



4,699
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享近年来,应用数据呈现爆炸式增长,处理器和主存之间的带宽限制成为数据密集型应用的瓶颈。此外,目前流行的一些数据密集型应用,如神经网络应用和图计算应用,数据的局部性差。这会导致处理器片上缓存命中率降低,进而导致处理器和主存之间频繁地传输数据.这样的大量数据传输除了使得总线拥堵并影响性能,还会造成大量的能耗开销。研宄表明,两个浮点数在CPU (central processing unit) 和主存之间传输所需的能耗要比一次浮点数运算大两个数量级。在大数据系统中,能耗开销大会使得基于传统冯.诺依曼(von Neumann) 结构的系统扩展性差,甚至无法支持大型的数据密集型应用。
内存计算(processing in memory, PIM) 给总线上数据传输量过大的问题提供了一个根源性的解决方案.它通过赋予内存一部分计算能力,使其能直接处理一些形式单一且数据量大的计算(例如向量乘矩阵)。内存计算有两种形式,一种是将计算资源以高带宽的连接方式集成到主存单元中(一般称之为近数据计算, near data computing,NDC),另一种是直接利用存储单元做计算(一般称之为存内计算, compute in memory,CIM)。这两种形式都很大程度减少了中央处理器和主存之间的数据移动,从而达到提升系统性能并降低能耗的目的.数据表明,近年来提出的内存计算架构相比于传统冯.诺依曼架构有着几十,上百,甚至上千倍的性能提升。尽管在性能和能耗方面优势明显,目前内存计算的应用仍面临着诸多挑战。
在近数据计算方面,由于内存中用于数据处理的逻辑芯片计算能力较弱,架构设计者需要分析和提取出程序中适合放到内存中做计算的部分,其余留给中央处理器处理。其次,架构设计者还需要针对上层应用的特点,对近数据计算中的逻辑芯片进行精心设计以取得大幅性能提升。不仅如此,近数据计算还缺乏高效透明的系统级支持。虽然一些面向特定应用设计的近数据计算微体系结构提供了上层软件接口,但是程序员需要对底层充分了解才能够使用该近数据计算系统。也有研究者设计了对上层透明的内存计算系统接口,但仅能适应特定的内存计算结构,缺乏通用性。
在存内计算方面,由于用来直接做计算的内存单元能够支持的算子类型有限,存内计算较难高效支撑复杂多样的计算模式。因此,研究者们常针对算子类型少且简单的数据密集型应用设计专用的计算体系结构和系统。除此之外,存内计算模块集成到现有系统结构中的形式尚不明确。虽然存内计算模块既可以作为存储模块也可作为计算模块,但其作为内存的一部分和现有存储系统合作的方式仍有待研究.另外,存内计算模块硬件本身存在性能和可靠性的问题,例如基于非易失存储的存内计算单元中非易失模块的可靠性问题。
由此可见,内存计算技术虽然潜力大,但是其结构复杂,与上层应用关系紧密,应用到现有系统中仍面临着诸多挑战。因此,我们对现有的内存计算研究进行综述,阐述内存计算从硬件架构到软件系统支持的相关技术方法和研究进展。本文首先详细分析和介绍了内存计算的兴起原因,然后介绍了内存计算的形式以及目前已有的内存计算微体系结构,接着分析和总结内存计算所面临的挑战,最后介绍内存计算给现在流行的应用带来的机遇。
20世纪70年代,超级计算机中单指令多数据流的性能不佳[181.这是因为存在数据依赖的问题,导致单指令多数据流无法进行高效的数据并行.因此,研宄者们提出内存计算技术,希望在存储端加上处理单元,提前执行好部分计算以减少数据的依赖。
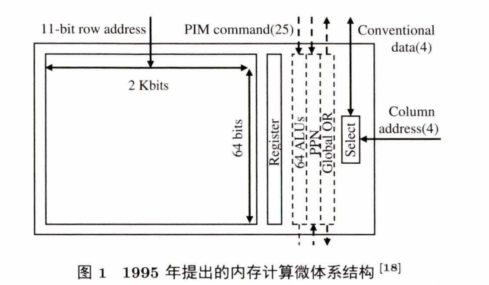
图1是20世纪提出的内存计算微体系结构.该结构通过在存储阵列旁加了一些计算单元(例如 ALU),用于支持存储阵列内部的数据处理.这种做法直观但并不实用。一方面,当时的技术能力还无法使计算单元和存储单元紧密地结合,所加的硬件资源占用了较大的存储片上面积,不能达到与其相匹配的计算资源利用率。另一方面,当时的应用所处理的数据量不大,不能使所加的计算单元满载。在当时的技术环境下,这种直接在存储内部加计算单元的方式不仅难以获得较高的资源利用率,而且不能达到占用面积小且能耗低的目的.故而,内存计算在20世纪并没有兴起。
内存计算真正兴起是在2010年后,数据呈现指数级暴增.该阶段数据驱动的应用发展迅猛,例如近年来流行的人工智能应用,需要大量的数据进行模型训练,推理时也需要处理大量的数据。以谷歌翻译为例,近年来处理数据量不断增长,目前一分钟需要翻译六千九百五十万个词。现代计算机中片上存储空间有限,对于大规模的数据处理需求,中央处理器将频繁地到主存取数据并把处理好的数据存回主存。数据显示,传输两个浮点数的能耗要比一次浮点运算大两个数量级现在全球能源紧缺,降低能耗是设计现代计算机的一大要点。因此,研究者们重新考虑赋予内存一定的计算能力,从而减少数据移动,降低计算机系统运行能耗。
与此同时,新型存储器件迅猛发展,包括 3D 堆叠的存储器件,如 HMC (hybrid memory cube) / HBM(high bandwidth memory) 和 3D XPoint, 以及交叉栅栏式(crossbar) 结构的非易失性存储器件,如ReRAM和PCM。
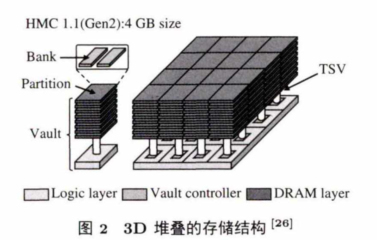
图2 展示了一种3D堆叠的存储结构。其中,最底层为逻辑层,包含控制器和其他处理单元.逻辑层上面堆叠有DRAM存储层,他们通过高速地穿过硅片的通道(through silicon via, TSV) 相连接。图2中的一个立方体(cube) 包含了16个拱(vault),每个拱的一层包含了两个阵列(bank).与传统的二维结构不同的是,该 3D 结构最底层的逻辑层可以放置计算单元,且可以通过超高 速 的T S V 与上层的存储单元进行数据交互,从而使得计算和存储结合得更加紧密。
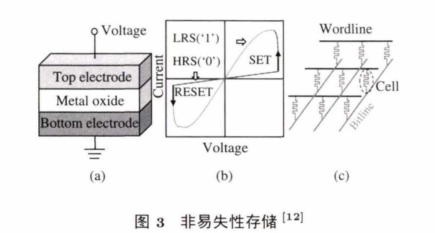
图3 展示了 ReRAM 的 结 构 .其 中 ,图 3(a) 是 一 个 ReRAM c e ll的物理结构图,以三明治模式将金属氧化物层夹在两个电极中间。图 3(b) 展示了 S E T 操 作 和 RESET操作的电流和电压关系图.图3(c) 展示了ReRAM的 crossbar的结构:每 个 cell放置于字节线和比特线的交叉处.这样的NVM (non-volatile memory) 结 构 和 传 统 的 DRAM结构相比,具有存储密度高和静态功耗低的优点,同时其特殊的物理结构为存储和计算相结合提供了支持。
综上所述,数据驱动的应用迅猛发展以及数据量指数级暴增驱动了内存计算的发展,并且新型存储器件的快速发展为内存计算提供了技术保障。因此,内存计算在2010年后兴起。
内存计算技术是一个宏观的概念,是将计算能力集成到内存中的技术统称。集成了内存计算技术的计算机系统不仅能直接在内存中执行部分计算,还能支持传统以CPU为核心的应用程序的执行。区别于内存计算,存算一体芯片将存储与计算相结合,是 一 种 ASIC (application-specific integrated circuit) 芯片,常用于嵌入式设备中,针对一类特定的应用设计,不能处理其他应用程序。内存计算包括两大类:近数据计算和存内计算。
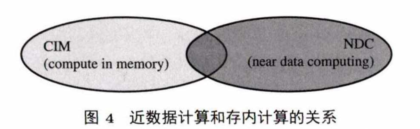
两者的关系如图4 所示,它们在形式上不同,但是在特定场景下可以融合设计。近数据计算和存内计算的最大区别就是:近数据计算的计算单元和存储单元依然分离,而存内计算直接利用存储单元做计算,计算和存储紧耦合.下面将从硬件结构和所支持的计算操作两个方面具体介绍近数据计算和存内计算相关技术。
为缓解传统冯.诺依曼架构中总线上的数据传输问题,近数据计算在存储周边放置计算单元,这就需要高速通道进行连接。因此,近数据计算通常依赖于3D堆叠的内存结构,如 图2所示,近数据计算系统中通常有一个或多个NDC cube,它们与CPU或者GPU相连接(如 图 5 所示),多个NDC cube之间可能也会存在连接.目前基于3D 堆叠的近数据计算的研究主要集中在:(1) NDC cube模块与现有系统的集成方式;(2) NDC cube和 CPU / GPU 之间,NDC cube之间的连接方式,通信方式以及一致性协议;(3) NDC cube中逻辑层的设计;(4) NDC数据映射方式;(5) NDC的软硬件接口及上层系统软件支持。除了基于3D 堆叠内存结构的NDC,还有基于2D NVM的NDC结构,主要思想是对 NVM中现有外围电路进行改造,以支持特定类型的计算。
(1)通用的近数据计算架构;
(2)针对机器学习的近数据计算架构;
(3)针对图计算的近数据计算架构;
(4)针对垃圾回收的近数据计算架构;
近数据计算中逻辑层的设计较为灵活,可以针对不同系统的需求设计通用的处理器或者专用的加速器。在设计针对通用应用的近数据计算系统时,由于放到内存端的通用处理器一般性能较弱,需要考虑自动化地分割应用程序的计算部分,把能从近数据计算中获益的部分放到内存中处理.在设计针对特定类型应用的近数据计算系统时,需要仔细分析应用特点,抽取算子,设计对应的数据流. 除了逻辑层的设计,近数据计算系统结构设计还需要考虑:各个内存块之间的连接方式,包括通信方式和数据一致性协议、数据映射策略、与现有系统集成方式、软硬件接口设计。
和近数据计算不同,存内计算直接使用内存单元做计算,主要利用电阻和电流电压的物理关系表达运算过程.存内计算依赖于新型的非易失性存储器,如 ReRAM和 PCM 等。在所有存内计算操作中,最普遍的是利用基尔霍夫定律(Kirchoff’sLaw) 进行向量乘矩阵操作辦]。原因在于:(1)它能够高效地将计算和存储紧密结合;(2)它的计算效率高(即,在一个读操作延迟内能完成一次向量乘矩阵);(3 ) 目前流行的数据密集型应用中,如机器学习应用和图计算应用,向量乘矩阵的计算占了总计算量的9 0 % 以上。除了向量乘矩阵操作,存内计算还能利用电阻、电流及电压的物理关系实现查询,按比特与/或/非等操作.本小节首先综述基于向量乘矩阵的存内计算研究,然后综述其他存内计算技术。
(1)基于向量乘矩阵的存内计算;
(2)基于逻辑操作的存内计算;
(3)基于搜索操作的存内计算;
存内计算支持的算子较少,设计灵活度不如近数据计算的逻辑层,但是存内计算用于支持特定算
子 (目前主要是向量乘矩阵算子)的性能很高且能耗低.存内计算的核心思路是利用新型存储的物理结构和特性来支持应用程序中频繁出现的算子.同时,存内计算相关研究还关注:存内计算模块互联和数据流的设计;数据映射策略:外围电路的优化和复用;与现有存储系统的融合。
内存计算面向的应用有如下特点:
(1)数据密集,在普通冯.诺依曼结构中有大量的内存访问;
(2)数据局部性差,片上缓存命中率低;
(3)计算密集且计算形式简单,易于并行.
内存计算包含两大类:近数据计算和存内计算。近数据计算通常使用3D 堆叠的内存结构,在内存中集成计算逻辑芯片,并用高速通道将计算单元和内存单元相连接,存算依然分离。存内计算直接使用内存单元做计算,利用电流 、电压、电阻等物理量之间的关系表示某类计算.近数据计算相比于存内计算灵活度更高,能支持较多算子;存内计算虽然能支持的算子较为单一,目前能支持向量乘矩阵算子,按位逻辑操作,或者搜索操作,但是其计算速度快且能耗低.设计内存计算架构时,设计者需要根据应用场景的需求(应用中算子的类型、延迟和能耗的限制等)进行选择,必要时也可结合使用近数据计算和存内计算两种技术,充分利用两者优点。
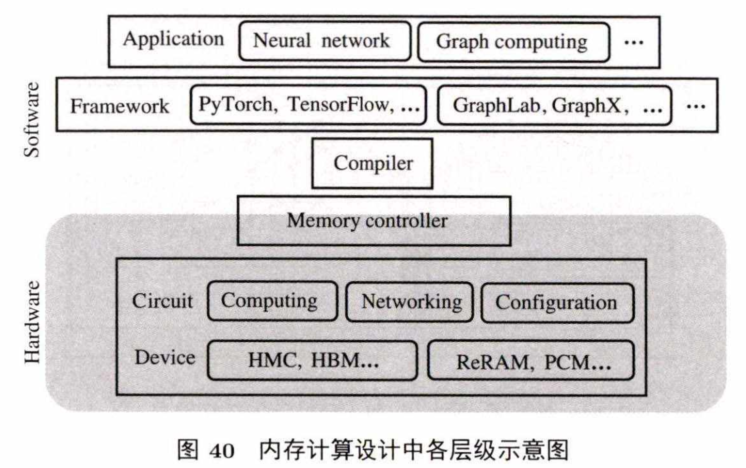
内存计算设计时需要考虑计算机中多个层级,如图40所示.内存计算本身存在一些问题,与现有的系统相结合也会带来新的问题,每个具体问题都涉及图4 0 中的某些层级.解决这些问题是内存计算可以在计算机系统中发挥作用,提升系统性能和降低能耗的关键.本节将分析并总结近数据计算和存内计算本身及其与现有系统集成会带来的挑战。
在近数据计算系统中,对程序模块的分割不当或者过度使用近数据计算来处理数据反而会增加系统能耗。该问题的产生通常与编译器的设计和内存控制器的设计相关。Kim等分析了集成有传统处理器和NDC cube的系统的能耗特征,发现LLCMPKI (misses per kilo instructions) 是一个决定应用是否能在近数据系统中高效执行的关键特征:通 常 高 M P K I表示可从近数据计算系统中获得高的能耗节约。因此,他们认为应将高M P K I的计算放到NDC cube中做,把其余部分留在传统系统中做。
因为近数据计算的NDC cu b e中逻辑芯片通常使用FPGA, CGRA,和 ASIC处理器等非通用处理器,所以硬件配置与应用需求的匹配成为一个挑战.该问题通常与电路设计和器件选择强相关。Gao等提出了一种异构且可重构的逻辑阵列,同时利用FGPA和 CGRA。通过分析适合近数据计算处理的大量应用,结合两者长处,设计FPGA和 CGRA以及逻辑层的多路选择器的个数,以满足近数据计算应用的高性能低能耗的需求.针对特定应用场景或者特定应用,如何配置近数据计算中的逻辑芯片部件仍有待探索和研宄。
近数据计算的计算资源基本均匀分布在整个内存中,直接使用传统的数据存储方式会导致计算资源分配不均匀,计算核与其所需的数据相距远等问题,进而导致内存计算的计算资源利用率低. 该问题的产生通常与编译器设计和内存控制器设计相关.内存中数据的存储需要考虑到计算资源的利用率,尽量使所有计算资源能够时分复用,管道串行,要避免因计算资源集中在某一块使用而导致长时间的数据等待。对于特定的存内计算架构,通常采取设计合适的数据映射策略来提高计算资源的利用率的思路。而数据映射策略取决于不同的内存计算系统架构和运行在其上的应用。因此,在设计上层系统时,需要同时考虑两者来设计合适的数据和计算核的排布。
运行在近数据计算系统中的应用需要在中央处理器和近数据计算端来回切换,因此,相应的系统应支持这样的灵活切换.目前的近数据计算都是针对特定的硬件结构或特定应用提供的上层软件支持灵活性不够。
近数据计算运用到系统中时,还需要考虑近数据计算中的多任务调度以及近数据计算任务和传统访存任务的调度问题.首先,由于近数据计算的计算资源均匀分布在内存中, 一个好的多任务调度策略能使计算资源利用率高,同时减少系统中的冲突和中断.其次,在不处理内存计算任务时,近数据计算模块也可以用作普通存储模块,因此,需要一个内存计算任务和传统任务的调度策略,来优化内存计算和传统存储混合的系统结构性能。
另外,近数据计算中有多个计算模块,各计算模块之间可能会共享数据,包括并发地对数据进行增删改查的操作.因此,近数据计算需要一个解决冲突问题的方案,以保证其数据的一致性。
以上问题都属于近数据计算的系统问题,通常与系统级的设计强相关,也与编译器和内存控制器相关。
NVM 的寿命有限,例如 PCM 的 SLC (single level cell, —个 cell只能 存 0 或 1,即一个比特位)的寿命只有 〜
,ReRAM 的 SLC 的寿命只有 107 〜109 I17,58,59]. MLC (multi-level cell, —个 cell能存多个比特位)的寿命问题更加严重,通常只有104 〜105 次写,甚至更低.对于传统NVM存储,磨损均衡是延长寿命的有效方法.磨损均衡算法通过每隔一段时间改变逻辑地址到物理地址的映射,使得写操作在整个NVM 中均衡. 然而这种方法在基于NVM 的存内计算中并不适用,因为存储于NVM中的数据还直接用作计算.如果直接使用传统的磨损均衡算法交换数据所存储的位置,计算结果将是错误的. 该问题由器件相关问题引起,除了选择和配置合适的器件外,还可以通过上层设计来缓解,例如应用中算法的设计和内存控制器的设计等。
ISAAC通过在片上加eDRAM减少对NVM 的写。IBM 的研究人员通过用CMOS+PCM做一个 cell的方式,使寿命的CMOS单元承受频繁的更新操作。Long-live-time提出了一种针对神经网络训练的C IM 硬件寿命延长方法,通过改变神经网络权值更新方法(每次选误差最大的行更新而不是全部更新),再结合行粒度的磨损均衡算法,延长基于NVM 的存内计算硬件的寿命.我们正在进行的工作将祌经网络和N V M 的特点综合考虑,从而延长基于NVM 的存内计算硬件寿命. 针对其余应用的NVM 存内计算硬件寿命的延长方法仍待探究。
NVM写出错问题以及外围电路对输出模拟域电流转成电信号产生误差的问题使基于NVM 的存内计算可靠性不佳. N V M 的 cell会因为写电流过高或寿命己到而产生stuck-at fault (阻值停留在某个固定值不可改变).传统存储中,可以将发生错误的cell值存到别的物理位置,然后改变原逻辑地址到物理地址的映射来容这种错误.而这种方式在基于N V M 的存内计算中并不适用,存储在存内计算的 NVM 中的数据还要直接用作计算,数据之间的相对物理位置不能被改变,否则计算结果会出错。
与寿命问题相似,可靠性问题也是由器件相关问题引起的,除了选择合适的器件外,还可以通过上层设计来缓解。
Xia等利用神经网络中权值的稀疏性(一些位置的权值为0)来容存内计算NVM上 stuck-at-0的硬件错误。Xia等还通过利用存正负值的一对存内计算NVM阵列来互相容错。Liu等提出分析识别出神经网络中重要的部分,把此部分放到可靠性高的存内计算硬件上去做.我们正在进行的工作将采取更加灵活的方式,综合利用神经网络和NVM 本身的特点来容更多类型的stuck-at错误。由于外围电路的误差而造成的可靠性降低问题仍待解决。
每个NVM的MLC能存的比特位有限(目前最高可存7 比特位),这样的数据精度在神经网络中通常不够使用。因此,很多基于NVM 的存内计算用多个MLC或者SLC来存一个数据,但这样会产生较大的支持中间数据计算的外围电路开销.不仅如此,基于NVM 的存内计算目前不支持浮点数计算,所有计算数据都先要转换成定点数后再做计算.这样会带来结果精确度损失甚至结果不正确的问题.而一些应用,例如大规模的神经网络训练,需要高精度的数据来保证网络的高准确度.因此,可以通过软硬件层协同设计,来支持高精度浮点数的运算。
由于NVM 的写能耗比DRAM高,而 基 于 NVM的存内计算有大量的原地更新,在没有缓存的帮助下会产生大量的NVM 写操作,这 使 得 基 于 NVM 的存内计算系统能耗过高.同时,用于支持电模转换 (ADC,DAC) 的外围电路能耗过大,也会使得存内计算系统能耗高.该问题与器件层强相关,可以选择写能耗较低的器件,还可以通过上层的设计减少器件的写能耗开销。
Mao等探索神经网络中数据的结构化稀疏性,在算法和编译器层面,通过重构数据块的方式去掉与零操作相关的数据,从而减少NVM的写能耗。在应用算法和电路层面,Ni等通过二值化的ReRAM存内计算阵列减少电模信号相互转换的能耗。Wang等使用脉冲神经网络(spiking
neural network,SNN),在应用算法和电路层面,减少电模信号的相互转换能耗,还改变了 SNN训练的算法来减少取样的能耗.Narayanan等 I66]在 使 用 SN N 降低能耗的同时,在内存控制器层面,探索神经网络中计算的并行性来提高针对SN N 的存内计算的吞吐. A nkit等[67】在电路设计层面,利用低能耗的 SNN实现了一个可重构的连接,为 SN N 中计算的数据流服务,从而降低基于NVM 的存内计算的能耗。Xia等通过分析数据的分布,在应用算法层面,提出新的数据量化方法,将中间数据转化成 1 比特位的数据从而取消DAC,另外选择必要的输入信号减少输出的个数,从而减少A DC的能耗。
基于NVM的存内计算中,外 围 电 路 的 ADC和 DAC不仅能耗占比大,还占用了很大的片上面积,此外 ,用于中间数据处理的外围电路也占了存内计算的较大一部分面积。尽管NVM 有很高的存储密度,当用作存内计算的计算核时,还需要大面积的外围电路支撑,这使得整个结构占用面积大。该问题主要与电路的设计相关。Mao等通过3D堆叠的方式,将外围电路放到最下层做成一个外围电路资源共享池,由堆叠在其上的 NVM 存内计算阵列共享.基于此,通过时分复用的方式,极大地减少了外围电路的使用,从而减小了基于NVM 的存内计算架构的面积。
和近数据计算一样,存内计算的计算资源也分布在整个内存中.因此数据存储需要考虑计算资源的利用率,在编译器层面和内存控制器层面,针对具体的存内计算系统架构和运行在其上的应用,设计对应的数据映射策略。
存内计算模块作为有一定计算能力的存储模块,在集成到现有的混合存储系统时,需要考虑不同的集成方式.例如基于非易失性存储的内存计算模块可以和传统的DRAM 并列接到总线上,也可以和纯 NVM 存 储 以 及 DRAM 存储并列连接到总线上,而后通过内存控制器来管理.除与传统混合存储相结合外,内存计算模块还可作为C PU 的协处理器.对于这些架构,存内计算模块亟需一套相对应的软硬件接口支持,以保证其高效且灵活的应用。
除此之外,和近数据计算一样,存内计算运用到系统中时,也需要考虑多任务调度以及存内计算任务和传统任务的调度问题,同时要保证存内计算中数据的一致性.该挑战主要涉及系统级的设计和内存控制器的设计。
内存计算模块不仅用作存储,还用作计算。存储于内存计算中的数据需要以某种特定的排布来配合其中配置好的数据流,从而达到高性能计算的目的。传统面向内存的虚拟地址空间管理会破坏内存计算中的特定数据排布,并不适用于内存计算模块。因此,内存计算亟需相应的虚拟地址空间的支持,同时还需要和传统存储相配合的访存模式,以保证上层应用使用内存计算模块的安全性。该挑战主要与系统级的设计和内存控制器的设计相关。
内存计算技术在处理存储密集型、数据局部性差、且计算形式较为单一、易于并行的应用上优势明显.目前流行的3 类应用:机器学习,图计算和基因工程,在传统系统中因总线带宽有限和片上片下数据移动太频繁而性能低且能耗高.内存计算技术恰好弥补了传统计算机体系结构在这3 种流行应用上的缺陷.本节主要介绍内存计算给这3 种应用带来的机遇。
机器学习的核心是神经网络神经网络类型很多,包括:卷积神经网络,主要用于图像处理;循环神经网络,主要用于自然语言处理;深度神经网络是卷积网络或者循环神经网络的强化版,有更多的网络层;生成对抗网络是无监督学习中的最受关注的网络类型;还有深度强化学习,是一种在线学习方式,基于环境的改变而调整自身的行为.这些网络各具特点,大的网络会对存储造成很大的压力,连接多的网络会给计算和传输造成很大的压力.他们的共同点在于都有很多向量乘矩阵操作,占到所有计算的90% 以上。因此基于NVM 的存内计算适合用于支持祌经网络计算。
随着互联网数据爆炸式的增长以及人们对数据单元之间关系的关注,图计算在新型应用中占有较大地位。图计算的应用包括:网络安全、社交媒体、网页评分和引用排序、自然语言处理、系统生物学、推荐系统等。由于图计算应用的数据局部性差且数据量很大,目前用来处理图计算的系统面临性能不佳且能耗过高的难题。
图计算中大量操作都可以转换成矩阵乘的形式,因此可以用基于N V M 的存内计算来处理。综合考虑图数据的预处理,稀疏矩阵的分隔和映射,以及硬件控制和数据流设计,能够高效且低能耗地支持图计算应用.图计算也可以用基于H M C的 NDC来处理,通过分析现在图计算中哪些操作适合放到 HMC中处理,然后有针对性地设计逻辑层和上层的指令集,能取得较高的性能提升和能耗节约。所以内存计算给图计算的发展提供了很好的机遇。
近年来,随着基因工程的发展,生物学信息数据呈指数级增长[88,891.这种生物数据的暴增给现在诸如基因序列匹配的应用带来了很大的挑战l9Q,91l 目前有一些针对基因序列查找的软件方面的加速方法,也有利用基因处理的高并行性的硬件加速方法但是由于生物数据的量太过庞大,传统计算机系统片上片下数移动量太大,系统能耗是一个很大的问题[94,951.基 于 RCAM的存内计算能利用CAM 的极速查找能力,提供很高的硬件并行度,同时在存内处理能降低数据移动的能耗,适用于大规模生物数据处理.因此,存内计算给基因工程的发展提供了机遇.
在数据爆炸时代,内存计算技术为解决传统冯•诺依曼架构中总线拥堵问题以及片上片下数据传输能耗过高问题提供了解决方案.内存计算技术得益于新型3D 堆叠技术和非易失存储技术的发展。内存计算主要有两种形式:近数据计算和存内计算.近数据计算技术通常依赖于3D 堆叠的内存结构,存算依然分离,但计算部分到存储部分带宽较大,计算部分灵活性较高.存内计算技术通常依赖于新型的非易失存储,直接利用存储来做计算,存算紧耦合,能够为特定算子(例如向量乘矩阵)提供极高性能的计算,但缺乏一定的灵活性.内存计算技术总体还处于发展初期,有一些硬件和软件支持上的问题。但是内存计算的潜力很大,能够给目前流行的机器学习应用,图计算应用,和基因工程提供高效低能耗的系统结构支持。
毛海宇,舒继武,李飞,等. 内存计算研究进展. 中国科学:信息科学,2021, 51: 173-206, doi: 10.1360/SSI-2020-0037 Mao HY, Shu JW , Li F , et al. D evelopm ent of processing-in-m em ory (in C hinese). Sci Sin Inform , 2021, 51: 173-206, doi: 10.1360/SSI-2020-0037

支持存内计算开发者社区

存内计算的前途很宽广,但是现存的挑战仍然很多
存内计算支持的算子较少,设计灵活度不如近数据计算的逻辑层

支持存内计算开发者社区


