


442
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享询问chatGPT什么是正向建模,它给出了这样的答案:
正向建模是一种用于描述和分析系统或过程的建模方法。它基于系统的目标和行为,以及各个组成部分之间的相互作用关系,从而生成系统的模型。
在正向建模中,建模过程从系统的高层目标出发,逐步细化到具体的组成部分和其行为。它着重于描述系统的结构和功能,以及各个组件之间的交互关系。这种建模方法通常用于系统设计、工程分析和软件开发等领域。
正向建模的一般步骤包括:
- 确定系统的高层目标:明确系统要达到的目标和期望的结果。
- 识别系统组成部分:将系统划分为各个组成部分或模块,并确定它们之间的关系。
- 描述组成部分的功能和行为:对每个组成部分进行详细描述,包括其功能、输入和输出。
- 定义组件之间的交互关系:确定各个组件之间的通信和数据流动方式,以及它们在系统中的相互作用。
- 构建系统模型:使用适当的建模工具或技术,将系统的结构、功能和交互关系表示为模型。
- 分析和验证模型:对建立的模型进行分析和验证,以确保其符合系统需求和目标。
正向建模方法可以帮助开发人员和系统设计者更好地理解系统的行为和交互,从而促进系统的设计、开发和优化。它在系统工程、软件工程和业务流程建模等领域中得到广泛应用。
了解了正向建模的含义之后,我认为我们在本单元中根据指导书所写的需求画出UML图就是一个完整的正向建模过程。将上面列出的正向建模具体步骤对应到本单元的作业中,应该就是第1步对应阅读、理解指导书;第2、3步对应构建UML类图;第4步对应构建UML状态图和顺序图;第5步对应使用StarUML画出图;第6步对所画出的图进行验证。
以本单元第一次作业为例,我先通读了一遍指导书,明白了本单元需要我们实现一个图书馆模拟系统,其中具体需要实现借书、还书等功能。之后我就对着指导书的情景描述进行分析,初步提取出需要构建的类以及需要实现的方法。以这段文字为例:(*假设已有图书馆、书等类)
如果所需书籍目前有余本在架上,那么该同学会到对应类别的书架处取书。如果是A类书籍,该同学将在图书馆完成阅读 (阅读时间忽略不计,即假设同学从书架取书后立即完成阅读,将书放回) ;如果是 B 类书籍,该同学会先到 借还管理员 处登记,若符合借书数目限制则成功借书,否则书本 当即被留在借还管理员处 ,借书失败;如果是 C 类书籍,该同学会直接到 自助机器 处刷卡借书,若符合借书数目限制则借书成功,否则书本 当即被留在自助机器处 ,借书失败。
先提取名词——借还管理员、自助机器,这显然是需要构建的两个类,它们也需要在图书馆类中实现一个实例。再分析流程,借书分为ABC三类,A类即仅在图书馆类中完成;B类书需要在借还管理员类中实现一个借书方法;C类书则需要在自助机器类中实现借书方法,这两个借书方法都需要根据一个学生所拥有的的书进行数目限制判断。
这样逐段读下去,就初步完成了UML类图的构建。接下来,我就会再根据情景描述看着已有的类图尽可能多的模拟情况来完善类图。最后就是根据类图来具体编写代码了。
根据这样的正向建模与开发流程,虽然前期在分析指导书构建类图时仍稍显痛苦,但构思好之后编写代码可谓是一泻千里十分顺利,也真真切切体会到了这种方法带来的好处。
由于构建的类比较多且三次作业提交中都包含了类图,在此仅展示与主干逻辑有关的类
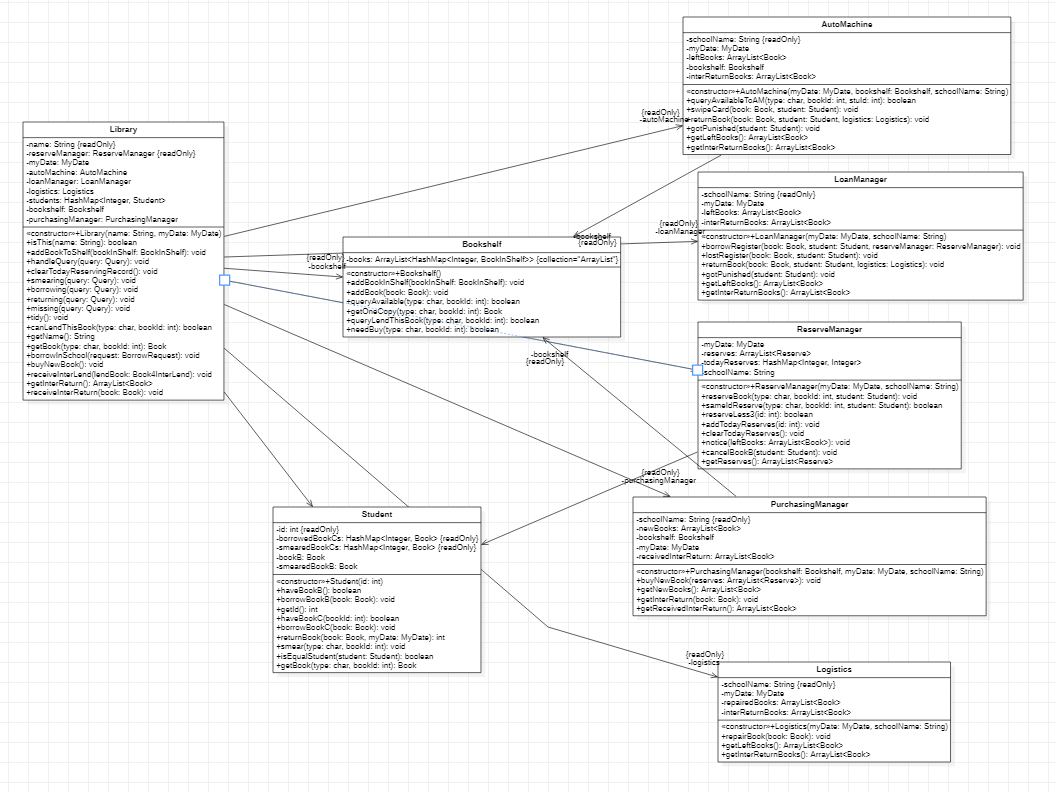
对于主体业务逻辑我是构建了一个 图书馆类 来进行处理,几位管理员以及自助机器均可以看作是图书馆的 工作人员,故在图书馆中实现各一个实例即可。同时我还在图书馆中构建了 书架类,用于模拟真实图书馆的馆藏,允许借阅的书籍均保存在书架类中,书架类在图书馆类中进行实例化,需要访问书架的工作人员(比如自助机器、图书管理处、整理管理员等)将书架的引用通过构造方法传入类中作为一个属性。各种输入请求由图书馆类来进行综合分析,之后调用这些工作人员类的中方法来进行处理。
在第14次作业增加校际借阅后,我们需要构建多个图书馆实例,同时还需要这些图书馆之间相互通信交流传递书籍。对此,我构建了一个总的 控制类 ,在这个控制类中有所有图书馆的实例,由控制类来负责一开始对输入指令的分配,之后每一天对业务流程的控制以及校际图书的传递。
在控制类中实例化一个日期,并将其引用传入各图书馆类,图书馆类又将引用传入各个需要输出日期的工作人员类中,这样在控制类中变更日期,所有上述类都能同步更新。但需要注意的是,每个请求以及借到手的书中不能是引用,必须实例化一个日期用以存储请求目标日期或是书的借阅日期。
代码设计与UML类图间的追踪关系——非常紧密
从本单元第一次作业开始就要求了类图的绘制,在架构设计之初也遵循了正向建模的模式,在开发过程中也注意了类图与代码的对应。
代码设计与状态图的追踪关系——较为紧密
第14次作业时先是较为细致的根据指导书还有自己的代码绘制了一本书的状态图,也顺利通过了相应评测。
代码设计与顺序图的追踪关系——一般
此次顺序图也并没有达到事实求是反应代码流程的过程,并且仅绘制了借阅到预定图书的部分,其中为了通过评测还反反复复做出了一些修改。
第一单元是我真正意义上第一次采用面向对象的思想去解决问题(OOPre的作业主要还是熟悉java语法),面对复杂的表达式,面向过程的编程思想显得无从下手。这因为如此,我才更深刻地体会到面向对象分析解决问题的优势,将复杂的表达式层层解析为一个个对象,使用递归下降的方法对其进行解析和处理,最终迎刃而解。但是现在再回头去看第一单元的代码,相比于第四单元还是有很明显的“面向过程”的影子,这也导致部分模块的处理显得尤为臃肿,方法复杂度也非常高。
第二单元主要学习多线程编程以及设计模式的应用,这也是我第一次学习使用多线程的方法编写代码,对线程同步互斥的理解还非常浅,导致处理线程同步和线程安全的问题上花费了大量的时间和精力。但同样的,这个单元的作业给我带来的进步也格外显著,不光是熟悉了多线程的使用方法,更重要的是学习到生产者消费者模型和流水线模型,通过在作业中设计这两种模型也加深了对面向对象编程的理解,将调度器、托盘、需求、电梯等设计为对象,分别思考他们的功能,最终作为一个个模块组合为项目,这也让我体会到面向对象编程“分治”的特点。
第三单元的核心是学习JML规格化语言,没有太多需要自己设计架构的地方。此外也借此复习了图论的相关算法,并了解到各个基础算法的优化方式。不过这一单元课程组提供的代码架构也确实让我学习到不少经验,这在我第四单元的架构设计中其实也有一定体现。把person、relation分别看做图的节点和无向边,构建起来网络模型,并针对这个网络进行一些功能拓展(如分组,发送信息)。
第四单元的架构设计相已经在前面详细论述了,我认为我的架构相较第一单元还是有了不小的进步。像是在第一次作业中就模仿实际图书馆把所有工作人员类都放在一个图书馆类中,这样就让第二次作业的迭代比较容易。此外,像上面提到的有关日期、图书的细节处理,都自然而然地采用了面向对象的思想,让整体的架构高内聚低耦合。
可能是运气好或者是OOpre难度相对较低的缘故,我在上学期的课程中每次作业在通过中测后没有进行任何测试就都通过了强测。这也就导致了我在本学期第一单元的前两次作业疏于测试,在通过中测后就没有再进行测试,最后两次作业强测各扣了30分。后面的作业就再也不敢大意了。先是使用一些在各种群里流传强测试点或者自己手动构造一些测试点和同学进行对拍,之后又开始使用别人编写好的评测机,到第三单元开始和同学尝试用python自己编写评测机,最后第三第四单元都使用了自己写的评测机。最终,除了前两次作业,后面作业强测和互测均没有再出现bug。
在本学期课程之前,自己的程序或许谈不上测试,一直都是做题通过评测即万事大吉的思想。而经过一学期的锻炼,自己能清晰地认识到测试以及搭建自动评测机地必要性。
首先本学期OO课程带来的最大收获就是学习到面向对象的思想,不光是在作业上,包括后面几次的评测机编写,其实都或多或少体会到面向对象的优势。另外也学到很多知识,包括git的使用,单例、生产者消费者等设计模式,markdown的使用,jml语言和uml图等。
另外,一次次作业的迭代开发也让我意识到设计和架构的重要性,一个好的架构能够帮助程序员更加方便和顺利地维护项目、拓展功能,尽量减少各个模块之间的耦合度,防止修改或增加一个功能,会导致其他模块的功能受到影响,最终导致迭代难度过高而重构。
当然还有代码风格的变化,一学期的作业都要求我们按照一定的代码规划进行编写,我也切实感受到经过OO课程的实践,自己代码风格的规范化。比如在OS挑战性任务中会习惯性地增加空格,不至于看上去那么紧凑;也会自主地使用规定的方法对变量和方法进行命名,增加代码的可读性。



