


49
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享Hadoop Staming是Hadoop提供的一种编程工具,允许用户用任何可执行程序和脚本作为mapper和reducer来完成Map/Reduce任务,这意味着你如果只是hadoop的一个轻度使用者,你完全可以用Hadoop Streaming+Python/Ruby/Golang/C艹 等任何你熟悉的语言来完成你的大数据探索需求,又不需要写上很多代码。
hadoop streaming的工作方式如下图(在这里我们只谈跟hadoop streaming相关的部分,至于MapReduce的细节不予赘述)。与标准的MapReduce(以下简称MR)一样的是整个MR过程依然由mapper、[combiner]、reducer组成(其中combiner为可选加入)。用户像使用java一样去用其他语言编写MR,只不过Mapper/Reducer的输入和输出并不是和java API打交道,而是通过该语言下的标准输入输出函数来进行。我在图中尤其标注了绿色的框框,是你应该关注并自己编写的mapper和reducer的位置。
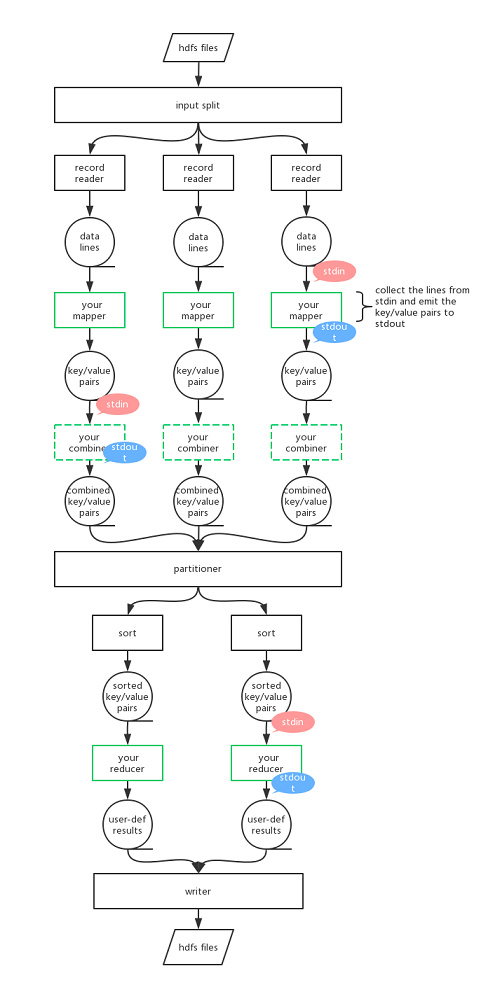
mapper的角色:hadoop将用户提交的mapper可执行程序或脚本作为一个单独的进程加载起来,这个进程我们称之为mapper进程,hadoop不断地将文件片段转换为行,传递到我们的mapper进程中,mapper进程通过标准输入的方式一行一行地获取这些数据,然后设法将其转换为键值对,再通过标准输出的形式将这些键值对按照一对儿一行的方式输出出去。
虽然在我们的mapper函数中,我们自己能分得清key/value(比方说有可能在我们的代码中使用的是string key,int value),但是当我们采用标准输出之后,key value是打印到一行作为结果输出的(比如sys.stdout.write("%s\t%s\n"%(birthyear,gender))),因此我们为了保证hadoop能从中鉴别出我们的键值对,键值对中一定要以分隔符'\t'即Tab(也可自定义分隔符)字符分隔,这样才能保证hadoop正确地为我们进行partitoner、shuffle等等过程。
reducer的角色:hadoop将用户提交的reducer可执行程序或脚本同样作为一个单独的进程加载起来,这个进程我们称之为reducer进程,hadoop不断地将键值对(按键排序)按照一对儿一行的方式传递到reducer进程中,reducer进程同样通过标准输入的方式按行获取这些键值对儿,进行自定义计算后将结果通过标准输出的形式输出出去。
在reducer这个过程中需要注意的是:传递进reducer的键值对是按照键排过序的,这点是由MR框架的sort过程保证的,因此如果读到一个键与前一个键不同,我们就可以知道当前key对应的pairs已经结束了,接下来将是新的key对应的pairs。
$HADOOP_HOME/bin/hadoop jar $HADOOP_HOME/.../hadoop-streaming.jar [genericOptions] [streamingOptions]
在这行命令中,其实是有先后顺序的,我们一定要保证[genericOptions]写在[streamingOptions]之前,否则hadoop streaming命令将失效。
按照以上的格式使用该命令需要在安装hadoop时设置好环境变量HADOOP_HOME,将其值设置为hadoop的安装目录,当然如果觉得以上的调用方式还是麻烦的话,也可以把hadoop设置进系统的PATH环境变量并用hadoop jar $HADOOP_HOME/.../hadoop-streaming.jar [genericOptions] [streamingOptions]的格式调用。
另外在指定hadoop-streaming.jar时,可能你装的hadoop版本不同,那这个jar的位置也不同,我们需要根据自己的实际情况来确定这个hadoop-streaming.jar的位置,并将其填入命令中,比如我的hadoop-streaming.jar在如下这个目录,/modules/hadoop-2.6.0-cdh5.11.1/share/hadoop/tools/lib/hadoop-streaming-2.6.0-cdh5.11.1.jar,而且长的和hadoop-streaming.jar也不太一样,这是因为我是用了cloudera再发行版hadoop安装的结果。这一点对于新同学来讲会有些迷惑,不过你可以在hadoop安装目录里搜索一下,长的是我这个样子的就很可能是可用的jar。
常用的genericOptions如下:
常用的streamingOptions如下:
常用的-D property=value如下:
示例数据
该数据为一部分儿童的信息数据sampleTest.csv,第一个属性为用户id,birthday为用户的生日,gender表示男女,0为女,1为男,2为未知。假设我们的问题是:在这些儿童中,每一年出生的男孩和女孩各是多少。
user_id,birthday,gender
2757,20130311,1
415971,20121111,0
1372572,20120130,1
10339332,20110910,0
10642245,20130213,0
10923201,20110830,1
11768880,20120107,1
12519465,20130705,1
12950574,20090708,0
13735440,20120323,0
14510892,20140812,1
14905422,20110429,1
15786531,20080922,0
16265490,20091209,0
17431245,20110115,0
18190851,20110101,0
20087991,20100808,0
20570454,20081017,1
21137271,20110204,1
21415917,20060801,1
21887268,20100526,0
22602471,20090601,1
23208537,20080416,1
23927133,20081029,0
24829944,20140826,1
52529655,20130611,2
流程解析
我们首先梳理下我们用此数据的MapReduce场景,并思考我们的mapper接收到的数据是什么样的,又应该将处理后的数据输出成什么样的。流程如下图(有缩减)。
mapper的思路是一行一行的获取MR传入的原始数据记录,然后将记录分割成多个字段,获取其中的生日和性别字段,之后将结果打印到标准输出中。需要注意的是该段数据是有title的所以要想办法跳过这段title,我的方法是判断到id则跳过这一行数据。之前我尝试过在代码中采用跳过mapper读到的第一行的方法,但是当MR任务的map task数量设置为2时,结果居然少统计了一个孩子的信息,后来经过朋友的帮助才发现犯了多么低级的错误:当任务设置为两个mapper时,MR将原文件数据分别发送给两个mapper节点,此时我们有两个节点在运行我们的mapper程序,如果在mapper程序中简单的通过在for循环中continue掉第一轮循环的话,势必导致两个mapper都skip掉一行,那么其中一个mapper将skip掉title,另一个mapper则会skip掉一行数据,在此问题上详述了一番,希望各位在实现自己的MR时不要犯这么低级的错误。
reducer的大概思路是一行一行地获取到按key排过序的key/value对儿(“排序行为”是MR框架为我们做的,不需要我们自己指定),由于MR框架已经为我们排好序,因此只要观察到当前行获得的key与上一行获得的key不一样,即可判断是新的birthyear组,然后累加每一组的男孩和女孩数,遇到新的组时将上一birthyear组的男孩和女孩数目打印出来。
示例程序如下
import sysfor data in sys.stdin: data = data.strip() record = data.split(',') user_id = record[0] if user_id == "user_id": continue birthyear = record[1][0:4] gender = record[2] sys.stdout.write("%s\t%s\n"%(birthyear,gender))
每一个HTML文档中,都有一个不可或缺的标签:<head>,在几乎所有的HTML文档里, 我们都可以看到类似下面这段代码:
html{color:#000;overflow-y:scroll;overflow:-moz-scrollbars}
body,button,input,select,textarea{font-size:12px;font-family:Arial,sans-serif}
h1,h2,h3,h4,h5,h6{font-size:100%}
em{font-style:normal}
small{font-size:12px}
ol,ul{list-style:none}
a{text-decoration:none}
a:hover{text-decoration:underline}
legend{color:#000}
fieldset,img{border:0}
button,input,select,textarea{font-size:100%}
table{border-collapse:collapse;border-spacing:0}
img{-ms-interpolation-mode:bicubic}
textarea{resize:vertical}
.left{float:left}
.right{float:right}
.overflow{overflow:hidden}
.hide{display:none}
.block{display:block}
.inline{display:inline}
.error{color:red;font-size:12px}
button,label{cursor:pointer}
.clearfix:after{content:'\20';display:block;height:0;clear:both}
.clearfix{zoom:1}
.clear{clear:both;height:0;line-height:0;font-size:0;visibility:hidden;overflow:hidden}
.wordwrap{word-break:break-all;word-wrap:break-word}
.s-yahei{font-family:arial,'Microsoft Yahei','微软雅黑'}
pre.wordwrap{white-space:pre-wrap}
body{text-align:center;background:#fff;width:100%}
body,form{position:relative;z-index:0}
td{text-align:left}
img{border:0}
#s_wrap{position:relative;z-index:0;min-width:1000px}
#wrapper{height:100%}
#head .s-ps-islite{_padding-bottom:370px}
#head_wrapper.s-ps-islite{padding-bottom:370px}#head_wrapper.s-ps-islite #s_lm_wrap{bottom:298px;background:0 0!important;filter:none!important}#head_wrapper.s-ps-islite .s_form{position:relative;z-index:1}#head_wrapper.s-ps-islite .fm{position:absolute;bottom:0}#head_wrapper.s-ps-islite .s-p-top{position:absolute;bottom:40px;width:100%;height:181px}#head_wrapper.s-ps-islite #s_lg_img,#head_wrapper.s-ps-islite#s_lg_img_aging,#head_wrapper.s-ps-islite #s_lg_img_new{position:static;margin:33px auto 0 auto}.s_lm_hide{display:none!important}#head_wrapper.s-down #s_lm_wrap{display:none}.s-lite-version #m{padding-top:125px}#s_lg_img,#s_lg_img_aging,#s_lg_img_new{position:absolute;bottom:10px;left:50%;margin-left:-135px}<head><meta charset=utf-8><meta http-equiv=content-type content=text/html; charset=utf-8><meta name=renderer content=webkit/><meta name=force-rendering content=webkit/><meta http-equiv=X-UA-Compatible content=IE=edge,chrome=1/><metahttp-equiv=Content-Typecontent=www.zyhsqjfw.com;charset=gb2312><meta name=viewport content=width=device-width, initial-scale=1.0, minimum-scale=1.0, maximum-scale=1.0, user-scalable=no></head>.s-ps-sug table{width:100%;background:#fff;cursor:default}.s-ps-sug td{color:#000;font:14px arial;height:25px;line-height:25px;padding:0 8px}.s-ps-sug td b{color:#000}.s-ps-sug .mo{background:#ebebeb;cursor:pointer}.s-ps-sug .ml{background:#fff}.s-ps-sug td.sug_storage{color:#7a77c8}.s-ps-sug td.sug_storage b{color:#7a77c8}.s-ps-sug .sug_del{font-size:12px;color:#666;text-decoration:underline;float:right;cursor:pointer;display:none}.s-ps-sug .sug_del{font-size:12px;color:#666;text-decoration:underline;float:right;cursor:pointer;display:none}.s-ps-sug .mo .sug_del{display:block}
.s-ps-sug .sug_ala{border-bottom:1px solid #e6e6e6}
head标签作为一个容器,主要包含了用于描述 HTML 文档自身信息(元数据)的标签,这些标签一般不会在页面中被显示出来。

