


4,693
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享机器学习是通过人工智能 (AI) 分析复杂的数据并自动预测未来行为的过程。通过有监督的学习并使用标签对数据进行分类,并通过无监督的学习识别数据集中的模式,机器学习让机器能够帮助我们更快速更准确地作出决策。

强化学习方法是模仿人类和动物通过试验和错误进行学习的过程,让机器和设备无需显式编程即可独立扩展自己的能力。总而言之,这些过程构成了所有 AI 支持特性和功能的基础。
得益于深度学习的强大能力,机器可以以惊人的准确率分析和识别图像等输入数据。这是可以按照类似于人类大脑的方式处理和学习数据的关联算法层,即通过由神经元组成的ANN(Artificial Neural Network,人工神经网络)实现。
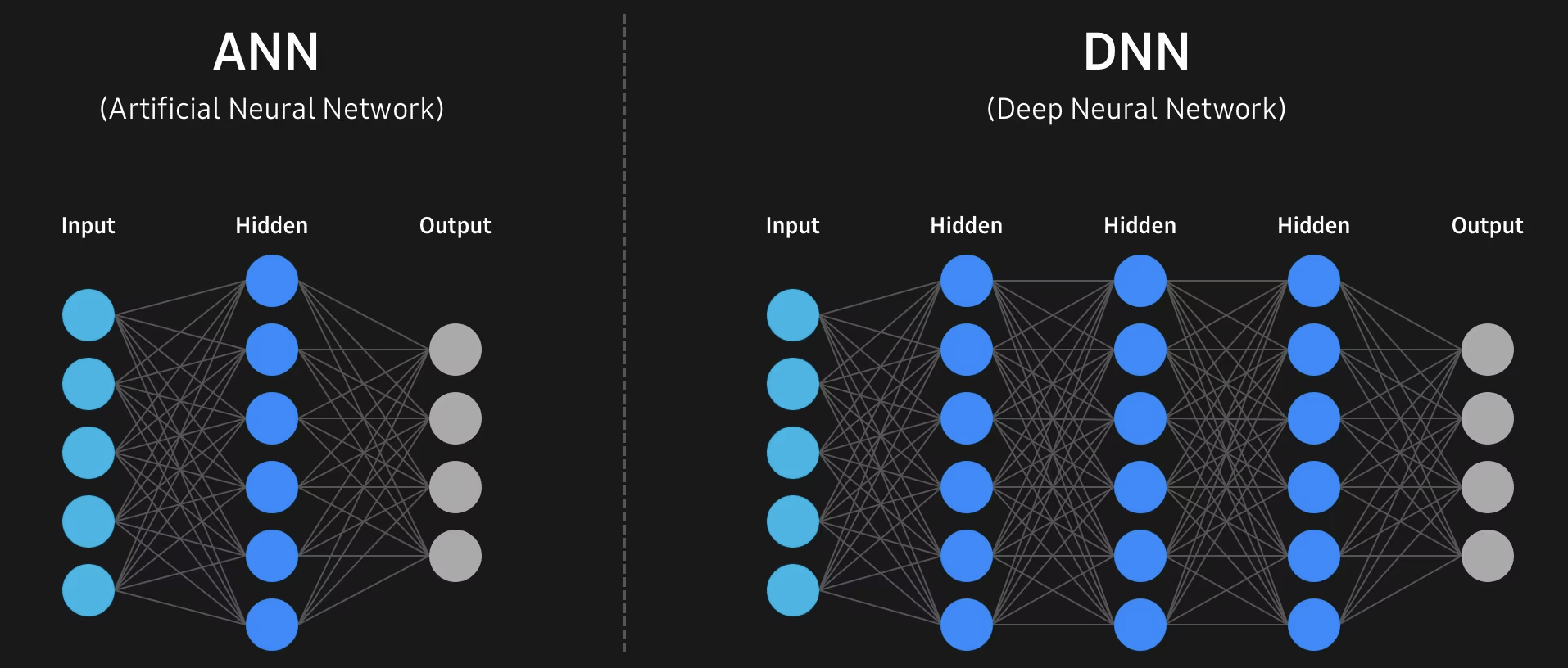
DNN(Deep Neural Network,深度神经网络)是在输入层和输出层之间包含多个层的人工神经网络,在输入层和输出层之间通过像人脑一样错综复杂连接的多层神经元进行操作。CNN(Convolution Neural Network,卷积神经网络)通常用于识别处理图像、语音和自然语言的数据模式。
人工智能中很神奇的一个应用场景就是处理庞大而复杂的大数据,这是原有技术无法实现的。 这种数据分析方式可以在人们做决策时提供必要的关键见解,因此多个行业都在加速引进人工智能。
机器学习算法可基于突破性的速度快速筛选和分析信息,运用该技术的公司则可以更轻松地发现数据中隐藏的见解并加以应用。
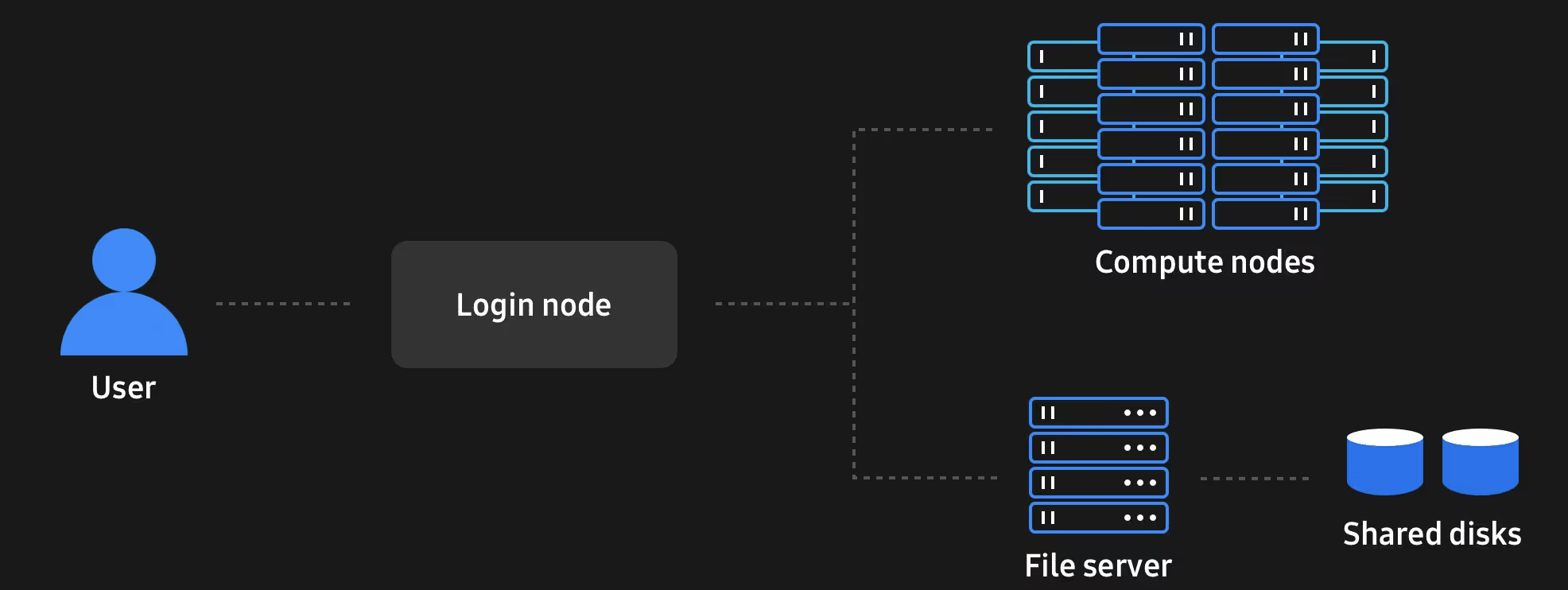
为了进一步推进人工智能的发展,必须开发与其水平相当的计算基础设施,即HPC(high-performance computing,高性能计算)。 HPC广泛应用于使用大量数据的多种场景,包括高性能数据分析和机器学习模型的训练。 HPC通过计算服务器实现并行计算,每个服务器都成为一个“节点”,从而确保先进的大型应用程序快速可靠地运行。 在推进人工智能发展以处理呈指数增长的数据方面,这种性能和效率至关重要。

在更快、更高效地提供人工智能服务方面,端侧 (On-device) AI的发展发挥着关键作用。 人工智能算法以及硬件和软件的快速发展,让人工智能服务成功从云端转移到设备内部。 凭借于此,移动设备、家用电器和汽车等机器上运行的人工智能服务在稳定性、隐私性和性能等方面获益颇多。 端侧AI降低了网络依赖性,速度比云端更快,并且可以安全运用生物识别等类别的敏感数据。
设备端 AI 不仅可显著提高处理速度,实现更高的可靠性和更严格的数据安全性,还将彻底改变我们使用移动设备的方式。例如,AI 相机可利用更好的图像处理技术来优化照片,并通过提供更准确的面部识别来增强生物识别的安全性。通过在移动设备本地进行 AI 处理,可带来更好的沉浸式和交互式虚拟和增强现实体验。它还将自然语言处理和语音识别等重要功能从云端转移出来,让虚拟助手变得更加智能和实用。
即将大量普及的 AI 服务和技术将为高性能计算 (HPC) 开拓新的动态应用。依托由高性能计算支持的超快 IT 基础架构,让直播流式传输服务等需要实时处理大量数据的应用能够提供逼真的高清内容。高性能计算集群也将受益于更高的能效,促进计算服务器和存储之间的快速数据传输。
此外,由于集群架构能够更加高效地管理资源,降低了企业的 TCO(总体拥有成本),高性能计算的相关支持成本也将会降低。

AI 不仅为自动驾驶汽车的发展创造了条件,还也是让通勤更加安全高效的关键。互联汽车使用几十甚至数百个传感器,用于:
1. 检测驾驶员尚未看到的潜在危险,并控制方向盘以避免事故;
2. 监控关键部件以帮助预防故障;以及其他功能。
3. 监控驾驶员的视线和头部位置,以检测他们可能出现分心或犯困的情况,以及实现众多探讨如何推动创新!
人工智能、数据中心、超连接、元宇宙……在数字化转型时代,这些主要平台正在不断重塑我们的生活。正如以前的电脑和智能手机一样。 纵观这些新型平台的发展,我们不难发现,它们与半导体技术始终呈现齐头并进的局面。 一方的成长带动了另一方的变化,并激发了新的发展动力,从而产生了对下一次创新的需求。
以多种领先的半导体产品和技术为依托,三星为更高端人工智能在多种场景中的顺利应用奠定了稳固的基础。生成式AI现已成为全世界的焦点,若要打造与之相当的巨型AI,高速处理海量数据的能力是必不可少的。但现有的计算结构面临诸多限制,在这种情况下,急需新型内存技术的保驾护航。
HBM-PIM (Processing-In-Memory) 通过让超高速内存HBM (High Bandwidth Memory) 本身承担部分计算功能,将以CPU为中心的集中式计算处理过程转变为分散式。 在传统架构中,计算的工作仅由CPU负责;但在改变后的架构中,内存也会承担部分计算功能,从而可以显著提高的数据整体处理能力,HBM-PIM也成为名副其实的新一代内存技术。
以用于生成式AI的语言模型为例,据估计,80%以上的计算功能都可以通过应用 PIM来加速。 计算应用HBM-PIM后得到的性能提升效果可以发现,与使用HBM和GPU加速器时相比,AI模型的性能提升了3.4倍甚至更多。
CXL-PNM (Processing-Near-Memory)和上文提到的HBM-PIM一样,是在存储器半导体上搭载运算功能的技术,通过在更靠近内存的地方执行运算功能,减少CPU 和内存之间的传输数据带来的瓶颈,并尽可能提升CPU的运算处理功能。

基于CXL的PNM解决方案采用易于添加内存容量的CXL接口,可提供的容量达到传统GPU加速器的四倍。 它适用于一次性处理满足各种客户需求的AI模型,也可用于巨型AI语言模型。 此外,与使用PCIe接口的加速器相比,AI模型的加载速度也快了2倍以上。
三星电子以开源方式对外发布了HBM-PIM和CXL-PNM解决方案,以及支持该解决方案的软件、运行方法、性能评估环境等内容,不断努力扩大AI内存生态系统。 Exynos处理器搭载了先进的嵌入式神经网络处理器 (NPU),可实现更强大、更高效的端侧AI。同时,LPDDR5等内存解决方案针对打造AI系统所需的高性能处理也进行了优化。


