


301
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享目录
读入一个包含加、减、乘、乘方以及括号(其中括号的深度至多为 1 层)的单变量表达式,输出恒等变形展开所有括号后的表达式。
表达式预处理:由于输入的表达式中含有不定数量的空白符,并且还会出现连续的加减号。因此,先对输入的表达式字符串进行预处理(删除不必要的空白符和加减符号)能够使之后的表达式解析更加方便。
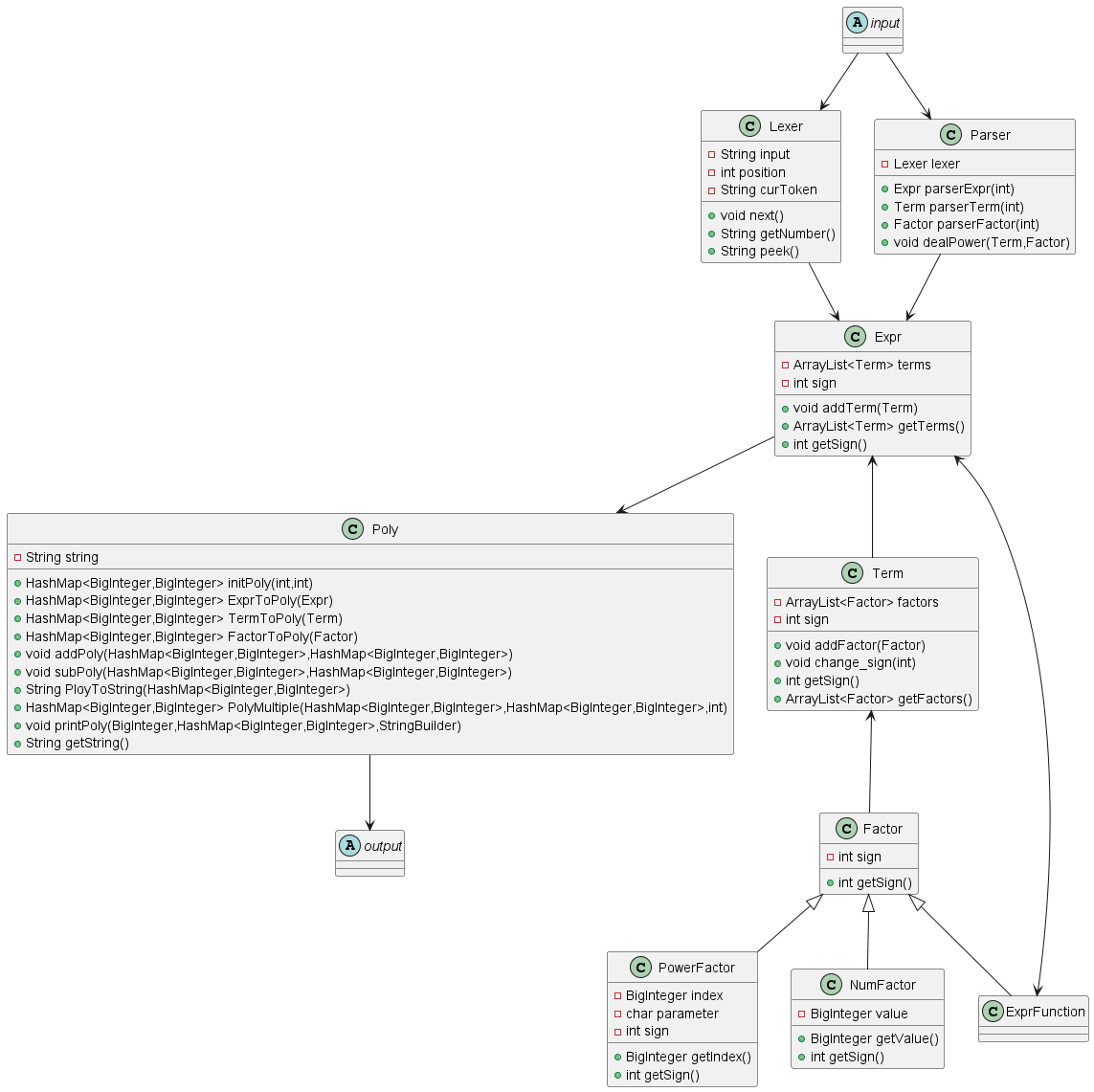
表达式解析:根据相关的数学知识,我们可以将表达式(Expr)按照 + 、 - 分为多个项(Term),而每个项按照 * 分为多个因子(Factor),对于因子我们可以将其分为3类——常数因子、幂函数因子(x^b,其中b为常数)、表达式因子。其中对于表达式因子的处理,采用递归的方式再次调用处理表达式的方式即可。在理解表达式的递归表达通式之后,借助 Parse 和 Lexer 将字符串表达式解析成Expr的形式。
Expr转换:为了方便输出,我们将 Expr 都转换成多项式(Poly)。而 Poly 的基本表现形式为——a*x^b(a为系数,b为指数),因此借助Hashmap<BigInterger,BigInterger>这样一个容器储存多项式,其中 key 代表指数, value 代表系数。得到这样一个 Hashmap 之后通过计算将表达式进行化简,最后将结果进行转化输出。

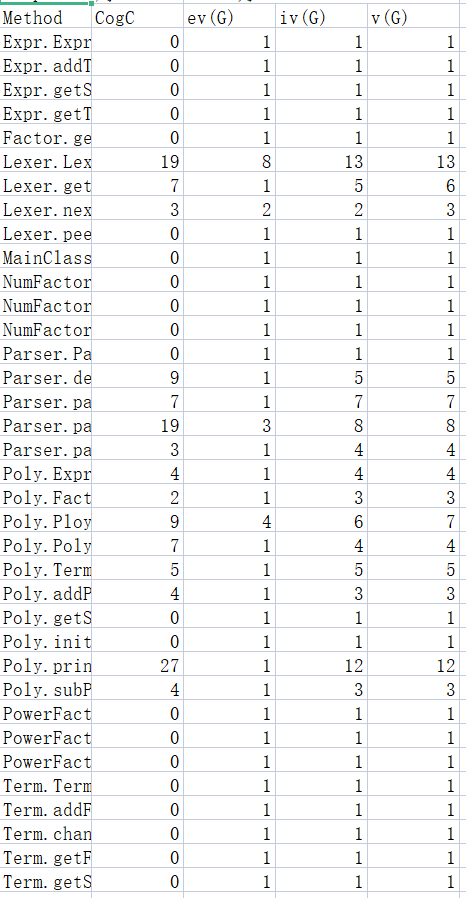
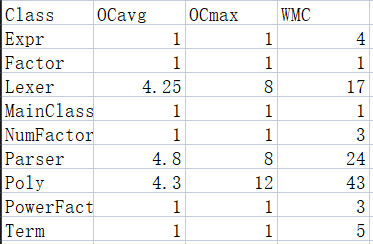
对于第一次作业可以优化的部分有限,需要注意的点如下:
本人在测试的过程中没有遇到bug,但是在互测环节中发现有部分同学对于最终输出为0的表达式的处理出现问题。这部分同学由于最后计算结果为0,导致输出空串造成bug。
在第一次作业的基础上,进行功能的扩展。增加的迭代要求如下:
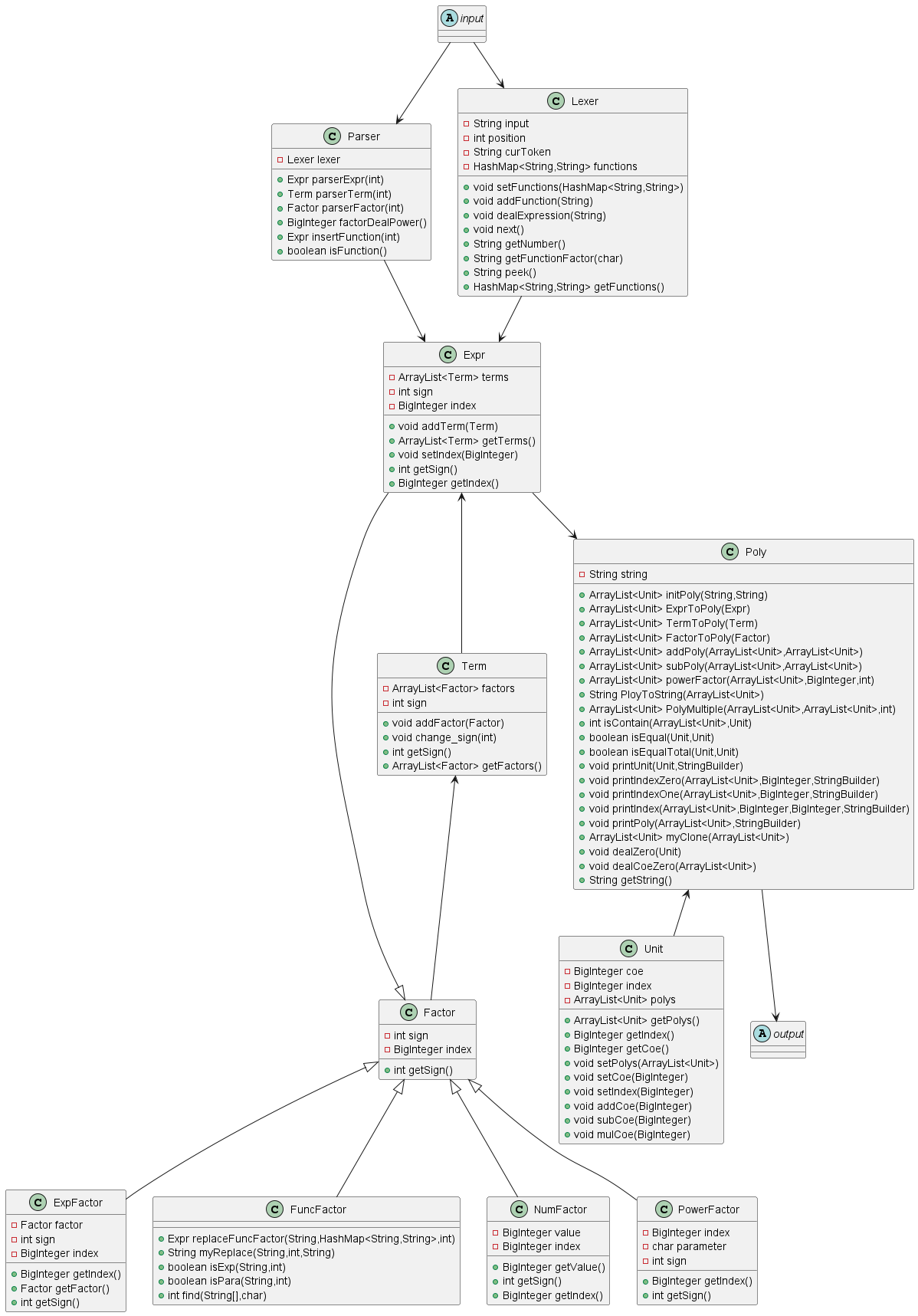
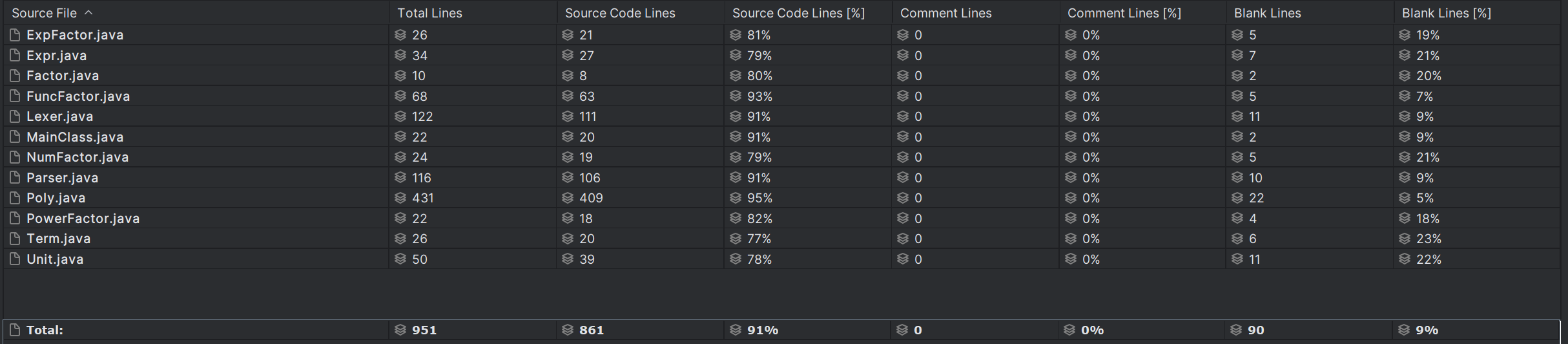
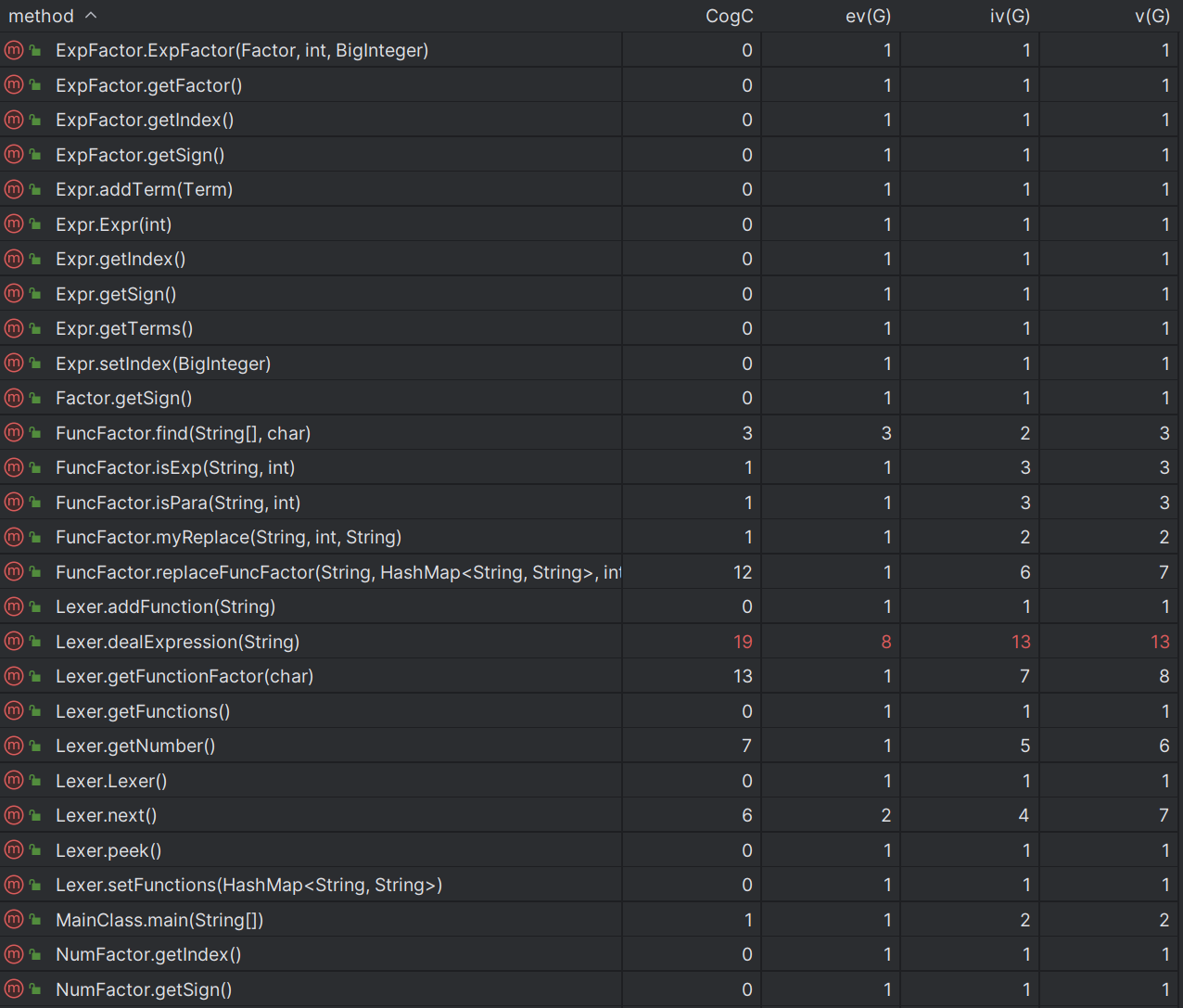
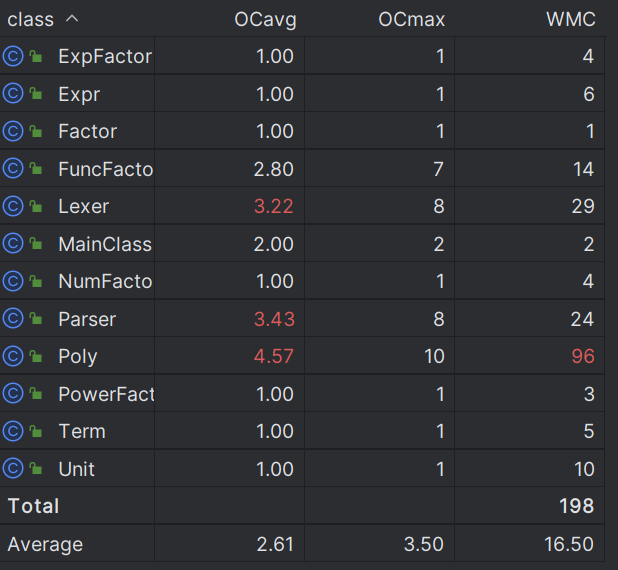
在第一次作业的基础上,第二次作业的优化难度更大,本人所想到的优化点如下:
第二次作业的强测环节,代码出现了TLE的问题。后经过检查发现是进行运算时没有对乘方运算的处理出现了问题,我对于乘方的处理就是若解析到 '^ a' 则将a个相同的因子放入项中储存,这就导致当处理类似 (((((((((((x^8)^8)^8)^8)^8)^8)^8)^8)^8)^8)^8)^8 的极端数据时,调用乘法运算的次数呈指数级增长,最终造成Time Limited Error。因此,针对这个问题我修改了处理乘方符号的方法,我将这个指数作为一个属性单独存了起来,等到需要运算的时候再将因子展开做乘法,这样调用乘法的次数就是一个平稳的线性增长,不会出现之前那种恐怖的增长幅度。
在之前迭代的基础上增加了求导因子,同时自定义函数的函数表达式中可以调用其他自定义函数。
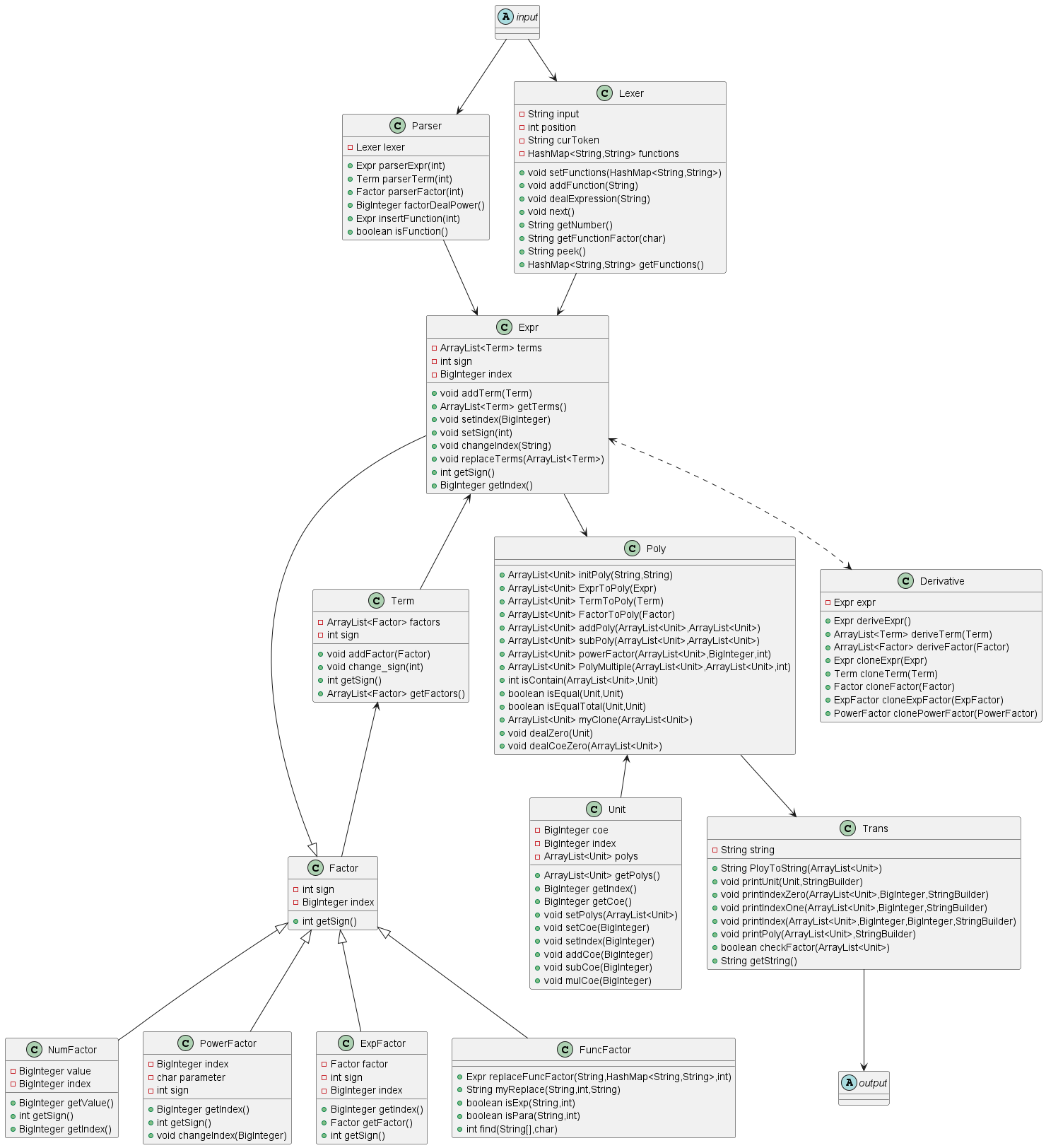
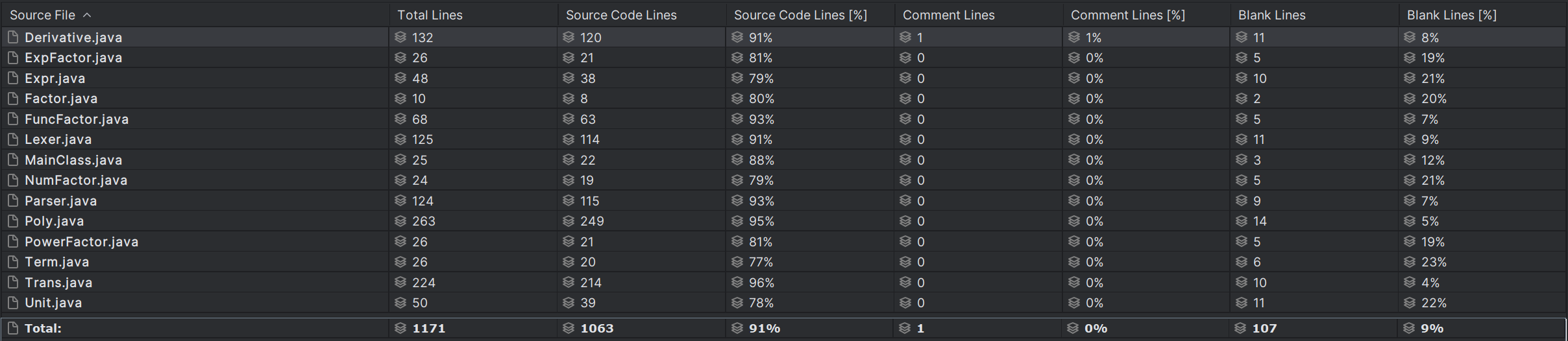
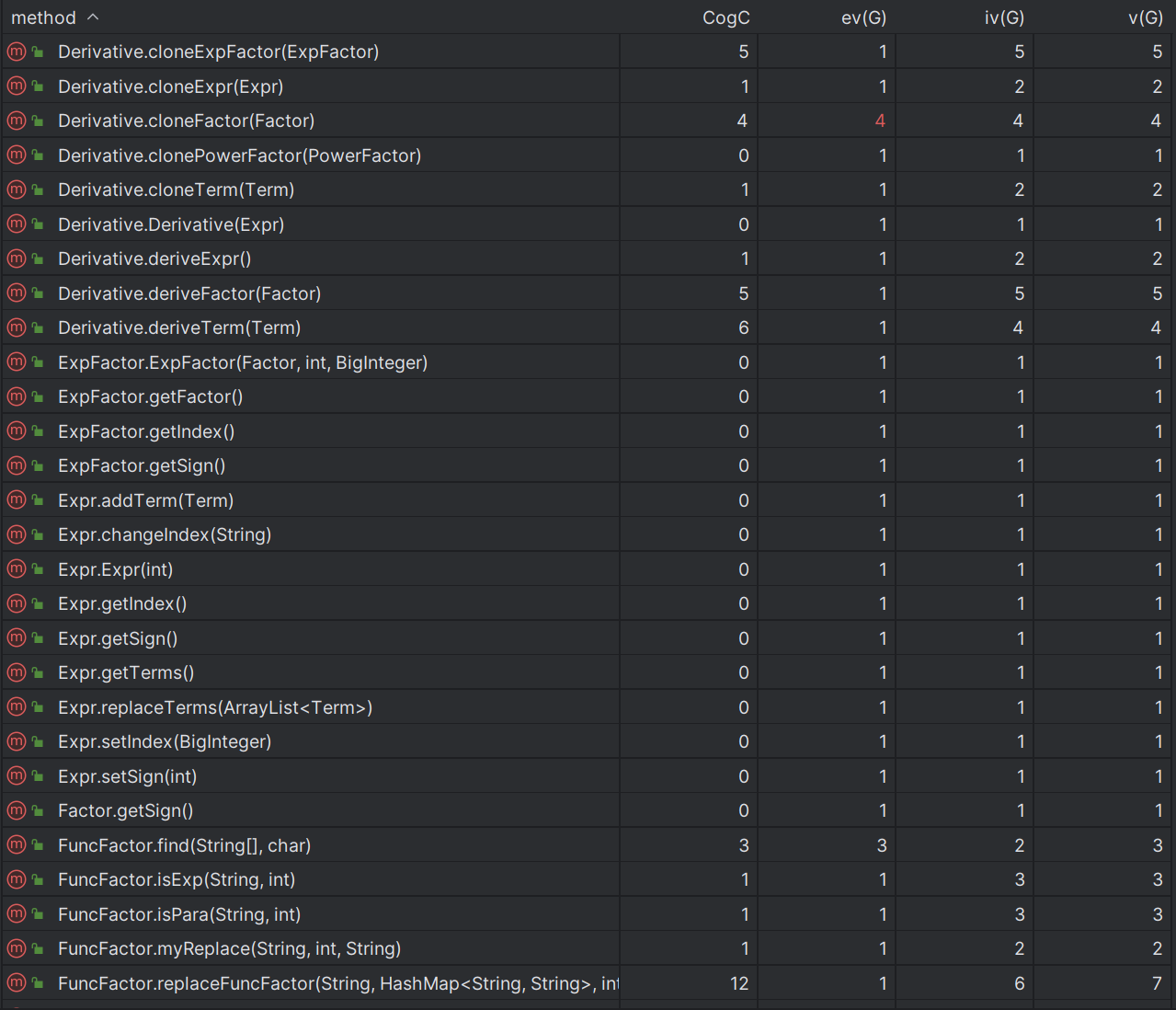
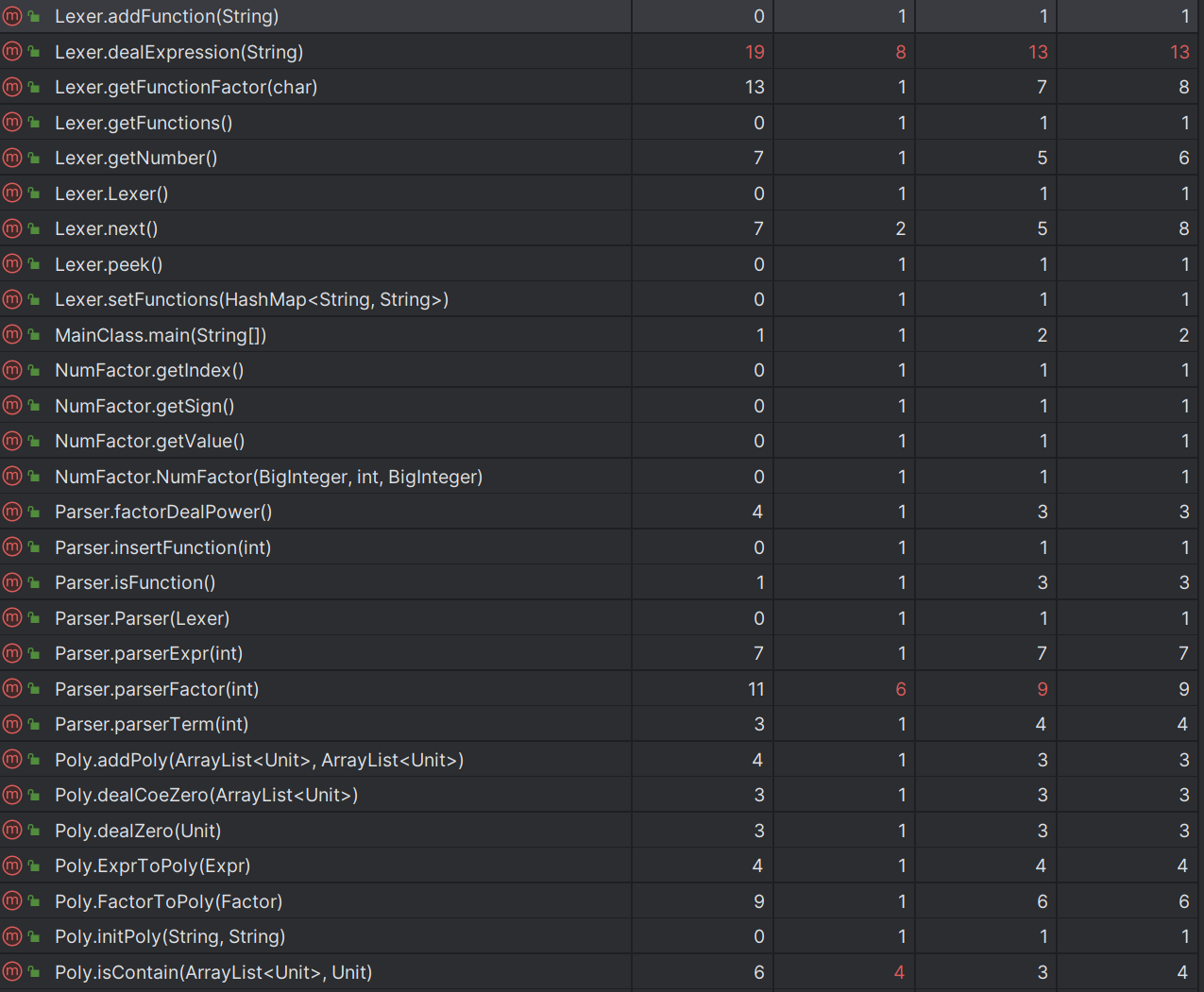
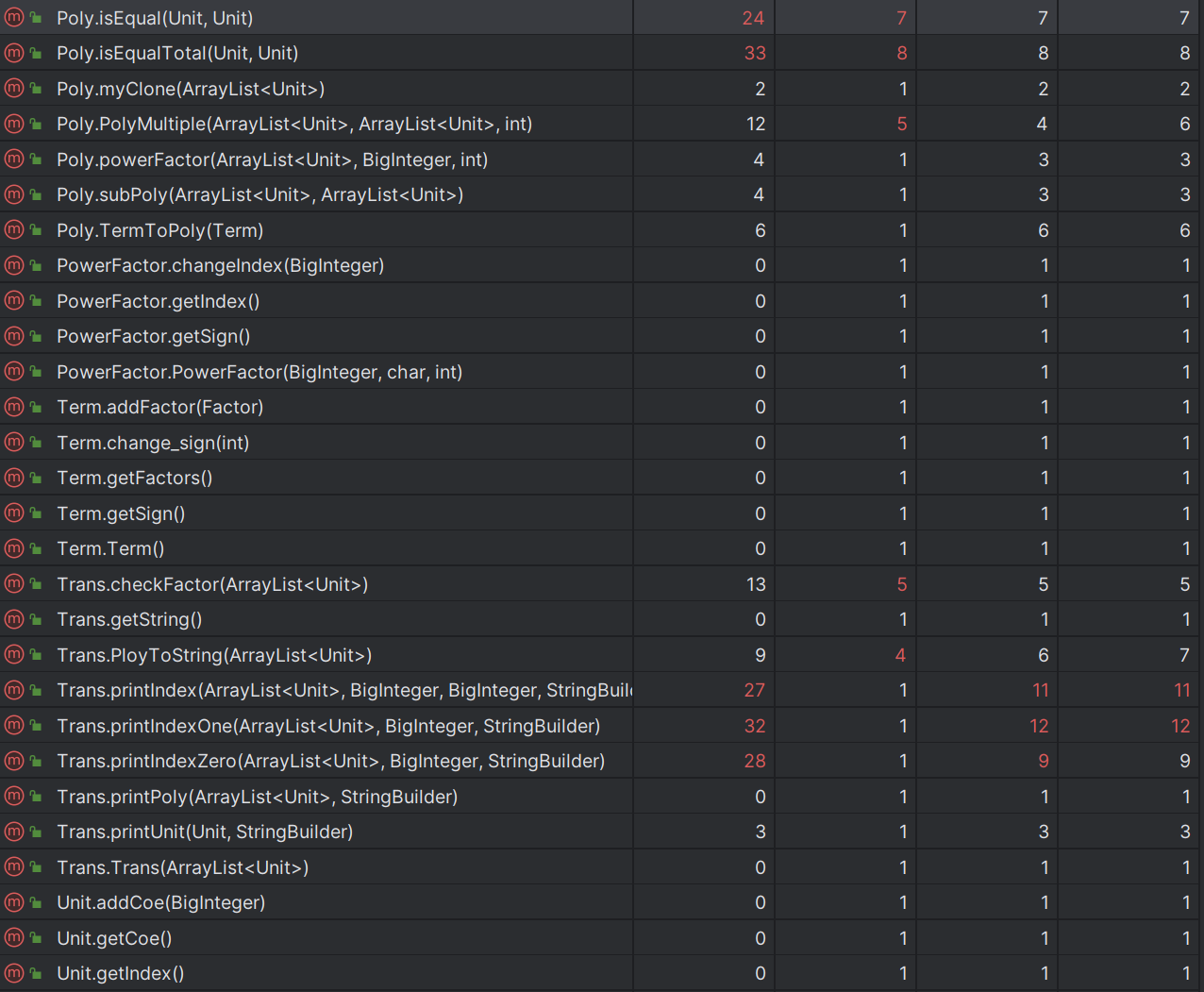
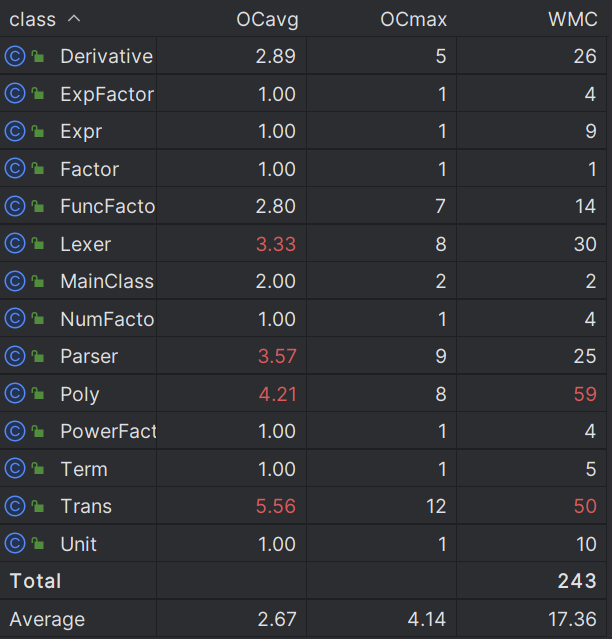
只新增了Derivative类用于处理求导因子,将其转换成了Expr形式,避免了对已有代码进行修改而带来其他的bug。
与第二次作业的优化处理方式基本上一致,此处不再赘述。
本人的代码顺利的通过了强测以及互测,但是从评论区得知有同学出现了CPU处理时间超时的问题,例如处理类似 dx(exp(exp(exp(exp(exp(exp(exp(exp(x^2))))))))) 的数据。猜测是处理递归的过程中没有及时将基本单元合并,导致在进行计算的时候递归次数过多造成CPU计算时间过长。
在完成整个Unit1的作业之后,我对于面向对象编程的理解更加深入了。同时也清楚地认识到一个条理清晰、逻辑顺畅的架构对于整个Unit开发和迭代的重要性。在第一次作业的开发过程中,我并没有太注重整体架构的可延展性,这就导致了我第二次作业的推进变得十分艰难,最终只将表达式的计算部分进行小范围的重构。因此,我便意识到一个好的架构不仅能够让代码看起来思路更清晰,同时还能大大减轻功能迭代所带来的工作量。
此外,对于自动评测机的搭建,本人只是完成了第一次作业的评测机搭建,之后两次并没有对评测机进行更新迭代。但是我也收获颇丰,因为完成数据生成器的过程让我对于指导书的理解更加深入,能更好地避免出现理解指导书不到位的问题。
我认为这一单元课程内容的难度还是比较合适的,但是对于优化问题的处理感觉收益不大。建议在之后的课程中可以让代码的可优化性变得更强。



