


301
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享类复杂度
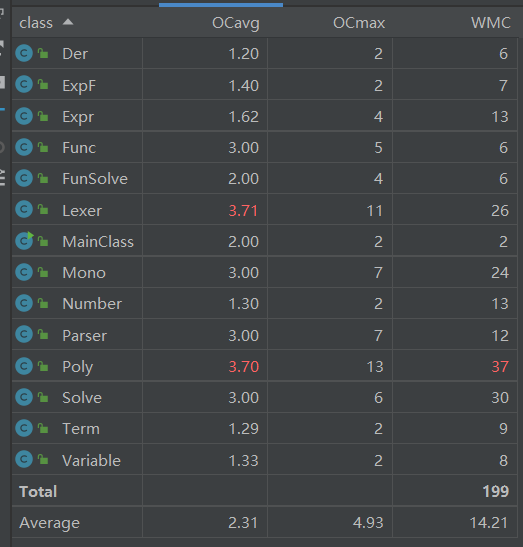
因为将每一个因子最终都以Poly的形式进行运算处理,所以会导致Poly类的复杂度很高
方法复杂度
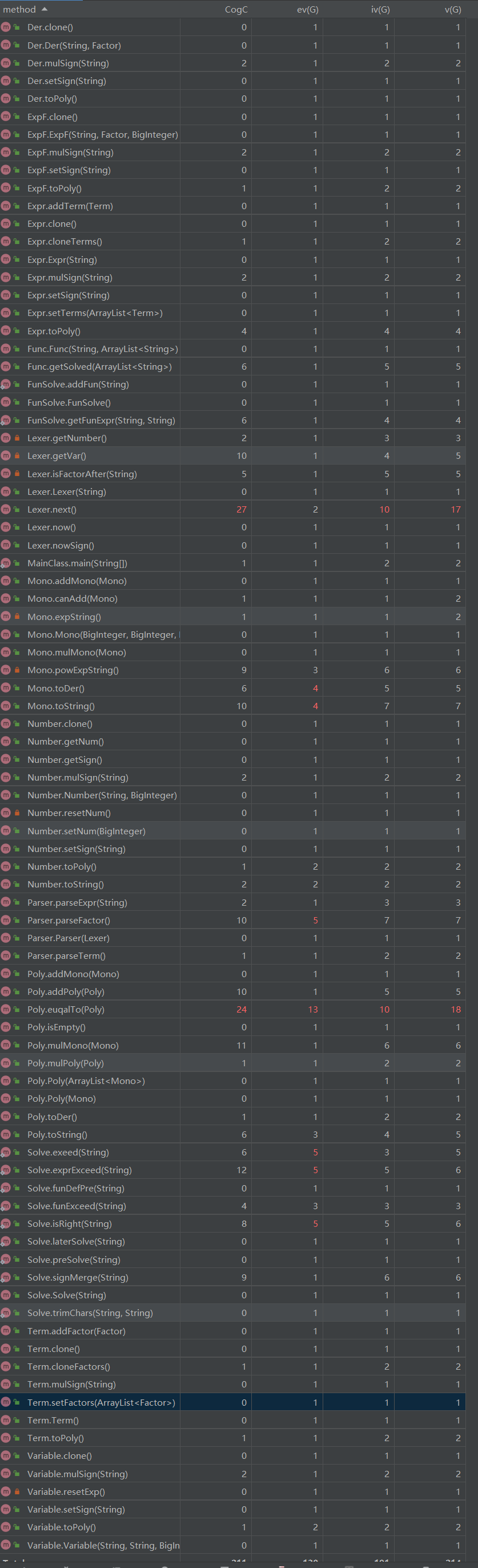
可以看到Poly的高复杂度主要是由于equalTo方法,因为采用了效率较低的嵌套遍历,同时每次循环都要调用Mono的判断方法,耦合度比较高
类逻辑图
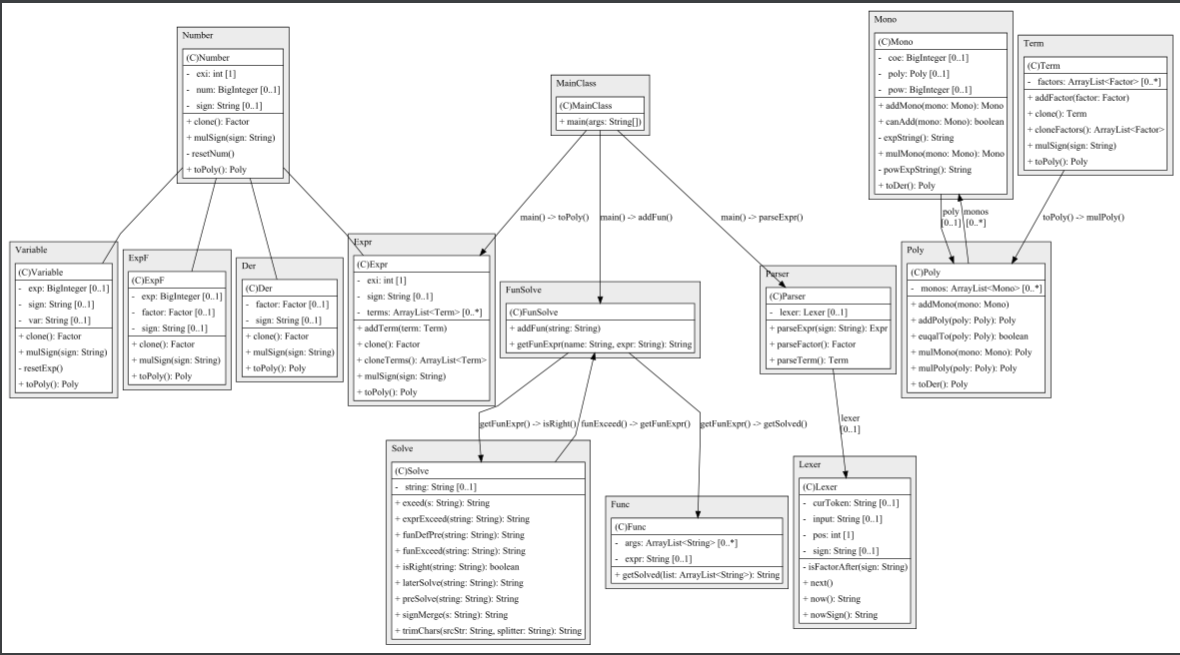
Factor接口关系
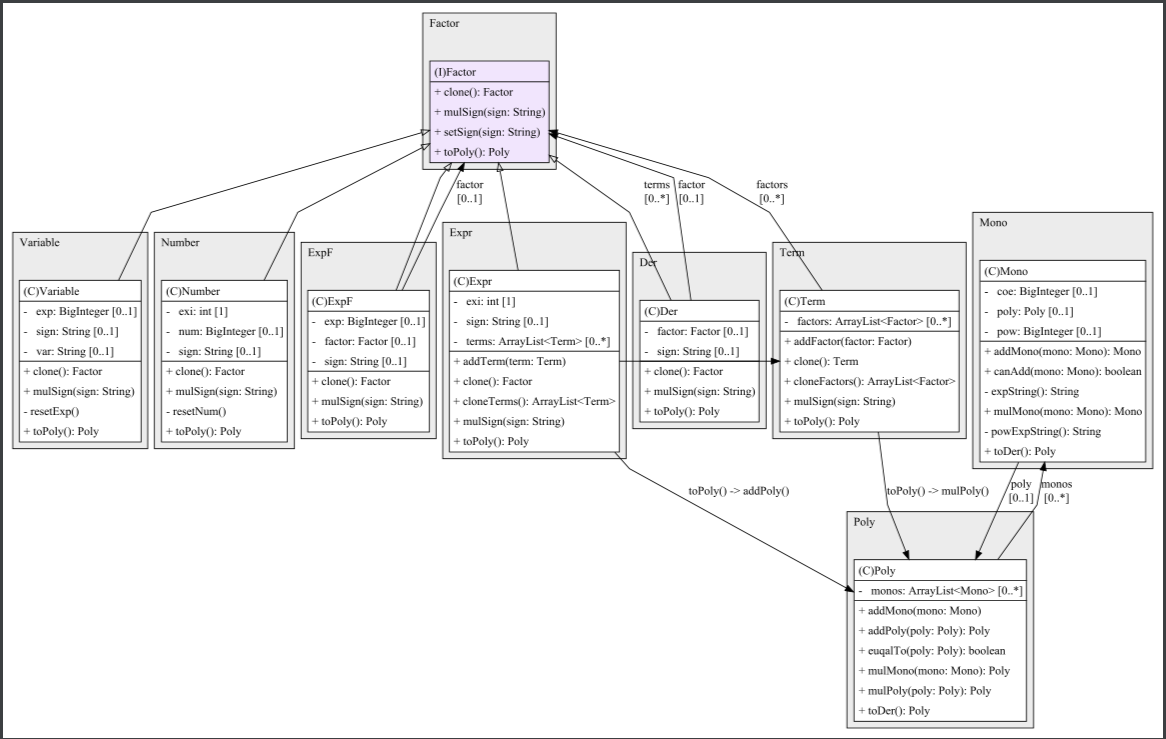
类调用关系
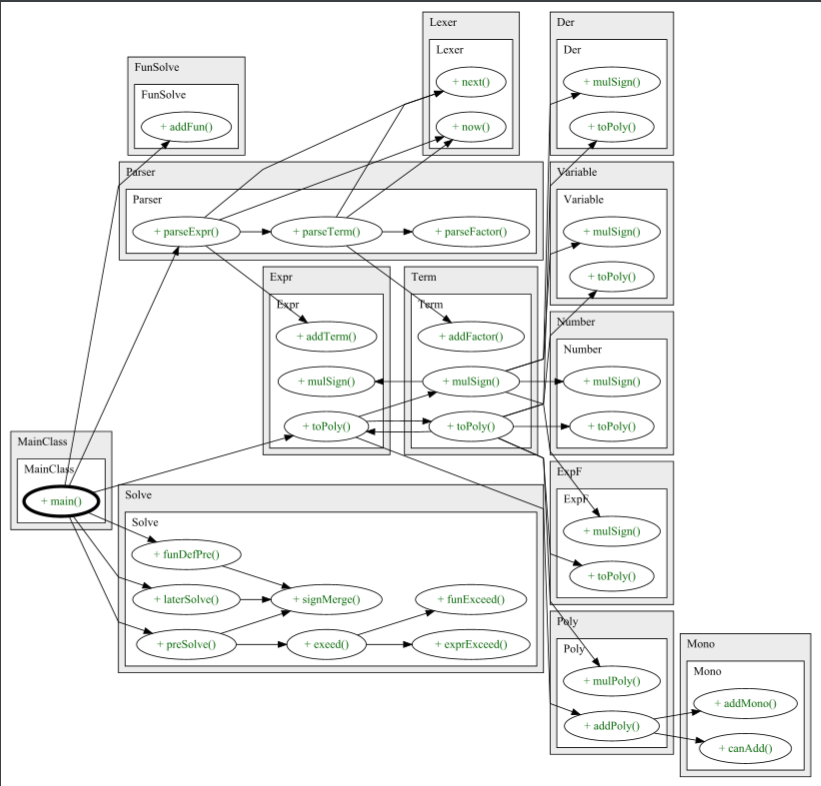
Solve储存了一系列静态方法,main中主要调用两个静态方法
preSolve方法实现待解析表达式的预处理,包括去除空白符、合并正负号以及表达式次方和自定义函数的展开
laterSolve方法实现表达式输出前的后处理,包括合并多余正负号和去除首尾正负号等
FunSolve主要完成函数定义的读入、函数形式和形参的储存等功能,方便Solve中自定义函数的展开
funs存储自定义函数的容器,函数名与函数类的映射、
main类调用 addFun函数来实现函数定义的读入以及函数形参的添加
Solve类调用getFunExpr函数来实现函数实参调用的代入,返回调用展开后的形式
Parser用于表达式语法解析,采用递归下降法逐层对表达式解析,最终形成一个由Expr Term Factor组成的树状层次结构,语法解析依赖于词法的分析
parseExpr parseTerm parseFactor三个方法相互调用来实现递归解析
Lexer用于表达式词法的分析,主要实现表达式的顺序遍历,同时返回当前的目标curToken与当前目标的符号sign
next告诉词法解析器向前解析表达式,更新当前目标和符号
now告诉语法解析器当前目标是什么
nowSign返回当前目标的符号
Poly由若干个Mono相加而成,处理涉及Poly的运算
monos存储所含有的mono
addPoly mulPoly mulMono分别实现两个Poly的相加、两个Poly的相乘以及Poly和Mono的相乘运算
toDer toString分别实现多项式的求导方法和输出方法,二者均是调用Mono的对应方法来递归实现的
Mono存储了基本项的形式,并且实现了仅涉及Mono的运算方法
mulMono canAdd addMono三个方法分别实现了两个Mono的相乘、两个Mono是否可以相加以及如何相加
toDer toString分别实现了单项式即基本项的求导和输出方法
这三者是解析表达式的三层结构,其中Factor是一个接口类
Expr Number Variable ExpF Der分别是表达式因子、常数因子、幂函数因子、指数函数因子以及求导因子,这些基本因子类全部实现了Factor接口
toDer toPoly分别实现各个因子的求导和转换多项式方法
第一次作业主要是实现递归下降的方法,因子只有最初的变量因子、数字因子和表达式因子,主要的难点在于递归下降方法的理解,包括Parser和 Lexer 的功能,递归实现嵌套表达式的逐层运算合并。然而我在第一次作业时并未深刻理解如何递归实现面向对象思维的运算,而是带有严重的面向过程思维来编写因子、项之间的合并,代码非常冗杂并且bug频出,这也是导致我第一次作业强测暴雷未入围互测的主要原因。
总体第一周的感觉就是 一定要先深刻理解并且对架构深思熟虑之后再写 否则就会一周忙忙碌碌但是效率和效果很差,仅第一次作业就写了768行代码
在第二次作业前的理论课上讲到了运算的递归实现,提到运算类的实现,于是我在第二次作业发布前开始重构,目标即为运算的递归实现,我实现了多项式 Poly 和单项式Mono两个运算关键类,并且同时在Expr Term Factor 中实现了 toPoly 方法,可以理解为Expr Term Factor 是文法解析时用来存储表达式结构的三个层次,之后将各个层次转化为 Mono Poly 这两个运算层次来实现表达式的递归运算。
递归运算的关键因素是找到表达式中的 基本项 ,这一点在研讨课当中被大家一致认同,第一次作业当中,可以认为最终表达式中的基本项就是 coe*x^exp 的形式,第二次作业中新增了 exp(因子)^指数 和自定义函数 ,对于自定义函数,只需要在预处理阶段将自定义函数的调用转化为各个实参因子的运算即可,因此自定义函数不属于基本项,而对于指数函数exp而言,不仅要实现parser和lexer对其的解析,而且还要对mono增加基本项和运算方法,基本项的形式 coe\*x^exp\*exp(poly)
但是本人由于对刚重构的递归架构不够熟悉,导致对基本项没有把握清楚,既没有实现exp的合并化简,也对第三次作业的求导操作带来了困扰
重构并且完成了第二次作业后代码行数为900行
这次作业是我认为最简单的一次,事实上在前两次架构基本明确之后,在此之上的增量开发就较为容易了,最主要的原因还是架构的可拓展性,实现求导操作的过程中,我分别实现了解析器的读入、各个因子的求导以及Mono Poly的求导。由于第二次作业中没有把握清楚基本项的本质,不仅exp难以合并,而且对求导操作带来了巨大的工作量,所以我又部分重构了一下,把握了基本项的形式,并且统一了mono求导的规则。
最主要的递归结构搭建成功后,再进行增量开发就比较容易,我的架构在第二次作业重构后基本成型,第三次作业中调整了基本项的形式,以便求导操作的递归进行。
如果出现新的迭代情景,例如要增加sin cos等函数,只需要兼顾读入和运算两部分即可。首先修改parser和lexer来适应新增函数的读入,其次为新增因子开辟新类,同时实现因子的toPoly toDer方法,最后在mono中调整基本项的形式,并且修改运算法则来适配基本项的一般形式。增量开发的过程既符合预期也符合新增习惯,这也是架构可迭代可拓展的优势。
第一次未能入围互测,原因是强测挂了很多点,分数过低,经过排查发现是预处理模块出现了问题,由于对正则表达式不够熟悉,在展开表达式时出现了bug,当存在多个括号时展开会发生错误。
第二次强测中发生了TLE,原因是预处理时乘方的展开使用正则表达式十分耗费时间,当表达式过多,乘方嵌套时速度会严重降低,直接被卡了。同时由于没有优化架构,导致exp的合并出现了很多问题,性能分损失了很多
第二次互测进入了B屋,并未被hack出bug
第三次强测中并未出现bug,并且由于部分重构,使得性能分追赶上来,没有太多的损失
第三次进入了A屋,被hack出了一个bug,原因是在判断两个基本项是否相同时,遍历元素出了问题,判断的并不够充分,导致判断是否可加出现了问题
这里说说我的缺点吧,相比于有些同学的优化,我的性能实在是很低,主要有几个原因
首先在处理模块采用了很多 循环+正则 的写法,这首先是十分具有面向过程性质的,其次是
第一次未进入互测,第二次成功hack出bug,第三次未hack出bug
第二次发现有同学先入为主定义了形参中x y z的顺序,当更换了形参顺序后,运行结果便会出错,例如f(y,x)=x会输出y的值
第一单元的作业让人感触最深的便是严重的面向过程编程的思维,在第一周的框架搭建时,我甚至直接面向过程实现了项与项之间的合并,导致之后的作业可迭代性非常差,不得已在第二次作业中重构。
总的来说,这三周的压力是逐渐下降的,由于思维的局限和理解不够深入,最初的框架最难实现,在经历了重构之后,代码架构的可拓展性大大增加,第三次作业的实现就很简单了
希望接下来的一单元能够更加深入的理解面向对象的编程艺术和java的魔力
可以放宽bug修复的代码行数要求,不然如果一个bug需要重构才能解决就很难受,而且有的bug往往牵一发而动全身



