


301
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享我在第二次作业中进行了重构,二三次作业采用了相同的具有良好扩展性的结构进行完成且第三次迭代内容较为简单,故将二三次进行合并分析,因此下面基于度量分析自己的程序结构
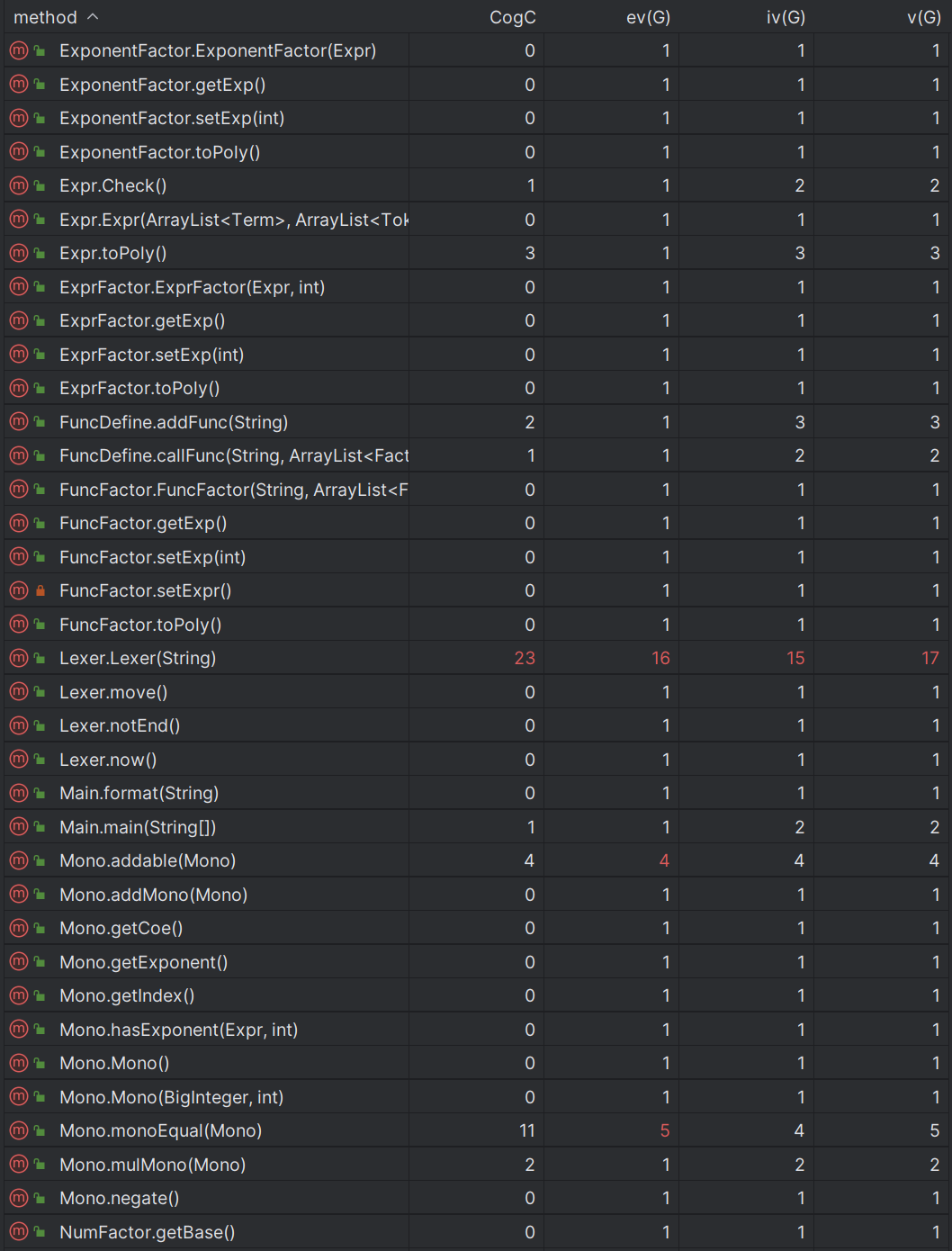
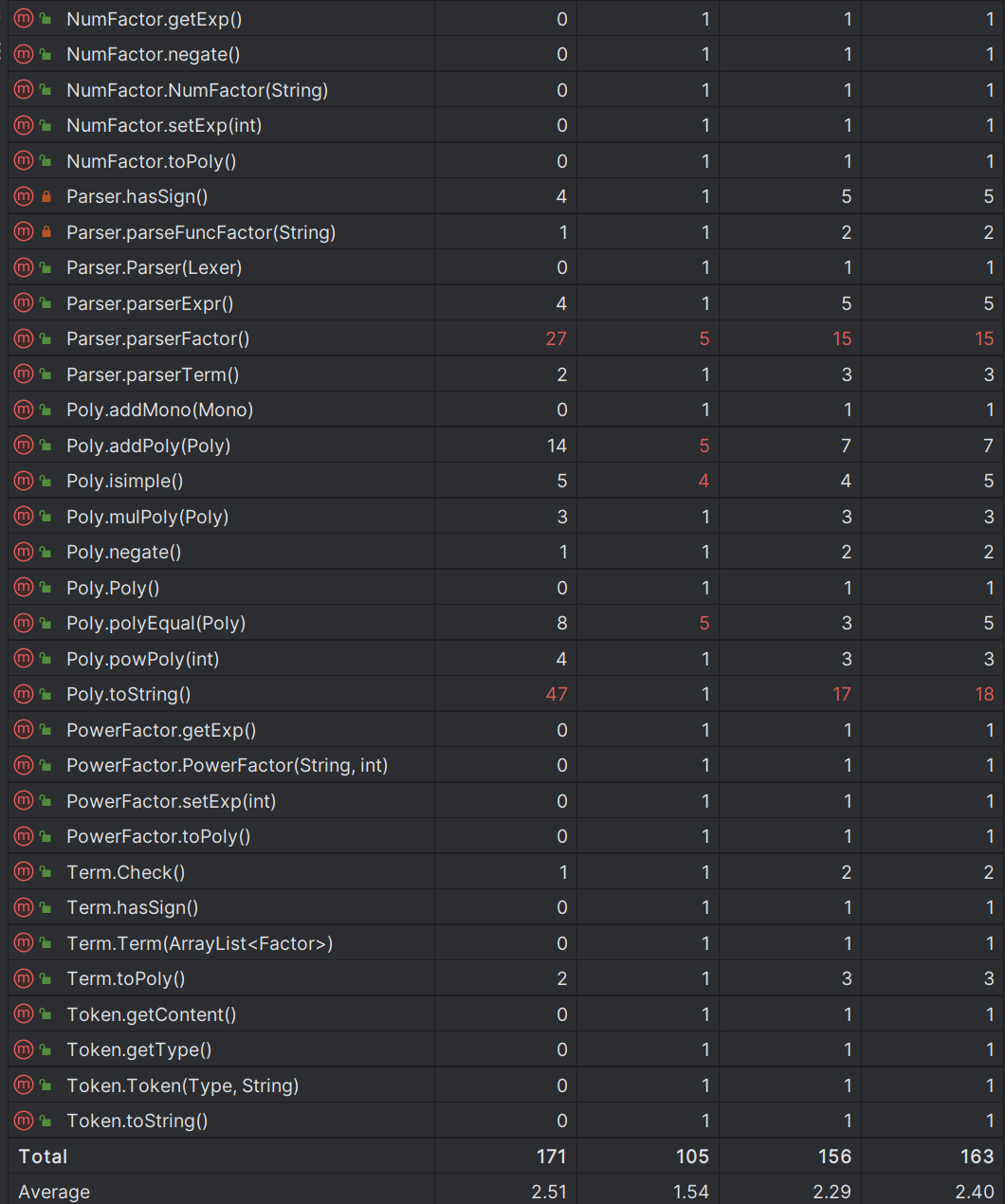
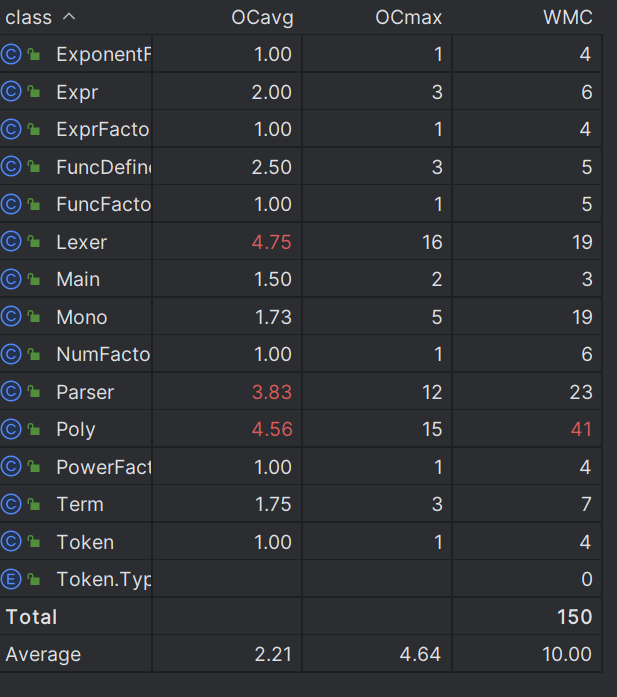
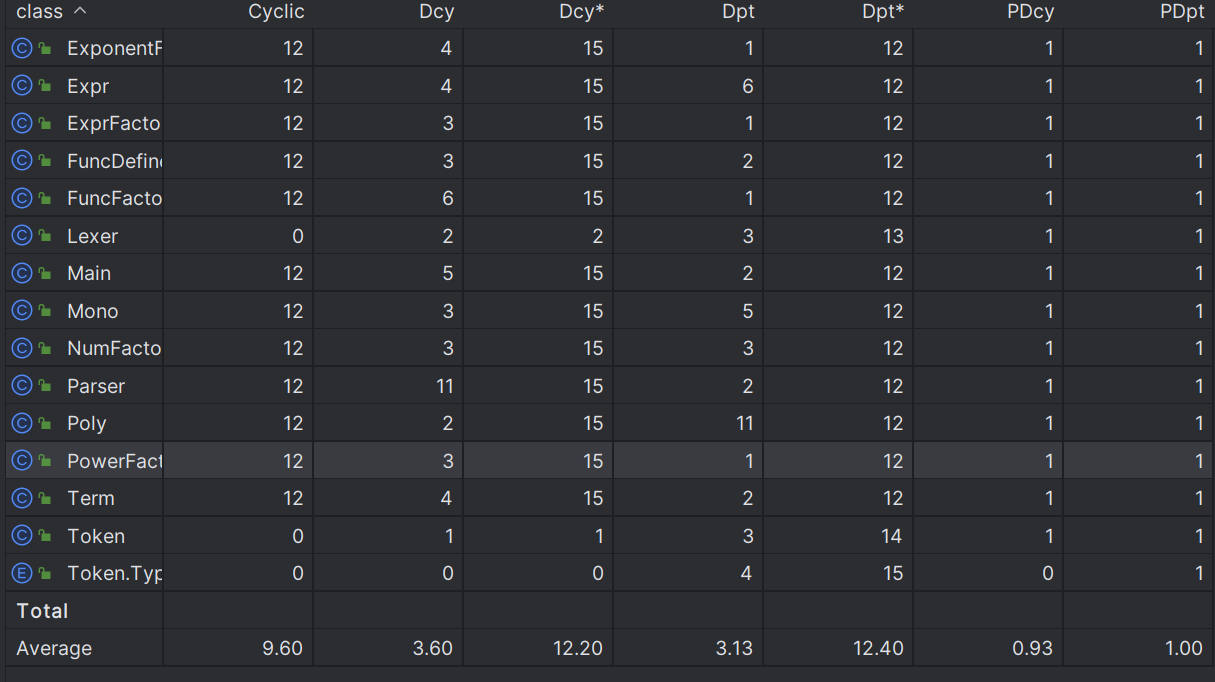
基于度量来分析自己的程序结构(基于 MatricsReloaded 插件实现)
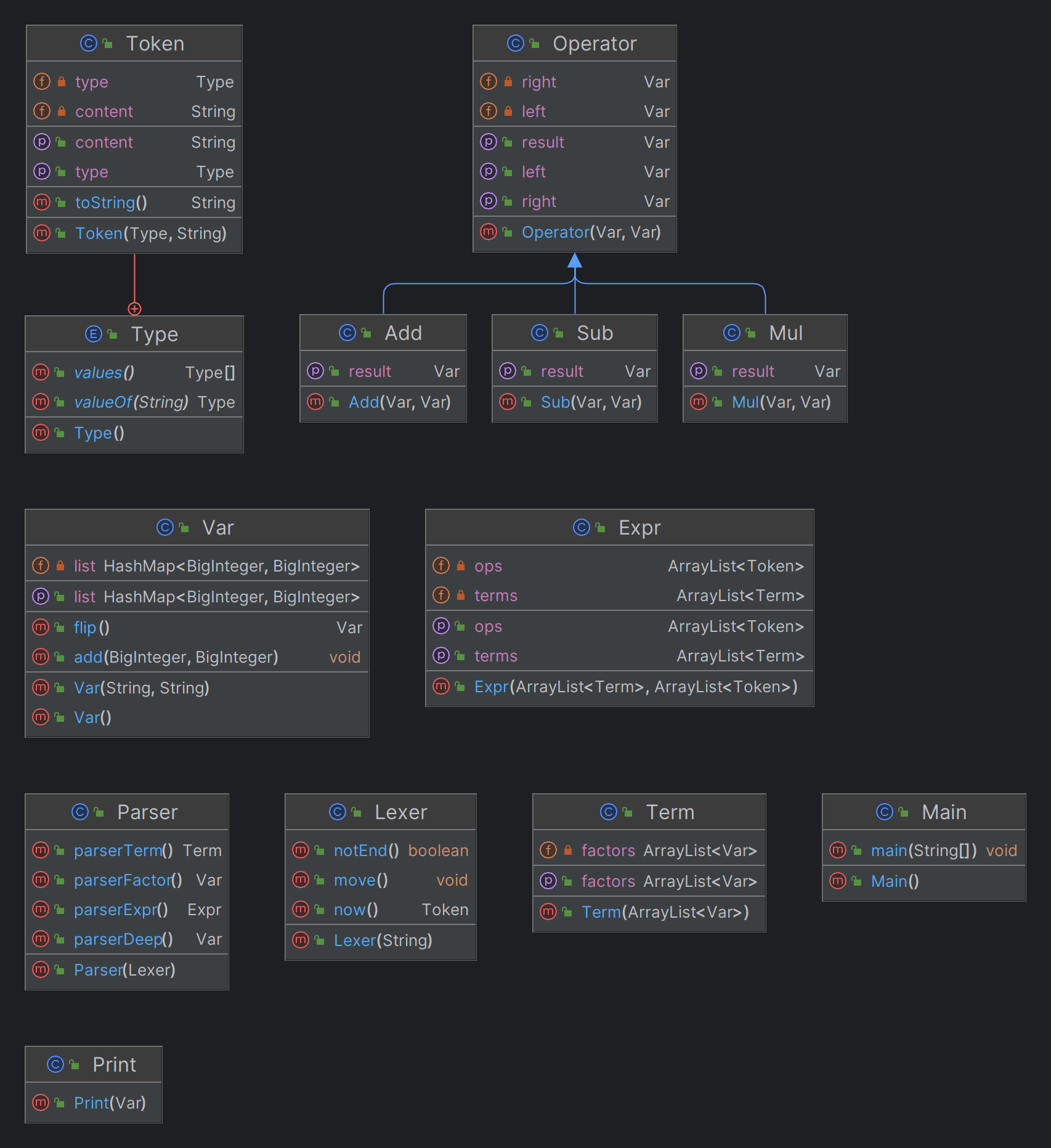
这部分我们需要使用的主要是方法和类的复杂度分析。
方法的复杂度分析主要基于循环复杂度的计算。循环复杂度是一种表示程序复杂度的软件度量,由程序流程图中的“基础路径”数量得来。
CogC 认知复杂度: 表示程序中的独立路径数目
ev(G) 基本复杂度:是用来衡量程序非结构化程度的,非结构成分降低了程序的质量,增加了代码的维护难度,使程序难于理解。因此,基本复杂度高意味着非结构化程度高,难以模块化和维护。实际上,消除了一个错误有时会引起其他的错误。
iv(G) 模块设计复杂度:设计复杂度是用来衡量模块判定结构,即模块和其他模块的调用关系。软件模块设计复杂度高意味模块耦合度高,这将导致模块难于隔离、维护和复用。模块设计复杂度是从模块流程图中移去那些不包含调用子模块的判定和循环结构后得出的圈复杂度,因此模块设计复杂度不能大于圈复杂度,通常是远小于圈复杂度。
v(G) 圈复杂度:是用来衡量一个模块判定结构的复杂程度,数量上表现为独立路径的条数,即合理的预防错误所需测试的最少路径条数,圈复杂度大说明程序代码可能质量低且难于测试和维护,经验表明,程序的可能错误和高的圈复杂度有着很大关系。
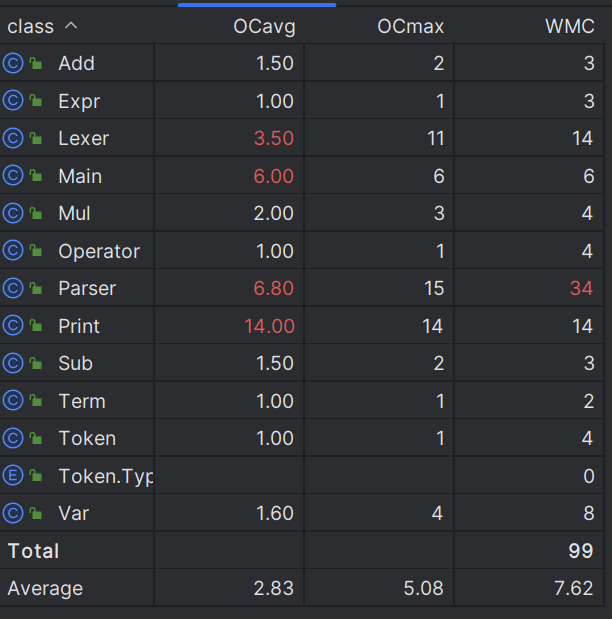
OCavg:类的方法的平均循环复杂度。
WMC:类的方法的总循环复杂度。
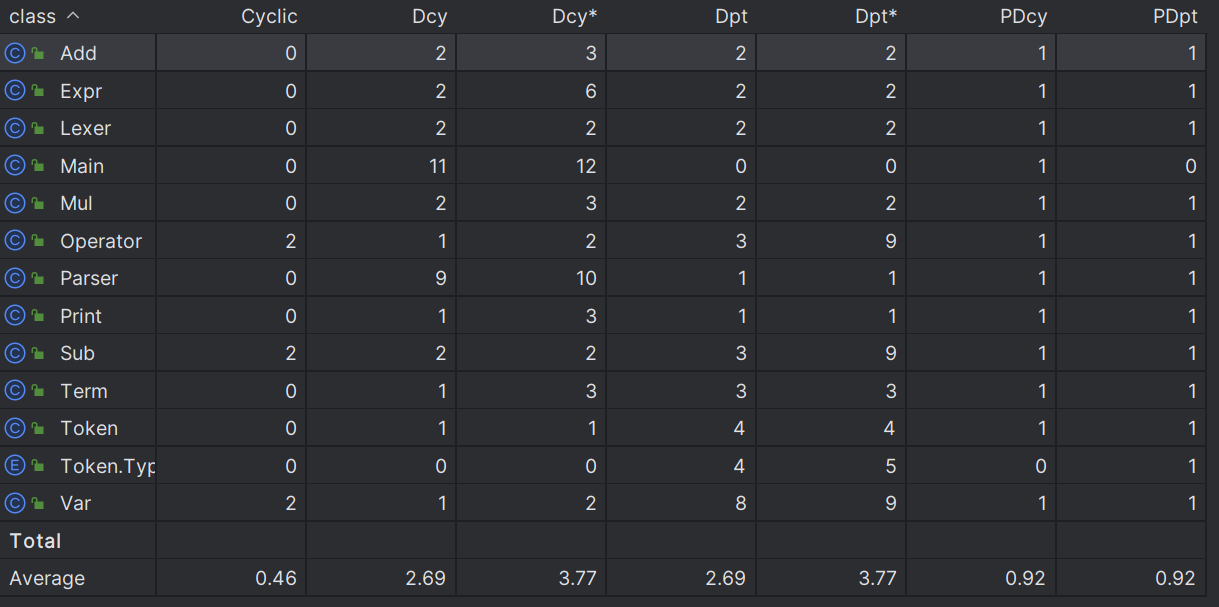
在第一次作业中,我并没有很好的领会面向对象的精神,多种类混杂在一起,类的复杂度较高,也不利于理解与后续扩展
在公众号中提供的递归下降的样例代码实现了Expr树的构造,在后续改写过程中,主要在Parser类中进行递归,每当读到括号时再次调用ParserExpr的方法使使树不断延伸,但是我为了方便将树的处理与Parser类放在一起,在每当读到括号调用ParserExpr后对树进行处理,认为此时的expr返回值所构建的树深度最大为3,进行处理
同时要说构建的Var类,因为第一次仅涉及多项式的问题,可以通过一个HashMap<>表示指数+系数的组合,因此Var可以同时储存单项式与多项式(这样简单的想法使后面的扩展变得困难,此处先按下不表)
在parserFactor的所有方法均返回Var,通过这样的递归方法也可以解决多层括号的问题
第一次的作业采取了较不成熟的写法,虽然顺利完成了第一次作业的要求,但是在第二次功能迭代时遇到了不小的问题,其中最为明显的就是存储问题。
由于第一次作业仅采取Var内的HashMap<>既充当单项式又充当多项式的功能的方法,在迭代时新增指数函数功能后,难以使用单一类存储单多项式,最开始我不太想进行重构,构造HashMap<>多层嵌套的方法来解决该问题,但是这种方式不仅繁杂、不够简洁优雅,而且单项式合并时需要同时判断X的指数与指数函数是否相等。这对于仅有一个Key值的HashMap是困难的,而若是使用嵌套HashMap实现两个Key值,效率会大打折扣,最终选择进行重构。
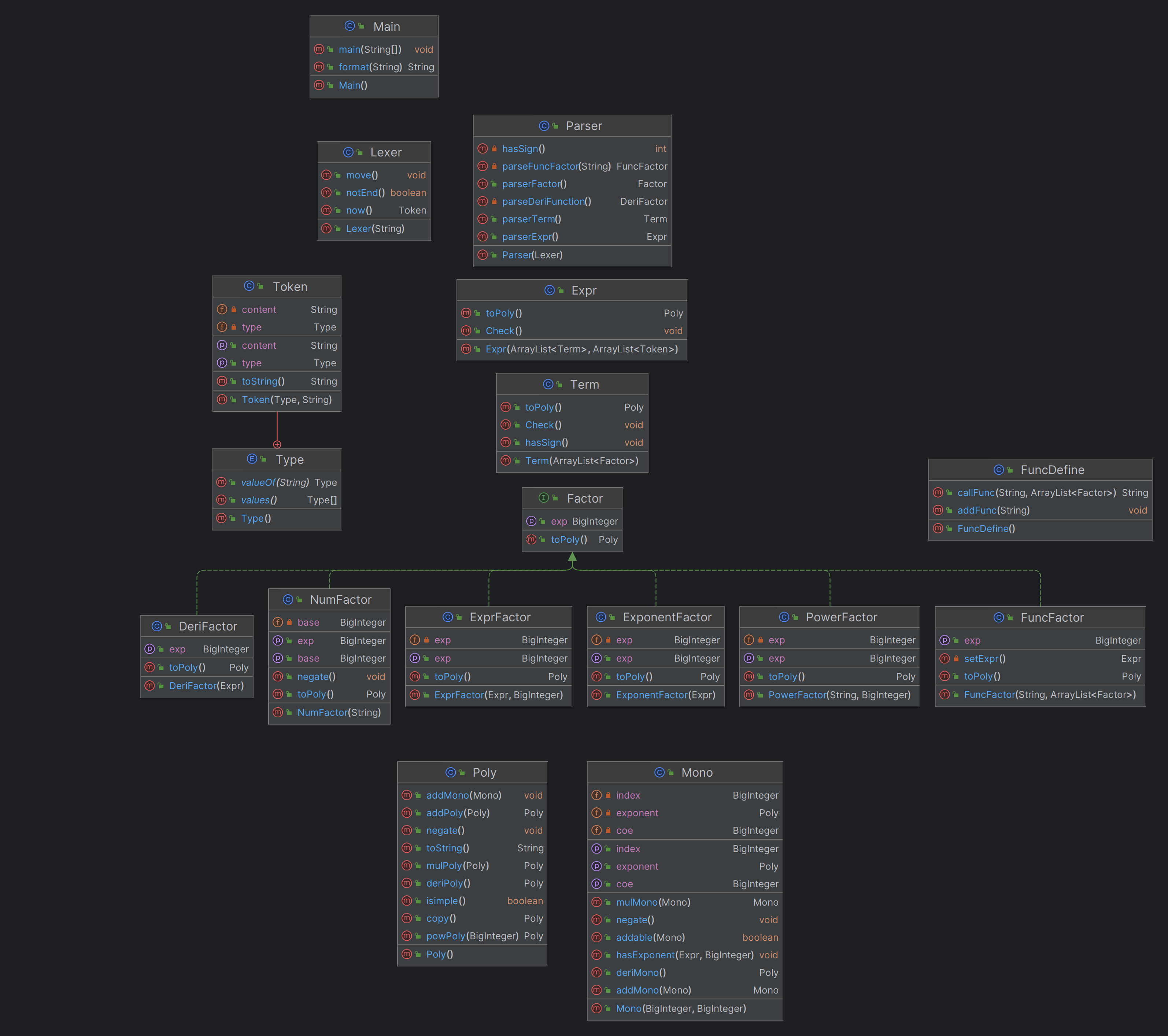
重构:
在第二次迭代中,我将单项式类(Mono)与多项式(Poly)类拆开,Parser类仅负责通过词义分析后的式子得到表达式树,将合并操作独立出来成为每个类的toPoly方法,降低了单个类内操作的复杂度。
二三次迭代新增功能可以大致分为两类,一个是在已有架构外新增功能(如:自定义函数),另一种是在已有架构内进行功能增添(例如:新增f,g,h,exp与dx)
迭代前后的代码对架构外功能的增添并没有什么不同,但是在架构内新增的功能在两种代码中有明显不同,明显迭代后可扩展性更优,新增因子类型仅需改变Mono类(单项式)的内变量与完善方法,对于整体Parser、Poly的解析合并没有很大影响。
这里借鉴往年OO第一章的要求:增加三角函数(函数内为一个因子)
原Mono类:
//Mono.java
public class Mono {
private BigInteger coe;
private int index;
private Poly exponent;
}
加入三角函数后,Mono修改为:
//Mono.java
public class Mono {
private BigInteger coe;
private int index;
private Poly exponent;
private ArrayList<Poly> sin;
private ArrayList<Poly> cos;
}
我们需要新建sinFactor与cosFactor两个类,每个包含一个ArrayList base列表
需要实现Factor接口的一系列方法,toPoly类写法如下:
@Override
public Poly toPoly() {
Poly poly = new Poly();
Mono mono = new Mono(BigInteger.ONE, 0);
mono.addSin(this.base);
poly.addMono(mono);
return poly;
}
在不考虑进一步优化的情况下,Mono加法判断条件新增判断sin 与 cos是否相等,乘法仅需将单项式的sin/cos加入列表
当考虑到求导操作(dx)时,将sin -> cos cos -> -sin 也不复杂
下面仅需稍微修改Token与语义分析的部分,Parser部分加入三角函数的读入操作即可架构清晰的初步实现该功能。
当然如果出现sinA * sinA或 sinA* cosA 等情况下,我们为了简化结果想要将两项进行合并,这部分就变得复杂起来,当然对于任何代码,优化的部分都是需要随着要求的增加而不断变化的,复杂的分析是不可避免的。
第一次作业中没有出现明显Bug,问题仅为在前文中的分析过的类内较为复杂,可扩展性较差,在强测中稍有扣分(0.4分左右),根源在于(x-1)与(-1+x)两个式子是长度不同的,而我的输出默认是按照指数上升的排列进行输出的,导致第一项并不总是正的,略有失分,当然我对这里略有微词,这里在后面的意见部分会再次提到。
第二次作业问题主要有两个,一个是我使用int类型来存储指数类型,但是在第二次作业强测部分出现指数巨大(爆int)的数据导致错误,另一个是exp()内若是整数因子或是变量因子则仅需要一层括号,否则需要两侧括号,我再该部分判断内容时对题意理解不清,写成单项式一层括号而多项式双层括号,若exp内为:
$$
1x^2exp(2)
$$
显然按照题意需要双层但是按我的写法却成了单层括号。
第三次作业中也并没有发现出现Bug。
在三次写代码的过程中也出现了一些Bug,大多出现在递归过程中,具体包含深浅拷贝的区分使用与空列表额判断分析,这些问题也集中出现在第二次代码写作中,而第三次基本没有出现问题顺利完成。
据此分析,我认为这些问题的原因一个是对java语言特性了解不深,另一个更重要的是对代码的熟悉程度,第二次时在摸索中写代码,对代码难免顾此失彼没办法同时顾及到所有代码,这时候就需要良好的命名风格与写作方法,在第二次迭代中我遇到的一个问题就是:有的方法是通过返回值返回结果,而有的是在原传入的实例上进行修改,没有返回值。因此一定要养成统一的写作风格,避免出现每次操作误改需要多次使用的源数据的问题。
在着手写代码时可以仿照类图梳理思路,统一方法命名,思路清晰的进行写作,而不是在写作过程中缝缝补补,代码冗杂混乱。
出现了bug的方法相较未出现bug的方法在往往行数更多,复杂度更高,原因是显然的,类内越复杂,逻辑越难以明晰,细节要求更多,我们应当适当提取方法,用规范命名的方法代替直接暴露出来的代码,这样既能提高代码的可读性,看到方法名就能明白操作的内容,也能使逻辑更加清晰易于分析。
一般是先使用评测机构造大量数据测试程序,当找到出现的Bug时,再分析出现问题的数据,将多余的部分不断简化,同时用简化数据测试,保证该数据仍能发现错误,最终得到一个简洁的短数据,这时候一般能直接找到出现问题的原因啦。
除此之外,在互测中也可以通过查看代码的具体架构构造数据,如果代码是通过展开连乘来解决的指数问题,那么大指数数据大概率会导致其程序TLE,如果代码没有清晰的分类,代码内重复代码较多,单个类负责多个功能,那么多层次的括号数据也许能找到其递归上的问题
我的优化过程是在得出结果后再进行操作的,以此来保证较高的正确性,避免因为优化的问题影响过程,不仅更易出现错误还难以发现,
我的优化较为简单,仅完成了相同项的合并,exp内括号的分析,前导0的去除,x^0/exp(0)替换为1的操作,对于更复杂的exp提取公因数,没有过多的考虑 /(ㄒoㄒ)/~~
本次一单元OO课程号称最难的一部分,平稳落地,还是很开心的。
原以为上过OOpre的课程就算是入门了面向对象,第一单元告诉我我还很嫩,从第二次作业的重构我才明白什么是面向对象,之前写的代码一直是繁杂不够简洁的,面向对象是模型化的,不是根据要求流程来实现,而是将主体分隔开,从老师举得例子来看,我去图书馆借书,读者是一个类,书是一个类,这样的划分是问题的开始,而不能先开始就写借书的操作,除此之外,面向对象还需要隐藏对象的属性和实现细节,仅对外提供公共访问方式,简单来说就是,你去吃饭就只能点做好了的菜,菜单上不会写着一道菜让顾客今后厨自己来做。通过面向对象的思路解决面向对象课程提出的问题让人愉悦,成品的代码显得结构清晰,逻辑严谨,开始有一点代码美了。
虽然,第二次作业重构的时候很痛苦,感觉OO这门课真的烂,但是走过这第一单元感觉收获满满,之前吃的苦也许是值得的。
课程组和助教都尽心尽力,第一单元总体上难度较大,第一次作业有了公众号思路与样例代码大部分人都是平稳落地,第二次作业难度就升高许多,我认为这方面可以再优化一下,避免给同学们带来强烈的压力与不适感,可以再提供一些思路的引导,便于大家完成作业。除此之外,互测的设计我觉得是OO课程的点睛之笔,但是个人认为还是有一定问题,主要是提交数据不够方便,一些复杂数据会显示为格式错误,提交间隔也有些长,希望能适当缩短一点。



