


49
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享Word2Vec的代码下载:
Google version (copied from original)C++11JavaPython
基本的系统配置:
Windows Original: cygwin
C++11: VS2013 Linux/Mac OS
Any version you like
下面我们将讲解你该如何将Google的Word2Vec源代码跑起来。首先,在你下载完了源代码之后就会看到如下文件列表:
然后,你可以运行“make”来编译,然后就可以运行一些demo脚本:./demo-word.sh, ./demo-phrases.sh。
其中,demo-word.sh是来做单词的嵌入,而demo-phrases.sh是来做短语的嵌入。关于短语的嵌入,大家可以此案看Mikolov2013那篇论文。
下面,让我们来看demo-word.sh的运行。执行make后会自动解压缩形成text8这个默认的语料库。其他的语料可以从wiki corpus以及datatang来找到。其中wiki的语料都是有关wiki的一些相关语料,datatang的语料比较小。
那么,demo-word.sh的脚本命令是怎么写的呢?这是一条命令:
其中所有的-都是参数,word2vec才是真正的命令。这些代码是:
time ./word2vec -train text8 -output vectors.bin
cbow 1
size 200
window 8
negative 25
hs 0
sample 1e-4
threads 20
binary 1
iter 15
其中train对应的是输入的语料,这里指定的语料是text8。output指定的是输出文件地址。接下来的是模型的参数,cbow是取值0或1,0表示使用skipgram,1表示用cbow模型。
size是嵌入向量的维度。
window是滑动窗口,也就是context的大小。
negative是负采样的大小。
hs是hiearchical softmax算法,这是一种让word2vec提速的算法,但是它提速没有negative sampling提速快。hs=0表示不用hiearchical softmax。
sample是科学技术方法的阈值,当我们做采样的时候会有一个词频的高低,sample就是需要计算的最小值。
threads是用到的线程数量。
binary是结果是否要用二进制方式储存,0表示输出是文本文件,1为二进制文件。
iter是算法迭代的次数。
所有这些参数都有默认值,平时使用的时候不需要更改。除此之外,Word2Vec还有如下一些参数:
alpha是学习率
?min-count:语料可以经过一些预处理,将词频低于mincount的就不考虑了。
?classes:是聚类的类别数。demo-classes这个脚本展示了如何使用classes。
我们知道,参数很重要。参数带来的效果要大于算法带来的效果。下面,列举一些常见的结论:
相似度:
接下来,我们用distance可以计算相似度。
另外,大家比较常用的是基于Python得Gensim版本。gensim是一个做很多NLP任务的一个包,包括word embedding和LDA等。
这是一个更可读,功能更多的包。它的函数也更多。另外,关于gensim的教程包括:
basic - tutorial from author:
第二个链接是一个用word2vec技术做应用的示例。
另外,我们可以测试诸如woman-man=queen-man这样的类比任务可以调用demo-analogy.sh来进行。
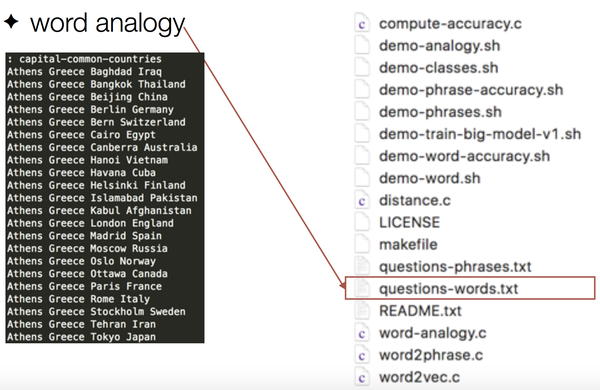
Analogy:
这是一个做analogy的测试例子:
可视化:
下面这个网页展示了如何做可视化的方法:
tSNE CSV web demo
http://wordvectors.org/
下面是一个可视化的效果:
这是一个自然语言与深度学习的系列课程,课程大纲如下:
本课程介绍自然语言处理中的基本工具:Word2Vec,它的历史渊源、原理、架构以及实现技术。 主要内容包括: 词嵌入问题:为什么要研究词嵌入,以及目前词嵌入方法的分类,Word2Vec的简单历史。
1、Word2Vec介绍:Word2Vec是在2013年Google开发的一套词嵌入方法,它包含CBOW和Skip-Gram两种方法。目前,人们使用比较多的是Skip-Gram方法。
2、Skip-Gram:详细介绍了Skip-Gram的工作原理。
3、进一步,课程介绍了什么是负采样(Negative sampling),它的目的是为了解决什么问题。 (课时:84分钟)
第一堂课程的课程概要如下:
在本次课程中,主讲人李嫣然会梳理聊天机器人前后三十年的发展脉络:从最早的聊天机器人具备怎样的功能,到当前最流行的各大公司、学界的聊天机器人有哪些新特征。以这些最新的聊天机器人为例,简要概述聊天机器人背后的主要技术要点,使大家能对聊天机器人有一个整体且较为全面的认知。
第一节课不仅可以使大家能亲自与当前流行的聊天机器人互动,同时也能基本理解在我们与聊天机器人“对话”的过程中,聊天机器人是如何处理人类语言并作出它的回答的。
课程大纲:
1.1 聊天机器人与人机交互
1.2 聊天机器人的前世今生
1.3 世界上第一个聊天机器人
1.4 最新聊天机器人面面观

