


442
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享感觉第一单元的难度较高,但是如果代码结构较好的话则不需要重构,并且整体难度会呈现先升高再下降的趋势。
下图是完成后的UML类图
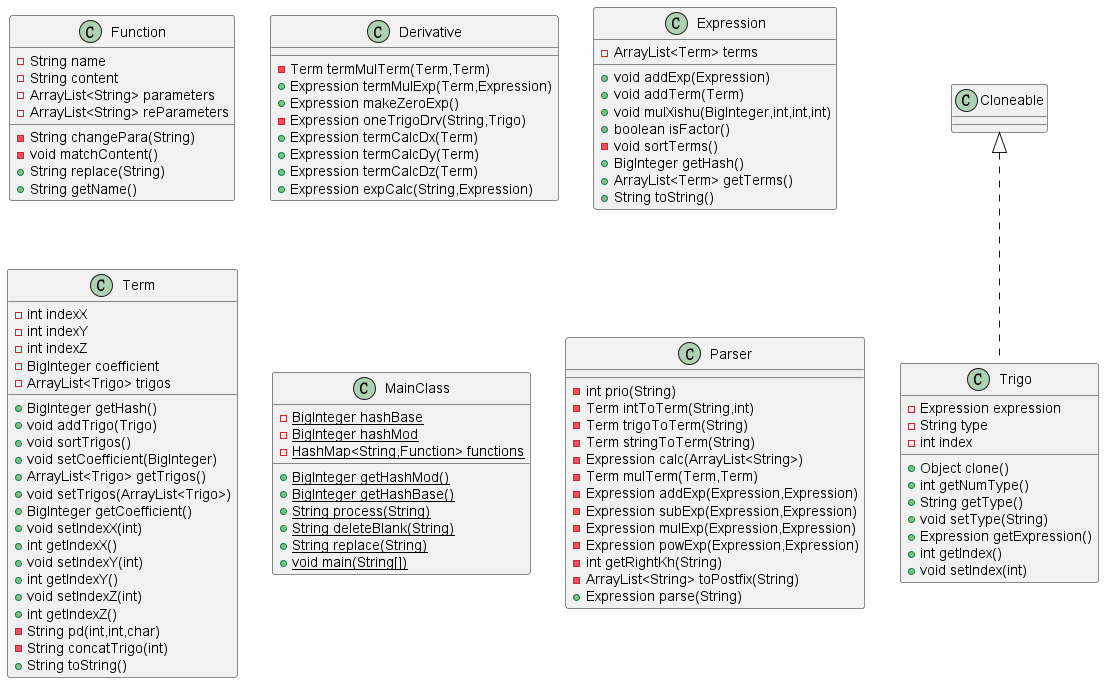
可以看到我的类总数比较少,因为写面向对象程序经验的不足,所以在第一次作业中主要还是面向过程的思想。
MainClass:主要架构,其中存储了计算哈希值的base和mod,其中的方法有对字符串进行预处理、主程序。
Function:函数替换类,该类用于处理函数在字符串层面的替换。
Derivative:求导类,处理求导因子出现的情况,将需要求导的表达式转化为求完导的Expression。
Trigo:三角函数类,用于存储一个三角函数的基本信息,继承了克隆方法。
Term:项类,是本次作业的基本单位,在第一次作业中四个参数即可构成一个项,第二次迭代之后在项中加入了存储Trigo的Arraylist。Term中主要实现了求哈希值、对三角函数排序、添加三角函数的方法。
Expression:表达式类,表达式为多个项的相加,因此表达式类中有存储了Term的Arraylist。该类主要实现了求哈希值、添加项、对项排序、乘系数的方法。
Parser:字符串处理类,其中的主要方法是处理字符串,返回一个处理完成后的表达式。
下图是类的复杂度分析
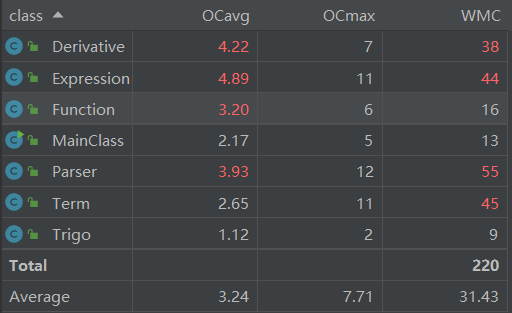
可以看出我的类复杂度较高,主要是因为本次作业的编程过程中对于面向对象的思想没有贯彻到底,很多地方都是将面向过程的函数生搬硬套到了其它类中,导致出现了“低内聚、高耦合”的尴尬情况,这点在之后的作业中需要反思。
第一次架构中我对表达式的处理没有采用递归下降的方法,而是将代码当作一个计算器:先将表达式转为后缀表达式(这个过程可以去除括号),再对后缀表达式进行运算(这个过程中合并同类项)。第一次作业经验不足,因此在构思上就花费了很多时间。
我设计了parser类用于处理字符串,其中的主要思路是利用数据结构的栈,先创建符号栈和运算单元栈(xyz和数字即为运算单元),读到运算单元就将其压入运算单元栈中,读到运算符就压入符号栈中,如果一个当前读到的符号的运算优先级小于等于符号栈中的运算符优先级,则将符号栈依次压入运算单元栈。最后再将符号栈依次压入运算单元栈,此时运算单元栈中存储的即为后缀表达式。之后再对后缀表达式进行计算,在计算的过程中会出现表达式之间的运算,因此运算的单元都应该视为一个表达式。最后将计算出来的表达式输出即可。
本次作业的难点主要在三角函数,因为自定义函数只需要做简单的字符串替换就可以了,但是三角函数涉及了表达式的递归调用以及关于三角函数的代码长度优化。
我的思路为在Term类中添加一个列表用于存储三角函数,每个三角函数中存储一个表达式,这样可以实现表达式的递归调用。并且对于每个表达式都重写哈希值,这样便可以通过哈希值来实现同类项的判断。当时我试图在哈希上使一些小聪明,让表达式的哈希值等于每一项哈希值的和,以达到让正负项相消的目的,但是这样出现了不可预期的bug,让我意识到了哈希的作用必须是判等,不应该再加其他作用。同时需要注意的是添加三角函数时一定要使用深克隆。
本次作业添加了求导的元素,由于前两次作业的磨练,这一次的求导在熟练递归的基础上显得不如第二次作业难。
我添加了Deravative类用于求导的计算,需要注意的是xyz的求导要区分开。
刚才提到了对于hash的小聪明,对于哈希功能的盲目更改让hash相关的bug贯穿本单元作业的始终,让我痛苦不堪的同时也给了我深刻的教育意义。
还有一个bug是添加三角函数时没有深克隆,但是这个bug较为好找。
第三次迭代中我在函数替换后没有重新对字符串预处理就开始解析,导致不可预测的bug出现,因为码量较多导致这个bug找了很久。

对于导致“低内聚、高耦合”的原因可以再深入思考下,比如功能划分不清、缺乏接口规范、全局变量滥用、消息传递不当、不合理的继承关系、过于复杂的代码结构等等


