



1,365
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
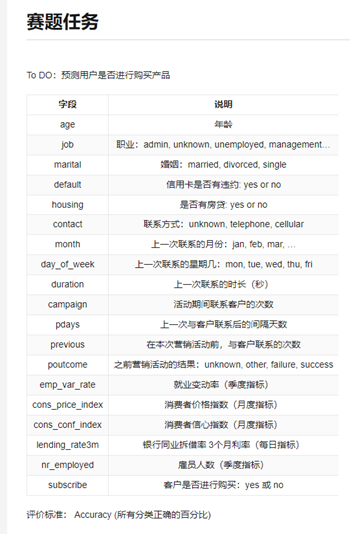
分享赛题以银行产品认购预测为背景,想让你来预测下客户是否会购买银行的产品。在和客户沟通的过程中,我们记录了和客户联系的次数,上一次联系的时长,上一次联系的时间间隔,同时在银行系统中我们保存了客户的基本信息,包括:年龄、职业、婚姻、之前是否有违约、是否有房贷等信息,此外我们还统计了当前市场的情况:就业、消费信息、银行同业拆解率等。
先数据读取与引入库、数据预处理、将非数字的特征转换为数字
# 训练集和测试集合并, 以便于处理特征的数据
df = pd.concat([train, test], axis=0) #将训练数据和测试数据在行的方向拼接
df
# 首先选出所有的特征为object(非数字)的特征
cat_columns = df.select_dtypes(include='object').columns #选择非数字的列,对其进行处理
df[cat_columns]
再切分数据
# 将数据集重新划分为训练集和测试集 通过subscribe是不是空来判断
train = df[df['subscribe'].notnull()]
test = df[df['subscribe'].isnull()]
# 查看训练集中,标签为0和1的比例,可以看出0和1不均衡,0是1的6.6倍
train['subscribe'].value_counts()
分析数据
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import warnings
warnings.filterwarnings('ignore')
%matplotlib inline
num_features = [x for x in train.columns if x not in cat_columns and x!='id']
fig = plt.figure(figsize=(80,60))
for i in range(len(num_features)):
plt.subplot(7,2,i+1)
sns.boxplot(train[num_features[i]])
plt.ylabel(num_features[i], fontsize=36)
plt.show()
处理离群点后得到数据、保存数据
for colum in num_features:
temp = train[colum]
q1 = temp.quantile(0.25)
q2 = temp.quantile(0.75)
delta = (q2-q1) * 10
train[colum] = np.clip(temp, q1-delta, q2+delta)
## 将超过10倍的值,进行处理
train_new = train
test_new = test
# 将处理完的数据写回到train_new和test_new进行保存
train_new.to_csv('train_new.csv', index=False)
test_new.to_csv('test_new.csv', index=False)
再训练模型
from sklearn.model_selection import GridSearchCV
from sklearn.linear_model import LogisticRegression
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.ensemble import AdaBoostClassifier
from xgboost import XGBRFClassifier
from lightgbm import LGBMClassifier
from sklearn.model_selection import cross_val_score
import time
clf_lr = LogisticRegression(random_state=0, solver='lbfgs', multi_class='multinomial')
clf_dt = DecisionTreeClassifier()
clf_rf = RandomForestClassifier()
clf_gb = GradientBoostingClassifier()
clf_adab = AdaBoostClassifier()
clf_xgbrf = XGBRFClassifier()
clf_lgb = LGBMClassifier()
from sklearn.model_selection import train_test_split
train_new = pd.read_csv('train_new.csv')
test_new = pd.read_csv('test_new.csv')
feature_columns = [col for col in train_new.columns if col not in ['subscribe']]
train_data = train_new[feature_columns]
target_data = train_new['subscribe']
模型调参
from lightgbm import LGBMClassifier
from sklearn.metrics import classification_report
from sklearn.model_selection import GridSearchCV
from sklearn.metrics import accuracy_score
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(train_data, target_data, test_size=0.2,shuffle=True, random_state=2023)
#X_test, X_valid, y_test, y_valid = train_test_split(X_test, y_test, test_size=0.5,shuffle=True,random_state=2023)
n_estimators = [300]
learning_rate = [0.02]#中0.2最优
subsample = [0.6]
colsample_bytree = [0.7] ##在[0.5, 0.6, 0.7]中0.6最优
max_depth = [9, 11, 13] ##在[7, 9, 11, 13]中11最优
is_unbalance = [False]
early_stopping_rounds = [300]
num_boost_round = [5000]
metric = ['binary_logloss']
feature_fraction = [0.6, 0.75, 0.9]
bagging_fraction = [0.6, 0.75, 0.9]
bagging_freq = [2, 4, 5, 8]
lambda_l1 = [0, 0.1, 0.4, 0.5]
lambda_l2 = [0, 10, 15, 35]
cat_smooth = [1, 10, 15, 20]
param = {'n_estimators':n_estimators,
'learning_rate':learning_rate,
'subsample':subsample,
'colsample_bytree':colsample_bytree,
'max_depth':max_depth,
'is_unbalance':is_unbalance,
'early_stopping_rounds':early_stopping_rounds,
'num_boost_round':num_boost_round,
'metric':metric,
'feature_fraction':feature_fraction,
'bagging_fraction':bagging_fraction,
'lambda_l1':lambda_l1,
'lambda_l2':lambda_l2,
'cat_smooth':cat_smooth}
model = LGBMClassifier()
clf = GridSearchCV(model, param, cv=3, scoring='accuracy', verbose=1, n_jobs=-1)
clf.fit(X_train, y_train, eval_set=[(X_train, y_train),(X_test, y_test)])
print(clf.best_params_, clf.best_score_)
得知预测结果准确率为 0.888
预测结果
y_true, y_pred = y_test, clf.predict(X_test)
accuracy = accuracy_score(y_true,y_pred)
print(classification_report(y_true, y_pred))
print('Accuracy',accuracy)
查看混淆矩阵
from sklearn import metrics
confusion_matrix_result = metrics.confusion_matrix(y_true, y_pred)
plt.figure(figsize=(8,6))
sns.heatmap(confusion_matrix_result, annot=True, cmap='Blues')
plt.xlabel('predict')
plt.ylabel('true')
plt.show()
输出结果得到表格 submission.csv
test_x = test[feature_columns]
pred_test = clf.predict(test_x)
result = pd.read_csv('./submission.csv')
subscribe_map ={1: 'yes', 0: 'no'}
result['subscribe'] = [subscribe_map[x] for x in pred_test]
result.to_csv('./baseline_lgb1.csv', index=False)
result['subscribe'].value_counts()

求带!!

博主的文章真是太有用了

向你学习!!👍👍

大神!!教教我吧!!



太棒啦❀❀

帖子对我很有帮助👍
