




4,662
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享存内计算助力“边缘学习”,清华存内芯片登Science
边缘学习
想象一下,如果智能设备能够进一步的适应不同的用户习惯和环境变化,那是不是就意味着进一步的定制化服务,这应该是符合我们对于未来生活的预期,因此学习能力对于智能设备而言,是一个极富吸引力的需求。
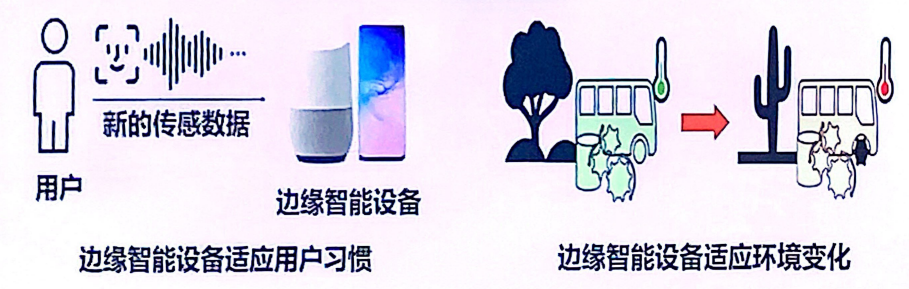
大脑的智能一部分来源于先天遗传,一部分来源于后天学习。受此启发,学者们认为增量学习是学习能力培养的重要途径。对比到智能设备,就是,在其出厂时,已配备了基础知识,而到了使用场景后,能通过新类别或新样本数据,在保有已有知识的基础上快速地学习新知识,达到更进一步的适配环境。【1】
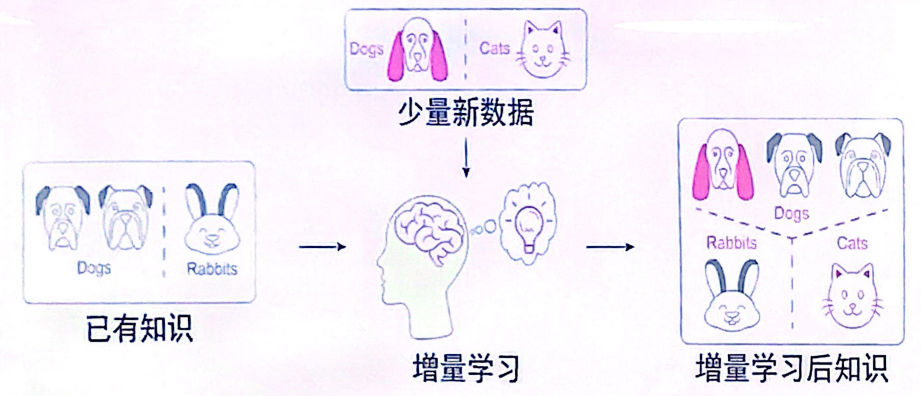
针对于智能设备的学习能力,目前有两条主要的技术路线:
智能设备将新数据上传到云端服务器,由云端服务器进行学习,并将更新后的模型传回边缘智能设备。
其存在延迟、功耗、成本高,安全性、可靠性差等问题。
在已有模型基础上,通过新数据,在边缘端直接完成模型的更新。
但如此将迎来功耗、算力以及学习能力的三重挑战。
存内计算的功耗、算力优势
随着神经网络规模的扩大,传统以CPU+GPU架构处理神经网络算法的模式逐渐遇到了速度和功耗的瓶颈,究其根源是因为冯·诺伊曼架构下存算分离使得以数据为中心的神经网络算法给计算系统带来过大的数据传输开销,降低速度的同时增大了功耗。
存内计算的概念最早可以追溯到上个世纪70年代,但是由于当时的技术限制和算力需求的不足,它并没有得到广泛的应用。直到近年来,随着半导体制造技术的突飞猛进,以及AI、元宇宙等算力密集的应用场景的崛起,存内计算技术才重新受到了学术界和产业界的关注和研究,并逐渐成为研究热潮。【2】
存内计算技术解决了存算分离导致的问题,通过将神经网络的权重存储到存算一体(NPU)芯片中的闪存阵列节点的电导上,再将以电压表示的数据源送入阵列,由欧姆定律可知,阵列输出的电流为电压和电导的乘积,从而完成了数据源和网络权重的矩阵乘加运算。这种利用器件物理特性,在存储器中直接进行高并行计算的范式,突破了数据传输的瓶颈,提高算力的同时又极大的降低了功耗,成为了边缘智能设备领域的重点关注对象。
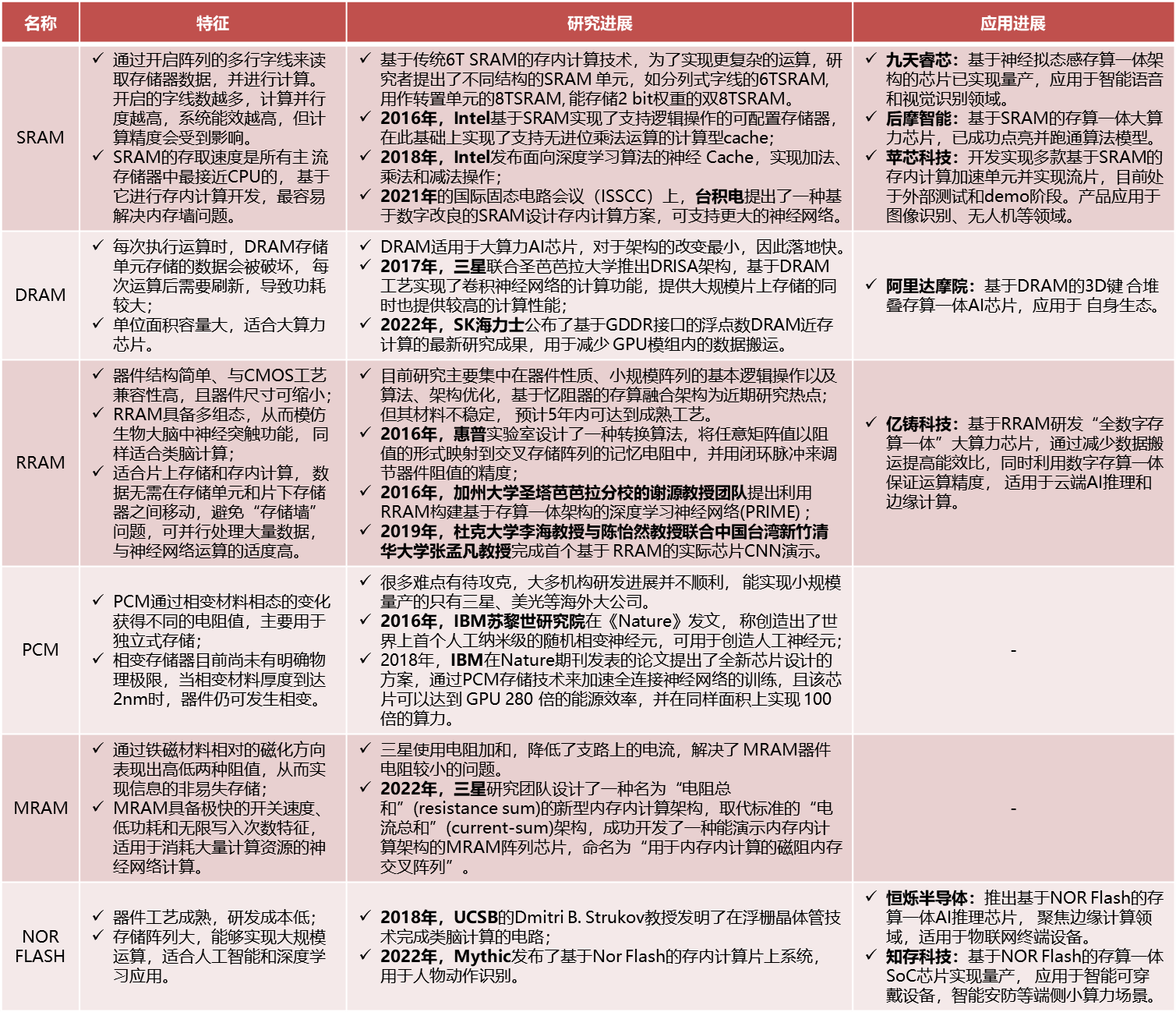
当然,前沿的研究人员和创业者们早就摩拳擦掌地涌进了这个赛道。下图是以不同器件为基础的存内计算研究进展以及应用在前的科技企业。
存内计算片上学习
9月14日,清华大学吴华强、高滨老师团队在Science在线发表了题为“Edge learning using a fully integrated neuro-inspired memristor chip”的研究论文,论文显示,团队基于存内计算范式,研制出全系统集成、支持高效片上学习(机器学习能在硬件端直接完成)的存内计算芯片。相同任务下,该芯片实现片上学习的能耗仅为先进工艺下专用集成电路(ASIC)系统的1/35,同时有望实现75倍的能效提升。这一突破,无异于向世界宣布,AI时代的新技术方向——基于存储器运行计算的新型架构模式,潜力是巨大的。
该文提出了适用于忆阻器(RRAM)存算一体芯片的基于符号和阈值的学习架构STELLAR(sign-and threshold-based learning architecture),该学习架构包括两个阶段:前向推断和权重更新。【3】
前向推断基于存内计算通用范式。
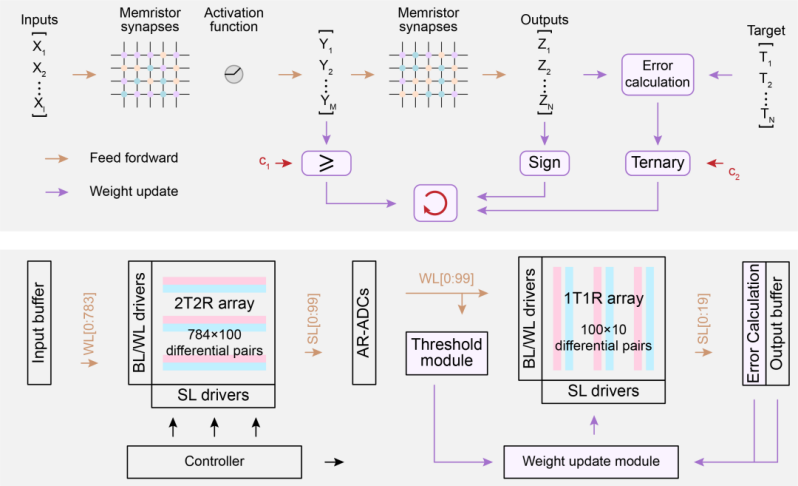
图片来自清华大学微信公众号[4]
权重更新时:
另外,在该文的存内计算架构中,是用两个器件电导的插值表示神经网络中的一个权重,权重更新时采用并行交替的电导调制策略进行传递。
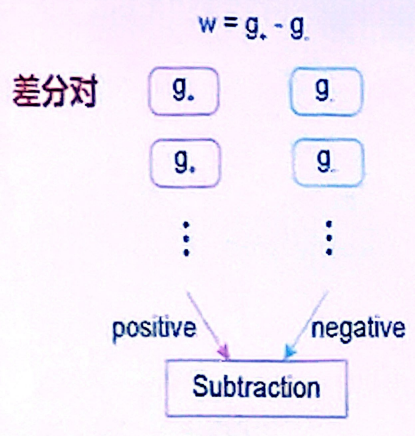
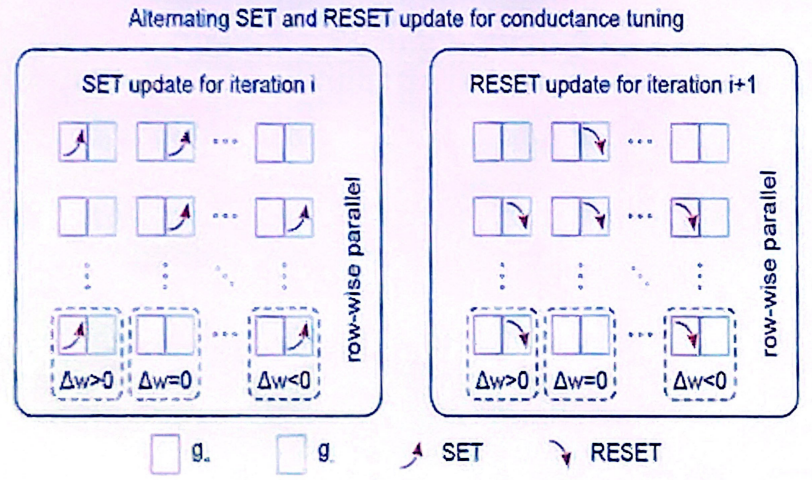
通过利用符号和阈值,与基于BP实现的比较,STELLAR方案在准确率基本没有损失的前提下,权重更新过程的能耗降低了两个量级。
综上,存内计算技术路线不仅能够有效的解决边缘智能设备现阶段面临的算力、能耗问题,而且针对于未来的边缘学习场景,也勾勒出了想象空间。
未来展望:AI大模型计算
伴随着Bert,Chat-GPT,Gemini等人工智能大模型的井喷式发展,存储计算需求呈爆炸式增长,云端需要TB级权重数量,边缘端也逐渐向GB级发展。
传统数字芯片存储计算瓶颈越来越严重,为了降低延迟而在片上集成SRAM,但片上容量有限,无法支撑大模型参数存储;如果采用片外DRAM/HBM方案,成本又过高,且数据搬运延迟大,功耗高。
而存算一体架构能够有效的解决上述问题,一方面片上集成规模提高了一个数量级;另一方面,在同等工艺制程下性能也提高了一个数量级,14nm可等效4nm的传统电路性能表现。

近期在中国科学发表的《存算一体芯片发展现状、趋势与挑战》[5]一文中,来自北京航空航天大学的学者们介绍了存算一体芯片当前的研究现状,并从技术与应用的角度分析了其未来的发展趋势:
(1)前移至感知端,与传感器融合,向“极致低功耗”迈进;
(2)后移至边缘端/云端,面向大模型场景,向“极致大算力”迈进;
(3)协同异构架构与异构集成,实现合力突围;
(4)驱动 EDA 设计工具与应用工具链开发,加速规模化量产应用。
相信在不久的将来,在学者、企业和社区的共同努力下,存算一体架构创新,能协助我国集成电路领域一举突破算力“卡脖子”问题。
参考文献:
【1】20231125-上海类脑智能材料与器件研究中心-存算一体技术研讨会-《支持在线学习的存算一体芯片》-高滨
【2】郭昕婕, 王光燿, 王绍迪. 存内计算芯片研究进展及应用[J]. 电子与信息学报, 2022, 44: 1-11.
【3】Zhang W, Yao P, Gao B, Liu Q, Wu D, Zhang Q, Li Y, Qin Q, Li J, Zhu Z, Cai Y, Wu D, Tang J, Qian H, Wang Y, Wu H. Edge learning using a fully integrated neuro-inspired memristor chip. Science. 2023 Sep 15;381(6663):1205-1211. doi: 10.1126/science.ade3483. Epub 2023 Sep 14. PMID: 37708281.
【4】清华大学:https://mp.weixin.qq.com/s/w0VZNIQ1KbClJJ8c05hPqg
【5】康旺, 寇竞, 赵巍胜. 存算一体芯片发展现状、趋势与挑战. 中国科学:信息科学,2024年第1期,doi:10.1360/SSI-2023-0311


