





4,621
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享
随着人工智能技术的飞速发展,特别是在自动驾驶和复杂场景理解等领域,Transformer模型因其卓越的序列建模能力和对长距离依赖关系的捕捉而日益受到重视。Transformer模型的核心优势在于其能够更好地理解和处理复杂场景,这对于自动驾驶等应用至关重要。然而,面对日益增长的需求,如何在存算一体芯片上高效部署Transformer模型成为一个关键问题。
本文旨在探讨存算一体芯片如何高效支持Transformer模型。我们将从Transformer模型的核心组件、存算一体芯片对Transformer模型的支持、全连接层的优化、多头注意力的优化、编译优化和并行计算等方面展开讨论。通过结合实际案例和事实,我们将深入理解存算一体芯片在支持Transformer模型方面的优势和挑战,并探讨可能的解决方案。
目录
Transformer模型是一种基于注意力机制的深度学习模型,它在自然语言处理、计算机视觉和推荐系统等领域取得了显著的成果。Transformer模型的核心组件主要包括多层感知机(MLP)和多头注意力(MHA)。
MLP是一种前馈神经网络结构,由多个层次的神经元组成,每一层都与上一层的所有神经元相连。
在Transformer模型中,MLP负责对输入特征进行变换和映射,帮助网络捕捉不同层次的抽象特征。
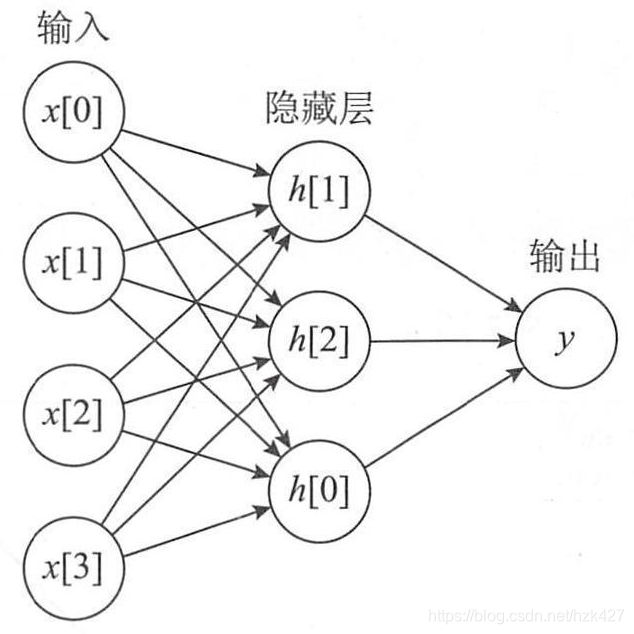
从上图可以看到,多层感知机层与层之间是全连接的。多层感知机最底层是输入层,中间是隐藏层,最后是输出层。
首先它与输入层是全连接的,假设输入层用向量X表示,则隐藏层的输出就是 f (W1X+b1),W1是权重(也叫连接系数),b1是偏置,函数f 可以是常用的sigmoid函数或者tanh函数。
其实隐藏层到输出层可以看成是一个多类别的逻辑回归,也即softmax回归,所以输出层的输出就是softmax(W2X1+b2),X1表示隐藏层的输出f(W1X+b1)。
MLP整个模型就是这样子的,上面说的这个三层的MLP用公式总结起来就是
![]()
MHA是Transformer模型中的一个关键结构,它允许网络在不同位置对输入序列的不同部分进行关注。
MHA包含多个注意力头(Attention Head),每个头都学习关注输入的不同方面。
每个注意力头通过查询(Q)、键(K)和值(V)矩阵的运算,捕捉输入序列中不同位置的关联信息。
MHA的并行性有助于有效地处理长序列,并使网络更具扩展性和泛化能力。
通过多头注意力,Transformer模型能够同时关注输入序列的不同部分,从而提高模型对复杂场景的理解和处理能力。
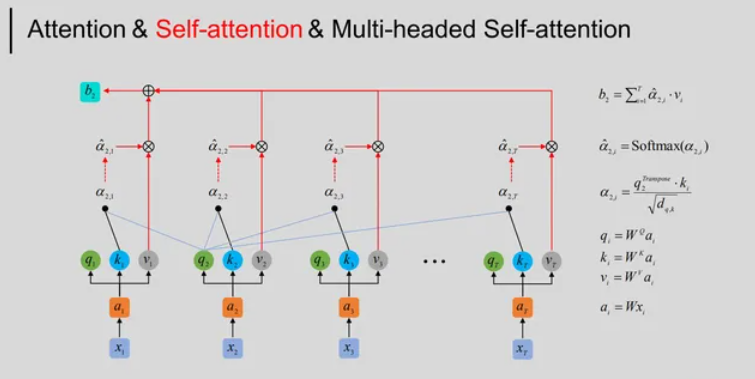
这些核心组件使得Transformer模型在处理序列数据时具有强大的建模能力和灵活性。然而,如何将这些组件高效地部署在存算一体芯片上,以充分利用其存储和计算特性,是一个值得探讨的问题。接下来,我们将探讨存算一体芯片如何高效支持Transformer模型的核心组件。
存算一体芯片,通过其独特的存储和计算集成架构,为高效支持Transformer模型提供了可能。这种芯片设计允许数据在存储单元内部进行处理,从而减少了数据在存储器和处理器之间的传输延迟,提高了计算效率。以下是存算一体芯片在支持Transformer模型方面的几个关键点:
通过这些优化,存算一体芯片能够有效地支持Transformer模型,特别是在处理长序列和复杂任务时,显示出其独特的优势。随着技术的不断进步,我们可以期待存算一体芯片在支持更复杂的深度学习模型方面取得更大的突破,为各种应用场景提供强大的计算支持。
全连接层(Fully Connected Layer)是神经网络中的一个重要组成部分,特别是在Transformer模型中,它通过矩阵乘法实现输入特征的变换。在存算一体芯片上,全连接层的优化主要体现在以下几个方面:
多头注意力(Multi-Head Attention, MHA)是Transformer模型中的核心组件,它通过并行处理多个注意力头来提高模型的并行性和全局信息的捕捉能力。在存算一体芯片上,多头注意力的优化主要涉及以下几个方面:
存算一体芯片能够高效执行多头注意力中的矩阵运算,包括查询(Q)、键(K)和值(V)矩阵的乘法操作。
由于存储单元的高计算密度,可以在存储单元内部直接完成这些矩阵运算,从而实现高效的并行处理。
Softmax函数在多头注意力中用于生成注意力权重,存算一体芯片可以通过并行计算来加速Softmax函数的执行。
通过优化存储单元的组织方式,可以实现对注意力权重的快速访问和更新,从而提高Softmax函数的效率。
存算一体芯片可以通过优化数据流来进一步提高多头注意力的执行效率。
例如,可以通过并行处理多个注意力头或同时处理多个矩阵运算来优化数据流。
为了提高多头注意力的执行效率,存算一体芯片通常配备高效的存算单元数据加载硬件。
这种硬件可以快速而高效地加载动态生成的矩阵(如Q、K、V矩阵)到存储单元中,从而减少数据搬移的延迟和能耗。
存算一体芯片通常具有多层次的内存结构,可以通过有效的内存层次管理来优化多头注意力的执行。
例如,可以通过将权重存储在较快的存储层次(如SRAM)中来减少访问延迟,同时将数据存储在较慢的存储层次(如DRAM)中以降低成本。
通过这些优化,存算一体芯片能够高效地执行多头注意力,从而在Transformer模型中发挥重要作用。这种优化不仅提高了模型的运行效率,还降低了能耗,为深度学习应用提供了强大的支持。
存算一体芯片通过其先进的设计理念和高效的存算一体架构,可以成功解决对Transformer算法的高效支持问题。随着技术的不断进步和硬件与算法的深入融合,我们可以期待存算一体芯片在支持更复杂的深度学习模型方面取得更大的突破,为各种应用场景提供强大的计算支持。
未来,存算一体芯片将继续发展,通过不断的迭代和创新,满足万物智能时代对算力的澎湃需求,推动人工智能技术的发展。



