


12,043
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享#网址http://yjt.hubei.gov.cn/fbjd/tzgg/,试了好多办法都走不通,服务器不返回正常的代码页面
# 第一次:直接requests返回非正常内容,失败
import requests
url = 'http://yjt.hubei.gov.cn/fbjd/tzgg/'
response = requests.get(url)
# 第二次,模拟头部信息,仍然返回非正常内容,失败
url = 'http://yjt.hubei.gov.cn/fbjd/tzgg/'
headers = {'User-Agent':'OW64; rv:59.0) Gecko/20100101 Firefox/59.0'}
response = requests.get(url, headers=headers)
# 第三次,调试页面获取cookie和header,放进代码里,只在1分钟之内有效,很快失效,失败
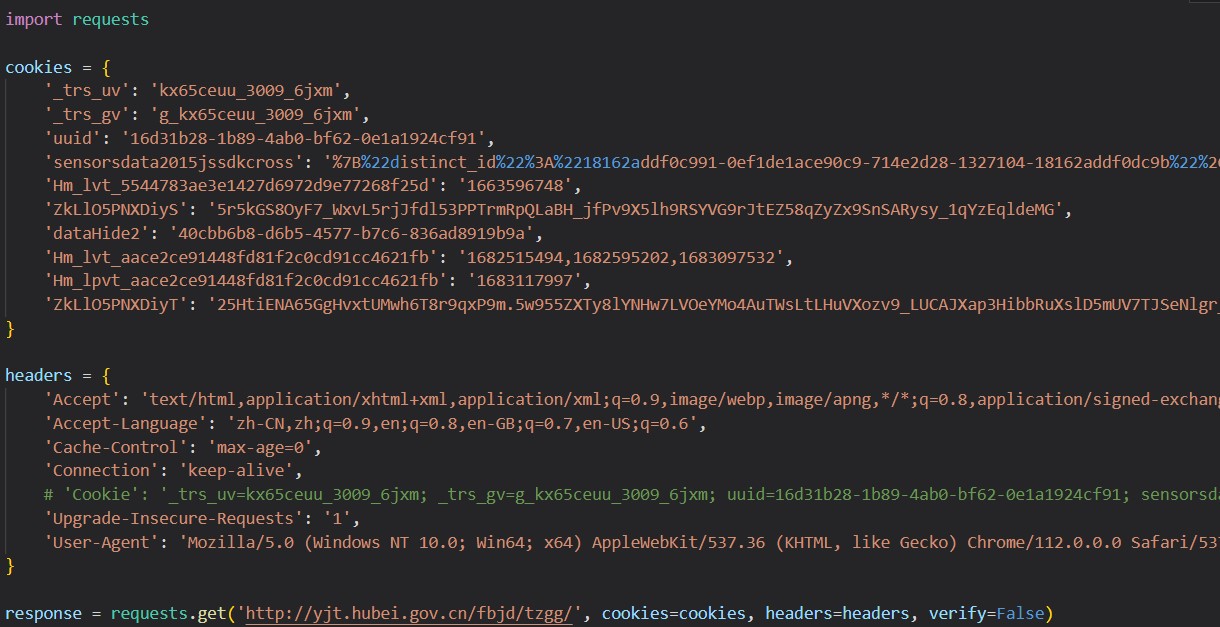
第四次,用selenium,还是失败了
from selenium import webdriver
driver=webdriver.Edge()
url = 'http://yjt.hubei.gov.cn/fbjd/tzgg/'
driver.get(url)
print(driver.page_source)
求大神指点迷津~~

目标网站有反爬措施,使用reuest要分析整个网络流程,而非只模拟1条消息。使用 selenium 也要设置 header头部参数的,这样使用通常会被很轻易地对方识别为selenium测试消息。



