



4,333
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享发射是指令就绪后,从指令缓冲进入到执行单元的过程。在(译码后的)指令发射阶段,指令循环仲裁选择一个Warp,将I-Buffer中的发射到流水线的后级,且每个周期可从同一Warp发射多条指令。
所发射的有效指令应符合以下条件:
1. 在Warp里未被设置为屏障等待状态;
2. 在I-Buffer中已被设置为有效指令(有效位被置为1);
3. 已通过计分板(Scoreboard)检查;
4. 指令流水线的操作数访问阶段处于有效状态。
5. 在GPU中,不同的线程束的不同指令,经由SIMT堆栈和线程束调度,选择合适的就绪的指令发射。
在发射阶段,存储相关指令(Load、Store等)被发送至存储流水线进行相关存储操作。其他指令被发送至后级SP(流处理器)进行相关计算。
SIMT堆栈用于在Warp前处理SIMT架构的分支分化的执行。一般采用后支配堆栈重收敛机制来减少分支分化对计算效率的负面影响。
SIMT 堆栈的条目代表不同的分化级别,每个条目存储新分支的目标 PC、后继的直接主要再收敛 PC 和分布到该分支的线程的活动掩码。在每个新的分化分支,一个新条目被推到栈顶;而当 Warp 到达其再收敛点时,栈顶条目则被弹出。每个 Warp 的 SIMT 堆栈在该 Warp 的每个指令发出后更新。
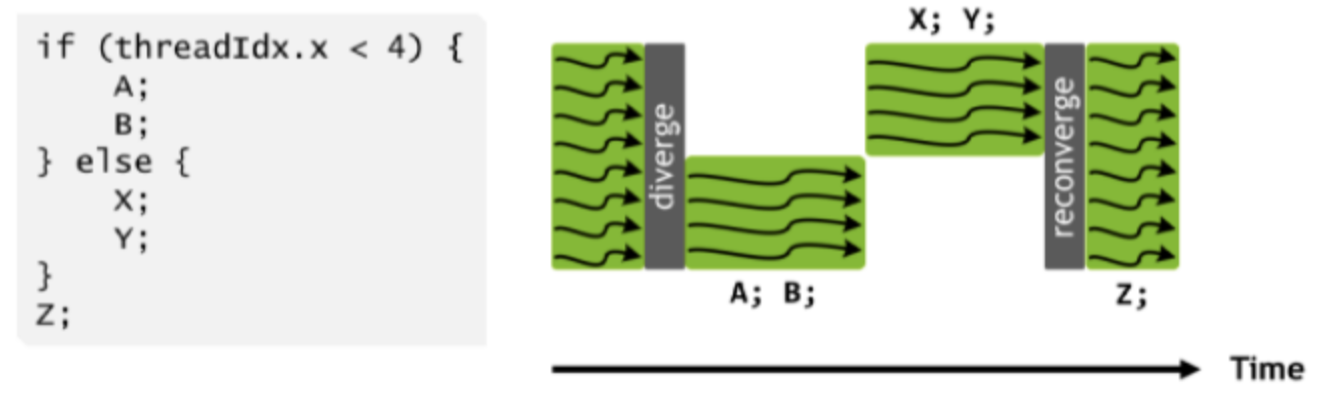
SIMT堆栈模块可有效改善线程束分化引起的GPGPU执行单元利用率下降的问题。控制流嵌套问题(Nested Control Flow)在控制流嵌套中,一个分支严重地依赖另一个分支,这极大影响了线程的独立性。如何跳过计算过程(Skip Computation)由于线程束分支的存在,导致同一个Warp内的有些线程并不必要执行某些计算指令。
SIMT堆栈中使用了SIMT掩码(SIMT Mask)来处理线程束分化问题,以下例来说明掩码如何控制整个Warp的执行。
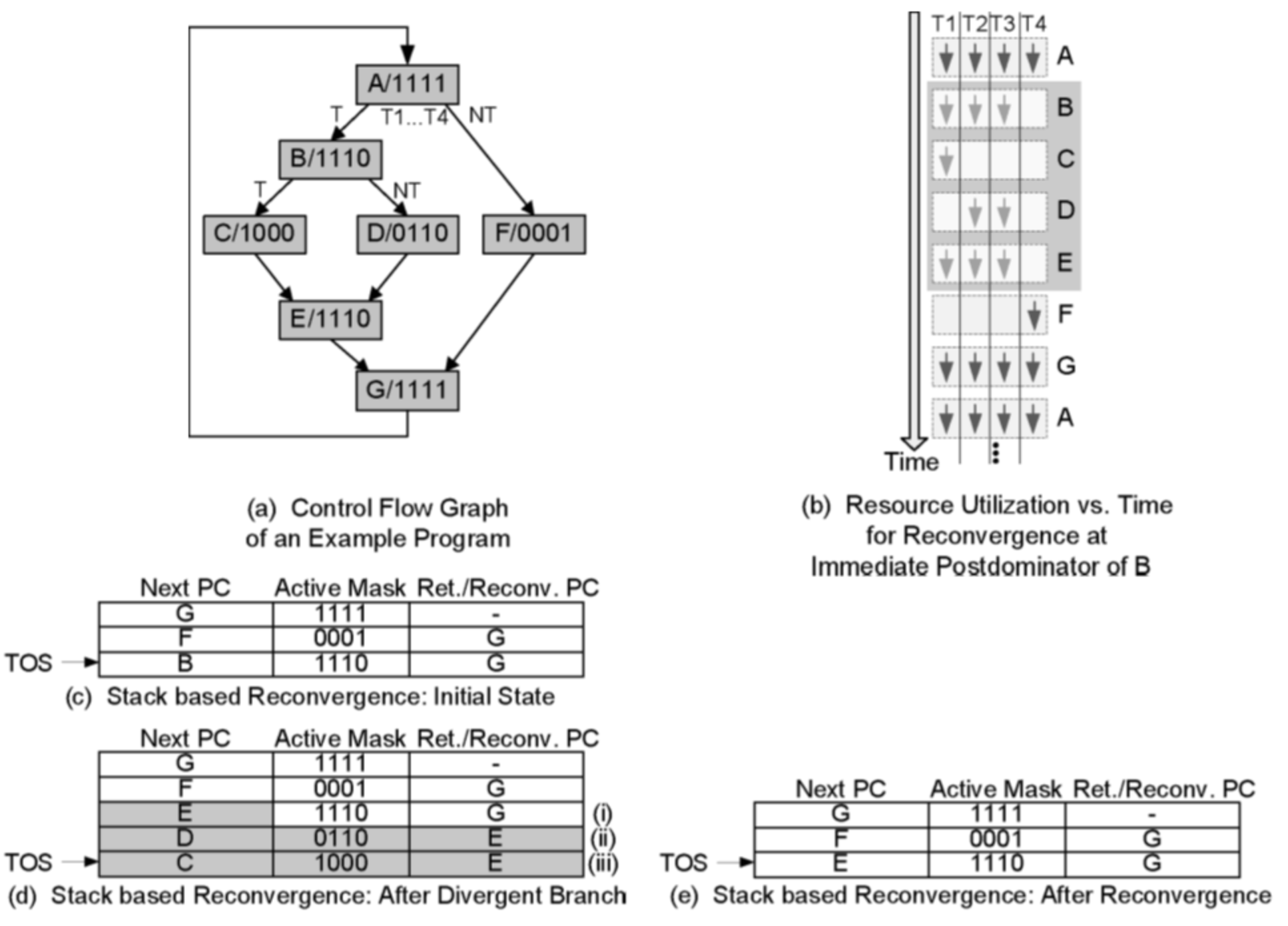
如上的 GPU端Kernel代码有多个分支,且在while循环中对应两个if else分支。其中A指令为一个Warp内所有线程都可以执行到,而B、C、D、F分别对应的四个分支各自处理指令,E和G处为指令位置(称之为Reconvergence Point位置),该位置为分支处理完毕之后,线程又重新聚合在一起进行执行,该点是分支处理的关键点。如上述代码在同一个Warp内执行,则该Warp需要处理4种分支情况,即多个线程分别执行不同的指令,出现线程束分化的情况,可能导致后继SIMD计算效率降低
为解决上述线程分化的问题,SIMT Stack模块使用掩码(Mask)来进行标记。
1. 掩码置为1表示该线程需要执行,置0表示该线程不需要执行,每一个bit位代表了一个线程。
2. 假设一个GPU Warp大小为4,即同时支持4个线程并行运行,当上述内核代码运行到A处时,所有的线程都运行,则标记为“A/1111”,其中Mask bit位从低位到高位分别表示四个线程从第一个到第四个线程。
3. 当代码运行到if(t3 != t4) 时出现分支造成线程分化,其中第四个线程运行F分支,第一到三个线程运行B分支,则可分别表示“F/0001”和“B/1110”。
4. 处于B线程继续执行又遇到if( t5 != t4 )分支,其中第一个线程执行C,第二和三个线程执行D,mask可分别表示位“C/1000”和“D/0110”。
5. 当C和D执行完毕之后到E,线程又重新聚合,即“E/1110”。
而在G处又出现了线程聚合,即“G/1111”。
6. 整个上述内核执行控制流图(Control Flow Graph,CFG),实心箭头代表线程执行,空箭头代表线程不执行被屏蔽掉,从上到下依次表示从第一个到第四个线程。
当出现分支时按照减少重合堆栈(Reconvergence stack)的深度的方法,先执行活跃线程最多的分支,然后再执行活跃少的分支。
进行线程束(Warp)调度的目的是充分利用内存等待时间,选择合适的线程束来发射,提升执行单元计算效率。在理想的计算情况下,GPU内每个Warp内的线程访问内存延迟都相等,那么可以通过在Warp内不断切换线程来隐藏内存访问的延迟。
GPU将不同类型的指令分配给不同的单元执行,LD/ST硬件单元用于读取内存,而执行计算指令可能使用INT32或者FP32硬件单元,且不同硬件单元的执行周期数一般不同。这样,在同一个Warp内,执行的内存读取指令可以采用异步执行的方式,即在读取内存等待期间,下一刻切换线程其他指令做并行执行,使得GPU可以一边进行读取内存指令,一边执行计算指令动作,通过循环调用(Round Robin)隐藏内存延迟问题,提升计算效率。
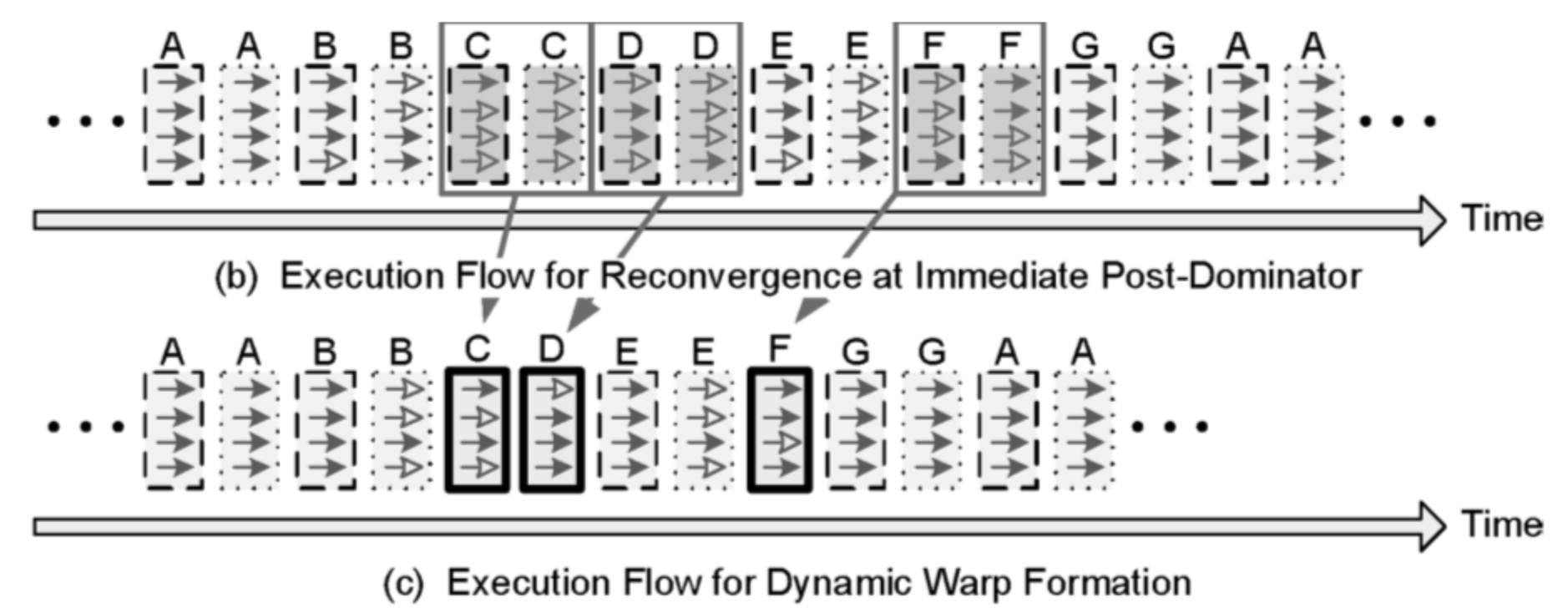
在理想状态下,可以通过这种循环调用方式完全隐藏掉内存延迟。但在实际计算流程中,内存延迟还取决于内核访问的内存位置,以及每个线程对内存的访问数量。内存延迟问题影响着Warp调度,需要通过合理的Warp调度来隐藏掉内存延迟问题。



