


442
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享第一单元的主题是表达式解析,主要围绕表达式恒等变形、相关括号展开及化简,帮助同学们掌握==层次化==、==模块化==的开发模式,对面向对象有初步认识。第一次任务是带括号的多变量多项式展开;第二次任务在前者的基础上,增添了嵌套括号、自定义函数以及三角函数因子的解析要求;第三次任务则加入了求导因子。
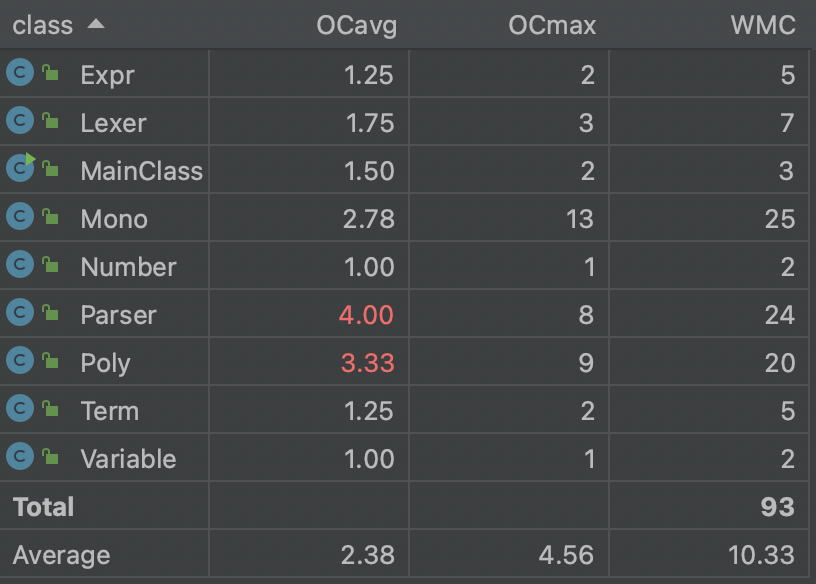
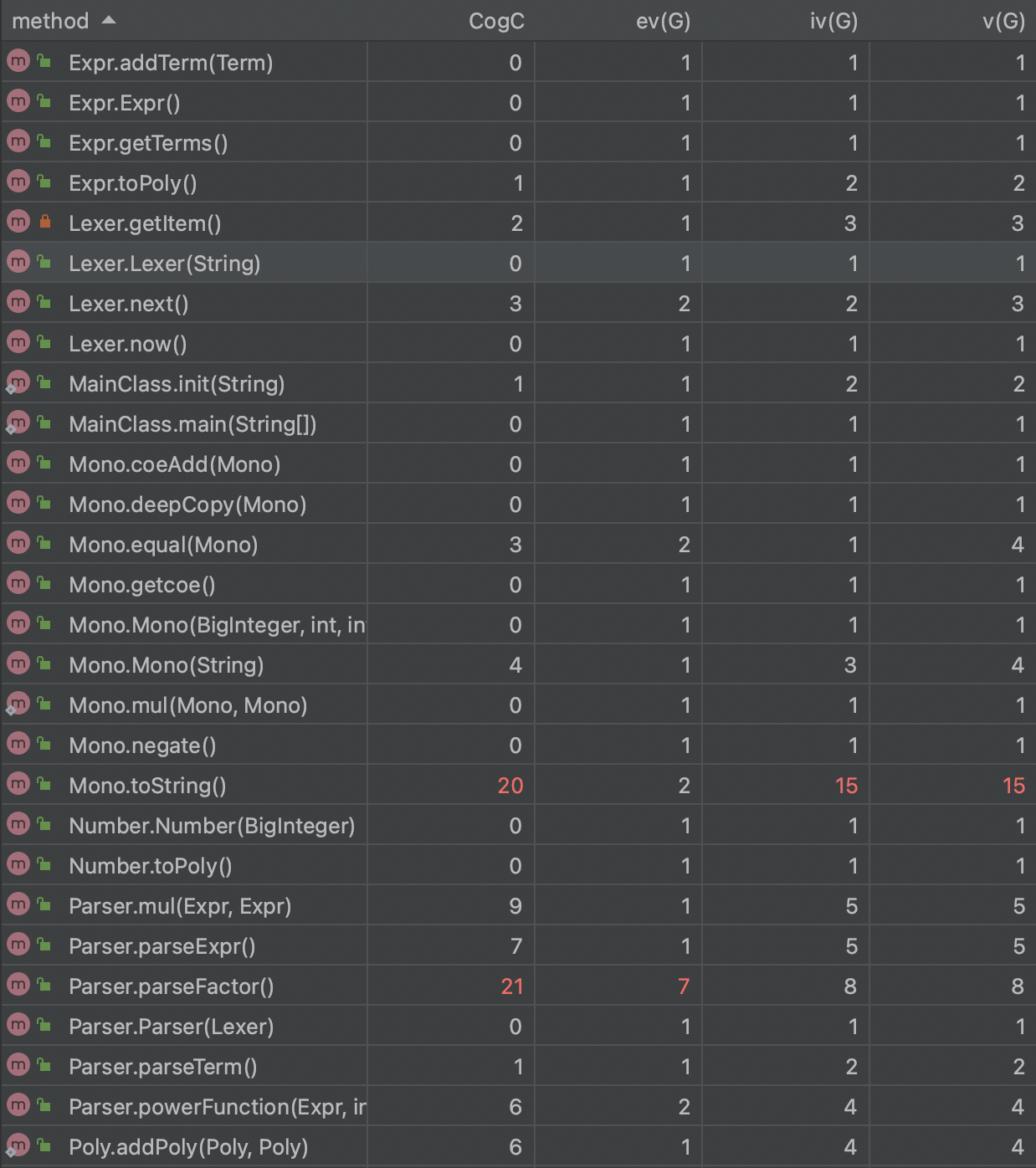
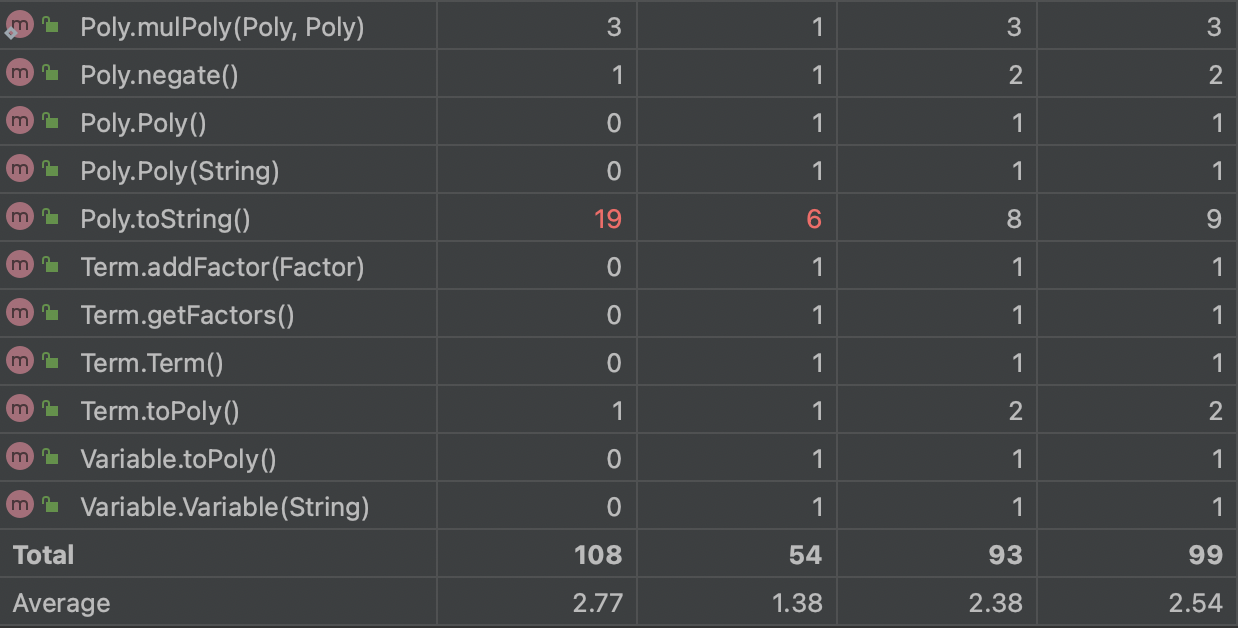
总体而言,三次任务代码量大,迭代性强,调试难度高,优化选择多样但复杂,因此建立一个优良的、可拓展性强的架构就极为重要。笔者在迭代开发过程中均采用递归下降的表达式解析方式,下面笔者将对三次作业进行逐步分析,并对本人的学习心得和体会进行总结。
第一次作业主要是关于多变量多项式的恒等变形括号展开
在初次完成第一次作业时,仅通过递归下降进行了繁冗的表达式展开,未进行计算处理等合并同类项,虽在评测中正确性检验完全通过但性能分为0,因此笔者在第二次作业前对第一次作业进行了小范围重构,此部分仅分析重构后代码,部分重构心得体会将在文末分享。
此部分输入预处理在第一单元中均适用
笔者将此部分放到了MainClass中进行统一的输入处理,对input进行init
public static String init(String input) {
String first = input.replaceAll("[ \t]", "");
//remove Blank character
String second = first.replaceAll("\\+\\+|--", "+").replaceAll("\\+-|-\\+", "-");
String third = second.replaceAll("\\+\\+|--", "+").replaceAll("\\+-|-\\+", "-");
//remove continuous "+""-"
String fourth = third.replaceAll("\\*\\+", "*").replaceAll("\\(\\+", "(");
//remove extra "+" behind "^","*","("
String fifth = fourth.replaceAll("\\*-", "*~");
//replace "*-" with "*~"
String expr = fifth.replaceAll("\\*\\*", "^");
//replace "**" with "^"
if (expr.charAt(0) == '+') {
expr = expr.substring(1);
}
return expr;
}
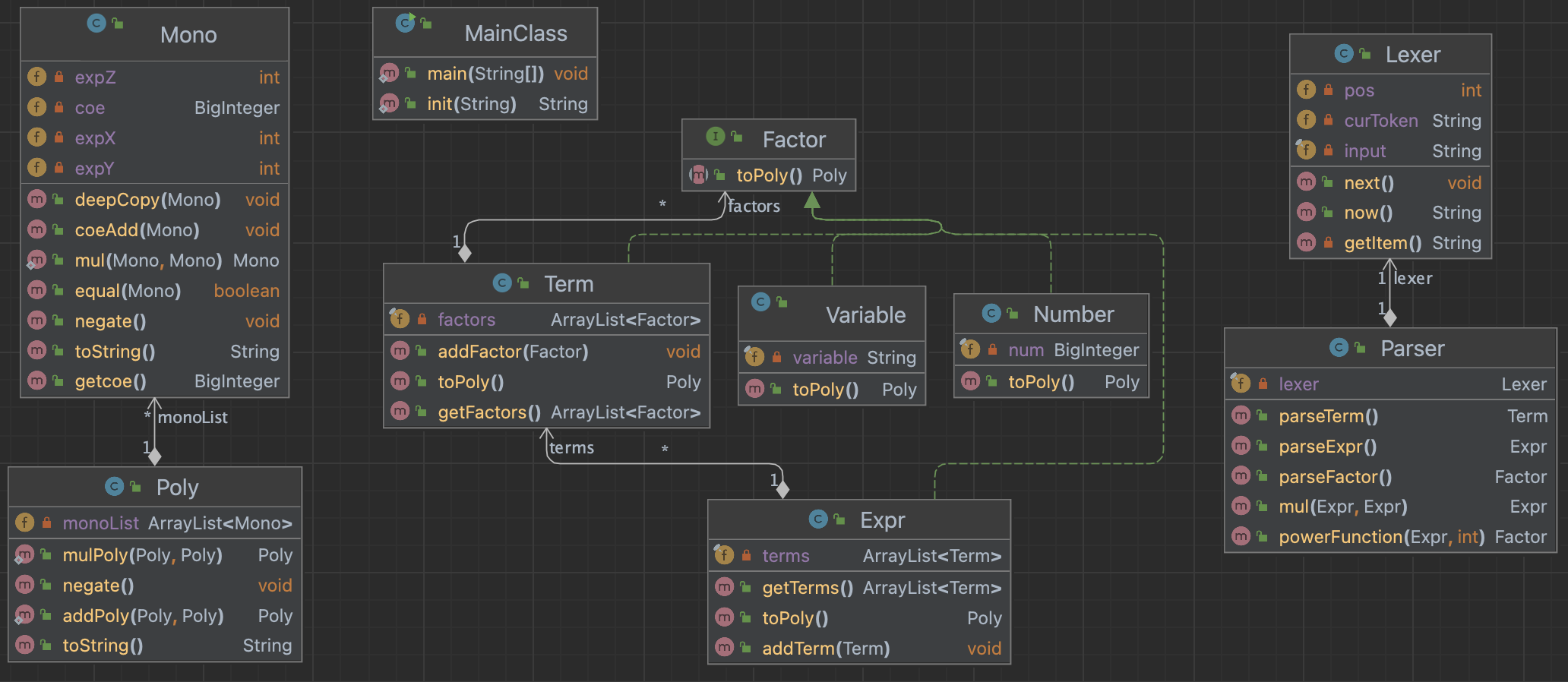
笔者对于表达式采用递归下降解析法。它主要包含了两个部分——==Lexer==(词法分析器)和==Paser==(语法解析器)。
Lexer主要是将表达式分解成一系列基本语法单元,而Parser主要是根据表达式的形式化定义,依靠Lexer分解出的语法单元,递归的生成表达式、项和因子。Paser语法解析中分为如下三个层次递归下降解析:
public Expr parseExpr() {
Expr expr = new Expr();
if (lexer.now().equals("-")) {
lexer.next();
Number neg = new Number(BigInteger.valueOf(-1));
Term term = parseTerm();
term.addFactor(neg);
expr.addTerm(term);
} else {
expr.addTerm(parseTerm());
} // Expr begin
while (lexer.now().equals("+") || lexer.now().equals("-")) {
if (lexer.now().equals("-")) {
lexer.next();
Number neg = new Number(BigInteger.valueOf(-1));
Term term = parseTerm();
term.addFactor(neg);
expr.addTerm(term);
} else {
lexer.next();
expr.addTerm(parseTerm());
}
}
return expr;
}
public Term parseTerm() {...}
public Factor parseFactor() {...}
经过分析,本次作业中表达式展开的最终结果其实是一个多项式的形式。可以发现,多项式中含有一系列的单项式,每个单项式都是 常数 $\times$ $x^X$ $\times$ $y^Y$ $\times$ $z^Z$ 这种形式。于是我们不难想到,我们可以再建立两个类——==Poly==(多项式类)和==Mono==(单项式类)。
这样之后,我们就可以在Expr、Term、Factor等类中都写一个toPoly()方法,将类中的内容转化为多项式。然后从factor.toPoly()一步步向上转化,那么最终可以通过expr.toPoly()来获得结果。
==Expr.toPoly()==
public Poly toPoly() {
Poly result = new Poly();
for (Term item : terms) {
Poly temp = Poly.addPoly(result,item.toPoly());
result = temp;
}
return result;
}
==深克隆== 因为运算过程中涉及对象的不同层次间依赖和适用,需采用深克隆!!
多使用static静态方法,避免浅克隆

参数含义:
第二次作业在第一次作业的基础上增加了三角函数,自定义函数以及一些数据的更新和细节。
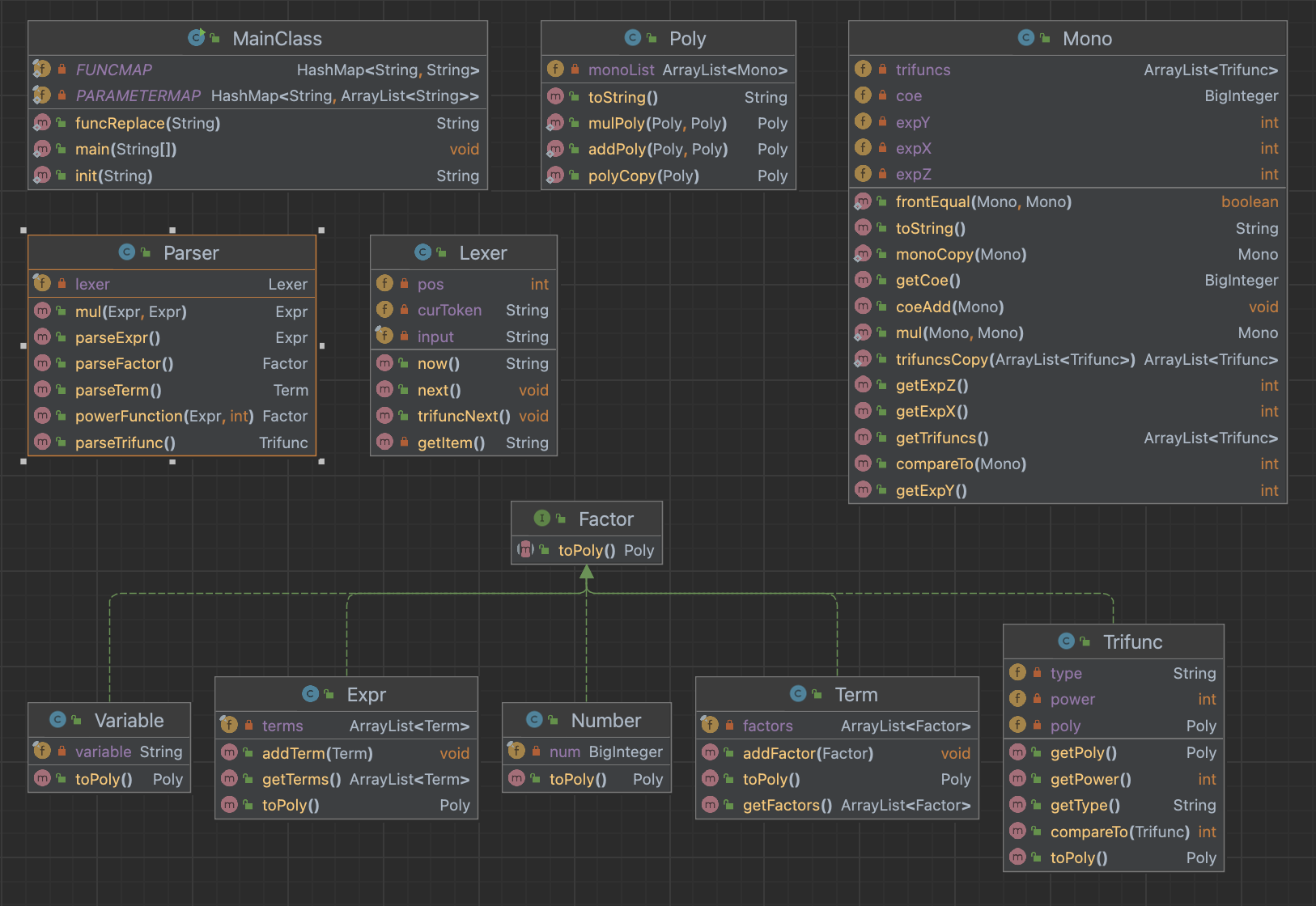
新增了三角函数类Trifunc,包含属性Poly存储内部表达式,type表示sin/cos类型,power表示指数。同时改变Mono单项式因子,在其中加入三角函数类Trifunc的列表。
为解析三角函数,我们在parser类中设置了一个**parseTrifunc()**方法,该方法在parseFactor()中被调用。解析逻辑是,当我们在parseFactor()中发现当前解析的因子为sin或者cos时,我们就可以调用parseTrifunc()方法,先将三角函数==括号内的因子==进行解析,然后解析该三角函数的指数,最后将解析结果保存到一个Trifunc对象中返回即可。
对于自定义函数,笔者在MainClass中直接暴力预处理掉了。
private static final HashMap<String, String> FUNCMAP = new HashMap<>();
// 函数名与函数体
private static final HashMap<String, ArrayList<String>> PARAMETERMAP = new HashMap<>();
// 函数名和参数
while (funcBody.indexOf('f') != -1 || funcBody.indexOf('g') != -1
|| funcBody.indexOf('h') != -1) {
funcBody = funcReplace(funcBody);
}
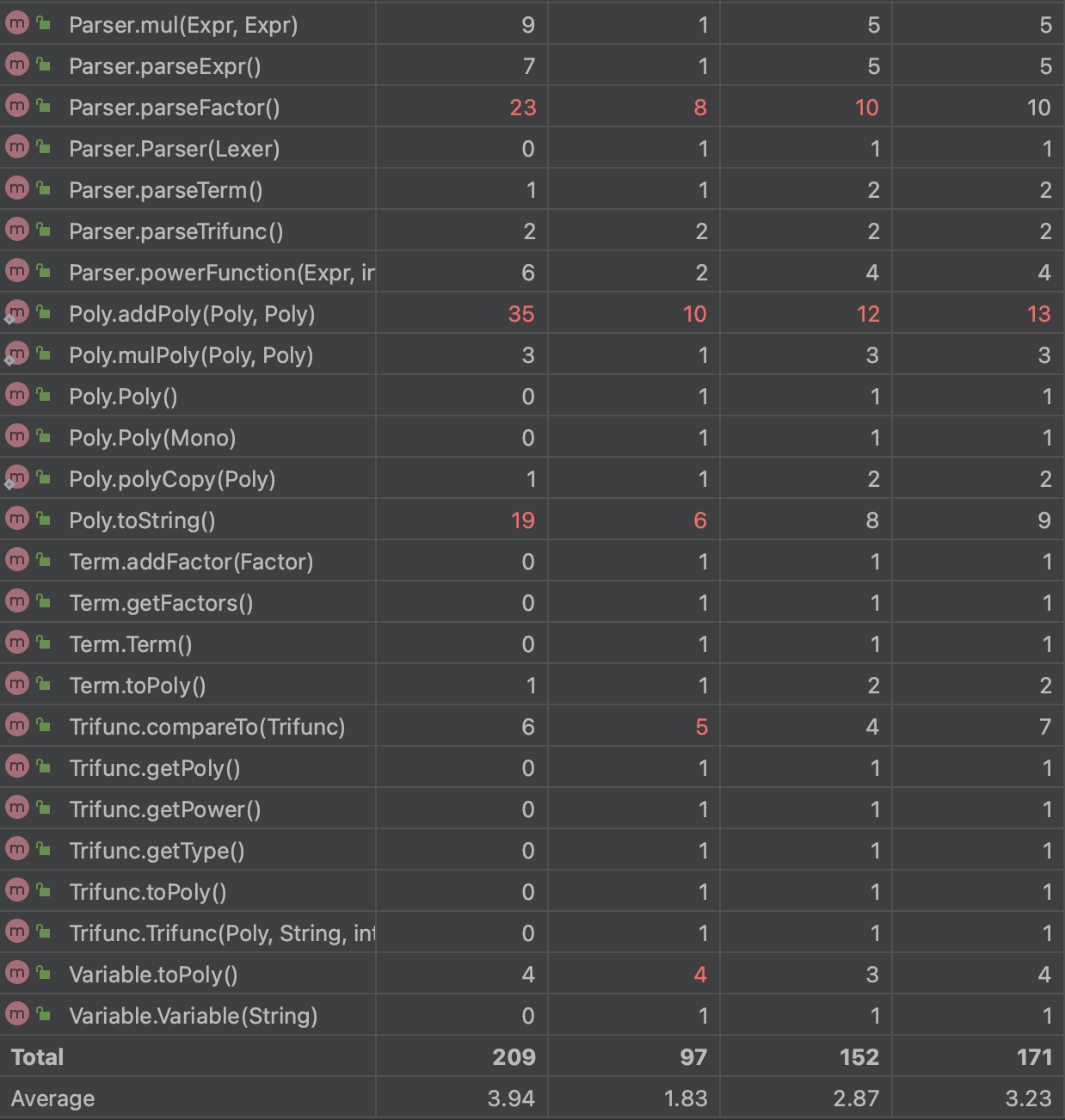
第三次作业在第一次和第二次作业的基础上新增了自定义函数的嵌套使用和求导因子。
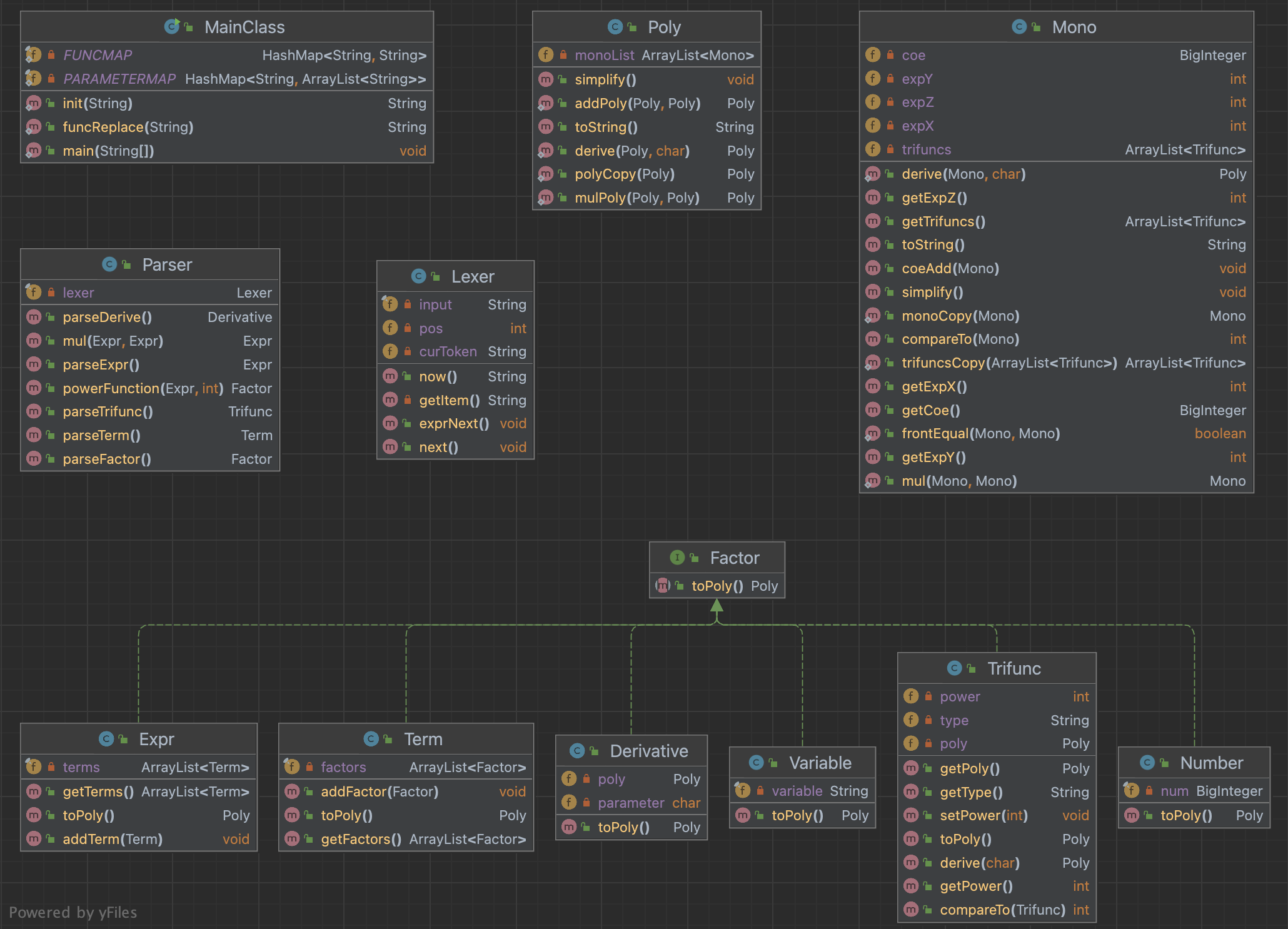
新增求导类==Derivative==,具有Poly属性存储需要求导的表达式,parameter属性存储求导变量。同时实现toPoly()方法实现统一输出转化。
具体求导在Mono与Poly类中通过derive方法实现。
public static Poly derive(Poly poly, char parameter) {
Poly polyResult = new Poly();
for (int i = 0; i < poly.monoList.size(); i++) {
polyResult = Poly.addPoly(polyResult, Mono.derive(poly.monoList.get(i), parameter));
}
return polyResult;
}
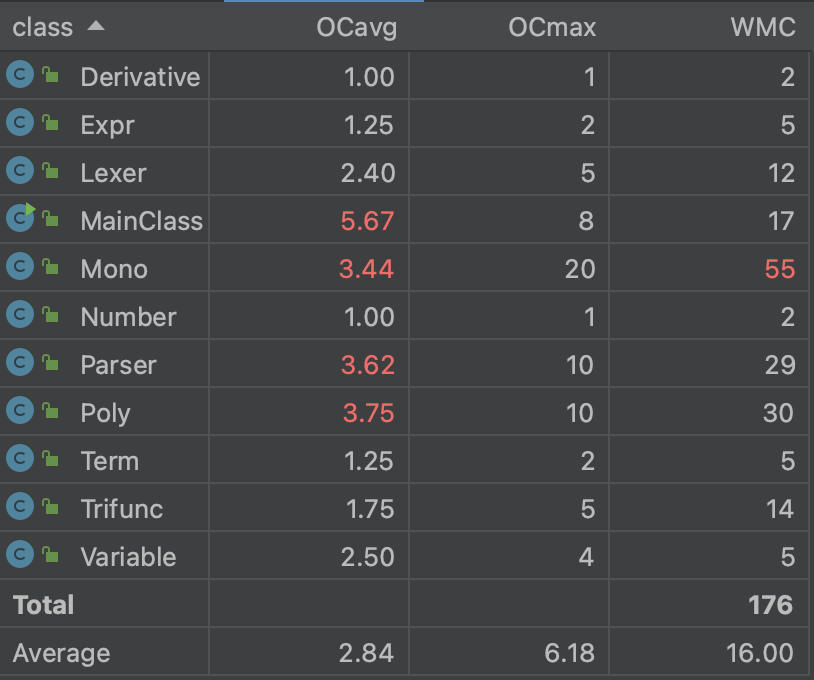
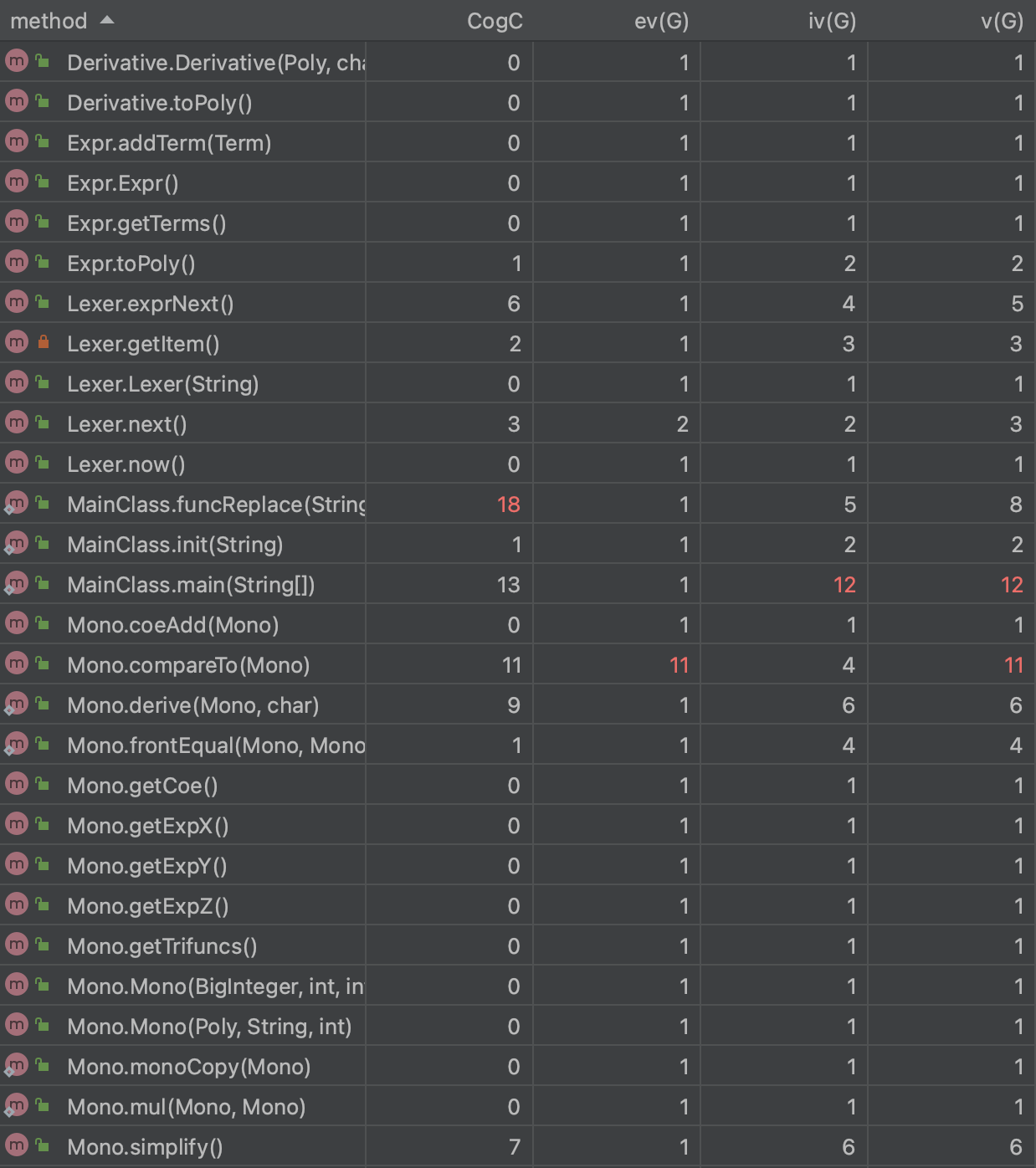
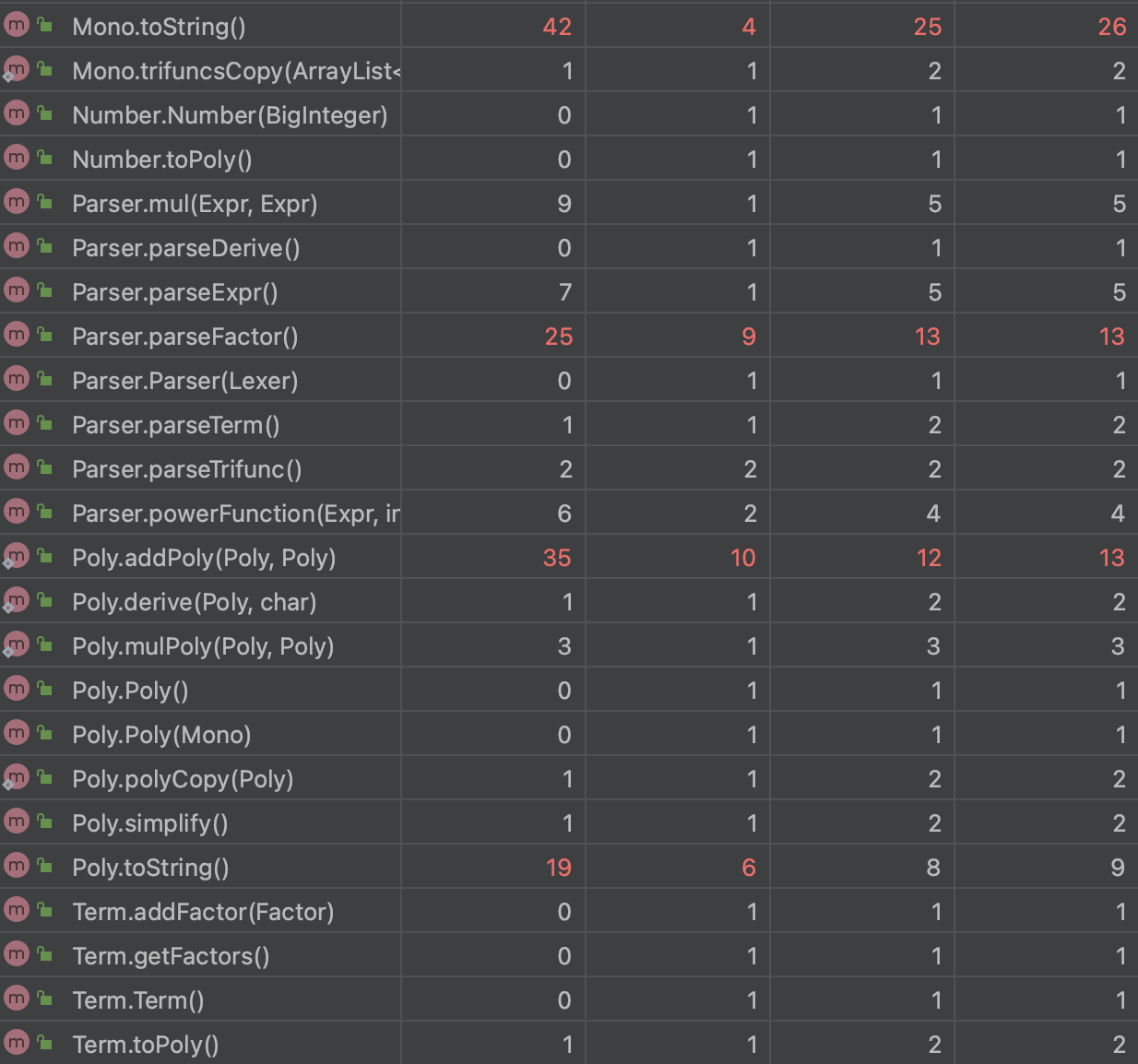
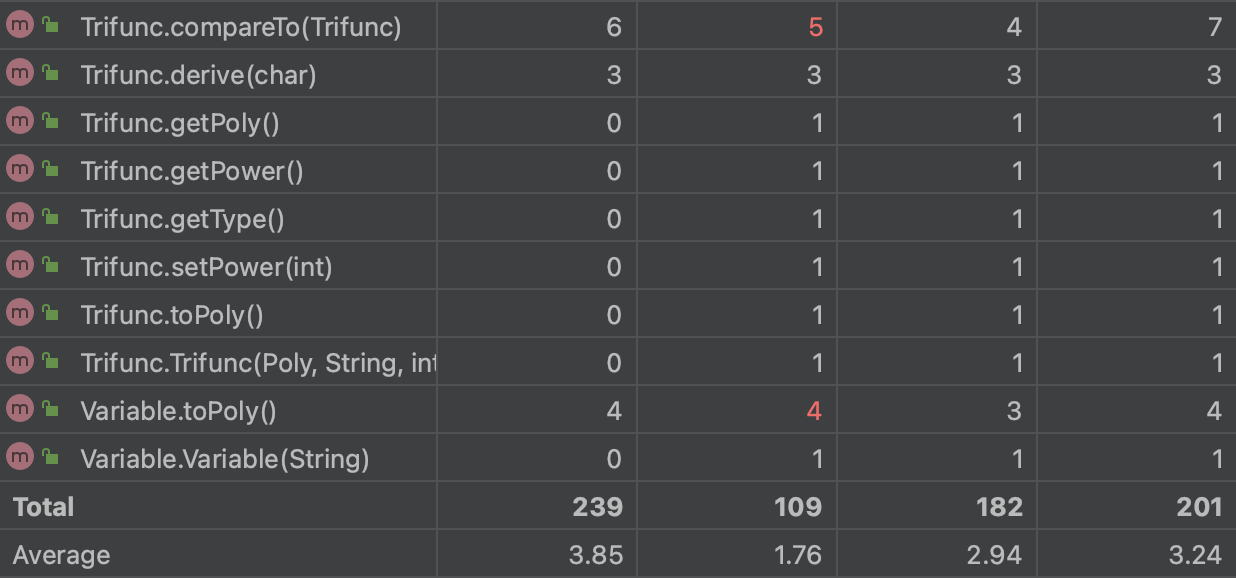
在第一次作业时,通过课上实验的抛砖引玉,笔者确定了采用递归下降算法来解析表达式,即使在之后的迭代中增加因子也可以处理,实现“高内聚,低耦合”,递归下降算法就好比抽丝剥茧,能让处理的过程比较可视,普适性也较高。
在三次作业中,我经历了一次部分性重构,由于第一次作业架构的缺陷,导致性能分全无且第二次作业无法进行,而重构后采纳了大佬优异的Poly-Mono架构后,在第二次和第三次拓展的过程中都比较顺利。
不过递归下降算法可能在时间的复杂度上没有那么优秀,我在编写过程中也出现了超时的现象,后续的学习仍要努力学着去==优化==自己的代码。
面向对象的学习是一门大工程,本单元由于个人原因未能投入太多时间,导致部分内容的缺失,很是遗憾。同时也没有学会评测机的搭建,在测试和性能优化以及代码风格方面仍有一定的缺失,仍需很大的努力。
通过本单元的学习,我感觉非常的充实,也让我感到自身的不足,之后我应当尽可能规范自己的架构,将思路梳理通畅之后再进行编码。希望能加油!多卷点性能分!提前完成作业!不赶ddl!努力前行!


