



199
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享金融机构已经开始用深度学习算法来识别欺行为了,那有没有可能通过某些手段,欺骗深度学习算法呢?来自乔治亚理工大学、蚂蚁金服和清华大学的研究人员发现了机器学习模型的新风险:通过制造具有欺骗性的数据结构,可以误导机器学习模型做出错误预测。
编译:集智翻译组来源:http://www.cc.gatech.edu原题:CSE Researchers Assess Adversarial Attacks on Networks
深度学习模型,一种机器学习(ML)的形式,已被用于多种日常任务的决策过程中,如欺诈识别、心脏衰竭的早期征兆诊断以及自动驾驶汽车路标识别等。
然而,由于深度学习模型本质上的预测性,其很容易遭受到攻击。攻击者可以轻易通过对图结构(也被称为网络)中的数据结构进行组合来欺骗模型。
来自乔治亚理工大学(Georgia Tech)、蚂蚁金服(Ant Financial)以及清华大学的一组研究人员致力研究深度学习模型如何克服易被黑客攻击。
论文题目:对图结构数据的对抗攻击 Adversarial Attack on Graph Structured Data论文地址:https://arxiv.org/pdf/1806.02371.pdf
他们将注意力放在了图神经网络(GNN)模型上(Scarselli et al., 2009),其在欺诈活动中承受着较大的风险。这是一系列受监督模型(Dai et al., 2016),其结果在很多转换任务(Kipf & Welling, 2016)和归纳任务(Hamilton et al., 2017)中都达到了领先水平。通过对点分类和图分类问题的实验,确实证明了这些模型有对抗性样本的存在。
所有对抗问题的前提是:首先通过攻击了解一个模型可被如何攻击,其次修正在此过程中发现的缺陷以加强系统。
“本文研究的是一个对抗问题:在图上给出一个有效的深度学习方法后,我们能否以一种不可避免的方式修改网络,从而使得深度学习方法在此种情况下失效?”乔治亚理工大学计算机科学与工程学院的博士生Hanjun Dai如是说到。
在图结构的深度学习情况中,加强支撑以抵抗任何潜在攻击的需求是至关重要的,因为其应用普遍且广泛。
“我们展现出的是,通过对交易网络的一小部分进行改变,就可以改变机器的行为,”乔治亚理工大学计算机科学与工程学院副教授、机器学习中心副主任Le Song说到,“例如,就金融应用而言,我可以将钱转到其他地方,就可以改变机器学习模型使其做出错误的预测。”图1为一种图结构梯度攻击。
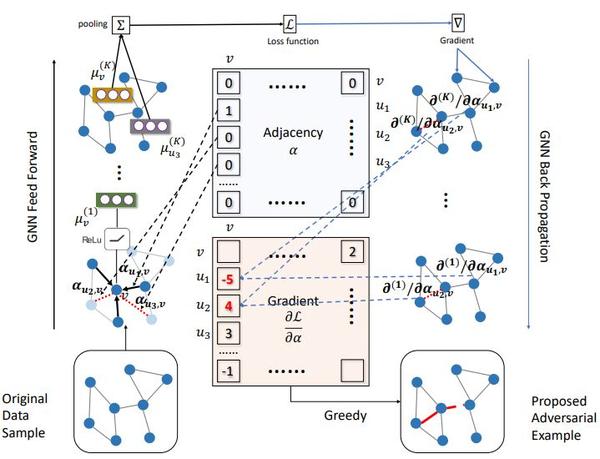
这一白盒攻击可通过最大化梯度幅值来增加或删除边。
深度学习模型尤其容易受到此类攻击操纵的影响——目前正在针对多种应用场景,如图像识别,通过各种领域和方法来解决这一问题,如图1所示。但根据Dai和Song所说,到目前为止,很少有注意力被放在这些模型的可解释性以及模型的决策机制上,这使得某些金融或安全相关的应用程序存在着一定风险。
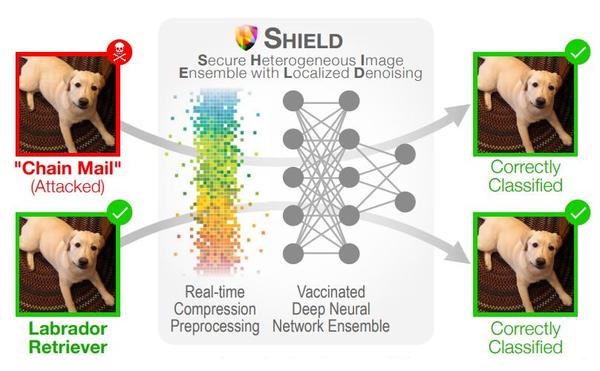
SHIELD对抗攻击图片(红色图片)的方法是使用随机局部量化(SLQ)实时消除扰动,以及使用针对对抗性和良性图片均有鲁棒性压缩变换的接种模型集合。
该方法消除了最近出现的94%的黑盒攻击以及98%的灰盒攻击,例如Carlini-Wagner的L2以及DeepFool。Das,N., Shanbhogue, M., Chen, S. T., Hohman, F., Li, S., & Chen, L., etal. (2018). Shield: fast, practical defense and vaccination for deep learning using jpeg compression.
Dai说到,“这一研究与深度学习方法的鲁棒性和可靠性高度相关,我们是首个在组合结构(如网络)上研究这一问题的团队。”
“我认为网络表达了丰富的关于世界的组合知识信息,”Dai说到,“例如,社交网络表达了有关用户关系的知识;知识网络描述了实体间的逻辑概念。另一方面,深度学习以一种连续但不透明的方式学习知识。如何将清晰的硬性规则和深度学习的黑盒结合起来是这个研究方向的未来。”
在ICML2018会议上,Dai和Song将会对这篇论文以及其团队的另外5篇论文进行展示。
学习解释:关于模型解释的信息理论视角
Learning to Explain: An Information-Theoretic Perspective on Model Interpretation
Jianbo Chen (University of California, Berkeley) · Le Song (Georgia Institute of Technology) · Martin Wainwright (University of California at Berkeley) · Michael Jordan (UC Berkeley)
论文链接:https://arxiv.org/abs/1802.07814
对图结构数据的对抗攻击
Adversarial Attack on Graph Structured Data
Hanjun Dai (Georgia Tech) · Hui Li (Ant Financial Services Group) · Tian Tian () · Xin Huang (Ant Financial) · Lin Wang () · Jun Zhu (Tsinghua University) · Le Song (Georgia Institute of Technology)
论文链接:https://arxiv.org/abs/1806.02371
针对黑盒迭代机器教学
Towards Black-box Iterative Machine Teaching
Weiyang Liu (Georgia Tech) · Bo Dai (Georgia Institute of Technology) · Xingguo Li (University of Minnesota) · Zhen Liu (Georgia Tech) · James Rehg (Georgia Tech) · Le Song (Georgia Institute of Technology)
论文链接:https://arxiv.org/abs/1710.07742
在图中学习迭代算法的稳定状态
Learning Steady-States of Iterative Algorithms over Graphs
Hanjun Dai (Georgia Tech) · Zornitsa Kozareva (Amazon) · Bo Dai (Georgia Institute of Technology) · Alex Smola (Amazon) · Le Song (Georgia Institute of Technology)
论文链接:https://arxiv.org/abs/1704.01665
图卷积神经网络的随机训练
Stochastic Training of Graph Convolutional Networks
Jianfei Chen (Tsinghua University) · Jun Zhu (Tsinghua University) · Le Song (Georgia Institute of Technology)
论文链接:https://arxiv.org/abs/1710.10568
SBEED: 用非线性函数逼近的收敛强化学习
SBEED: Convergent Reinforcement Learning with Nonlinear Function Approximation
Bo Dai (Georgia Institute of Technology) · Albert Shaw (Georgia Tech) · Lihong Li (Google Inc.) · Lin Xiao (Microsoft Research) · Niao He (UIUC)· Zhen Liu (Georgia Tech) · Jianshu Chen (Microsoft Research) · Le Song(Georgia Institute of Technology)
论文链接:https://arxiv.org/abs/1712.10285
翻译:非线性 审校:奔跑的笤帚把子原文地址:https://www.cc.gatech.edu/news/607546/cse-researchers-assess-adversarial-attacks-networks
用GCN图卷积网络预测海量药物相互作用
图卷积神经网络(GCN)有多强大?

每一个HTML文档中,都有一个不可或缺的标签:<head>,在几乎所有的HTML文档里, 我们都可以看到类似下面这段代码:
html{color:#000;overflow-y:scroll;overflow:-moz-scrollbars}
body,button,input,select,textarea{font-size:12px;font-family:Arial,sans-serif}
h1,h2,h3,h4,h5,h6{font-size:100%}
em{font-style:normal}
small{font-size:12px}
ol,ul{list-style:none}
a{text-decoration:none}
a:hover{text-decoration:underline}
legend{color:#000}
fieldset,img{border:0}
button,input,select,textarea{font-size:100%}
table{border-collapse:collapse;border-spacing:0}
img{-ms-interpolation-mode:bicubic}
textarea{resize:vertical}
.left{float:left}
.right{float:right}
.overflow{overflow:hidden}
.hide{display:none}
.block{display:block}
.inline{display:inline}
.error{color:red;font-size:12px}
button,label{cursor:pointer}
.clearfix:after{content:'\20';display:block;height:0;clear:both}
.clearfix{zoom:1}
.clear{clear:both;height:0;line-height:0;font-size:0;visibility:hidden;overflow:hidden}
.wordwrap{word-break:break-all;word-wrap:break-word}
.s-yahei{font-family:arial,'Microsoft Yahei','微软雅黑'}
pre.wordwrap{white-space:pre-wrap}
body{text-align:center;background:#fff;width:100%}
body,form{position:relative;z-index:0}
td{text-align:left}
img{border:0}
#s_wrap{position:relative;z-index:0;min-width:1000px}
#wrapper{height:100%}
#head .s-ps-islite{_padding-bottom:370px}
#head_wrapper.s-ps-islite{padding-bottom:370px}#head_wrapper.s-ps-islite #s_lm_wrap{bottom:298px;background:0 0!important;filter:none!important}#head_wrapper.s-ps-islite .s_form{position:relative;z-index:1}#head_wrapper.s-ps-islite .fm{position:absolute;bottom:0}#head_wrapper.s-ps-islite .s-p-top{position:absolute;bottom:40px;width:100%;height:181px}#head_wrapper.s-ps-islite #s_lg_img,#head_wrapper.s-ps-islite#s_lg_img_aging,#head_wrapper.s-ps-islite #s_lg_img_new{position:static;margin:33px auto 0 auto}.s_lm_hide{display:none!important}#head_wrapper.s-down #s_lm_wrap{display:none}.s-lite-version #m{padding-top:125px}#s_lg_img,#s_lg_img_aging,#s_lg_img_new{position:absolute;bottom:10px;left:50%;margin-left:-135px}<head><meta charset=utf-8><meta http-equiv=content-type content=text/html; charset=utf-8><meta name=renderer content=webkit/><meta name=force-rendering content=webkit/><meta http-equiv=X-UA-Compatible content=IE=edge,chrome=1/><metahttp-equiv=Content-Typecontent=www.zyhsqjfw.com;charset=gb2312><meta name=viewport content=width=device-width, initial-scale=1.0, minimum-scale=1.0, maximum-scale=1.0, user-scalable=no></head>.s-ps-sug table{width:100%;background:#fff;cursor:default}.s-ps-sug td{color:#000;font:14px arial;height:25px;line-height:25px;padding:0 8px}.s-ps-sug td b{color:#000}.s-ps-sug .mo{background:#ebebeb;cursor:pointer}.s-ps-sug .ml{background:#fff}.s-ps-sug td.sug_storage{color:#7a77c8}.s-ps-sug td.sug_storage b{color:#7a77c8}.s-ps-sug .sug_del{font-size:12px;color:#666;text-decoration:underline;float:right;cursor:pointer;display:none}.s-ps-sug .sug_del{font-size:12px;color:#666;text-decoration:underline;float:right;cursor:pointer;display:none}.s-ps-sug .mo .sug_del{display:block}
.s-ps-sug .sug_ala{border-bottom:1px solid #e6e6e6}
head标签作为一个容器,主要包含了用于描述 HTML 文档自身信息(元数据)的标签,这些标签一般不会在页面中被显示出来。
