




4,333
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享
闪易半导体是一家研发高性能、低功耗、低成本的存算一体化AI芯片的集成电路公司,团队成员分别毕业于清华大学和北京大学,分别在中美两国的电路设计生产、人工智能开发企业担任研发负责人。公司计划在三年内完成第一代语音产品在家电和物联网领域的推广和量产,同时设计和开发好第二代产品,用于图像识别及安防领域。
闪亿所使用的新型存储器PLRAM具有高精度(8-10比特),高线性度,高能效的特点,是第一种可以大规模量产的精度超过8bit的忆阻器,可以赋能存算一体化计算架构。基于新型忆阻器技术,可实现深度神经网络的模拟计算,在未来物联网生态的端侧和边缘侧中将发挥出重要作用。
闪锌石HEXA01作为首款集成PLRAM忆阻器阵列的芯片产品,其算力功耗比可达到10TOPS/W,而成本却比传统AI芯片下降一半以上,在智能家电、智能音箱、安放监控以及便携式可穿戴设备中发挥语音和图像识别的应用,还可用于工业IoT、医疗监护、通讯基带和自动驾驶中的专用信号处理。
Mythic是专注于研发深度学习的神经网络芯片的公司,该公司推出的新型的芯片和软件,无需通过云端就能在本地设备中实现语音控制、计算机视觉和其他的AI技术;这款芯片大小相当于衬衫纽扣,通过相匹配的软件,使之能与其他处理器和内存一起工作。Mythic 模拟矩阵处理器 (Mythic AMP™) 在功率、性能和成本方面具有巨大优势。它们降低了创新的障碍,使创建强大的边缘人工智能解决方案变得更加容易和更具成本效益。
Mythic AMP 通过在密集闪存阵列内执行推理深度神经网络所需的计算来利用模拟计算。这代表了相对于典型数字架构的显着优势。借助 Mythic 的集成开发环境,人工智能开发人员甚至可以快速部署最复杂的深度神经网络,并确信它们将有效执行——从数据中心到边缘设备。
M1076 Mythic AMP™:
M1076 Mythic AMP™ 在单芯片中提供高达 25 TOPS,适用于高端边缘 AI 应用。M1076 集成了 76 个 AMP 块,可存储多达 80M 的权重参数并执行矩阵乘法运算,无需任何外部存储器。这使得 M1076 能够提供桌面 GPU 的 AI 计算性能,同时消耗高达 1/10 的功率 - 所有这些都在一个芯片中。支持 INT4、INT8 和 INT16 操作,4 通道 PCIe 2.1 接口,带宽高达 2GB/s,用于推理处理,运行复杂机型典型功耗3~4W。
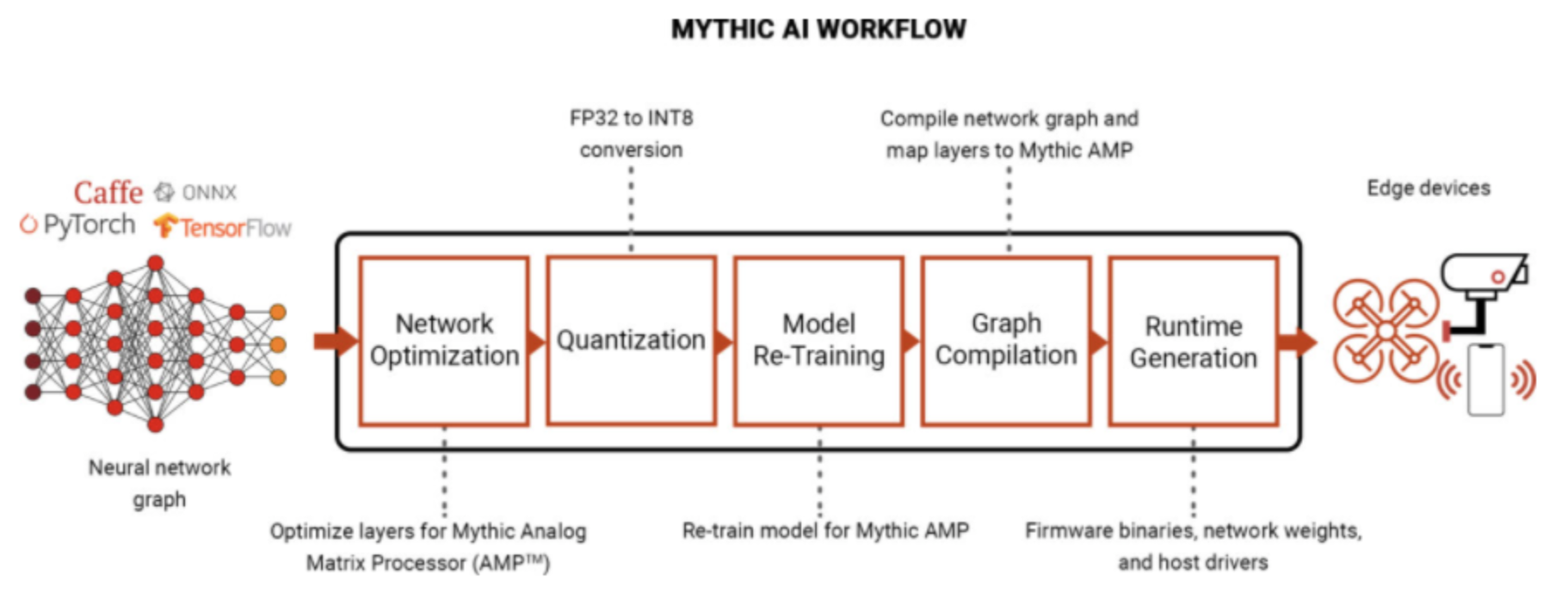
使用 Mythic 的 AI 软件工作流程在 Mythic 模拟矩阵处理器 (Mythic AMP TM )上实施和部署在 Pytorch、Caffe 和 TensorFlow 等标准框架中开发的 DNN 模型。模型经过优化,从 FP32 量化到 INT8,然后针对 Mythic 模拟计算引擎 (Mythic ACE TM ) 进行再训练,然后通过 Mythic 强大的图形编译器进行处理。然后将生成的二进制文件和模型权重编程到 Mythic AMP 中进行推理。开发人员还可以使用经过预审的模型来快速评估 Mythic AMP 解决方案。
Silicon Storage Technology, Inc. (SST) 是 SuperFlash® 技术的创造者,该技术是一种创新、高度可靠和通用的 NOR 闪存。SST 是 Microchip Technology Inc. 的全资子公司,专注于将嵌入式非易失性存储器 (NVM) 技术授权给代工厂、集成设备制造商 (IDM) 和无晶圆半导体公司,用于汽车、安全智能卡、物联网 (IoT)、人工智能 (AI)、工业和消费市场。
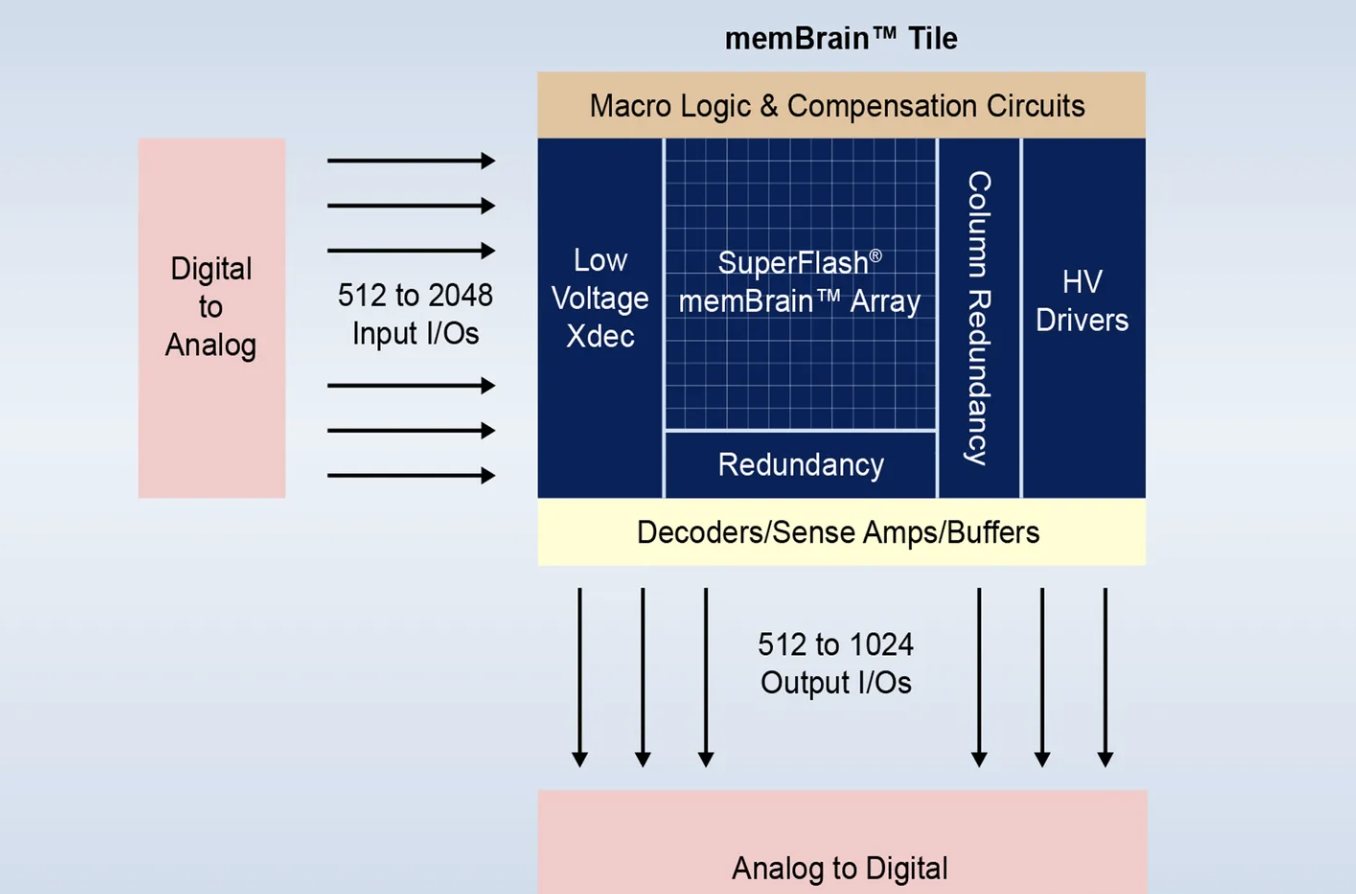
memBrain™ 神经形态内存产品基于 SuperFlash ®技术以计算用于神经网络推理的向量矩阵乘法 (VMM),通过模拟内存计算方法改进了 VMM 的系统架构实现,增强了边缘的 AI 推理。memBrain 神经形态产品将突触权重存储在浮栅存储器内,以显着改善系统延迟。
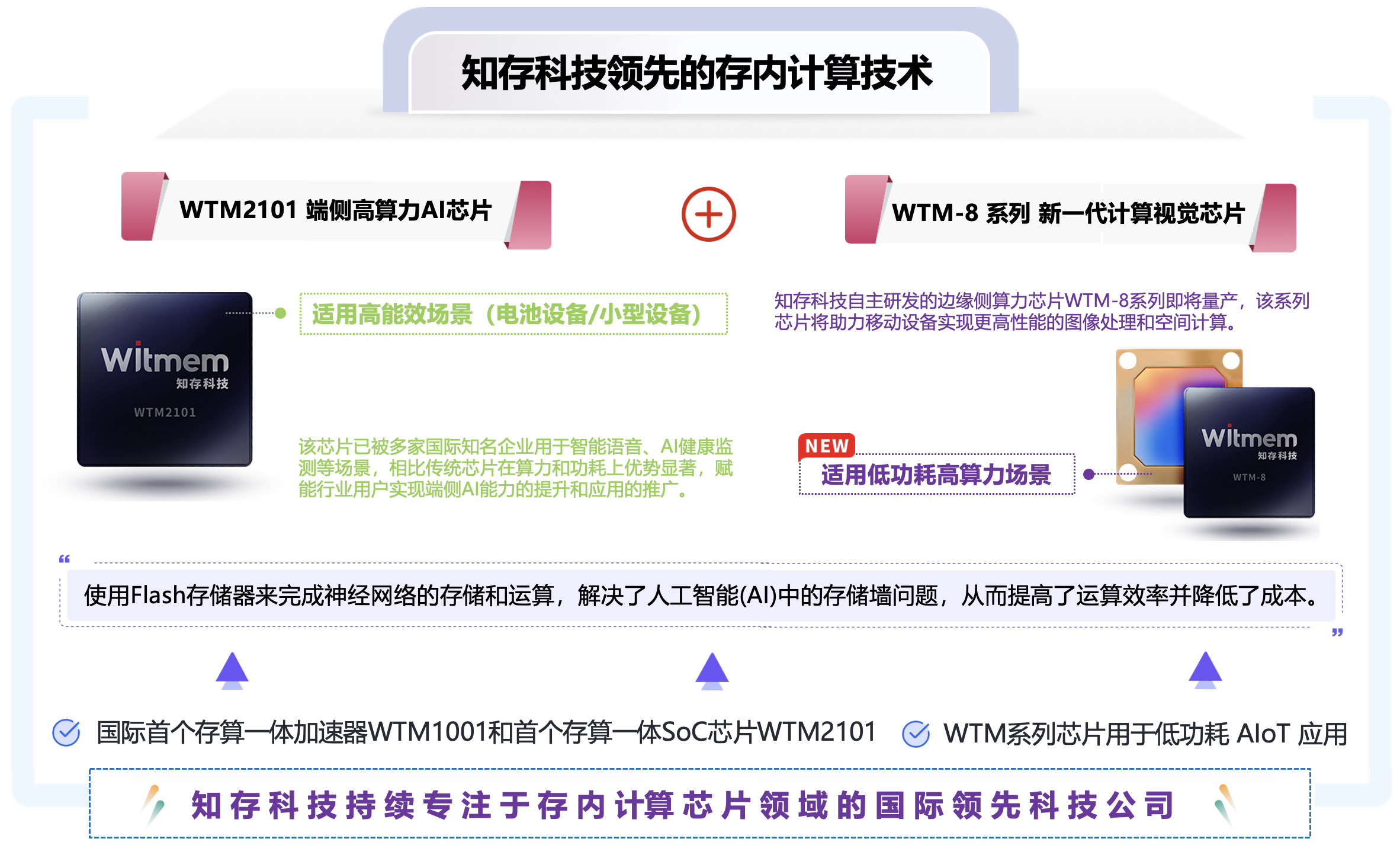
知存科技创立于2017年10月23日,拥有业内领先的存算一体技术。知存拥有多种适合存内计算的非易失性存储器工艺研发经验,构建了WTIN Mapper编译器、工具链、存内计算电路设计、多核运算等完善的存算一体开发生态。知存的存算一体技术创新使用Flash存储器完成神经网络的储存和运算,解决AI的存储墙问题,提高运算效率,降低成本。WTM系列芯片用于低功耗AIoT应用,如可穿戴设备和智能终端设备。
北京知存科技有限公司(简称“知存科技”)是一家专注于存内计算芯片领域的国际领先科技公司,知存科技的核心技术和产品创新性地使用了Flash存储器来完成神经网络的存储和运算,这一技术解决了人工智能(AI)中的存储墙问题,从而提高了运算效率并降低了成本。
知存科技已经推出了多个产品,其中包括:国际首个存算一体加速器 WTM1001、首个存算一体SoC芯片 WTM2101,这些芯片特别适用于低功耗的人工智能物联网(AIoT)应用,如可穿戴设备中的智能语音和智能健康服务。WTM2101芯片能够在微瓦到毫瓦级的功耗下完成大规模深度学习运算,这使得它非常适合用于可穿戴设备中的这类应用。此外,WTM2101已经在2022年完成了批量生产和市场推广。
北京知存科技有限公司不仅在技术上处于行业领先地位,而且还计划在未来推出针对超高清视频处理和其它大算力需求的应用处理器,以进一步扩展其产品的应用领域,并推动存内计算的产业化进程,公司的愿景是成为“存算一体芯片技术的国际领航者”,致力于成为一个具有广泛影响力的国际知名品牌。
每刻深思成立于2020年4月,总部位于北京海淀区,是一家旨在解决小型化、电池供电设备功耗和续航问题的芯片公司,主要致力于利用传统CMOS技术开发高能效、低能耗的智能感知芯片和模组,并提供完整的感知系统解决方案。公司的核心团队即来自于清华大学电子系,且由国际顶尖科研团队搭配“行业老兵”构成,均具有十余年芯片设计及研发经验,硕博士比例达80%。团队在高能效混合电路计算领域发表数十篇高水平文章,申请多项技术专利,在模拟信号计算领域具有深厚技术积累。



