



4,699
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享三星电子于 12 月 12 日宣布,他们开发了世界上第一个基于数字存内处理 (PIM,也可称存内计算或存算一体) 芯片(HBM-PIM)的GPU的大规模计算系统。
当下ChatGPT风靡全球,持续火爆。这种超大规模(Hyperscale)人工智能(AI)技术具有媲美人类的超强能力,可以回答问题、展开对话,甚至能够作曲和编程。在ChatGPT令人惊叹的超能力背后,支撑它的是大量的存储器密集型数据计算。
超大规模AI对计算的需求呈指数级增长,传统存储器解决方案逐渐力不从心。为解决此问题,三星电子在其高带宽存储器(HBM)中集成了一块AI专用半导体。
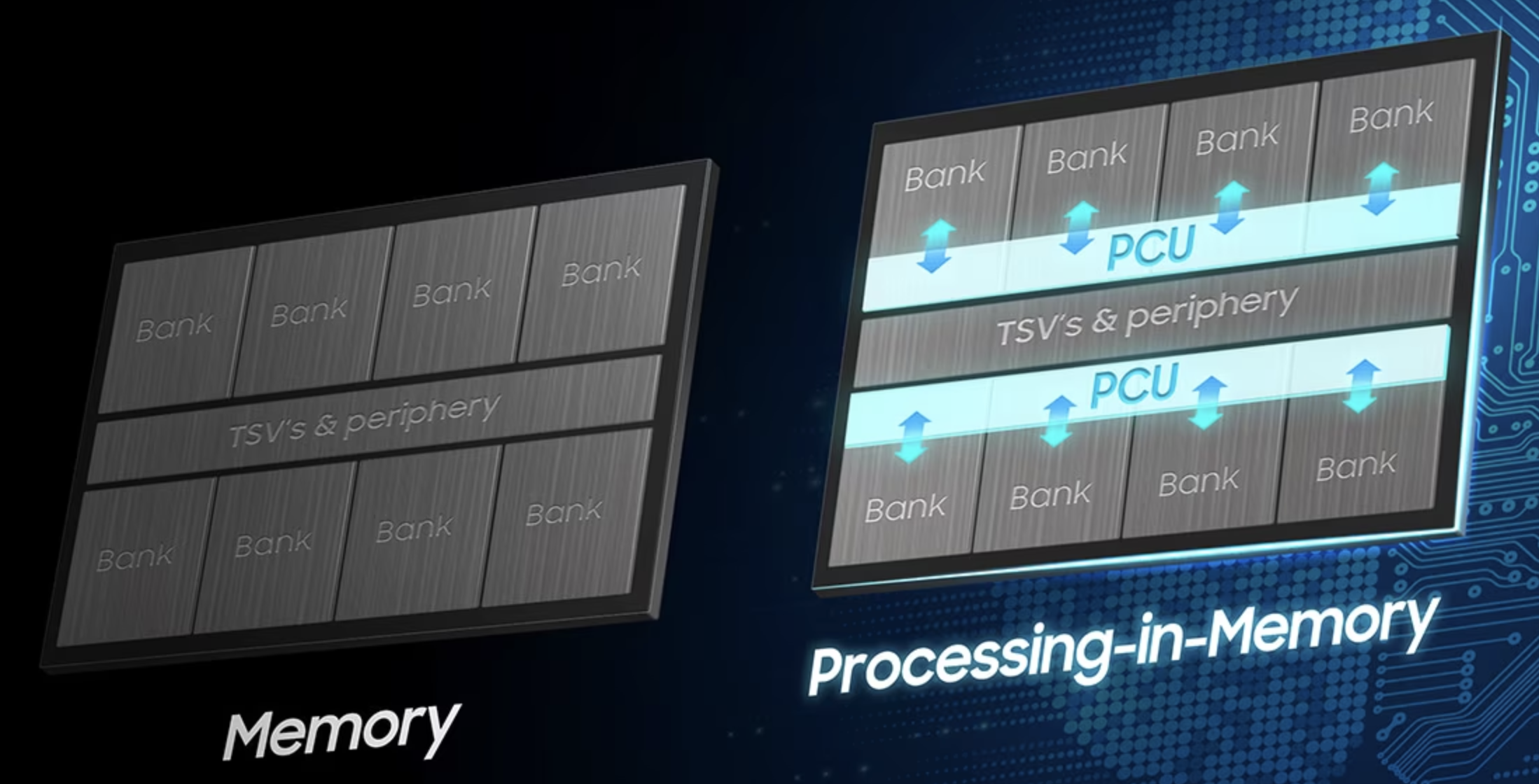
三星电子在业内率先将存算一体化 (PIM) 集成到高带宽内存 (HBM),以加快提升人工智能能力。PIM 能够通过在内存内核中集成一个称为可编程计算单元 (PCU) 的 AI 引擎来处理一些逻辑功能。 PIM 将在手机、数据中心和高性能计算 (HPC) 等需要持续性能提升的应用领域,刺激 AI 使用的增长。
三星电子高等技术研究院人工智能研究中心副主任崔昌圭(Choi Chang-kyu)在由三星电子主办的2022人工智能(AI)半导体未来技术大会上通过主题演讲披露了新计算技术的发展。他们通过组合来自AMD的96个GPU(MI100)构建了一个大型计算系统,每个GPU都加载了一个HBM-PIM芯片,并成功展示了存内处理 (PIM) 芯片的性能。这是一种存算一体技术,可以显著减少数据在CPU 和 DRAM 之间移动的频度并提升性能。
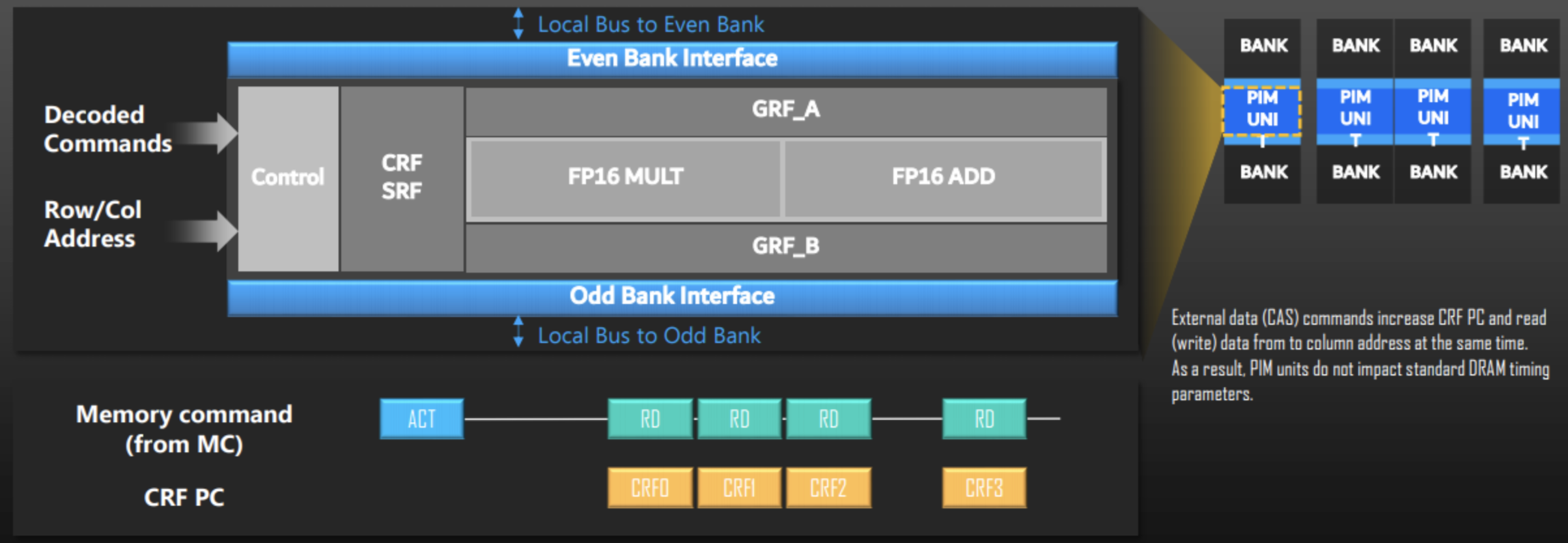
PIM 是指将计算单元与随机存取存储器 (DRAM) 集成在单个芯片上。这项技术有望有助于提高庞大的人工智能 (AI) 的性能。三星使了严格意义上的芯片内数字近存计算来提升AI计算性能。三星 HBM-PIM 芯片与其他公司 HBM 实现的不同之处在于,PIM 芯片上的每个存储块内都包含一个内部处理单元。

根据三星去年在ISSCC发布的学术文章信息披露,该HBM-PIM使用的是三星的20nm DRAM工艺。负责计算的PCU与DRAM 阵列在同一个晶圆平面内,显著性能提升主要来自存算一体技术而非3D 堆叠封装。仅用20nm工艺的PCU进行简单的逻辑计算(DRAM工艺做逻辑计算其实不划算,外周的逻辑晶体管的实际栅长在32nm附近),就使得7nm工艺GPU集群的性能提升到2.5倍。
与现有内存解决方案相比,三星的 PIM 理论上可以通过可编程计算单元 (PCU) 将性能提高达 4 倍。 与 CPU 中的多核处理一样,PCU 支持内存中的并行处理,从而提高性能。例如,PIM 带来的好处之一是在语音识别等 AI 应用中,PIM(存算一体化)的性能比现有的 HBM 提高了2 倍。

三星电子使用该系统训练语言模型算法T5(Text-to-Test Transfer Transformer)时,与未使用PIM时相比,性能提升了2.5倍,功耗降低了2.67倍。与仅配备 HBM 的 GPU 加速器相比,配备 HBM-PIM 的 GPU 加速器一年的能耗下降了约 2,100 GWh。三星表示,其 PIM 技术将对能源消耗和环境具有重大影响,可将集群的年能源使用量减少,相当于减少 960,000 吨碳排放。
三星开发的另一个方向是使用 CXL(Compute Express Link)开放标准,用于高速处理器到设备和处理器到内存的接口,从而可以更有效地使用与处理器一起使用的内存和加速器。
在需要快速处理大量数据的 AI 应用中,耗电量是一个重要问题。PIM 响应了这一需求,较之现有 HBM,将应用 PIM(存算一体化)的系统能耗降低了 70%。这一解决方案因而适合高耗电量 AI 应用,能够为要求较高的任务提供 合适的条件。
CXL 可以与其他技术结合使用,例如 Processing-near-Memory (PNM),以帮助促进内存容量扩展。与 PIM 一样,它通过使用内存进行数据计算来减少 CPU 和内存之间的数据移动。在 PNM 的情况下,计算功能在更靠近内存的地方执行,以减少 CPU 和内存数据传输之间发生的瓶颈。
三星本月早些时候推出了带有 CXL 的 PNM 技术,用于高容量 AI 模型处理。在测试中,基于 CXL 接口的 PNM 系统在推荐系统或需要高内存带宽的内存数据库等应用中性能翻倍。
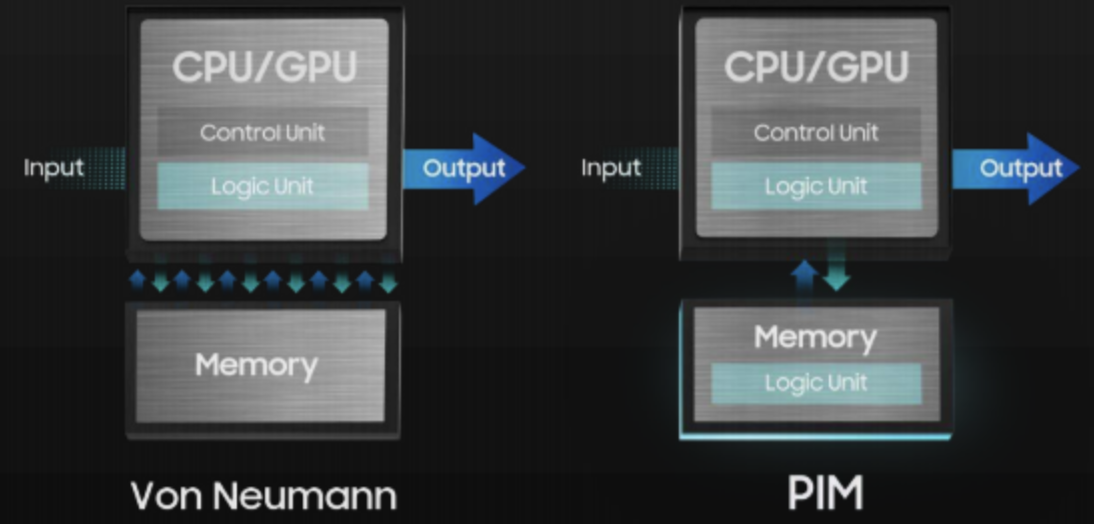
这种技术被称为存内计算(PIM)。该技术将专用数据处理器直接集成在DRAM中,可将部分数据计算工作从主机处理器转移到存储器当中。这可以减少数据的移动,提高AI加速器系统的能效和数据处理效率。
采用这种技术的一个例子是AMD(@AMD)发布的Instinct MI100 GPU计算加速卡,其便搭载了三星的HBM-PIM存储器。在大规模AI和HPC(高性能计算)应用中采用三星的HBM-PIM技术,有望将GPU加速器的性能提高一倍,同时还可降低能耗。
AMD在2月份的ISSCC 2023大会上谈到了该技术,并表示:“从系统的角度来看,我们希望尽可能提高能效,通过采用合作伙伴三星的PIM技术,我们看到存内处理时,用于数据移动的能耗可节约至85%。作为未来系统优化的一项技术,很有发展前景。”
三星半导体(#SamsungSemiconductor)深知,类似ChatGPT这样的超大规模AI在21世纪只会越来越重要。因此我们将继续致力于开发HBM-PIM等面向AI的新一代技术,并发布必要的软件和模拟器来支持这些技术的实施。

无需改变现有内存生态系统环境,即可应用 PIM,并且 PIM 可与 HBM、LPDDR 和 GDDR 内存集成。将 PIM 整合到 AI 应用,可以提高一系列功能的性能水平,尤其是在语音识别、翻译和推荐等功能。PIM 释放了 AI 的潜力,让商业和日常生活朝着更好的方向改变。


