


4,676
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享2018年6月,OpenAI 发表了GPT-1,以预训练生成式变换器为名的GPT家族首次登上历史舞台。在当时,OpenAI还笼罩在Google的光环之下,并不是很知名。
在GPT-1这项工作之前,绝大多数最先进的 NLP 模型都是使用监督学习,专门针对特定垂直领域任务(如情感分类等)进行训练。但已有的监督模型有两个主要限制:一方面需要大量带有标注的训练数据来学习不容易获得的特定任务,另一方面无法将现有模型泛化到训练数据集以外的任务。
也就是说,如果在真实生活场景使用有监督模型,训练数据集的构建任务将异常庞大和琐碎,数据集的标注成本会异常的高。为了解决这些问题,OpenAI提出了GPT-1。
GPT-1的核心是Transformer,通过两个途径针对性的解决上述的两个问题:
1. 通过无监督训练,解决需要大量高质量标注数据的问题,降低数据成本。
2. 通过大量不同类型混杂语料进行预训练,解决训练任务的泛化问题。
在GPT-1诞生的时代,AR(Autoregressive,自回归)与AE(Autoencoding,自编码)是无监督学习中的两大路径。AR类语言模型基于大量语料统计,基于单向或双向上下文进行文本生成,对数据的前后相对关系敏感,适合文本生成类任务。AE则通过被掩盖的输入重建原始数据(例如BERT),弥补了单向或双向信息的损失,但却由于信息的掩盖可能导致训练与实际推理的偏差。换句话说,BERT这类基于编码器的模型训练难度可能是高于同尺寸GPT类的。
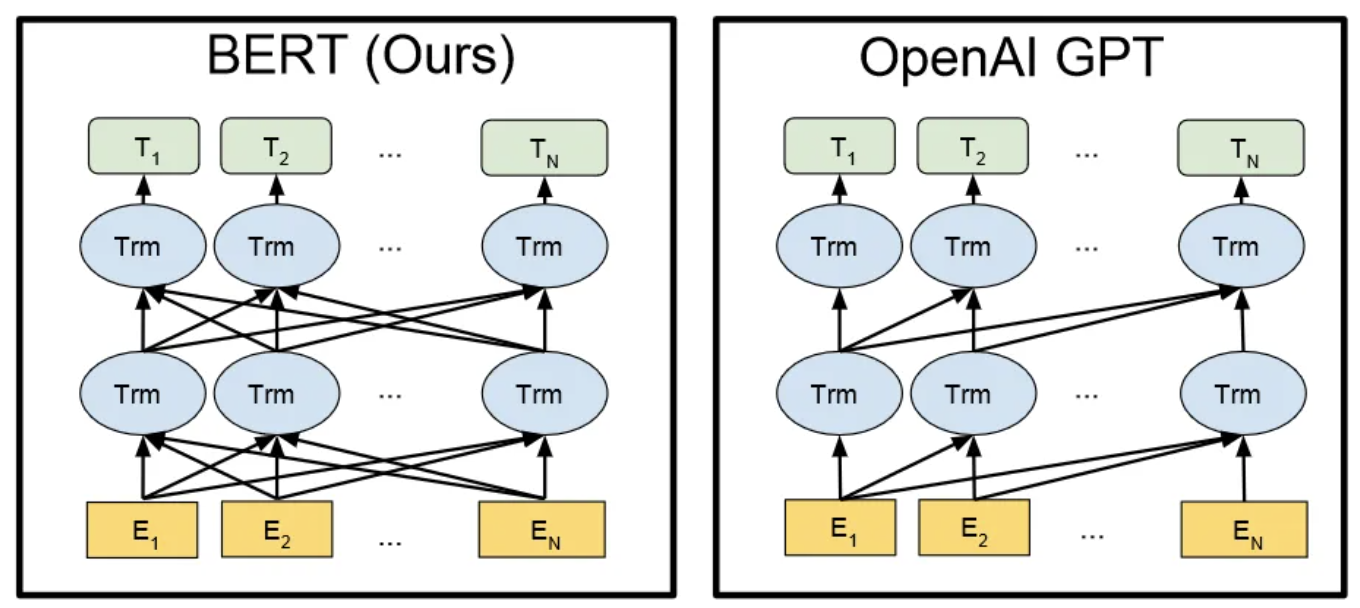
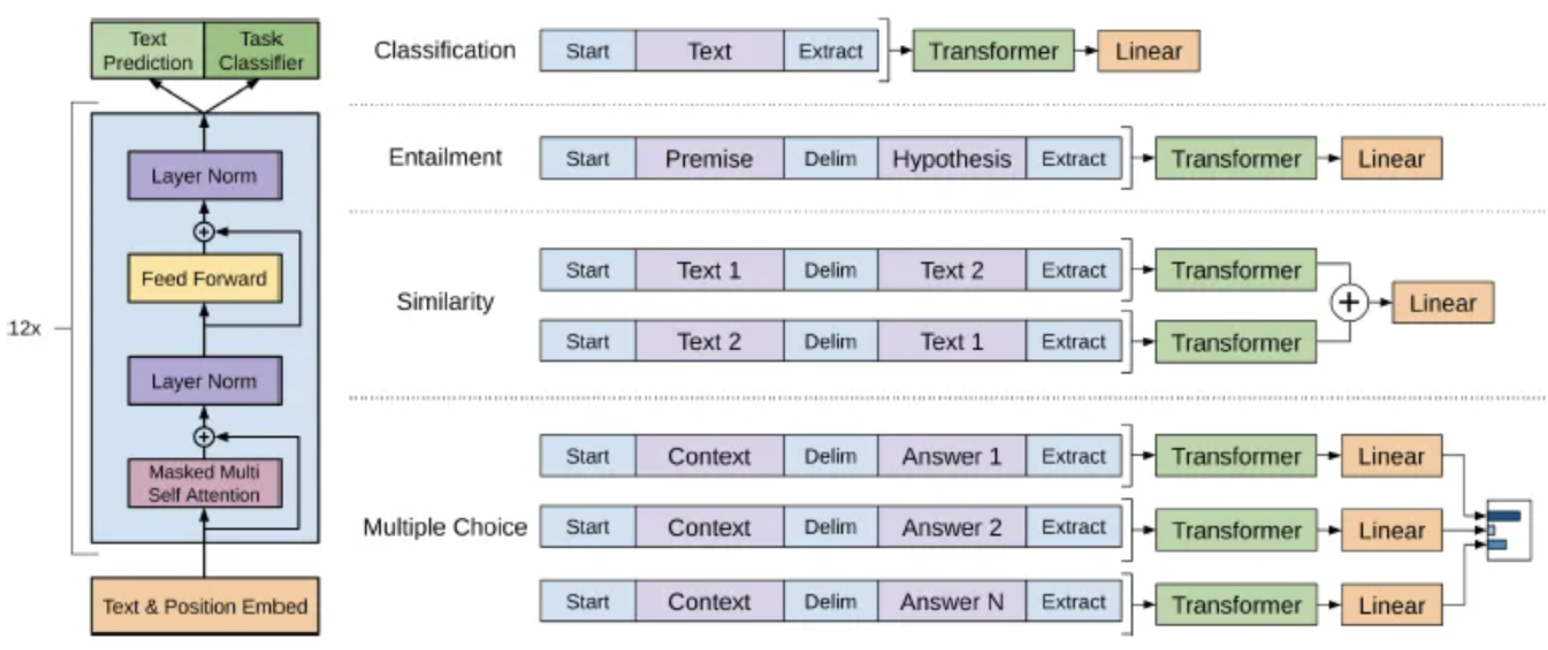
GPT-1 是一个典型的自回归语言模型,只具有解码器模块。GPT-1模型使用 768大小词嵌入。使用 12 层模型,每个自注意力层有 12 个注意力头,并使用GELU 作为激活函数。
GPT-1模型训练使用了BooksCorpus数据集。训练主要包含两个阶段:第一个阶段,先利用大量无标注的语料(节约标注成本)预训练一个语言模型。在BooksCorpus 数据集上训练后,GPT-1能够学习到大范围的文本/词汇的隐含关系,并在包含连续文本和长文的多样化语料库中获取大量知识。
接着,在第二个阶段对预训练好的语言模型进行精调,将其迁移到各种有监督的NLP任务。也就是后文提到的“预训练+精调”模式。OpenAI团队也在GPT-1的研究中评估了模型层数对无监督预训练和有监督精调的影响。
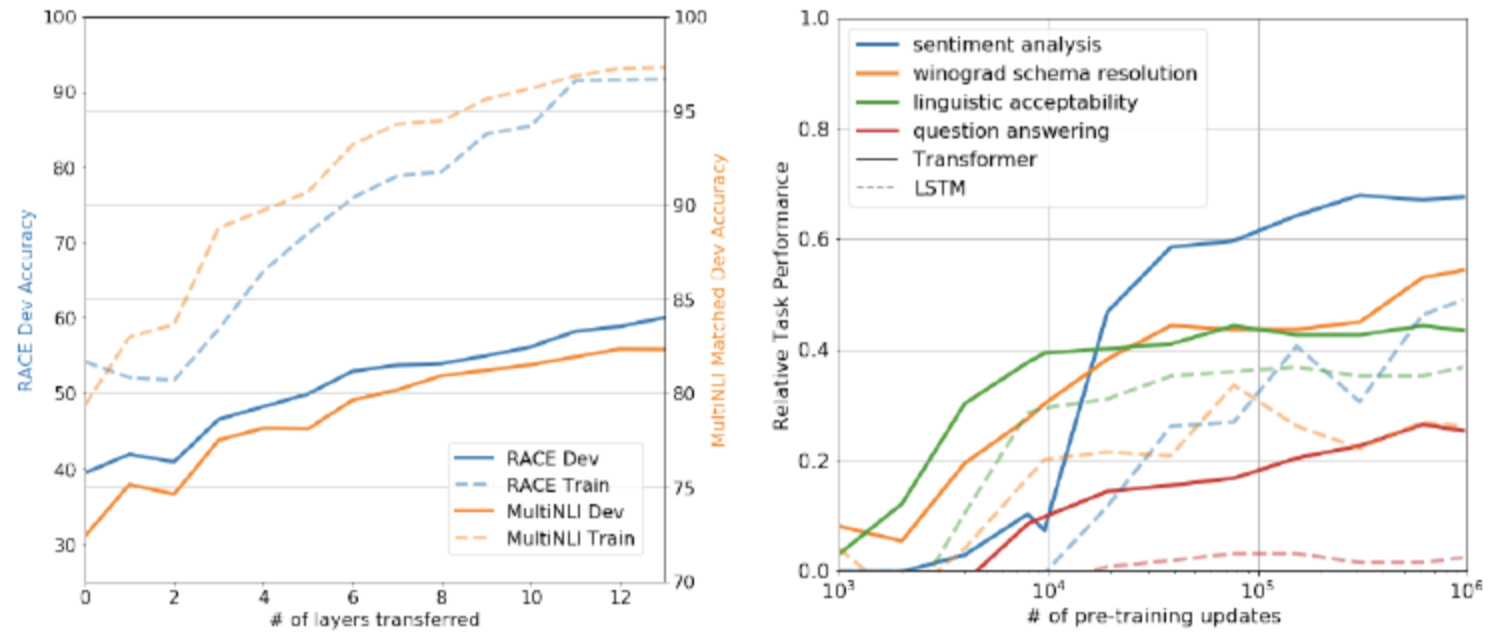
实验表明转移嵌入(transferring embeddings)明显改进了模型性能,每个Transformer层在MultiNLI数据集上获得的提升可高达9%。
2019年,OpenAI 发表了另一篇关于他们最新模型 GPT-2 的论文( Language Models are Unsupervised Multitask Learners )。该模型开源并在很多NLP任务中使用。相对GPT-1,GPT-2是泛化能力更强的词向量模型,尽管并没有过多的结构创新,但是训练数据集(WebText,来自于Reddit上高赞的文章)和模型参数量更大。目前很多开源的GPT类模型是基于GPT-2进行的结构修改或优化。
GPT-2 有 15 亿个(1.5B)参数。是 GPT-1(117M 参数)的 10 倍以上。GPT-2与 GPT-1 的主要区别包括:
1. GPT-2 有 48 层,使用 1600 维向量进行词嵌入,使用了 50,257 维标记的更大词汇量。
2. GPT-2的层归一化被移动到每个子块的输入,并在最终的自注意力块之后添加了一个额外的层进行归一化。
3. GPT-2在初始化时,残差层的权重按 1/√N 缩放,其中 N 是残差层的数量。
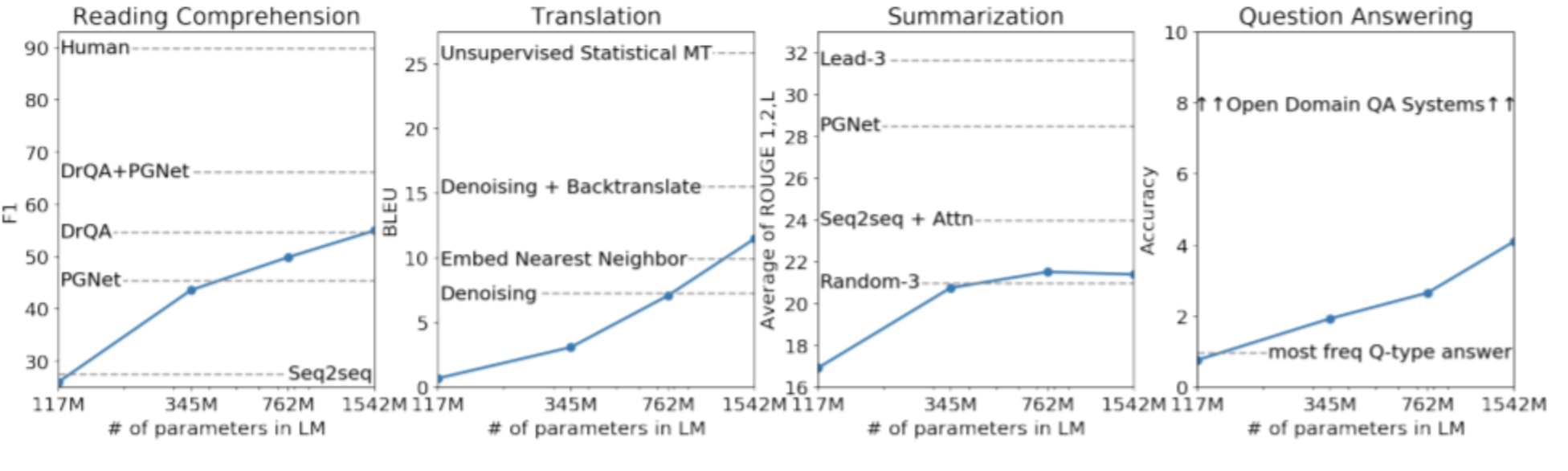
GPT-2的研发团队训练了 117M(与 GPT-1 相同)、345M、762M 和 1.5B参数的四种语言模型,并比较了不同大小的模型精度。在同一数据集上,模型的性能随着参数数量的增加而提升。这一现象事实上导致了后来的语言模型的尺寸的迅速增加。
GPT 2 的一个关键能力是零样本学习(Zero-shot Learning)。Zero-shot是零样本任务迁移的一种特殊情况,即在没有提供示例情况下,模型根据给定的指令理解特定任务。
GPT-2使用的 WebText 的数据集包含来自超过 800 万份文档的 40GB 文本数据。比 GPT-1 模型的 BookCorpus 数据集更加庞大。
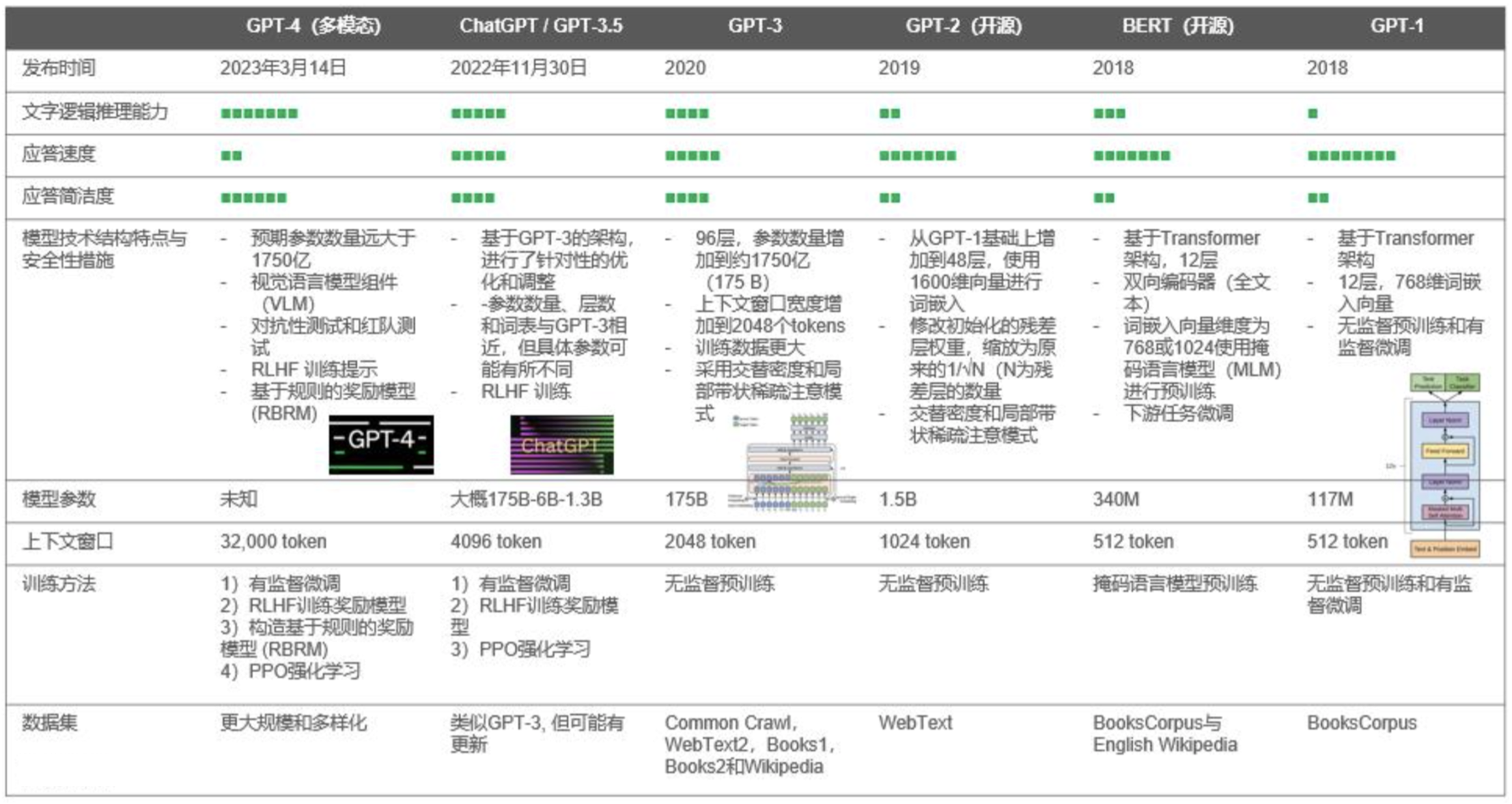
OpenAI使用 RLHF(Reinforcement Learning from Human Feedbac,人类反馈强化学习) 技术对 ChatGPT 进行了训练,且加入了更多人工监督进行微调。
ChatGPT 具有以下特征:
1. 可以主动承认自身错误。若用户指出其错误,模型会听取意见并优化答案。
2. ChatGPT 可以质疑不正确的问题。例如被询问 “哥伦布 2015 年来到美国的情景” 的问题时,机器人会说明哥伦布不属于这一时代并调整输出结果。
3. ChatGPT 可以承认自身的无知,承认对专业技术的不了解。
4. 支持连续多轮对话。
存算一体介质与计算范式尤为重要。同时,器件—芯片—算法—应用跨层协同对存算一体芯片的产业化应用与生态构建非常关键。概述了端侧智能存算一体芯片的需求 、现状 、主流方向 、应用前景与挑战等。

支持存内计算开发者社区的建设!


