




6,135
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享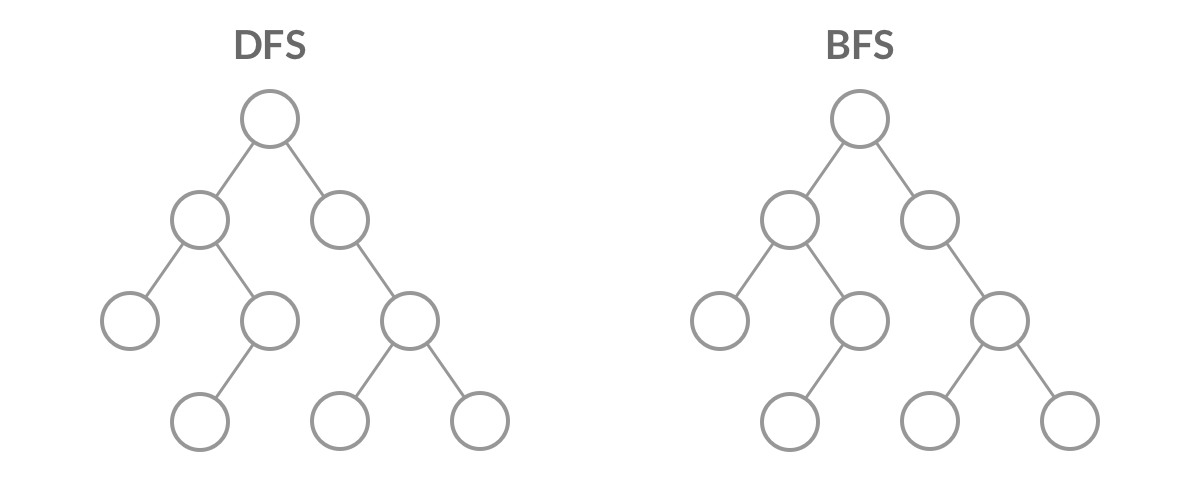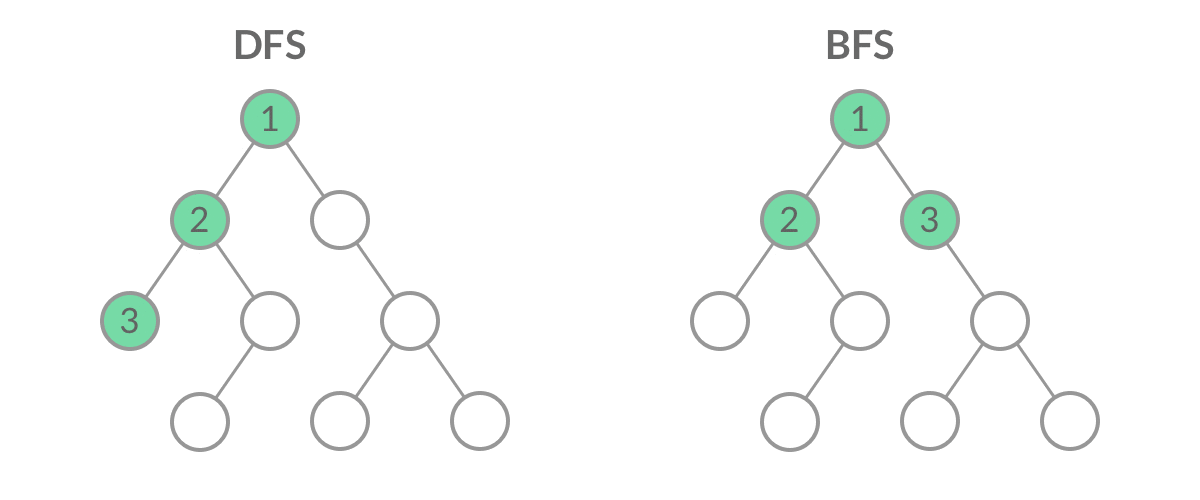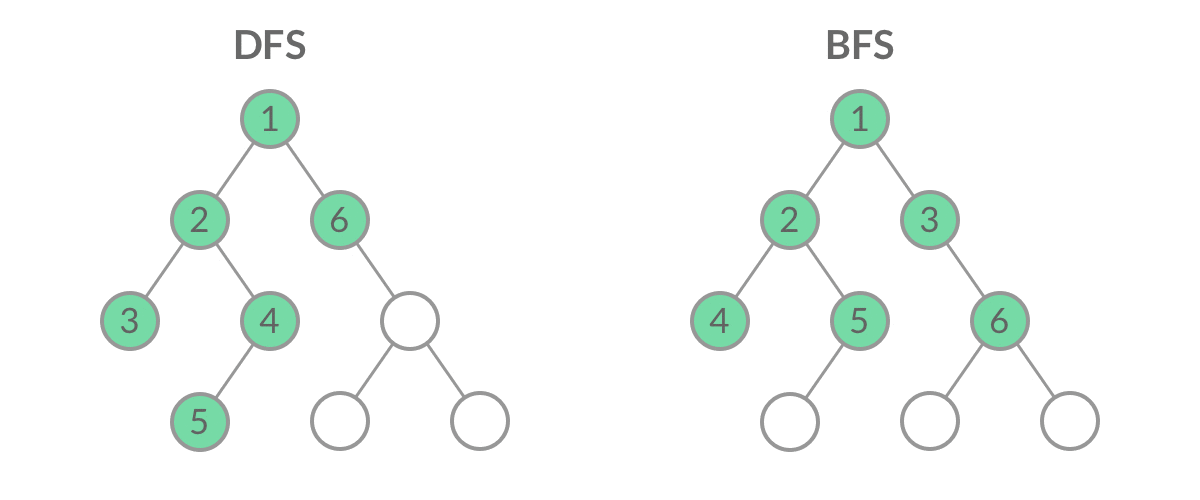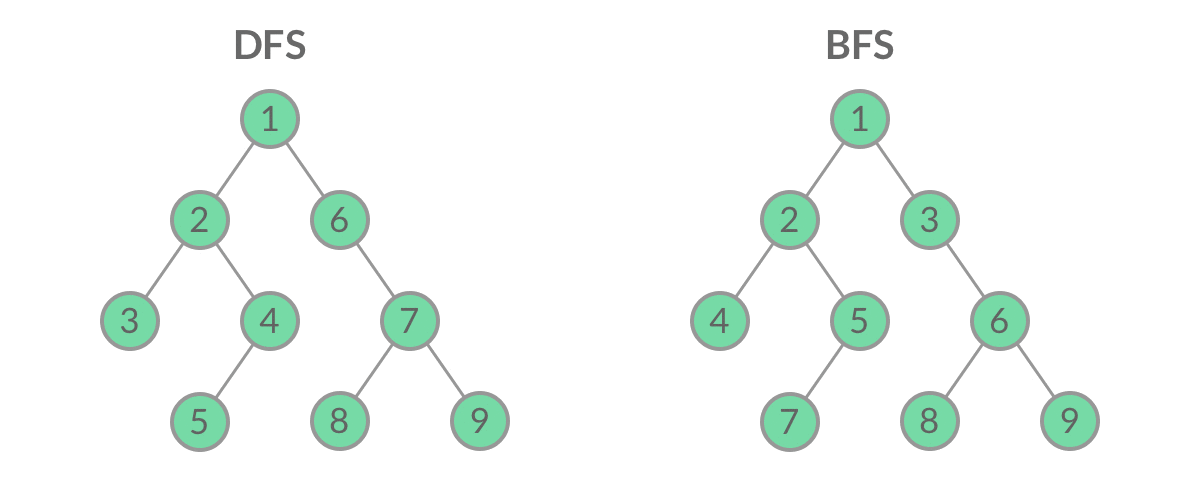
深度优先搜索(DFS)和广度优先搜索(BFS)是常用的图搜索算法。它们可以用于许多不同的应用,例如:
总之,DFS和BFS是非常常见和有用的算法,它们可以应用于许多不同的领域,包括计算机科学、人工智能、生物学、社会网络等。
不太懂的看视频 QWQ(来自@码农论坛)
深度与广度优先搜索
深度优先搜索一般通过递归实现,也可以通过模拟栈实现。
1.创建一个栈并将起始顶点压入栈中。
2.当栈不为空时,进行以下操作:
3.重复步骤 2 直到栈为空。
//递归深度优先遍历
void DFS(ALGraph* G, int v, int* visited) {
printf("%c ", G->vertices[v].data);//输出顶点v
visited[v] = 1;//标记顶点v,表示已遍历
ArcNode* p = G->vertices[v].first;//p指向v第一条依附顶点v的边
while (p != NULL) {
//递归遍历顶点v未访问的邻接点
if (!visited[p->adjvex]) {
DFS(G, p->adjvex, visited);
}
p = p->next;
}
}
广度优先搜索使用队列来实现。
1.创建一个队列,并将起始顶点入队。 2.当队列不为空时,进行以下操作:
重复步骤 2 直到队列为空。
//广度优先遍历
void BFS(ALGraph* G, int* visited) {
int e;//用来储存出队的顶点的顶点数组中的下标
ArcNode* p = NULL;
Queue* Q = InitQueue();//初始化队列
Push(Q, 0);//把第一个顶点入队
visited[0] = 1;//标记第一个顶点
//循环结束条件为空队
while (Pop(Q, &e)) {
printf("%c ", G->vertices[e].data);//输出出队顶点
p = G->vertices[e].first;//指针p指向依附顶点e的第一条边
//将顶点e未访问的邻接点入队并标记
while (p != NULL) {
if (!visited[p->adjvex]) {
Push(Q, p->adjvex);
visited[p->adjvex] = 1;
}
p = p->next;
}
}
}
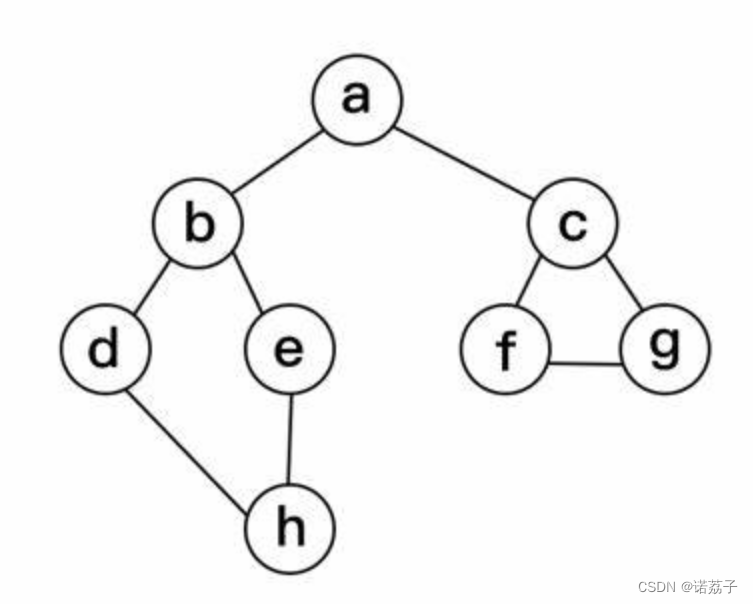
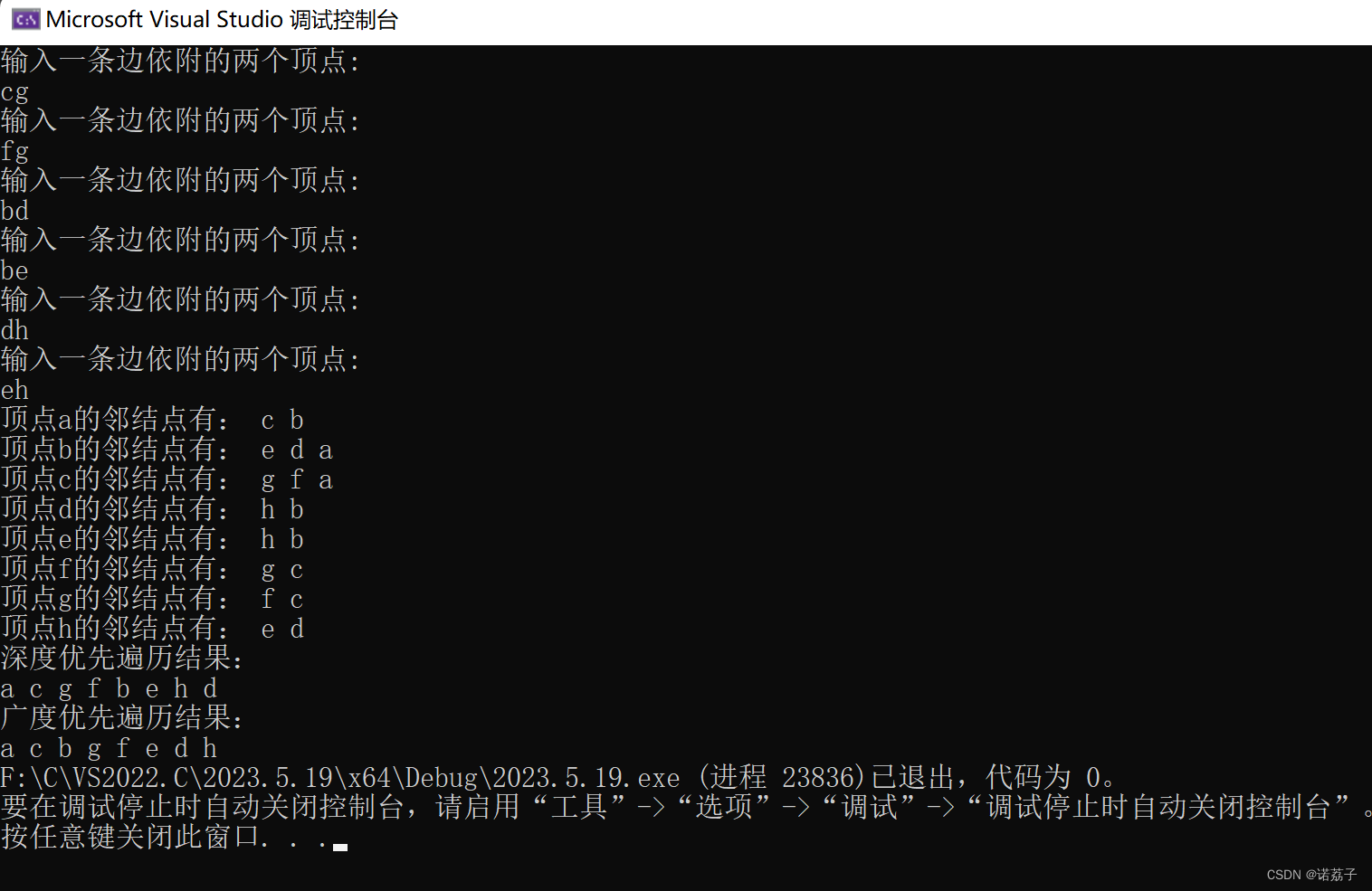
#define _CRT_SECURE_NO_WARNINGS 1
#include <stdio.h>
#include <malloc.h>
#include<stdbool.h>
#define MVNum 100 //最大顶点数
typedef struct ArcNode { //边表结点
int adjvex;//邻接点在顶点数组中的下标
struct ArcNode* next;//指向下一条边的指针
}ArcNode;
typedef struct VNode { //顶点信息结构体
char data;
ArcNode* first;//指向第一条依附于该顶点的边的指针
}VNode, AdjList[MVNum];
typedef struct { //图结构体
AdjList vertices;//邻接表
int vexnum, arcnum;//顶点数和边数
}ALGraph;
//查找
int LocateVex(ALGraph* G, char v) {
int i;
for (i = 0; i < G->vexnum; i++) {
if (G->vertices[i].data == v) {
return i;
}
}
return -1;
}
//无向图邻接表的创建
ALGraph* CreateALGraph() {
int i, j, k;
char v1, v2;
ALGraph* G = malloc(sizeof(ALGraph));
printf("输入顶点数和边数:\n");
scanf("%d%d", &G->vexnum, &G->arcnum);
getchar();//吸收换行符
printf("依次输入顶点信息:\n");
for (i = 0; i < G->vexnum; i++) {
scanf("%c", &G->vertices[i].data);
G->vertices[i].first = NULL;
}
getchar();//吸收换行符
//构造边表
for (k = 0; k < G->arcnum; k++) {
printf("输入一条边依附的两个顶点:\n");
scanf("%c%c", &v1, &v2);
getchar();//吸收换行符
i = LocateVex(G, v1), j = LocateVex(G, v2);//确定v1、v2在邻接表数组中的下标
ArcNode* p1 = malloc(sizeof(ArcNode));//生成新的边结点*p1
p1->adjvex = i;//邻接点序号为i
p1->next = G->vertices[j].first;//头插法插到顶点vj的边表头部
G->vertices[j].first = p1;
//因为是无向图,所以生成对称的边结点*p2
ArcNode* p2 = malloc(sizeof(ArcNode));
p2->adjvex = j;
p2->next = G->vertices[i].first;
G->vertices[i].first = p2;
}
return G;
}
//输出邻接表
void print(ALGraph* G) {
int i;
for (i = 0; i < G->vexnum; i++) {
printf("顶点%c的邻结点有:", G->vertices[i].data);
ArcNode* p = G->vertices[i].first;
while (p != NULL) {
printf(" %c", G->vertices[p->adjvex].data);
p = p->next;
}
printf("\n");
}
}
//递归深度优先遍历
void DFS(ALGraph* G, int v, int* visited) {
printf("%c ", G->vertices[v].data);//输出顶点v
visited[v] = 1;//标记顶点v,表示已遍历
ArcNode* p = G->vertices[v].first;//p指向v第一条依附顶点v的边
while (p != NULL) {
//递归遍历顶点v未访问的邻接点
if (!visited[p->adjvex]) {
DFS(G, p->adjvex, visited);
}
p = p->next;
}
}
typedef struct QNode {
int data;
struct QNode* next;
}QNode;
typedef struct {
QNode* front;
QNode* rear;
}Queue;
Queue* InitQueue() {
Queue* Q = malloc(sizeof(Queue));
QNode* t = malloc(sizeof(QNode));
t->next = NULL;
Q->front = t;
Q->rear = t;
return Q;
}
void Push(Queue* Q, int e) {
QNode* t = malloc(sizeof(QNode));
t->data = e;
t->next = NULL;
Q->rear->next = t;
Q->rear = t;
}
bool Pop(Queue* Q, int* e) {
if (Q->front == Q->rear) return false;
QNode* p = Q->front->next;
*e = p->data;
if (Q->rear == p) {
Q->rear = Q->front;
}
Q->front->next = p->next;
free(p);
return true;
}
//广度优先遍历
void BFS(ALGraph* G, int* visited) {
int e;//用来储存出队的顶点的顶点数组中的下标
ArcNode* p = NULL;
Queue* Q = InitQueue();//初始化队列
Push(Q, 0);//把第一个顶点入队
visited[0] = 1;//标记第一个顶点
//循环结束条件为空队
while (Pop(Q, &e)) {
printf("%c ", G->vertices[e].data);//输出出队顶点
p = G->vertices[e].first;//指针p指向依附顶点e的第一条边
//将顶点e未访问的邻接点入队并标记
while (p != NULL) {
if (!visited[p->adjvex]) {
Push(Q, p->adjvex);
visited[p->adjvex] = 1;
}
p = p->next;
}
}
}
int main() {
ALGraph* G = CreateALGraph();
print(G);
int visited_1[MVNum] = { 0 };
printf("深度优先遍历结果:\n");
DFS(G, 0, visited_1);
int visited_2[MVNum] = { 0 };
printf("\n广度优先遍历结果:\n");
BFS(G, visited_2);
}
两者的主要区别在于搜索的顺序不同,深度优先搜索的搜索顺序是一条路走到黑,直到遇到死路才回退,而广度优先搜索的搜索顺序是逐层遍历,先遍历距离起始节点为1的节点,再遍历距离起始节点为2的节点,以此类推。
文章来源: https://blog.csdn.net/m0_73070900/article/details/130868251
版权声明: 本文为博主原创文章,遵循CC 4.0 BY-SA 知识共享协议,转载请附上原文出处链接和本声明。


