



301
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享在第一单元中,我们使用java实现了表达式的括号展开与化简。在三次的迭代开发中,我们熟悉了面向对象的思想,初步体会了层次化设计的思想的应用和工程实现。三次作业的内容包括——
每次的作业都是不小的挑战,但同时也提供了不可多得的练习机会。如今第一单元结束,借这次的博客总结,现将本人三次作业的代码架构进行详细讲解,并记录本人的学习体会心得。
第一次作业的要求是通过对数学意义上的表达式结构进行建模,完成单变量多项式的括号展开:
读入一个包含加、减、乘、乘方以及括号(其中括号的深度至多为 1 层)的单变量表达式,输出恒等变形展开所有括号后的表达式。
从题目中,我们很容易看出表达式是由不同类型的部分组成的,包括常数、自变量、幂函数等因子,由*连接起来的因子即为一个项,而几个项之间的加减即为表达式。
特殊的是由()包括的表达式部分,也可看做因子,作为组成项的部分。根据面向对象的思想,我们可以建立相关的类来处理不同种的表达式部分,并形成表达式树的关系。我注意到幂函数类(包含系数,指数)可以同时包括常数项(指数为0)和自变量(指数为1),于是合并常数、自变量、幂函数为一个Pow类,将所有因子统一,同时将+ -符号下放到Pow的系数中,简化了代码实现,对之后的化简处理更有利。然后分别实现储存和处理表达式、项的类Expr、Term,并都以Factor作为接口。表达式树的关系如下图所示。
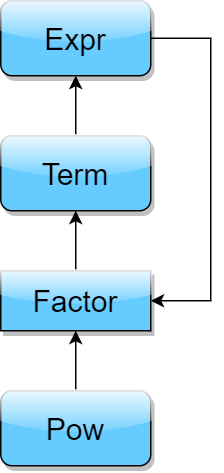
接下来分析如何处理读入的表达式字符串,首先要进行预处理,用正则表达式去除字符串内的空白字符。然后,我们可以使用正则表达式拆分读入的字符串,分解成常数、自变量、运算符等不同类型的字符,也可以使用递归下降法分析。由于正则表达式分析对于表达式因子的实现比较麻烦,同时拓展性较差,在未来两次的作业迭代中很可能需要大改,甚至重构,于是我选择了递归下降法分析,并借鉴了课题组提供的第一单元训练中的结构,去实现Lexer,Pasrser类,前者用于读取表达式字符串的语法单元并转化为token,如+,*等运算符、123,x等因子和标志进入表达式因子的(等,后者负责将Lexer分析出的token存储到我所实现的Expr类中,基于递归下降的思想,形成树形的储存结构。
最后是化简储存好的表达式并输出,为了尽可能减少输出的字符串长度(卷性能分),需要涉及到合并同类项和特殊情况的化简。
代码架构的UML类图与类的解释如下:
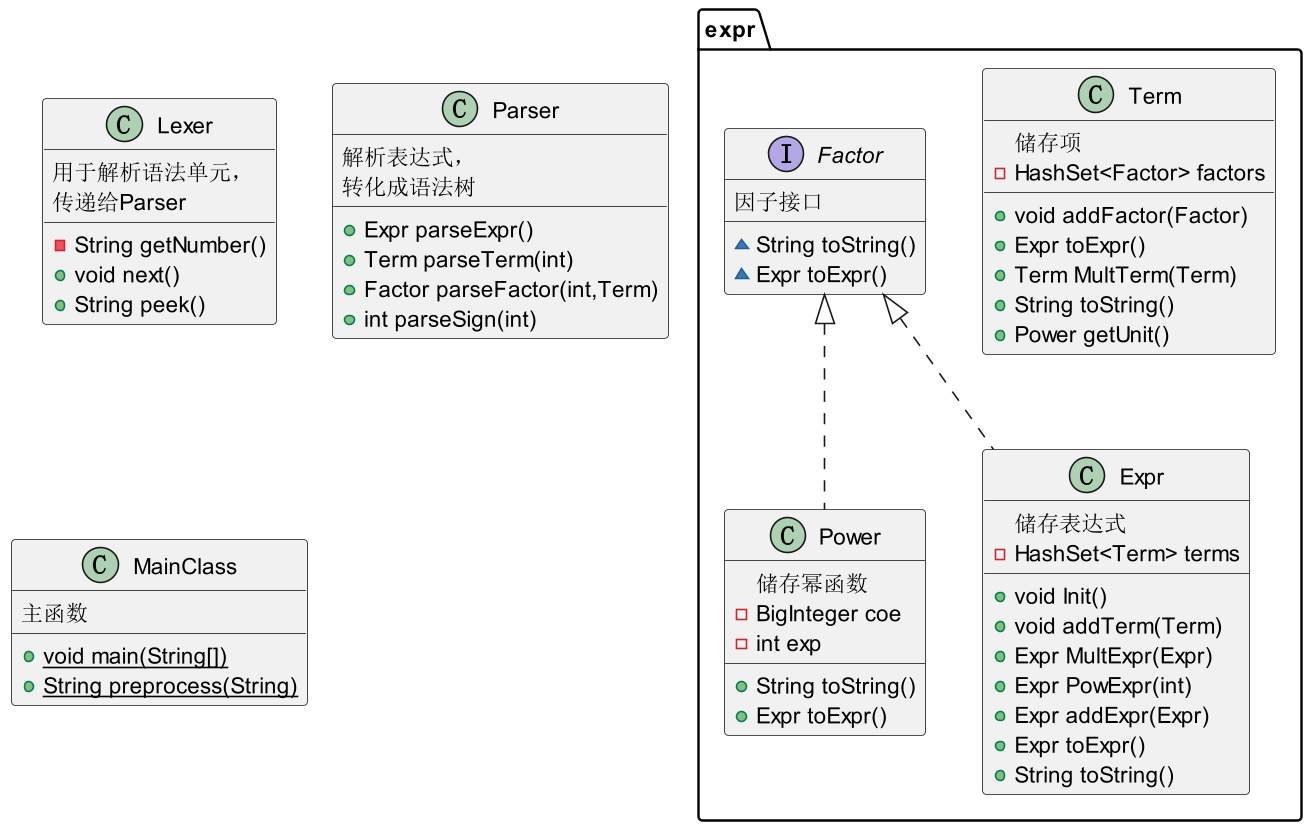
Lexer
在本次作业中,表达式的基本语法单元的类型有数字,变量,运算符和括号,我们在Lexer中判断这些语法单元并使用curToken存下来,在Parser中使用。代码如下:
char c = input.charAt(pos);
if (Character.isDigit(c)) {
curToken = getNumber();
} else if (c == '+' || c == '-' || c == '*' || c == '(' ||
c == ')' || c == '^' || c == 'x') {
pos += 1;
curToken = String.valueOf(c);
} else {
throw new RuntimeException("Unexpected character: " + c);
}
将表达式中所有语法单元都解析出来,就轮到Parser发挥作用了
Parser
Parser类中将表达式的解析分成了三部分——parseExpr, parseTerm, parseFactor,每一部分的解析都遵循形式化文法。
由于Term前可以带符号,于是添加parseSign对可能的符号先做解析,若为负号则向Term中多乘一个-1,将符号的处理转化成Term内数字的相乘。
以parseExpr为例,因为第一项之前可能带有符号,于是我们就先将符号(+或者-)解析出来,然后解析第1项。解析完第1项后,我们就可以直接使用while循环对后面的项依次进行解析。代码如下:
public Expr parseExpr() {
int sign = parseSign(1);
Expr expr = new Expr();
expr.addTerm(parseTerm(sign));
while (lexer.peek().equals("+") || lexer.peek().equals("-")) {
sign = parseSign(1);
expr.addTerm(parseTerm(sign));
}
return expr;
}
parseTerm和parseFactor也是同理,并注意在parseFactor中读到(是,递归调用parseExpr,这样就把含括号的表达式解析出来了。
不难发现,本次作业中的Term,如果不含表达式因子,就可以最终化简成coe * x^{exp},也就是将所有常数相乘,变量的指数相加。于是给Power类中添加储存系数(coe)和指数(exp)的变量用来储存。可是含表达式因子的Term就没那么容易搞定了,最终一定是化简成Expr的形式。为了能统一方法,降低代码量与复杂度,我决定给Expr、Term、Power都实现toExpr方法,作为Factor的抽象方法。在转化成Expr的同时做化简,包括合并同类项等等。这样一来,Term就最终化简成含有一个或多个形如coe * x^{exp} Power对象的Expr。最终,只要给解析出来的Expr调用toExpr方法,在其中递归调用Term、Factor的toExpr方法,将Term中的Factor相乘,将Expr中的Term相加,就能获取最终的化简表达式。
//Expr.java
public Expr toExpr() {
for (Term term : this.terms) {
//先调每个term的toExpr,再调用addExpr
}
}
public Expr addExpr(Expr expr) {
//this和expr的exp相同的项合并
}
//Term.java
public Expr toExpr() {
for (Factor factor : this.factors) {
//先调每个factor的toExpr,再调用MultExpr
}
}
public Term MultTerm(Term term) {
//系数相乘,指数相加
}
//Power.java
public Expr toExpr() {
Expr expr = new Expr();
expr.addTerm(new Term(this));
return expr;
}
获得最简的Expr结构后,就是调用toString()转化成字符串的时候了,这个环节比较简单,只需要注意几个化简的地方:
0,则最终结果为0,1,则可以省略系数,简化为x^n-1,则可以省略系数,简化为-x^n0,则可以省略x^0,简化为a1,则指数部分可以省略,简化为a*x-方法复杂度:
| method | CogC | ev(G) | iv(G) | v(G) |
|---|---|---|---|---|
| Parser.parseFactor(int, Term) | 23.0 | 5.0 | 13.0 | 13.0 |
| expr.Power.toString() | 14.0 | 10.0 | 6.0 | 10.0 |
| expr.Expr.toString() | 11.0 | 4.0 | 7.0 | 8.0 |
| expr.Expr.addExpr(Expr) | 9.0 | 1.0 | 6.0 | 6.0 |
| Lexer.next() | 5.0 | 4.0 | 3.0 | 10.0 |
| expr.Expr.MultExpr(Expr) | 3.0 | 1.0 | 3.0 | 3.0 |
| Lexer.getNumber() | 2.0 | 1.0 | 3.0 | 3.0 |
利用MetricsReload工具分析方法复杂度,我发现parserFactor的复杂度较高,这是因为我将所有因子的解析都写在此方法中。为了降低复杂度,在第二次作业迭代时,我将每种因子的解析分别实现方法,在parserFactor进行调用。
无,人均满分。
第二次作业的要求是通过对数学意义上的表达式结构进行建模,完成多项式的括号展开与函数调用、化简:
读入一系列自定义函数的定义以及一个包含幂函数、指数函数、自定义函数调用的表达式,输出恒等变形展开所有括号后的表达式。
第二次作业在第一次的基础上增加了自定义函数和指数函数,并支持了多层括号。相比于第一次作业,第二次作业的难度提升十分明显,不但允许了嵌套,还有自定义函数,大大增加了数据的复杂度,也让性能分的获取变得十分具有挑战性。由于第一次作业采用的梯度下降法自然支持多层括号嵌套,我将本次作业拆分成了两部分,分别设计其实现,并分别测试其正确性。
考虑到自定义函数中也会出现指数函数,为防止潜在的bug(如替换x时把exp中的x也替换了),我先实现指数函数,进行充分测试,确保正确后,再实现自定义函数。
第一次作业中,我们把Term化简成了由n个Pow类组成的Expr,Pow形如coe * x^{exp},而本次作业新增了指数函数,那么最终Term会化简成了由n个形如coe * x^{exp}*exp(Factor)的形式。这种情况下,第一次采用的方法就不适用了,可以用新的类Unit代替第一次作业中的Pow,实现类似的储存效果。
得益于递归下降法的可扩展性,Laxer和Parser的部分比较简单,逻辑上就是读到'exp'后就进入parserExp,再调用parserExpr,将得到的Expr存入ExpFunc对象,如果是exp(Expr)^n就化简成exp(n*Expr)。
实现自定义函数,可以建立一个类来集中处理,用于储存函数的形参和函数体,并实现函数读取、替换的方法。我采用字符串替换的方法,对输入的字符串进行预处理,处理结束后保证没有自定义函数再调用已经实现的解析函数,降低耦合度。
代码架构的UML类图与类的解释如下:
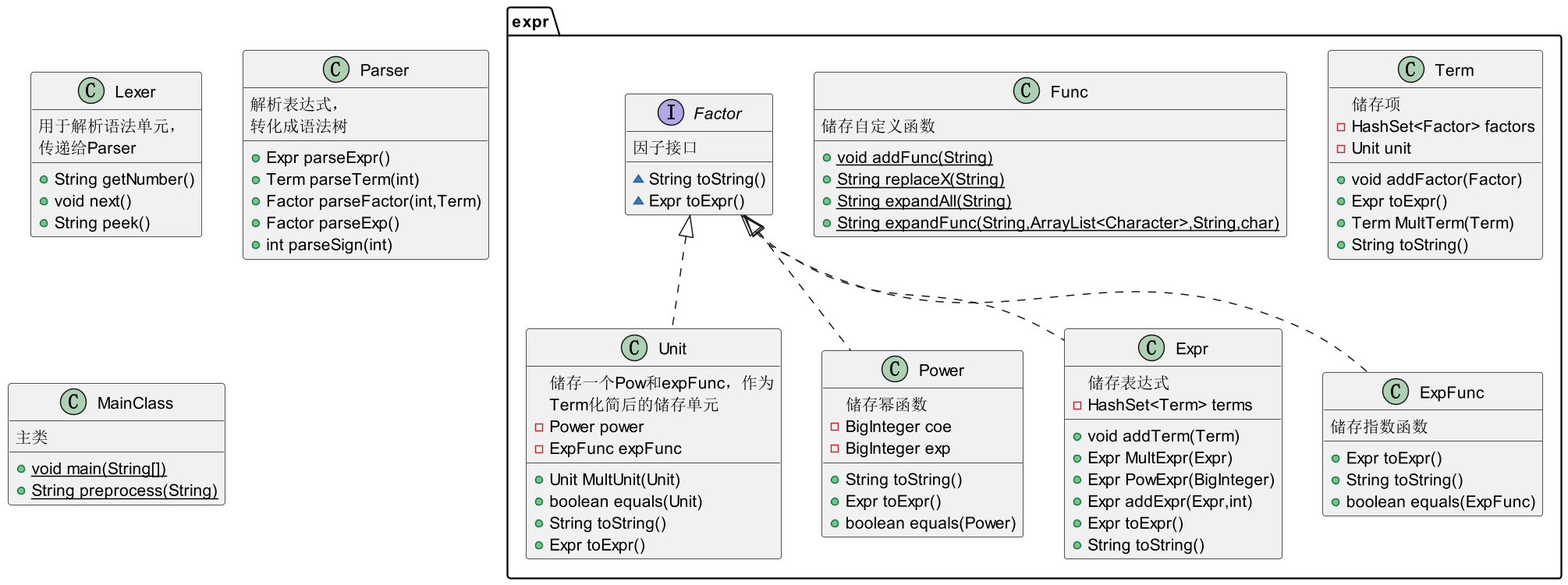
ExpFunc
新增ExpFunc类,用于储存exp(Factor),为了方便调用方法,我直接用Expr储存指数部分。由于第一次已经定下了整体架构,ExpFunc也实现Factor接口的toString和toExpr方法,统一所有Factor为Expr再化简,这样就能沿用第一次作业的化简方法。
// ExpFunc.java
public Expr toExpr() {
ExpFunc expFunc = new ExpFunc(base.toExpr());
Expr expr = new Expr();
expr.addTerm(new Term(expFunc));
return expr;
}
Unit
新增Unit类,储存一个Pow和一个ExpFunc,这样Unit类的作用就类似第一次作业中的Pow,可以储存不含表达式因子的化简后的Term。在第一次作业中,toExpr是化简的方法,在Term.toExpr()中会把每个因子相乘化简出来的结果用一个Pow储存,本次作业就需要使用Unit储存。同时,需要让Expr.MultExpr()支持指数函数相乘,也就是对两个指数调用Expr.addExpr()。
化简
为了合并同类项,在Expr.addExpr()中需要判断每个Term化简后unit的x的指数和exp的指数是否相同,x的指数很好比较,但是exp的指数是Expr,很难用常规的方法比较。我联想到Expr.addExpr()就是将相同的项合并,也就是系数相加,那就可以反其道而行之,将相同的项系数相减,如果最后项都消完了,就说明两个Expr相同。于是修改Expr.addExpr(),增加系数相减的功能,在Unit类内实现equals方法。
// ExpFunc.java
public boolean equals(ExpFunc expFunc) {
Expr expr = this.exp.toExpr().addExpr(expFunc.exp.toExpr(), -1);
return expr.getTerms().isEmpty();
}
// Expr.java
public Expr addExpr(Expr expr, int sign) {
Expr result = new Expr();
ArrayList<Unit> units = new ArrayList<>();
for (Term term : this.terms) {
//调用unit的equals方法,当sign=1合并相等的项,sign=-1则相消
}
for (Term term : expr.terms) {
//调用unit的equals方法,当sign=1合并相等的项,sign=-1则相消
}
for (Unit unit : units) {
//相当于删除系数为零的项
if (unit.isZero()) {
continue;
}
Term term = new Term(unit);
result.addTerm(term);
}
return result;
}
toString也可以对一些特殊情况进行化简:
0,则最终结果为1,exp(Factor)exp((a*x))化简成exp(x)^a可以节省两个字符,可以判断如果是这种形式的指数,就把指数提出来Func
读入函数的方法很简单,不多赘述。替换函数也较为简单,依次读取传入的字符串,如果读取到f g h,就按,分出每个实参,然后按顺序对应替换函数体内的形参。需要注意的点就是字符串替换要注意exp中的x不能替换,我选择将x都换成#(特殊字符),这样就不会和exp产生冲突。
| method | CogC | ev(G) | iv(G) | v(G) |
|---|---|---|---|---|
| expr.Expr.addExpr(Expr, int) | 19.0 | 9.0 | 10.0 | 11.0 |
| expr.Func.expandFunc(String, ArrayList, String, char) | 17.0 | 6.0 | 9.0 | 9.0 |
| expr.ExpFunc.toString() | 16.0 | 6.0 | 9.0 | 9.0 |
| expr.Power.toString() | 14.0 | 10.0 | 8.0 | 10.0 |
| expr.Func.addFunc(String) | 13.0 | 1.0 | 5.0 | 11.0 |
| Parser.parseFactor(int, Term) | 12.0 | 6.0 | 10.0 | 10.0 |
| expr.Expr.toString() | 11.0 | 4.0 | 7.0 | 8.0 |
利用MetricsReload工具,我发现addFunc方法复杂度较高,因为要判断同类项,并且为了同类项相减复用了这个方法,使得其复杂度提升。expandFunc方法则是要读取实参,并把形参替换,可以把这两部分拆成两个方法。
第二次作业中,我的代码出现了bug,就是类似exp((-x^2))化简成了exp(-x^2),忽视了因子前面不可带符号的文法规定。由于我直接将exp的指数用Expr储存,无法直接判断是否是表达式因子,在输出判断时简单的将仅有一个项且不带*的表达式当作非表达式因子,忽略了在先前的输出优化时将-1*x优化成了-x,导致出现缺少括号的情况。再加上对-的特判即可修复,但是很不优雅,更好的做法还是在转成字符串前先判断是不是表达式因子。
事实证明,化简有风险,优化需谨慎
hack出来别人的bug也有我犯的这个错误,以及指数函数的0次方的处理出现bug。
第三次作业的要求是通过对数学意义上的表达式结构进行建模,完成多项式的括号展开与函数调用、化简:
读入一系列自定义函数的定义以及一个包含幂函数、指数函数、自定义函数调用、求导算子的表达式,输出恒等变形展开所有括号后的表达式。
第三次作业增加了求导算子,并支持了自定义函数的嵌套。实验课上给了我们一定的参考,加上要求比较简单,本次作业的工作量不大:
求导算子不算因子,而是一种运算,所以其实现具有低耦合度的特点。其可以分解成dx+表达式因子。只要在Laxer中添加dx的token,在Parser中利用ParserExpr先读进来dx()中的表达式,再对所有Factor实现求导方法,按照求导的法则,如链式法则、乘法法则等实现即可。
自定义函数嵌套也完全可以沿用已实现的方法,即在读入函数后对函数进行一次预处理,将每个函数体当作一串表达式,调用替换函数的方法即可将函数之间的调用全部展开。
代码架构的UML类图与类的解释如下:
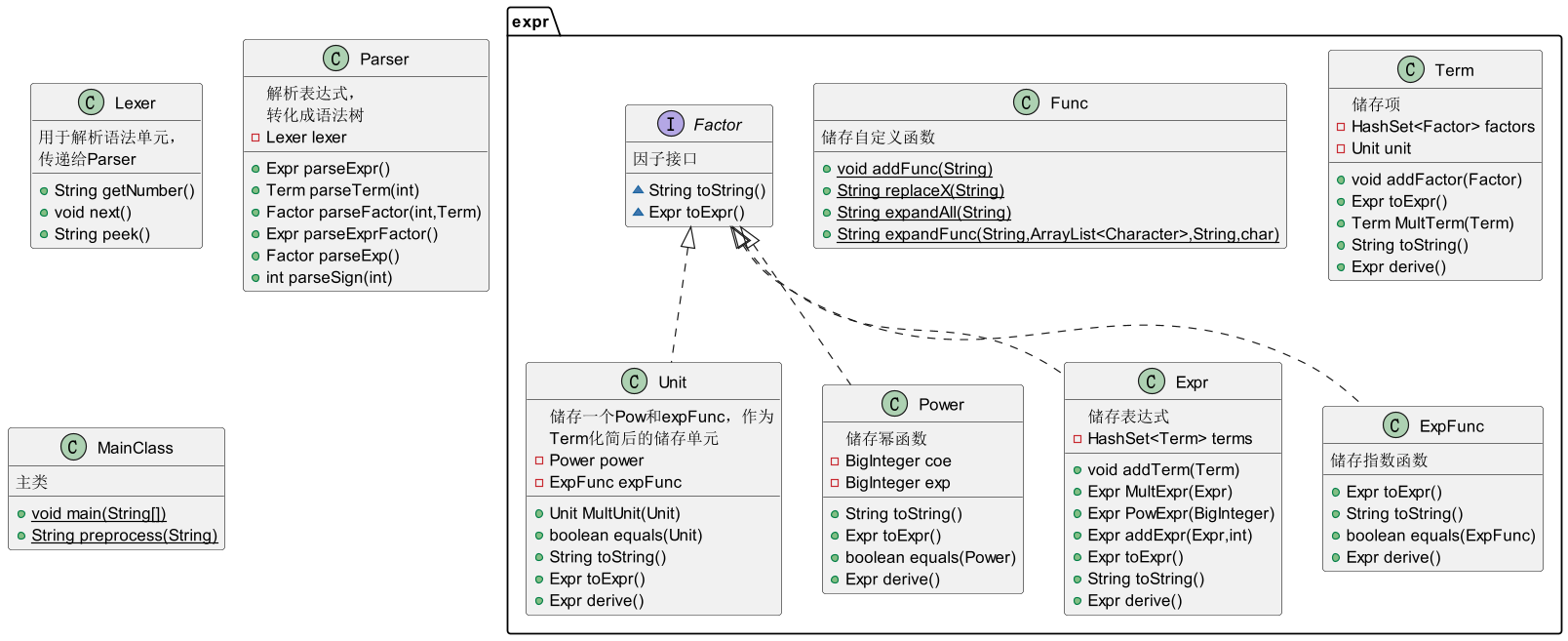
本次的代码修改量较少,且没有建新的类,整体与第二次作业差异较小。
无新增类,在Parser中调解析表达式因子的方法,化简后求导,最后返回。
// Parser.java
...
} else if (lexer.peek().equals("dx")) {
Expr expr = parseExprFactor();
expr = expr.toExpr();
expr = expr.derive();
return expr;
}
求导方法derive()的实现非常简单,因为表达式已经经过化简,每一项都化成了一个Unit:coe * x^{exp}*exp(Factor),只要求导变成coe*exp* x^{exp-1} *exp(Factor)+coe*dx(Factor)* x^{exp} *exp(Factor)
即可,其中要对Factor再调一次求导,递归调用
直接把函数体里的其他函数替换即可
public static String expandAll(String input) {
if (fFunc != null) {
fFunc = expandFunc(fFunc, gVars, gFunc, 'g');
fFunc = expandFunc(fFunc, hVars, hFunc, 'h');
input = expandFunc(input, fVars, fFunc, 'f');
}
// g,h同理
return input;
}
由于本次作业量比较小,就不分析太多了
在第三次作业中,由于我是一次替换一个形参,所以自定义函数的替换出现了BUG,如: 2; f(y,z)=y+2*z; g(z,y)=f(z,y); g(1,2)
在g(z,y)展开时先把形参y换成实参z,变成z+2*z,然后把形参z换成实参y,变成z+2*z,就出现了问题。这个bug是第二次埋下的隐患,只不过第二次作业实参只会有x,而x被换成了#,就没有体现出这个bug,这也跟我第三次作业写的太快,测试太少有关。修复这个bug也很简单,先把所有形参替换成特殊符号(如A、B、C),再去换成实参。
良好的架构为迭代带来了诸多优势,让我印象深刻的就是第三次作业实现完全按原有的架构展开,实现十分清晰,在短时间内就完成了要求(虽然出bug了,但是也算是第二次埋的坑)。递归下降法递归调用的方法完美契合了要求,否则只是人脑解析那些嵌套了一层层的表达式都会CPU烧了。
递归下降法在新增因子的扩展性很好,只需要添加部分代码即可,如果未来需要增加新因子,直接在Parser里加一个判断,然后新实现一个相关的类。同时,新增运算也只需沿用原来的解析方法,再添加对于的计算方法即可,如果未来需要增加新运算,也是在Parser里加一个判断,给所有可能的类增加该运算相关的实现。
事实证明,递归下降法很好的完成了它的使命,没有让我重构过代码,感谢课程组一开始的实验题就把递归下降的架构给了出来,赞美课程组。
同时,我将所有Factor都转化为Expr再进行合并和化简也让我轻松不少,统一格式之后就更好进行处理,如两个Factor相加,直接转Expr然后调addExpr。当我需要Factor实现什么方法时,就无脑全实现,并按照实际的类去层层调用。
一是可以用评测机去尝试测出别人的bug,这种数据的特点就是完全随机,指不定哪个数据就碰到bug了。问题是写的不好过不了互测的要求(
二是使用自己开发时试过的数据,特别是测出自己bug的数据,这种数据的特点是疯狂试探边界条件,如((2)^8)^8,exp(exp(exp(exp(exp(exp(exp(exp(x))))))))。但是容易因为没想到某个要点而错过hack成功的机会。
基本上就是常规的输出优化,顺便做了一个减少括号的特判。
在实现第二次作业时,群里出现了一个巨大数据,而我的程序无法运行。为了优化,我进行了很多剪枝优化,如0*(一堆东西),理论上后面的都不用解析了,就是0。再如(一堆东西)^0,是1。此外,我将指数函数的次方处理做了优化(exp(一堆东西)^n),本来我秉着能复用就复用的心态,是有几次方就调addExpr加几次,但是addExpr需要合并同类项,要比较很多东西,导致很慢,所以改成直接把n乘到括号里,快了不少。
我的优化比较难保证准确性和简洁性,毕竟性能和优雅难以兼得,长度方面的特判就要写一坨的if-else,很不简洁。优化后也可能出现bug,不过毕竟优化前的版本肯定是正确的,只要优化的范围不大,debug还是比较容易的。
OO课程的难度还是不低的,相较于过去所写的代码,OO的作业算是在写一个较大的项目了,这对个人的技术要求不低。我平均每次作业都要花上6-7小时左右的时间,但也积累了很多经验。以往写的代码量少,没什么架构,能跑就完了,现在写项目,对好架构的需求就很大了,否则重构就是家常便饭。同时我也意识到写代码前一定要深思熟虑,构思好再写,否则人和代码总得跑一个,人和学分总得没一个。
OO的互测也让人印象深刻,当发现自己有bug时的懊恼不解,到发现某地方犯蠢,属实是不可多得的体验。
这一单元整体质量很好,让人感受到了写OO的快乐,实打实提升了个人的OO能力。三次作业循序渐进,不过第三次作业确实有点简单了,希望加大力度,当然也可能是考虑到希望一些人能花时间填前面的坑,让通过的人数更多。
然后就是希望性能分不单单以输出长度为指标,也可以从时长来评判,毕竟处理的速度更快也是代码优化得好的体现。为了不增加负担,可以作为加分项,比如额外设立几个大数据点,用时时长短的可以补一点因为强测所失的分,对于大佬可以作为救场的方向。



