


301
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享第一单元的任务是表达式展开,历经了三次迭代,分别是:
hw1. 展开包含加、减、乘、乘方的含变量x的表达式,最多有一层括号
hw2. 在hw1的基础上增加了多层括号嵌套和自定义函数调用,以及指数函数exp
hw3. 在hw2的基础上增加了求导算子,以及允许自定义函数定义中调用其他自定义函数
下面以最终的hw3为例进行各部分的分析
首先是整体的架构:
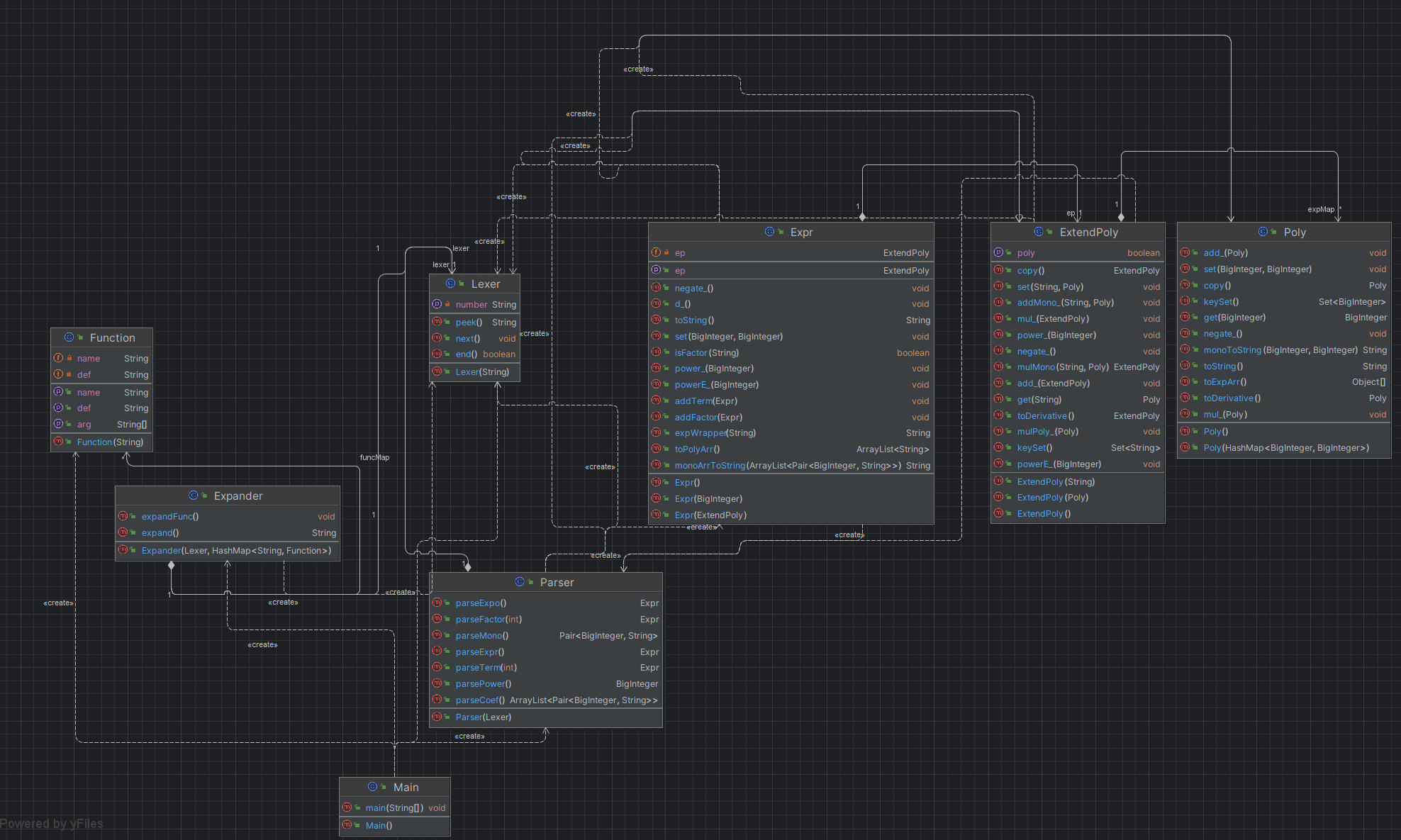
其中Lexer和Parser采用与实验相同的思路,Lexer将字符串转化为词元,交给Parser进行递归下降解析,并转化为表达式结构储存。
由于3次任务中设计到的运算的封闭性,我将多个层次的结构(表达式、项、因子)统一为同一个类Expr,并由Expr中的ExtendPoly统一表示他们的数据,这样带来的好处是可以在不同结构之间的运算中复用相同的方法。其中,ExtendPoly表示多个多项式,即Poly类,乘exp()的数据结构。具体来说,Poly类表示下面的P(x),而ExtendPoly类表示下面的Q(x)。
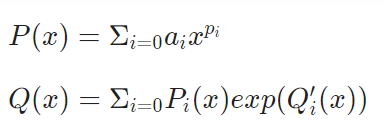
因此,在递归下降分析时,我将分析到的所有形式化数据类型全部转换成ExtendPoly的形式,之后只需实现ExtendPoly之间的运算即可。
对于自定义函数的解析,我设计了两个类:Function和Expander。Function负责记录函数的名称(f、g、h)、形参(x、y、z)和定义式。由Function组成的List会传给Expander,Expander.expand()会对于输入的字符串查找自定义函数并替换为带有实参的定义式。
综上,整个程序的思路是:读入函数并展开函数内调用的函数-读入表达式-展开函数-递归下降解析并同时进行合并简化-输出
然后是各部分的代码量:
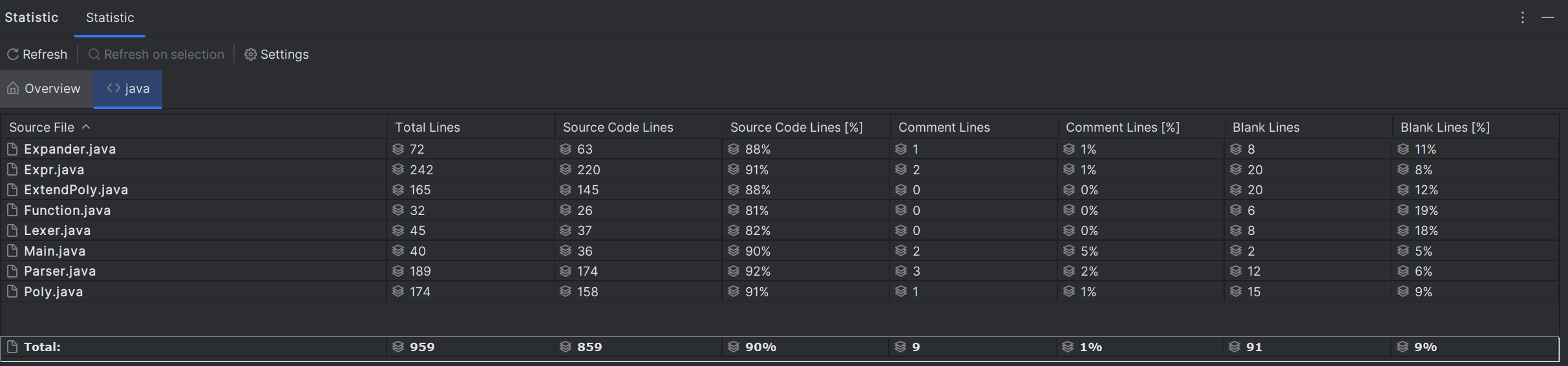
以及各类的复杂度:
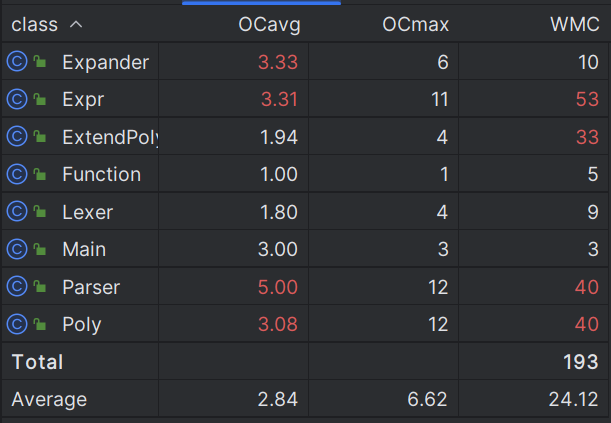
可以看出由于我将多个层次的数据统一存储为ExtendPoly基本项,因此主要的复杂度都集中在基本项的运算上。
类内方法的复杂度:
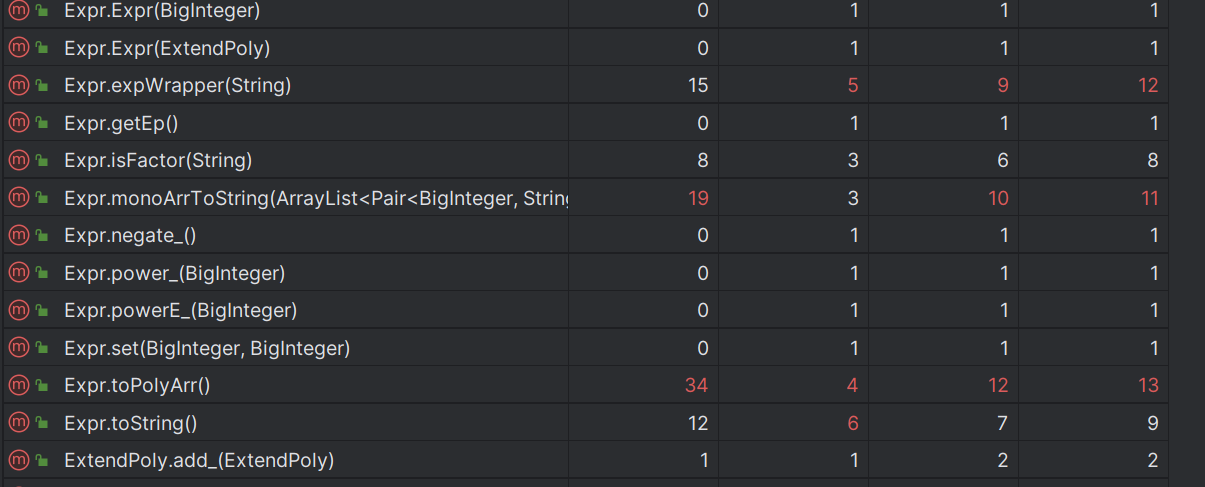

可以看出,复杂度高的部分集中在分析因子、输出以及优化相关方法上。
在第一次的作业中,最终化简的目标是一个关于x的多项式,而进一步可以发现,不仅最终的结果可以表示为多项式,常数、变量因子、幂函数等都可以表示为多项式的特殊形式,他们之间的运算都可以通过多项式的运算来完成。因此,贯穿整个单元的主线思路都在于确立基本项,并在一方面将所有解析过程中的中间项由基本项表示,另一方面实现完备的基本项运算。hw1的基本项是Poly,而hw2、3的基本项是ExtendPoly。这使得我的整体架构在经历三次迭代时无需任何重构,每次只需进行增量开发。
在第二次作业的设计中遇到了本单元最大的挑战:如何表示递归的结构?第二次作业新增了指数函数exp,而exp中还可以嵌套和外层结构完全相同的表达式,如果使用递归的表达式树结构,将会对未来合并exp所需的表达式比较是否相等造成巨大的开发成本。因此,我借鉴了序列化与反序列化思想,既然结构化的表达式树不好操作,就将它转化为字符串(相当于复用主程序,进行序列化),在字符串层面上无论是进行判断相等还是生成hashcode都有现成的方法。而如果进行合并时需要让字符串中的表达式参与运算,就重新调用Lexer与Parser,将字符串反序列化为Expr。对于比较操作,只要通过排序保证恒等的表达式一定能化为相同的字符串。对于合并操作,如exp的乘法,采用指数相加,即对两个exp内的字符串"Q1(x)"与"Q2(x)",重解析并化简"Q1(x)+Q2(x)",作为合并后exp内的表达式字符串。通过这样的序列化与反序列化操作,尽管增加了一定的复杂度,但使得表达式可以十分方便地进行运算、比较与存储,最终的评测表明,这种权衡是利大于弊的。事实上,从这个角度来解读,整个作业的流程就是将字符串反序列化为结构化数据,再序列化为字符串的过程。
在此架构下,每个Expr中使用一个ExtendPoly来储存数据,而ExtendPoly中带有一个HashMap<String, Poly>,key为exp中的表达式序列化后的字符串,value为该exp乘的多项式。这些键值对表示的P(x)^exp(Q(x))的和,就是该ExtendPoly,以及含有该ExtendPoly的Expr的值。而Poly则来自hw1,带有一个key为指数,value为系数的HashMap<BigInteger, BigInteger>来表示多项式。
在第三次作业的迭代中,涉及对自定义函数的嵌套调用,以及求导的操作。但由于之前hw2的合理设计,使得在处理这些新任务上可以复用之前的绝大部分代码。对于自定义函数中调用其他函数的情况,可以沿用上述展开字符串中函数的方法,将自定义函数的定义式作为输入,进行函数展开。而求导则类似exp的解析,识别到exp(或dx)时,就先对括号内表达式进行解析并化为最简字符串(无后效性的子任务,也是上述的序列化操作)再进行放入exp(或求导)的操作,唯一的不同在于识别到不同算子时调用不同的方法,而绝大部分parse代码可以得到复用。
如果在此之后新加入新的函数(如三角函数、对数)或运算方法(如除法),可以适当拓展基本项的表示,并添加运算方法,而无需从整体上重构代码结构。
本程序由于较为简洁的设计和实现,没有在公测和互测中被测出bug,但在私下曾发现由于疏忽而导致的化简不彻底,姑且算一个小bug
对于测试别人的bug,我与几位同学共同搭建了一个在线评测平台,通过多线程、自动化的方式对代码进行有一定强度的测试。该平台不仅供我们使用,也开放给了全部的同学,截至目前共有200位左右的同学在我们的平台上进行了测试。
该平台的测评程序分为两部分,首先是数据生成器,我们使用python,依照每次作业的形式化定义,为生成每一层级的内容分别编写了函数,并在生成时依照一定概率调用不同的函数来生成多样的输入样例,同时,在调用生成函数时还传递了递归深度以及剩余可用长度两个变量,用以控制复杂度。然后是输出判别器,我们主要使用sympy的expand方法,确保恒等的输出可以化为相同的结果进行判断,由于自定义函数的sympy化简比较复杂,我们将一个经过充分测试的Expander(上述用于函数替换展开的类)单独打包,对输出做预处理至没有自定义函数后,再交给sympy.expand生成标准答案。但有时这样的方法仍会出现一些纰漏,因此我们使用一位同学的程序作为标程,对用户的输出进行二次化简,如果用户程序二次化简结果与
该程序直接运行输入的结果相同,我们仍然判定为该用户通过测试。
该评测方法的优点是可以自动化地进行大量的评测,不足之处在于暂时不能对于sympy允许但作业要求不允许的语法进行判别,也暂时没有进行性能(即输出长度)的判优,这些都可在之后进行增量开发解决。
尽管我们没有直接查看每个人的评测结果,但根据同学们的反馈,大多数同学的错误还是通过平台发现了这也从侧面认证了该测试方法的有效性。
在进行递归下降分析前,进行一些预处理可以将免去在下降时处理许多特殊情况。我首先将输入字符串的全部空白字符去除,之后将exp替换为e,dx替换为d,在输出时再替换回来。这样Lexer在解析词元时只需通过一个字符即可进行词元的判断。在展开自定义函数时,可能会遇到替换的实参中含有其他形参的情况,我的解决办法是将形参统一改为其他地方不会出现的形式,如x,y,z换为_x,_y,_z。
在合并时,会出现exp内较大的表达式的情况,在进行优化后有可能将大数提出至exp外作为指数,在随后的合并中又会乘入exp内。如果和多项式同样采用连乘的方式,此时exp的指数没有最大限制,会轻松将程序卡至超时。因此,对于exp的乘方,采用特殊的办法,对exp(Q(x))^p要变成exp(pQ(x))的情况,我们直接将exp内的字符串"Q(x)"(即序列化表示的表达式)替换为"pQ(x)"再进行化简。
从hw1开始,一些显而易见的输出优化就是按照规定,将输出的表达式化到最简形,此时在长度上也一定达到了最短。这种优化只需在toString时多加判断即可。比较困难的是在hw2和hw3中exp内可以提取共同的常数因子至exp()外的指数,使得总体长度缩短。这涉及到几个问题,首先,对于显而易见的计算最大公约数(gcd)并提出,并不能达到最简,原因如这篇帖子所说,但经过我的一些推导,可以经过对gcd因子的常数次枚举得到最短的表达式(原因见同一篇帖子下我的回复)。做到这里已经可以获取到绝大部分的性能分了,但还有少数例外,即拆出gcd较大的部分项,变为若干exp()的连乘得到更短的结果。然而由于这种优化开发投入换来的收效甚微,故放弃了如此的性能优化。
我的优化过程的实现在于对toString的修改。toString时,在输出非1的exp函数时,会重新对exp里的字符串进行反序列化,并计算每个系数的gcd,再通过上述方法遍历潜在的更优的因子,最后,将exp(a*Q(x))变为exp(Q(x))^a输出。这种实现方式会引入一定复杂度,但不会对整个程序的性能有较大拖累,因为序列化与反序列化过程已在整个程序中多次使用。
作为少数几个没有上过OO pre,且之前没有写过Java的人,最开始的几次作业的确使我遇到不少挑战。但好在有强大IDE的支持,使我很快地上手了Java,并顺利完成了几次作业。此外,评测平台的开发也始终伴随了这几次作业,甚至比作业本身经历了更多更彻底的迭代,耗费了许多课余时间。但当同学们不约而同地告诉我我们开发的评测机帮助他们进行了有效的debug,避免了对强测出错的焦虑,就觉得我们做的一切都是有价值的。
第一单元的总体难度较为适中,但我认为可以在性能优化上给同学们更明确的指引,从而不用为了小数点后几位的性能分钻研数论问题。



