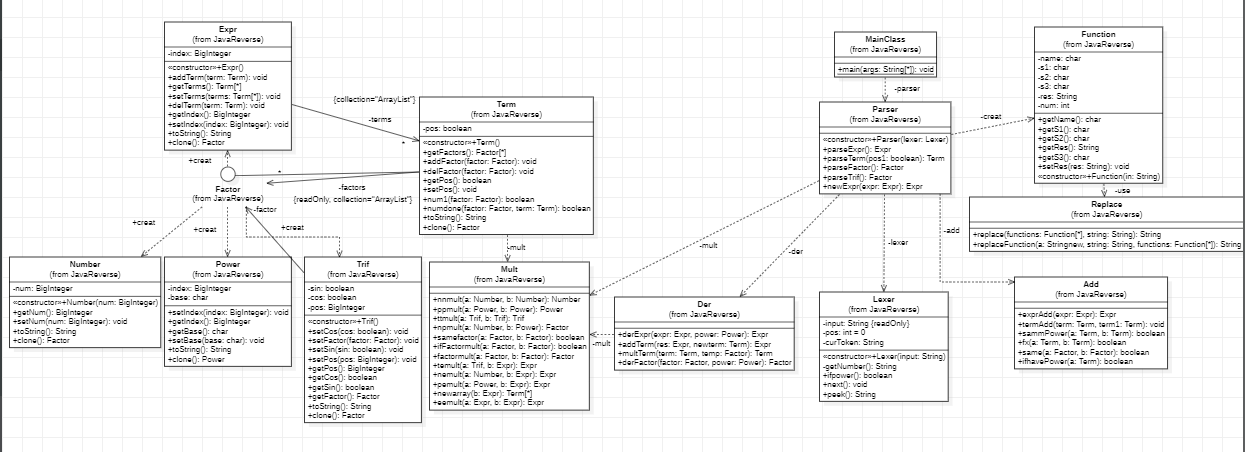
结构变化相较第二次很少,只是修改了功能函数。由于第二次自定义函数只有简单的替换,第三次先把函数放入parser中解析(包含求导,嵌套的一系列操作),之后使用toString再进行字符串替换。同时,吸取前两次经验,给各个类增加深克隆函数clone。
MainClass:程序入口,对读入的字符串初步处理,去除" "和“\t”,将表达式通过repalceFunction替换后再调用Lexer和Parser产生结果。 Replace:字符串替换的类,含有替换所用的函数。Lexer:词法分析器,将字符串中读取的字符根据不同情况返回数值。Parser:语法分析器,最复杂的程序,依次进行因子、项、表达式的处理。Mult:乘法器,统一定义了需要用到的各种乘法函数。Add:加法器,统一定义了化简中需要的函数。Der:求导大类,包含求导所用的函数。Factor:定义的接口,Term、Power、Expr类均从Factor实现。Number:数字因子类型,只含有记录具体数字的num变量。Power:未知量因子类型,含有底数base(只会为xyz其中之一)、指数index。Trif:三角函数因子类型,含有指数pos和判断正余弦的变量以及内容物factor。Term:项因子,从Factor实现,含有表达正负的pos和Factor类型数组(表示项中的因子)。Expr:表达式因子,也是最高层的因子,含有表示指数的index和Term类型数组(表示各项)。 优缺点分析:本次实验,本次的改动对原有部分改变很小,只是增加了新的求导大类,改动了自定义函数替换部分,利用了Parser,好处是节省了代码量,但是必须解析函数,可能出现意想不到的错误。另外,Der集中各种求导函数,好处是比较连贯清晰,但是相较于给每个类添加求导函数,更加复杂不方便。
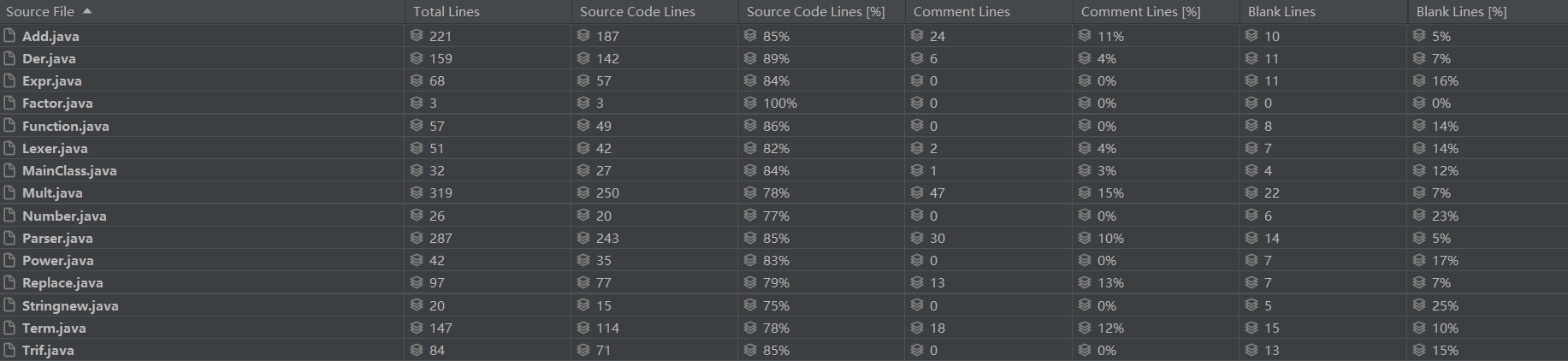
如图所示,代码主要集中在Mult、Add、Parser、Replace和Der类中,说明分类过少,功能函数集中在同一类。而且没有把求导函数分散到每个类中,算是一种失误。
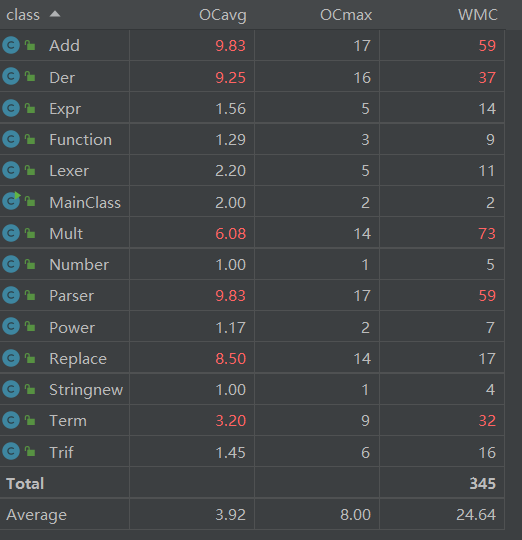
跟代码规模分析的结论一致。
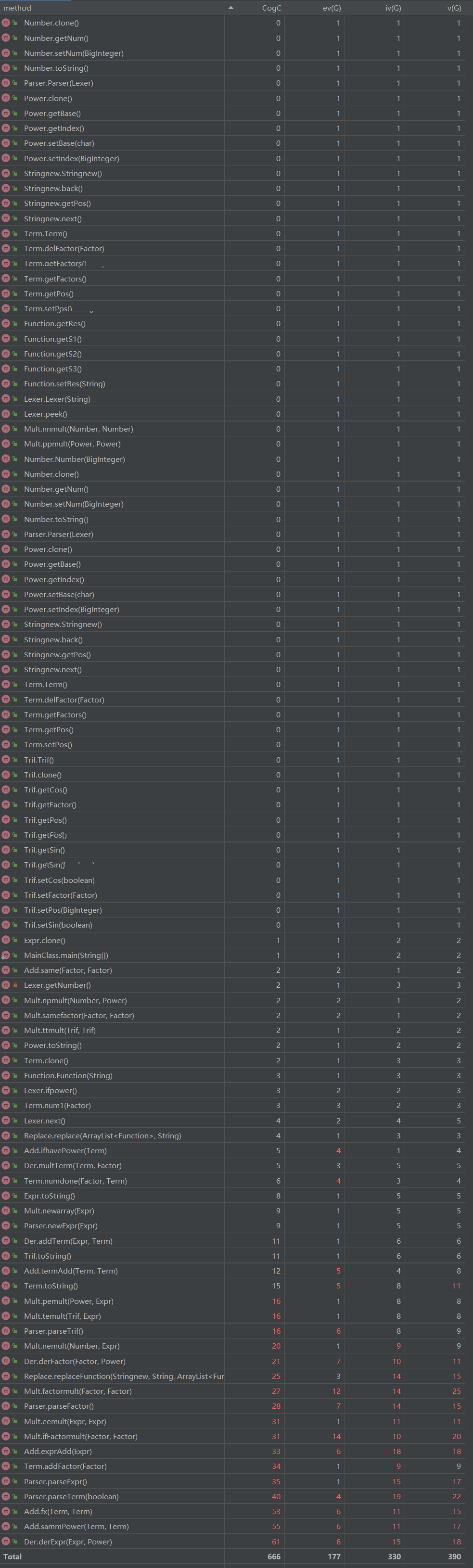
如图所示,复杂度较高的函数有
exprAdd:也就是在表达式层面化简的主函数,包含内容较多。sammPower:用来比较项的未知量是否完全一样的函数,有两个相同的三层嵌套循环,发杂度较高,可以将一个循环写成函数再使用。eemult:表达式乘表达式函数,调动的函数最多,考虑的情况最多。 parserExpr:分析表达式的函数,要考虑到返回的Term类型,复杂度较大。parserTerm:分析项的函数,复杂度高主要是因为乘法也在其中进行。addFactor:给项添加因子的函数,由于因子种类很多,因此代码量较大。 derexpr:整个系统中最复杂的函数,由于求导的函数较少,它包含了大部分的内容,因而最复杂,出错也最多。强测试和互测中共发现两个主要bug。
i和j,先删除i后,如果i小于j第二个元素的位置会自动变为j-1,因此需要分类讨论。Number类型,因此对于4*0会识别为4,所以需要改变循环条件。第一次作业中,已经采用了递归下降的方式,可以直接解析嵌套括号,减轻了后续的工作。对于读取到的表达式,通过在Parser中Expr-Term-Factor逐级分析。乘法会在Term层面进行,在Term每读取到一个Factor时都会进行乘法。加法会在Expr层面进行,将得到的表达式合并同类项。
第二次作业是在第一次的基础上的,对于自定义函数,我是使用了字符串替换,并新定义了一种Trif类。而Trif的内容,无脑定义为Expr,不利于化简但是写起来更加简单。这一次迭代可兼容性较差,因为只对函数进行简单的字符串替换,还需要进一步处理。
结构变化相较第二次很少,只是修改了功能函数。由于第二次自定义函数只有简单的替换,第三次先把函数放入parser中解析(包含求导,嵌套的一系列操作),之后使用toString再进行字符串替换。这个操作简化了大量的运算,但是程序运行时间大大加长。同时,吸取前两次经验,给各个类增加深克隆函数clone。
除了在第一次作业,笔者很少参与hack,这是由于自己很少编数据,这是一种欠缺,而在第一次成功hack了很多次,主要是根据别人具体的代码,寻找错误。而错误数据重点放在偏上,而不是复杂,通过x*11等可能诱发错误的极端数据发现bug。
第一单元的作业总体而言不是很满意。
首先,三次作业中没有进行重构,但不代表架构都是好的,相反,从第一次开始就非常复杂,而在之后没有改变原来的结构,使内容更加复杂,容易出错。
在对程序纠错上,我觉得问题很大。没有自己搭建测评机,测试数据也很少,使得每次强测都能发现新的错误。在下单元中,我会学习搭建测评机,毕竟仅靠人眼很难找到隐藏的错误。
在优化上,笔者做的内容也很少,只是最简单的合并等,连x**2都未替换为x*x,之后的作业我会投入更多时间。
最重要的是对于结构的思考,开始之前就应该想好全部的结构,多与他人交流,利用研讨课等机会,简化代码,及时重构止损。



