



442
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享任务:对输入表达式结构建模,完成多项式的括号展开与函数调用、化简。
输入表达式的文法结构如下:
以下是我代码中的类,以及类中方法及简要关系示意图:
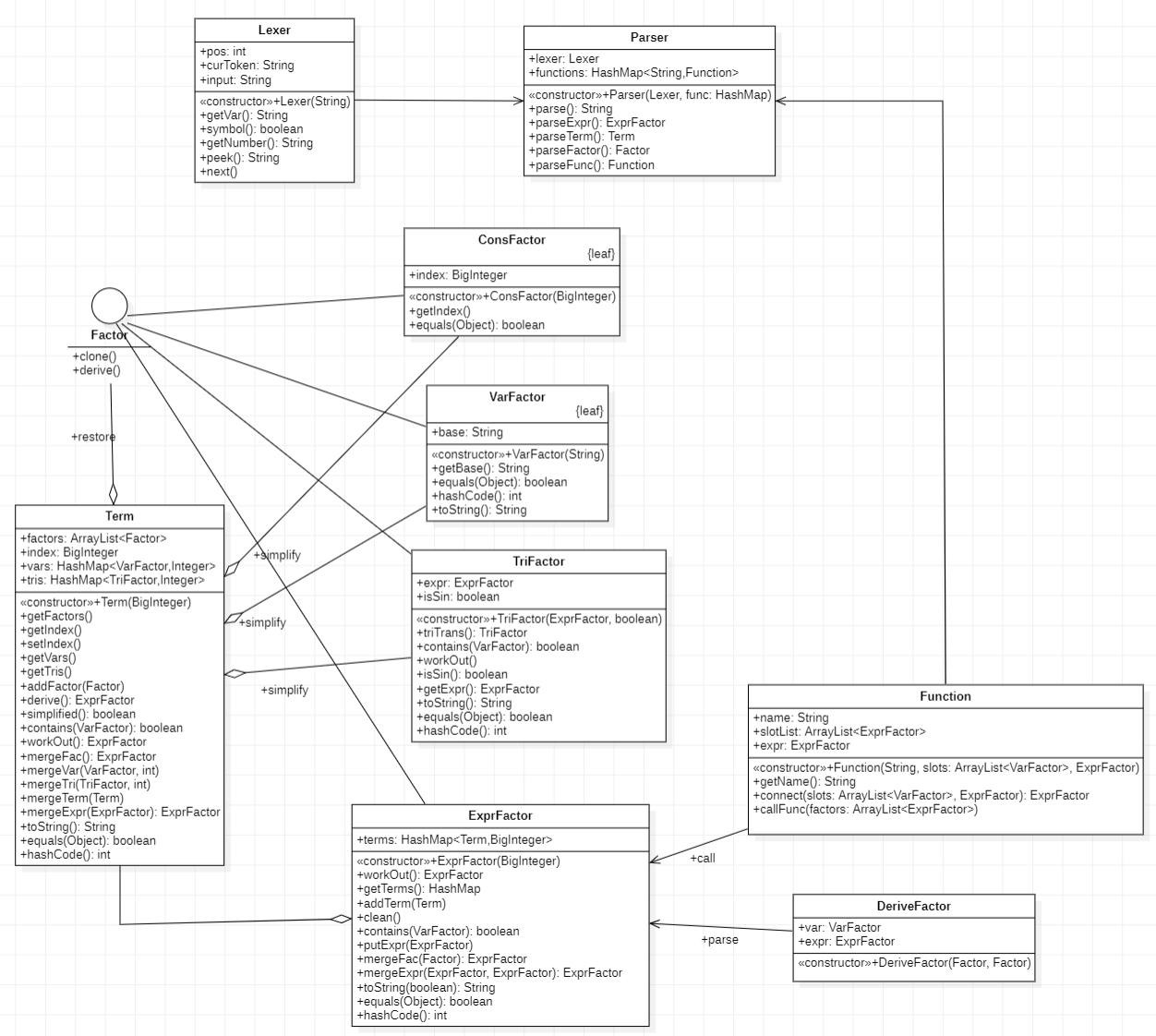
Term类
解析后的Term中,只有factors可以非空,即先存储后化简。好处:
Term最后输出的形式可以表达为:
$$term = index \times x^a \times y^b \times z^c \times \Pi sin(...)^p \times \Pi cos(...)^q $$
因此Term类设置了index、vars、tris槽,化简时按照因子类型归类。其中,vars和tris使用的时 因子-指数 对的形式存储,各因子都重写了 equals() 和 hashCode() 方法,方便合并同类项。
因子类
各因子同时实现深拷贝和求导方法。
Function类
Function的存储和调用中,实现使用了占位符slot。定义时,解析好的字符串通过 connect() 方法,将对应位的因子替换为 slot 存储。调用时给 slot 赋值,返回表达式的深拷贝。(实现详解见重构部分)
| class | OCavg | OCmax | WMC |
|---|---|---|---|
| expression.DeriveFactor | 1.0 | 1.0 | 4.0 |
| expression.ConsFactor | 1.2 | 2.0 | 6.0 |
| expression.VarFactor | 1.2857142857142858 | 2.0 | 9.0 |
| MainClass | 2.0 | 2.0 | 2.0 |
| expression.TriFactor | 2.0 | 8.0 | 22.0 |
| expression.ExprFactor | 2.7142857142857144 | 9.0 | 38.0 |
| expression.Function | 2.75 | 6.0 | 11.0 |
| Lexer | 2.8333333333333335 | 7.0 | 17.0 |
| Parser | 3.125 | 7.0 | 25.0 |
| expression.Term | 3.1904761904761907 | 10.0 | **67.0 ** |
| Total | 201.0 | ||
| Average | 2.4814814814814814 | 5.4 | 20.1 |
| Method | CogC | ev(G) | iv(G) | v(G) |
|---|---|---|---|---|
| expression.ConsFactor.clone() | 0.0 | 1.0 | 1.0 | 1.0 |
| expression.ConsFactor.ConsFactor(BigInteger) | 0.0 | 1.0 | 1.0 | 1.0 |
| expression.ConsFactor.derive(Factor) | 0.0 | 1.0 | 1.0 | 1.0 |
| expression.ConsFactor.equals(Object) | 1.0 | 2.0 | 1.0 | 2.0 |
| expression.ConsFactor.getIndex() | 0.0 | 1.0 | 1.0 | 1.0 |
| expression.DeriveFactor.clone() | 0.0 | 1.0 | 1.0 | 1.0 |
| expression.DeriveFactor.derive() | 0.0 | 1.0 | 1.0 | 1.0 |
| expression.DeriveFactor.derive(Factor) | 0.0 | 1.0 | 1.0 | 1.0 |
| expression.DeriveFactor.DeriveFactor(Factor, Factor) | 0.0 | 1.0 | 1.0 | 1.0 |
| expression.ExprFactor.addTerm(Term) | 7.0 | 3.0 | 5.0 | 6.0 |
| expression.ExprFactor.clean() | 0.0 | 1.0 | 1.0 | 1.0 |
| expression.ExprFactor.clone() | 1.0 | 1.0 | 2.0 | 2.0 |
| expression.ExprFactor.contains(VarFactor) | 3.0 | 3.0 | 2.0 | 3.0 |
| expression.ExprFactor.derive(Factor) | 1.0 | 1.0 | 2.0 | 2.0 |
| expression.ExprFactor.equals(Object) | 1.0 | 2.0 | 1.0 | 2.0 |
| expression.ExprFactor.ExprFactor(BigInteger) | 1.0 | 1.0 | 2.0 | 2.0 |
| expression.ExprFactor.getTerms() | 0.0 | 1.0 | 1.0 | 1.0 |
| expression.ExprFactor.hashCode() | 1.0 | 1.0 | 2.0 | 2.0 |
| expression.ExprFactor.mergeExpr(ExprFactor, ExprFactor) | 1.0 | 1.0 | 2.0 | 2.0 |
| expression.ExprFactor.mergeFac(Factor) | 1.0 | 1.0 | 2.0 | 2.0 |
| expression.ExprFactor.putExpr(ExprFactor) | 1.0 | 1.0 | 2.0 | 2.0 |
| expression.ExprFactor.toString(boolean) | 17.0 | 3.0 | 9.0 | 9.0 |
| expression.ExprFactor.workOut() | 1.0 | 1.0 | 2.0 | 2.0 |
| expression.Function.callFunc(ArrayList) | 1.0 | 1.0 | 2.0 | 2.0 |
| expression.Function.connect(ArrayList, ExprFactor) | 11.0 | 1.0 | 6.0 | 6.0 |
| expression.Function.Function(String, ArrayList, ExprFactor) | 1.0 | 1.0 | 2.0 | 2.0 |
| expression.Function.getName() | 0.0 | 1.0 | 1.0 | 1.0 |
| expression.Term.addFactor(Factor) | 4.0 | 1.0 | 4.0 | 4.0 |
| expression.Term.clone() | 3.0 | 1.0 | 4.0 | 4.0 |
| expression.Term.contains(VarFactor) | 10.0 | 5.0 | 5.0 | 8.0 |
| expression.Term.derive(Factor) | 8.0 | 3.0 | 4.0 | 5.0 |
| expression.Term.equals(Object) | 6.0 | 6.0 | 2.0 | 7.0 |
| expression.Term.getFactors() | 0.0 | 1.0 | 1.0 | 1.0 |
| expression.Term.getIndex() | 0.0 | 1.0 | 1.0 | 1.0 |
| expression.Term.getTris() | 0.0 | 1.0 | 1.0 | 1.0 |
| expression.Term.getVars() | 0.0 | 1.0 | 1.0 | 1.0 |
| expression.Term.hashCode() | 0.0 | 1.0 | 1.0 | 1.0 |
| expression.Term.mergeExpr(ExprFactor) | 5.0 | 1.0 | 3.0 | 3.0 |
| expression.Term.mergeFac(Factor) | 5.0 | 2.0 | 4.0 | 5.0 |
| expression.Term.mergeTerm(Term) | 2.0 | 1.0 | 3.0 | 3.0 |
| expression.Term.mergeTri(TriFactor, int) | 8.0 | 3.0 | 4.0 | 6.0 |
| expression.Term.mergeVar(VarFactor, int) | 5.0 | 2.0 | 3.0 | 4.0 |
| expression.Term.reverse() | 0.0 | 1.0 | 1.0 | 1.0 |
| expression.Term.setIndex(BigInteger) | 0.0 | 1.0 | 1.0 | 1.0 |
| expression.Term.simplified() | 0.0 | 1.0 | 1.0 | 1.0 |
| expression.Term.Term(BigInteger) | 0.0 | 1.0 | 1.0 | 1.0 |
| expression.Term.toString(boolean) | 17.0 | 5.0 | 10.0 | 12.0 |
| expression.Term.workOut() | 2.0 | 2.0 | 3.0 | 3.0 |
| expression.TriFactor.clone() | 0.0 | 1.0 | 1.0 | 1.0 |
| expression.TriFactor.contains(VarFactor) | 0.0 | 1.0 | 1.0 | 1.0 |
| expression.TriFactor.derive(Factor) | 2.0 | 2.0 | 2.0 | 3.0 |
| expression.TriFactor.equals(Object) | 2.0 | 2.0 | 2.0 | 3.0 |
| expression.TriFactor.getExpr() | 0.0 | 1.0 | 1.0 | 1.0 |
| expression.TriFactor.hashCode() | 0.0 | 1.0 | 1.0 | 1.0 |
| expression.TriFactor.isSin() | 0.0 | 1.0 | 1.0 | 1.0 |
| expression.TriFactor.toString() | 21.0 | 7.0 | 8.0 | 12.0 |
| expression.TriFactor.TriFactor(ExprFactor, boolean) | 0.0 | 1.0 | 1.0 | 1.0 |
| expression.TriFactor.triTrans() | 0.0 | 1.0 | 1.0 | 1.0 |
| expression.TriFactor.workOut() | 1.0 | 1.0 | 2.0 | 2.0 |
| expression.VarFactor.clone() | 0.0 | 1.0 | 1.0 | 1.0 |
| expression.VarFactor.derive(Factor) | 1.0 | 2.0 | 1.0 | 2.0 |
| expression.VarFactor.equals(Object) | 1.0 | 2.0 | 1.0 | 2.0 |
| expression.VarFactor.getBase() | 0.0 | 1.0 | 1.0 | 1.0 |
| expression.VarFactor.hashCode() | 0.0 | 1.0 | 1.0 | 1.0 |
| expression.VarFactor.toString() | 0.0 | 1.0 | 1.0 | 1.0 |
| expression.VarFactor.VarFactor(String) | 0.0 | 1.0 | 1.0 | 1.0 |
| Lexer.getNumber() | 2.0 | 1.0 | 3.0 | 3.0 |
| Lexer.getVar() | 3.0 | 2.0 | 4.0 | 4.0 |
| Lexer.Lexer(String) | 0.0 | 1.0 | 1.0 | 1.0 |
| Lexer.next() | 9.0 | 2.0 | 7.0 | 8.0 |
| Lexer.peek() | 0.0 | 1.0 | 1.0 | 1.0 |
| Lexer.symbol() | 4.0 | 1.0 | 3.0 | 4.0 |
| MainClass.main(String[]) | 1.0 | 1.0 | 2.0 | 2.0 |
| Parser.expandPower(Term, Factor) | 3.0 | 1.0 | 4.0 | 4.0 |
| Parser.newFactor(String) | 15.0 | 4.0 | 12.0 | 13.0 |
| Parser.parse() | 0.0 | 1.0 | 1.0 | 1.0 |
| Parser.parseExpr() | 4.0 | 1.0 | 4.0 | 4.0 |
| Parser.parseFactor() | 3.0 | 1.0 | 3.0 | 3.0 |
| Parser.parseFunc() | 1.0 | 1.0 | 2.0 | 2.0 |
| Parser.Parser(Lexer, HashMap<String, Function>) | 0.0 | 1.0 | 1.0 | 1.0 |
| Parser.parseTerm() | 6.0 | 1.0 | 4.0 | 4.0 |
| Total | 204.0 | 124.0 | 193.0 | 223.0 |
| Average | 2.5185185185185186 | 1.5308641975308641 | 2.382716049382716 | 2.753086419753086 |
第一次作业中,在 Term.addFactor() 方法中就完成了对各个因子合并化简,而不是在输出时才化简。Term 类中没有设置factors槽,而是存储了唯一的表达式因子,项中由多个表达式因子时,跟已有的表达式因子合并。
第二次作业中引入了自定义函数,那么自定义函数的存储中,这种架构就更加不可取了。此时我增加了factors槽,但是还没有放弃优先化简的思想,而是只在函数表达式存储时做了区分:函数存储时存因子到factor中,不化简,调用时立刻化简。为了完成这个结构,又增加了化简标志位。
第三次作业我才完全放弃了先化简的思想。不管是函数还是目标表达式,Term.addFactor()都不进行化简操作,在输出时统一化简,以空间为代价降低了代码的复杂度,简化了类结构,减少了标志位的存储传递。
第一次作业中,我按照文法的定义,将指数存储在因子内部。因为Term.addFactor()就对因子合并化简,这种结构就方便 Term类 直接访问和修改指数。
在第一次作业中,我还猜测接下来几周的文法发展方向,可能会实现负变量因子、负三角函数因子的化简,因此支持了所有因子的负数形式。解析是项不存储符号,符号全部由变量存储,即-x*y存储为(-x)*y,-x是一个因子单位。
因此第一次作业中我的Factor类如下:
public interface Factor {
void reverse(); //反转符号
void exp(int num);
}
第二次作业中,因为项延迟化简及需要表达式代入,指数的存储复杂了起来:函数没有指数,x**2需要存储成x*x;-x**3 需要处理成-x x x,需要对已经封装好的因子的符号和指数修改。不仅如此,化简过程中负号更难处理了:Term.mergeFactor()对递归化简因子,在哪一层处理符号需要统一,逻辑上增加了很多麻烦。
第二次作业中我的Factor类如下:
public interface Factor {
void reverse(); //反转符号
boolean getNeg();
void setNeg(boolean neg);
void exp(int exp);
int getExp();
}
第三次作业重构后,parser在Term层读取因子指数和符号,即:
public Term parseTerm(){
...
do {
if (lexer.peek().equals("*")) {
...
}
Factor factor = parseFactor();
if (lexer.peek().equals("**")) {
expandPower(term, factor);
} else {
term.addFactor(factor);
}
} while (lexer.peek().equals("*"));
...
}
因子类不再管理负号和指数,由项在化简时通过HashMap管理,降低了因子类的复杂度。
在第二次作业后重写了equals()和hashCode()方法,支持了项HashMap管理因子和表达式HashMap管理项。
实际上重写的只有叶类ConsFactor和VarFactor,其他类递归调用判等。
第一、二次作业中,因为对克隆的不了解,我在Term类中,继承了Serializable类,使用序列化和反序列化实现深克隆。
第三次作业中,参考训练的代码,对叶函数克隆,其他类递归克隆,实现了更优美的克隆方案。
第二次作业中,函数的slot实现,我通过建立三个ExprFactor引用,在构建函数时,如果传入对应变量,就在函数存储的表达式中存入对应引用。在调用时,只需修改三个引用的值,返回的表达式拷贝就是我们需要的表达式。
但在第三次作业中,我以更符合逻辑的方法,保存了引用栈:
private<ArrayList<ArraList<ExprFactor>>> slotList;
外层是自变量序列,内层时每一个自变量对应位置的引用序列,调用时两层遍历,依次给各个引用赋值。
后来在bug修复期间,觉得这种实现没有必要,没有第二次作业中的架构优雅,又改了回来:
private ArrayList<ExprFactor> slotList;
我在bug修复期间也使用了自动化工具生成数据,但我发现效果不如自己手搓数据好。手搓数据能够更好的覆盖各个数据类型,能更好的测试0,1等极端数据。
我的bug:
第一次接触oo,我在摸爬滚打中慢慢优化自己的代码结构,几乎每次作业都要重构一般的代码,但也慢慢让结构变得更合理,操作更简单,实现方式更加优雅。第一次第二次作业不能保证强测全对,第三次已经没有错误的测试点了(虽然没逃过互测),看到自己的进步我也很高兴。
但是在互测中我构造的测试数据还是比较弱,相比同房同学找到的bug很少。希望接下来在空闲时间多研究数据的生成,对自己和别人的程序都能有更好的理解。

第一次接触oo,我在摸爬滚打中慢慢优化自己的代码结构,几乎每次作业都要重构一般的代码,但也慢慢让结构变得更合理,操作更简单,实现方式更加优雅。第一次第二次作业不能保证强测全对,第三次已经没有错误的测试点了(虽然没逃过互测),看到自己的进步我也很高兴。
赞,不断进步!


