


199
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享随着深度学习的发展,人们已经不满足于将深度学习应用于传统的图像、声音、文本等数据上,而是对更一般的几何对象如网络、空间点云、曲面等应用深度学习算法,这一领域被称为几何深度学习(Geometric deep learning)。人们尝试在不规则的非欧氏的数据上扩展卷积神经网络模型,这便有了图卷积神经网络(Graph Neural Network)、PointNet等新的技术。
本文提到的文献,文末均附有下载地址
2016年,Bronstein的一篇名为《Geometric deep learning: going beyond Euclidean data》[1] 的文章来势汹汹,该文的后两位作者分别是Facebook前人工智能团队博士后成员Joan Bruna和现人工智能负责人Yann LeCun,这也算得上是全明星阵容,因此这篇文章的含金量和参考性就得以保证。
那么几何深度学习(Geometric deep learning)到底指什么?有能在哪些应用中体现价值呢?
在信息快速发展的现代社会,最具有价值的、最核心的宝藏是数据,可以说没有数据就没有机器学习的兴起和发展。

但是,另一方面让人头痛的也是数据:
但是现实生活中,我们能够通过目前的测量手段获得的数据,它们的底层结构是非欧几里得空间的,这类数据我们暂且称为非欧几何数据,最典型的两种非欧几何数据是图和流形。
图(Graph)是指的节点、连边组成的网络结构数据,比如社交网络;流形(Manifold)则通常用于描述几何形体,比如雷达扫描返回的各类物体表面的空间坐标。值得一提的是,这些几何数据通常具有恐怖的数量级,就拿社交网络来说,它的规模轻轻松松就能超过10亿,如果还妄想用传统的统计方法去分析和预测,那就过于天真和浪漫了。这就是为什么深度学习在几何数据领域有了用武之地。
那么下面就以该领域的两大类问题为主,介绍一些几何深度学习的应用场景和已有技术。第一类是3D图像的识别和分割,第二类是图信号的处理和预测。
随着图像处理结束的飞速发展,特别是卷积神经网络(CNN)的提出,让2D图像识别的精度超越了人类,仔细想想这是一件非常不可思议的事,冰冰凉凉的计算机真得能够模仿人类大脑学习如何看一张图片。
在这里,一定要吹捧一下CNN卷积神经网络构架的针对图像特征学习的有效性,在下面将要提到的文章中,要么是把CNN直接应用到网络模型中,要么就是模仿CNN提取特征的模式设计出心的非欧数据特征提取的框架,因此在图像处理这个领域,CNN功不可没。基于2D图像的深度学习技术,我们见识了五花八门的应用,比如人脸识别、机器看图说话(结合RNN)、物体检测(比如地铁安检扫描背包)、包括视频中的物品追踪等。
深度学习在大多是1D(声波信号)、2D(图片)以及3D(视频)等欧几里得结构化数据中表现不俗,其应用也方便了人们的生活,但是有很多问题仍然是现有技术无法处理的,其中一个很重要的问题就是如何进行空间中的物体探测和识别,也就是3D模型的识别和分割问题。
这个技术最直接的应用就是机器人操控和无人驾驶,以无人驾驶为例,车内的雷达系统会对车身周围的环境进行扫描,传回周围物体的空间坐标,接着片判断障碍物和行人的位置,然后进行合理的路线规划。我们需要建立一套网络输入是类似于空间坐标的非欧几里得数据,输出是对物体的探测或者分割。下面我们就介绍一下几种现有的能够完成3D模型分类和分割任务的技术。
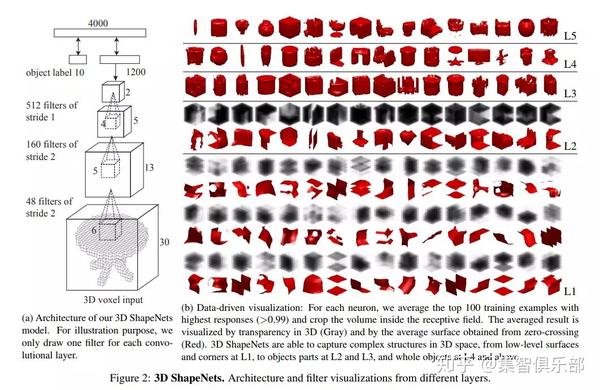
该技术的核心思想是把输入的3D形状数据表示(比如基于从视觉上与场景的表面的距离构建的Depth Maps深度图)转化为标准的3D立体数据表示(volumetric representation),并且提出一种对规则的、固定大小的3D立方体(voxel grids)进行卷积的网络构架去进行模型的识别和分割任务。其中,比较具有代表性的一种网络构架是普利斯顿大学2015年提出的ShapeNet[2]。
其实这种方法的思路可以说看作模拟CNN处理二维图片的方法,那么第一步就是把3D图形表示成一种标准的可处理的单位格式,于是就有了voxel的概念,类似于CNN处理pixel的信息一样。?
这样的方法存在的问题是,计算过程中内存的占用将会很大,也需要较长的时间去学习。与此相关的其他工作,比如:
区别于立体删格化的方法,多视角神经网络在处理3D图像的分类和分割任务中的中心思想是,用多张不同角度2D的图像来提取3D图像的表面特征,直接处理相应的2D图片信息从而进行3D物体的识别和探测,这样就可以直接利用二维图像上成熟的CNN技术。具有代表性的工作是2015年,马萨诸塞大学在2015年发表的工作Multi-view CNN[7]。
这种技术的思想并不难理解,跟人类肉眼识别物体类似,如果从一个角度上无法分别,可以试着从不同角度去辨别,多视角解析3D模型技术也正是利用了这点。这项技术可以用在三维模型的重建工作中。

??当然该方法的缺点是因为物体自遮挡的问题,在拍摄图片是会损失一些表面信息,并且角度的选择通常具有人工的痕迹,这样的操作不一定是完成任务必须的操作。相关工作如下:
当然除此之外,还有作者比较了两类方法,进行了分别的改进,并测试了不同的网络结构对结果的影响。值得一提的是下文的作者Charles R. Qi,也正是最新的基于点云识别3D图形的技术的提起人。
无论是基于立体删格化技术,还是基于多视角技术,它们都需要对原始的3D数据进行一些了的重新切割或者是映射到2D空间,而点云技术与他们最大的不同,在与他可以直接处理原始的三维图形表面的空间坐标。
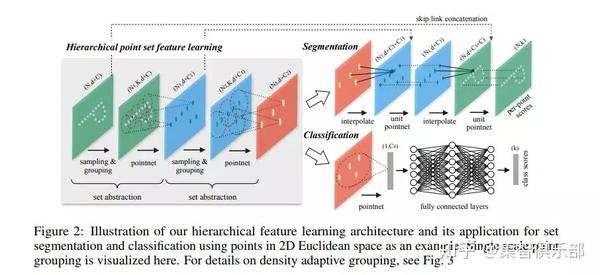
如果输入数某物体三维空间的点云则输出对该点云的预测;在场景分割任务中,则分别预测出每一个点的分类。该技术相比以上两种技术更新,并且可以结合网络的表征学习在节点分类、图分类领域提供新的思路。开篇之作是斯坦福大学(Charles R. Qi)2017年发布的PointNet[13]构架。

接着2017年底作者在原有框架中,模仿CNN中层级性的特征提取思想,提出了PointNet++[14]构架,再一次提高了分类和分割任务的精度。
当然这种方法最大的问题根据三维点提取的物体表面的信息可能与真是情况存在偏差,点云的采集和取样方法都会影响结果。因此也有不少针对该类型方法的改进:
另一类非欧几何数据就是图,这类数据最大的特点是他们底层结构是一个由节点和连边组成的网络,比如社交网络中人是节点、用户之间的互动比如关注、喜欢等就构成了连边。这样的抽象方法可以解决很多真实世界中信号传播的问题。
比如在传感器网络中,图像模型是由分布式互连传感器构成,其读数即为网络中的信号,这个信号是分布在网络中每一个节点上;在遗传学中,我们知道基因控制这蛋白质的表达,而基因组成的网络成为基因调控网络,每个基因节点都有一个信号值,在不同时间步这个信号值可能会发生变化,进而指挥不同蛋白质的形成。

对于这样的图信号,由于它底层的数据结构的特殊性,以往的信号处理方式是失效的,于是在2011年左右诞生了以图傅里叶变换(Graph Fourier Transform)为基础的图信号处理(Graph Signal Processing)理论,其思想类似于普通的信号处理,将实域上的信号转化为谱域表示,然后在谱域上完成其他工作。而进一步,计算机科学家们套用CNN的思想定义了图上的卷积(Graph Convolution)操作,搭配深度学习框架,逐渐我们能够实现图结构数据表征学习以及图上信号的预测等图结构的几何深度学习。
当然目前来说,该方法最大的弊端在于数据的底层结构,也就是图的拓扑结构对数据的谱域表达影响比较大(因为在图傅里叶变换中用到了图的拉普拉斯矩阵,它与网络的邻接矩阵有关,邻接矩阵定义了图的底层结构),因此它无法迁移到不同图结构的网络模型中。
就现目前的发表的工作来说,大多数基于图结构的深度学习,都是为了进行图上节点的表征学习,也就是把节点表示成一个高维的向量,在此基础上将进行网络上节点的分类任务或者聚类任务等。下面我们介绍几篇有代表性的工作。
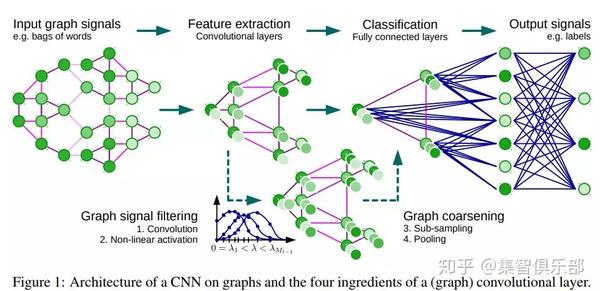
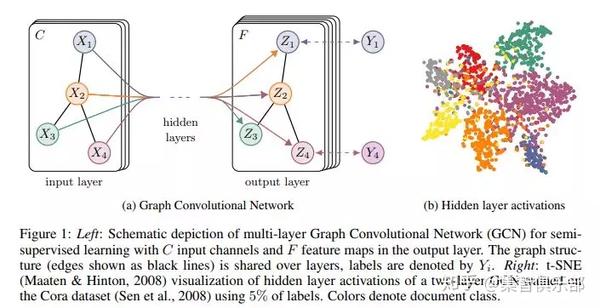
事实上DeepMind团队也开始关注图上的深度学习,在前不久发表了一篇名为《Learning Deep Generative Models of Graphs 》[24] 的文章,文章提出了一种利用深度学习技术生成网络结构的新框架,他的适用范围可以应用在制药、自然语言生成等领域。说不定再过几年,机器人就可以在制药领域大展身手,生成更有效的化学分子结构,从而治疗疑难杂症哟~
以上就是几何深度学习的一些梳理和整理,这个分支的发展可以让我们大胆的幻想一下未来的智能世界,无人驾驶使得路上交通更规范而有序,也消除了醉酒驾驶、疲劳驾驶等一些了人为的安全隐患;智能机器人代替单调而重复的人力劳动,甚至可以参与制药等高精端领域将大数据的价值发挥到最大。尽管在科技的发展中,不会一帆风顺,总有艰难险阻,但是人类的智慧从来不止步于不可能,反正就是日常做做梦,科技万岁~
[2]ShapeNet:http://3dshapenets.cs.princeton.edu/paper.pdf
[3]3D-CNN:3D Convolutional Neural Networks for Landing Zone Detection from LiDAR:https://www.ri.cmu.edu/pub_files/2015/3/maturana-root.pdf
[5]VoxNet:A 3D Convolutional Neural Network for Real-Time Object Recognition:https://www.ri.cmu.edu/pub_files/2015/9/voxnet_maturana_scherer_iros15.pdf
[7]Multi-view CNN:http://vis-www.cs.umass.edu/mvcnn/docs/su15mvcnn.pdf
[8]GIFT: A Real-time and Scalable 3D Shape Search Engine:http://suo.im/4rNPZi
[9]ShapePFCN:3D Shape Segmentation with Projective Convolutional Networks:http://suo.im/5irmbO
[10]Spherical Projections:3D Object Classification via Spherical Projections:http://suo.im/4GQgv6
[12]Volumetric and Multi-View CNNs for Object Classification on 3D Data:http://suo.im/53szCy
每一个HTML文档中,都有一个不可或缺的标签:<head>,在几乎所有的HTML文档里, 我们都可以看到类似下面这段代码:
html{color:#000;overflow-y:scroll;overflow:-moz-scrollbars}
body,button,input,select,textarea{font-size:12px;font-family:Arial,sans-serif}
h1,h2,h3,h4,h5,h6{font-size:100%}
em{font-style:normal}
small{font-size:12px}
ol,ul{list-style:none}
a{text-decoration:none}
a:hover{text-decoration:underline}
legend{color:#000}
fieldset,img{border:0}
button,input,select,textarea{font-size:100%}
table{border-collapse:collapse;border-spacing:0}
img{-ms-interpolation-mode:bicubic}
textarea{resize:vertical}
.left{float:left}
.right{float:right}
.overflow{overflow:hidden}
.hide{display:none}
.block{display:block}
.inline{display:inline}
.error{color:red;font-size:12px}
button,label{cursor:pointer}
.clearfix:after{content:'\20';display:block;height:0;clear:both}
.clearfix{zoom:1}
.clear{clear:both;height:0;line-height:0;font-size:0;visibility:hidden;overflow:hidden}
.wordwrap{word-break:break-all;word-wrap:break-word}
.s-yahei{font-family:arial,'Microsoft Yahei','微软雅黑'}
pre.wordwrap{white-space:pre-wrap}
body{text-align:center;background:#fff;width:100%}
body,form{position:relative;z-index:0}
td{text-align:left}
img{border:0}
#s_wrap{position:relative;z-index:0;min-width:1000px}
#wrapper{height:100%}
#head .s-ps-islite{_padding-bottom:370px}
#head_wrapper.s-ps-islite{padding-bottom:370px}#head_wrapper.s-ps-islite #s_lm_wrap{bottom:298px;background:0 0!important;filter:none!important}#head_wrapper.s-ps-islite .s_form{position:relative;z-index:1}#head_wrapper.s-ps-islite .fm{position:absolute;bottom:0}#head_wrapper.s-ps-islite .s-p-top{position:absolute;bottom:40px;width:100%;height:181px}#head_wrapper.s-ps-islite #s_lg_img,#head_wrapper.s-ps-islite#s_lg_img_aging,#head_wrapper.s-ps-islite #s_lg_img_new{position:static;margin:33px auto 0 auto}.s_lm_hide{display:none!important}#head_wrapper.s-down #s_lm_wrap{display:none}.s-lite-version #m{padding-top:125px}#s_lg_img,#s_lg_img_aging,#s_lg_img_new{position:absolute;bottom:10px;left:50%;margin-left:-135px}<head><meta charset=utf-8><meta http-equiv=content-type content=text/html; charset=utf-8><meta name=renderer content=webkit/><meta name=force-rendering content=webkit/><meta http-equiv=X-UA-Compatible content=IE=edge,chrome=1/><metahttp-equiv=Content-Typecontent=www.aimssg.cn/emp;charset=gb2312><meta name=viewport content=width=device-width, initial-scale=1.0, minimum-scale=1.0, maximum-scale=1.0, user-scalable=no></head>.s-ps-sug table{width:100%;background:#fff;cursor:default}.s-ps-sug td{color:#000;font:14px arial;height:25px;line-height:25px;padding:0 8px}.s-ps-sug td b{color:#000}.s-ps-sug .mo{background:#ebebeb;cursor:pointer}.s-ps-sug .ml{background:#fff}.s-ps-sug td.sug_storage{color:#7a77c8}.s-ps-sug td.sug_storage b{color:#7a77c8}.s-ps-sug .sug_del{font-size:12px;color:#666;text-decoration:underline;float:right;cursor:pointer;display:none}.s-ps-sug .sug_del{font-size:12px;color:#666;text-decoration:underline;float:right;cursor:pointer;display:none}.s-ps-sug .mo .sug_del{display:block}
.s-ps-sug .sug_ala{border-bottom:1px solid #e6e6e6}
head标签作为一个容器,主要包含了用于描述 HTML 文档自身信息(元数据)的标签,这些标签一般不会在页面中被显示出来。
