



442
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
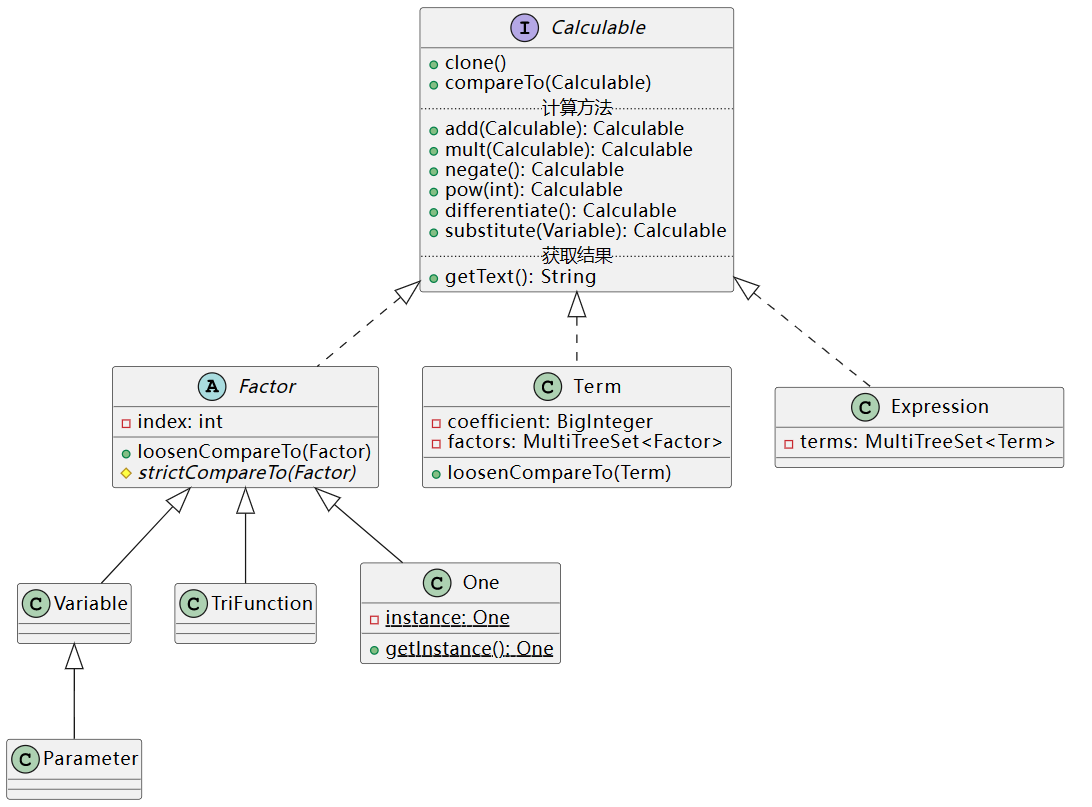
分享最终架构的核心类图如下图所示:(大部分抽象方法已在子类中省略;此外 getter、setter 也被省略)
设计了 Calculable 统一接口,Factor、Term、Expression 分别实现该接口,可以实现所有 Calculable 类的相互计算。之所以这样设计,是考虑到一件事情:子表达式化简的结果是不固定的,甚至可能是一个项,也可能是一个因子。设计为统一的 Calculable 接口后,只要保证 Calculable 的子类实现正确,在表达式 parse 之后展开的过程中就无需关心 Calculable 类内的各种结构*。换言之,就是将 Calculable 计算类与 parser 解耦,使一方的 bug 不会影响另一方。
*:Calculable 的用法示例如下:
Calculable result = new Expression(); // Expression 的默认初始值为 "0",res = 0 result = result.add(new Variable("x")); // res = 0 + x == x,此时 result 应是 Variable 类 result = result.mult(new Variable("y")); // res = x*y,此时 result 应是 Term 类这使得在 parser 解析并展开表达式时,只需要对每一个项展开的结果执行
res = res.add(term),即可得到展开完毕、且形式最简的内部表达。如果欲解析的表达式为3*x - 2*x,甚至可以得到x,它由一个Variable表示,但它们都是Calculable,在 parser 实现的过程中完全无需担心这一级 parser 返回的结果。
本架构支持对同类项进行自动合并,以及同类型的因子相乘自动添加指数。为了更高效地存储和处理 Term 中的 Factor,以及 Expression 中的 Term,设计了 MultiTreeSet<T> 类,继承自 TreeMap<T,T>,并实现了 Iterable 接口。
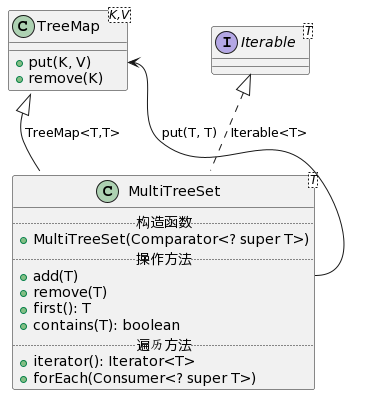
之所以选择 TreeMap 作为基类,是为了方便识别同类项。我的初衷是,希望它可以将所有的同类项识别为等价的,这样我就可以通过 map.contains(term) 方法,判断该表达式中是否有同类项了。由于我设计这套架构时已经到达了第二次迭代,出现了三角函数,为了处理三角函数的嵌套,增强这套设计方案的鲁棒性和可拓展性,我没有选择设计等价关系,而是设计了偏序关系。这套偏序关系定义在整个 Calculable 的全集上,任意两个 Calculable 的实例都可比,因而是一个全序,可以使用平衡树(TreeMap)存储。当且仅当两个 Calculable 完全相等时,在这一关系中定义它们相等。其定义我写在了代码中的 javadoc,在此也一并附上:
第一关键字: 因子 < 项 < 表达式;
表达式: 按所存储的所有项进行由小到大比较;
项: 按所存储的所有因子进行由小到大比较。系数作为第二关键字。
因子: 壹 < 变量 < 三角函数 <自定义函数 < 表达式因子,相同类型内部再排序,指数作为第三关键字;
变量: 参数 < x < y < z ,参数内部按String.compareTo(String)排序;
三角函数: sin < cos,同类型内按照内部因子的大小比较;
自定义函数: f < g < h,同类型内按照内部因子的大小比较;
如此,定义了一个无穷集合上的全序,无论三角函数如何嵌套,都可以在这个全序集中被比较。
这里要就 TreeMap 的作用做更详细的说明,用平衡树存储该全序集,能提升比较两个集合是否等价的效率。以比较两个 Term 是否等价为例,由于在 Term 内部所有的 Factor 都是按顺序排列的,因此比较两个 Term 的 Factor 集合是否完全相同,只需要同时按顺序遍历两个 Term 的 Factor 集合中的元素,一一对比。在研讨课中,我得知很多同学没有定义偏序,使用 List 存储 Factor,这样在比较两个集合是否相等时就需要 $O(n^2)$ 的复杂度,对每一个 Factor 都去另一个集合中遍历寻找是否存在。相较而言,本架构的方法只需要 $O(n)$ 的时间复杂度,是一个优点。
上面介绍了等价的比较,那么如何判断同类项呢?在我的实现中,如果要判断两个项是否等价,就是在判断两个项为同类项后,二者的系数 Term.coefficient 也相等。因此,只需要忽略二者的系数,去比较两个项是否有完全等价的因子集合,就可以判断二者是否为同类项。(对同类型因子的判断也同理。)
这个包里的类是用来做文法解析的,参考了 antlr4 的设计,首先将文本通过 Lexer 得到 Token 序列,然后将 Token 序列提供给 Parser 做递归下降,生成一个语法树,为每一个非终结符提供一个 Node 类。最后,在语法树的树根做 expand,它会递归调用每一层结点的 expand,最终返回展开后的 Calculable.
在第一次作业时由于缺乏设计,因此我直接在生成的语法树结点上做了括号展开,生成的最终结果也是语法树。然而语法树是一种和文法高度相关的结构,用作计算并不一定方便,因为在计算的同时还需要考虑中间过程如何用语法树结点表示,也就是在考虑如何和文法对应,这也就是没有将两个过程解耦——因此在第二次作业做了重构。但为了最大程度复用之前的代码,防止新的 bug,我还是沿用了语法树结点的生成,再遍历生成的语法树来产生 Calculable.
类图如下,可以发现相比 Calculable 的结构,这些结点显得很扁平,没有一个很清晰的继承关系。

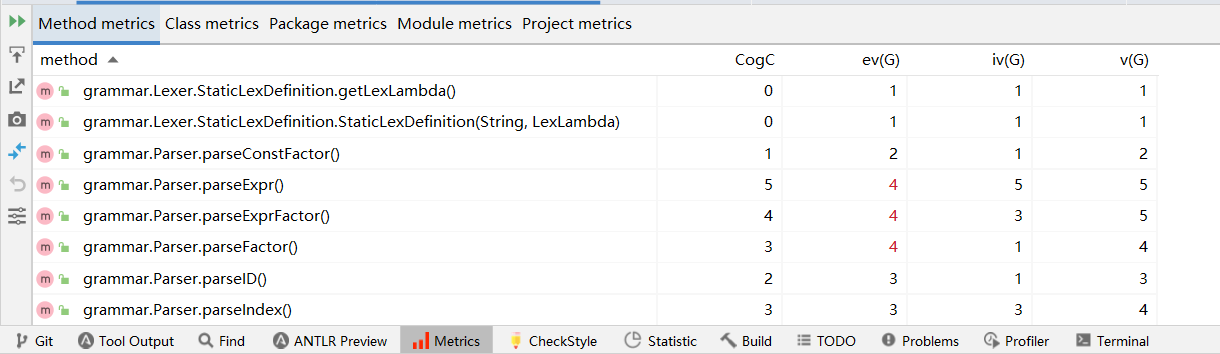
复杂度表如下图:

最终去除空行后代码行数达到了 1968 行之多(包括 50 行测试代码),如此多的代码行数难免在细节上出错,即便包装了很多的接口,但接口的调用规范也未必做了足够有效的设计。有一个错误就来源于对 Factor 构造函数的调用:我本在程序中约定,Factor 实例的 index 不能为 0,否则就应该使用 One 这个类来代替。然而,构造函数不可能返回相异的类,如果我要创建 x 的零次方,调用 new Variable("x", 0),它决计无法返回一个 One.getInstance(),而我又忘记在调用这个接口时检查这一点,导致产生未定义的行为。这确实使我意识到接口设计的重要性。最终,我采用类似工厂模式的方法,如采用静态方法 TriFunc.generate() 来代替构造函数传入指数,解决了这个问题。
此外,本次作业中采用递归下降算法的部分圈复杂度比较高,可能和算法本身的特点有关。
我 checkout 回了第一次作业时混乱的代码,又检测了圈复杂度,结果标红的代码也只有递归下降的部分。
接口设计很重要!我在设计接口时,对鲁棒性的考量,仅仅止于在方法实现中添加 assert,这并不是一个足够好的办法,并不能防止 bug 的发生;实际上,更应该做的是在设计接口时就防止用户(包括你自己)调用时忘记自己的调用约定。这似乎在工程设计上,叫做“防呆设计”吧?
第二次作业的重构中将 Calculable 计算类与 parser 解耦的做法令我在增量开发时十分愉快。然而,也需要注意,接口最终的易用性,与其设计、实现的复杂性,往往是一个跷跷板的两端。我设计 Calculable 类花费了很多的精力,实现代码花了更长的时间,现在依然认为没有能选择最好的实现方式,感觉我应该要使用更先进的设计模式。这也有待我在后面的学习、实践中进一步提升自己的能力了。

接口设计很重要!我在设计接口时,对鲁棒性的考量,仅仅止于在方法实现中添加 assert,这并不是一个足够好的办法,并不能防止 bug 的发生;实际上,更应该做的是在设计接口时就防止用户(包括你自己)调用时忘记自己的调用约定。这似乎在工程设计上,叫做“防呆设计”吧?
————第三单元讲的就是这部分的内容


