面向对象设计与构造第一单元总结
程序结构
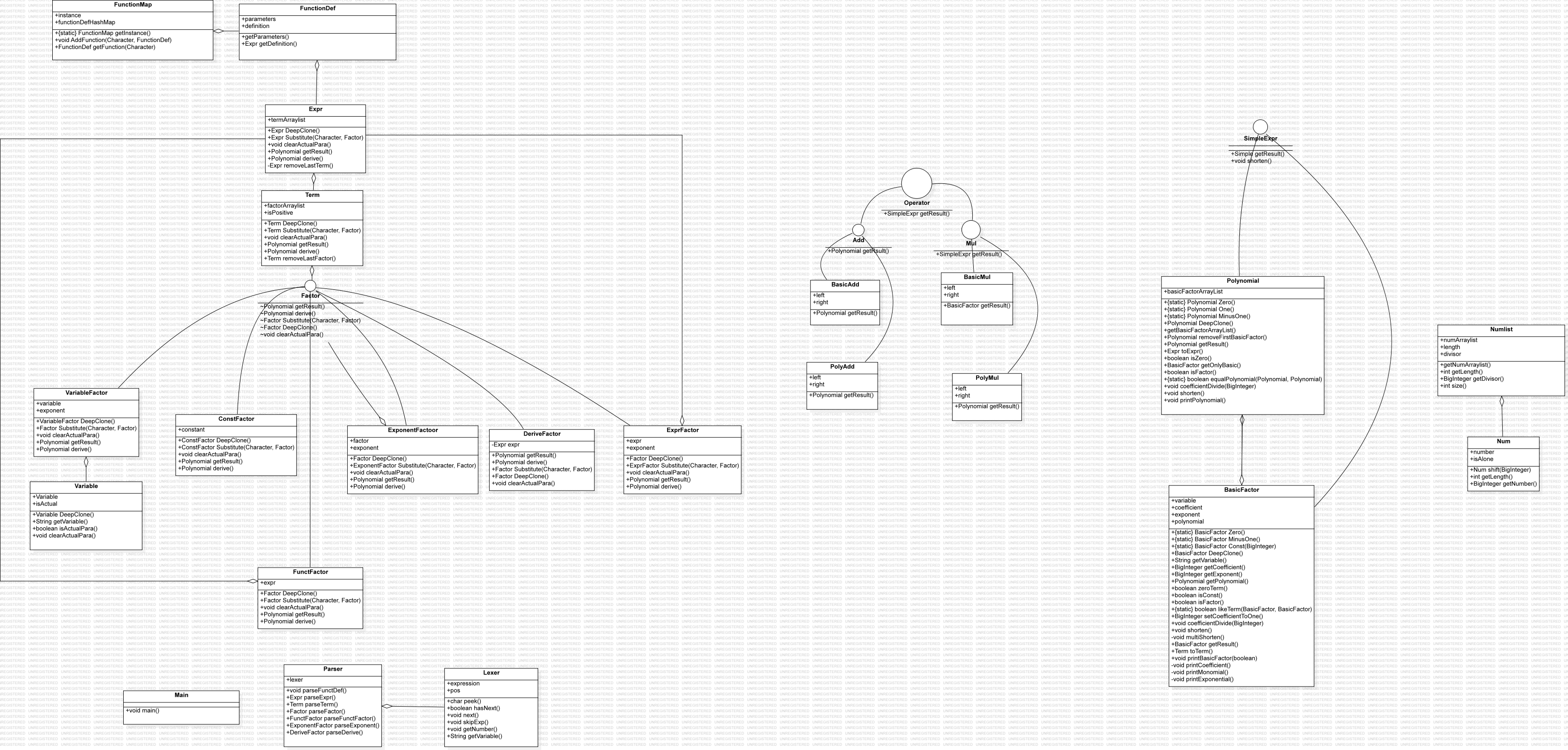
lexer对string进行词法分析,parser把lexer分析出来的token流解析成Expr。
- Expr树部分:
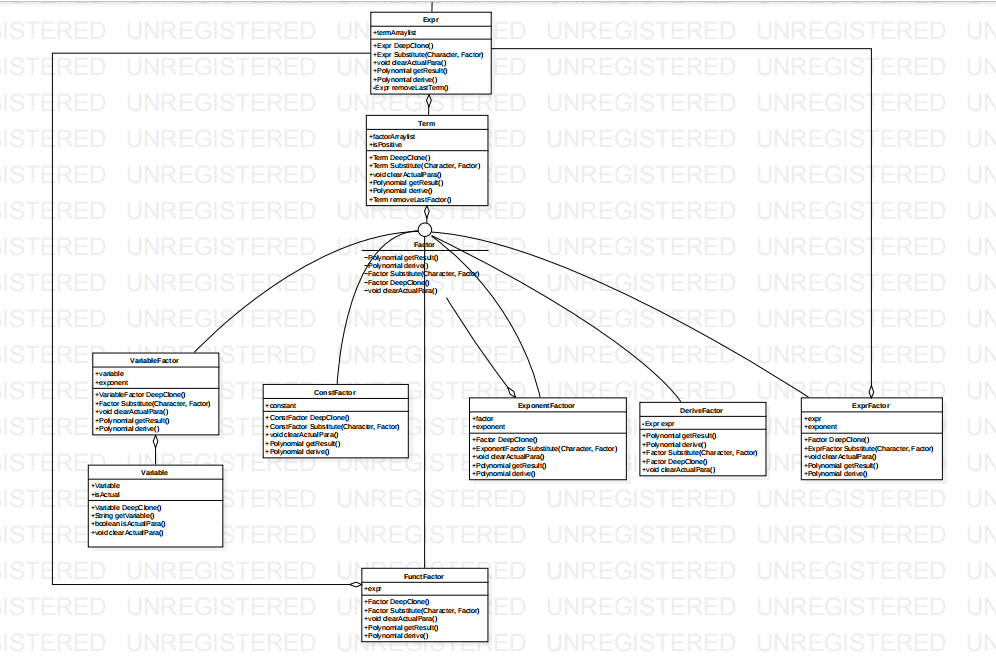
从结构化表述逐个实现的类。其中Variable类是为了标记形参/实参。
- Poly树部分:
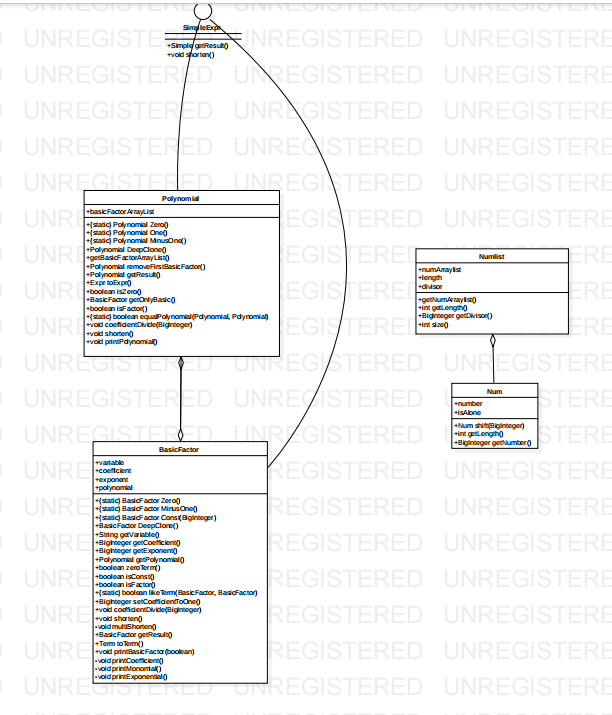
统一建模的标准简化表达式形式,后面会详细介绍,其中Numlist-Num用于优化。
- 操作部分:
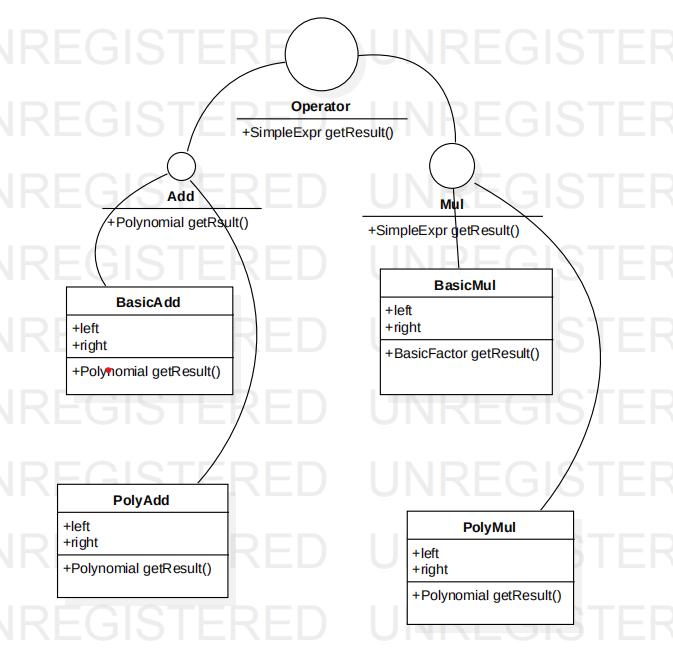
用一个统一的接口统一操作,设置多个操作方法(Basic-Poly)是为了让每个方法都结构简单,可以通过调用另一方法直接简单实现。
- 自定义函数部分:
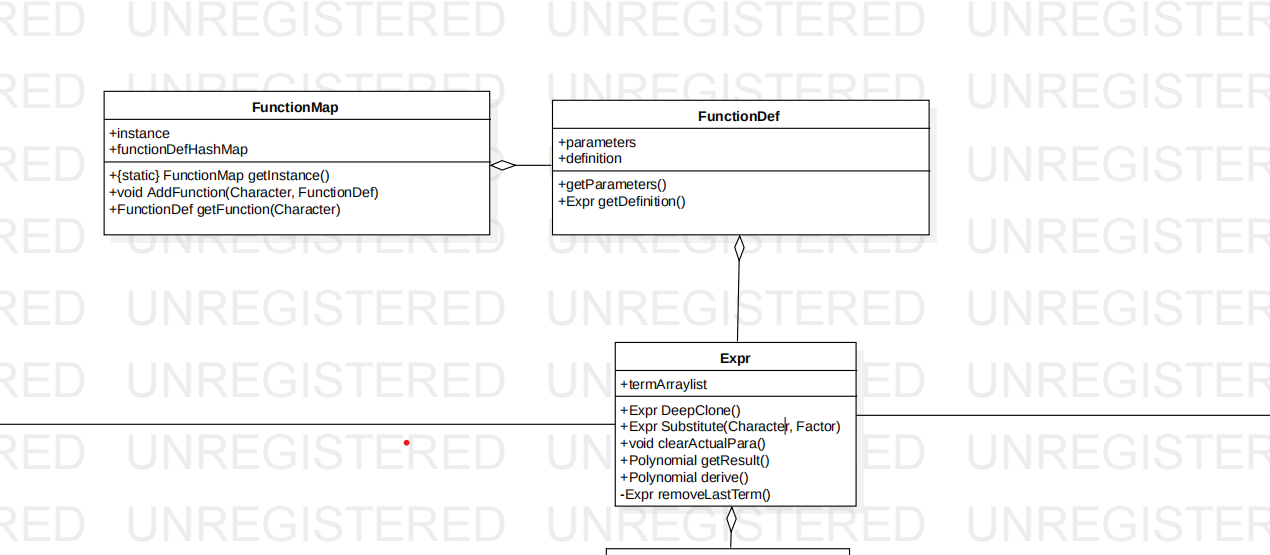
FunctionMap是全局可访问的单例,FunctionDef存储了形参和表达式结构,该类的设计主要是为了方便形参替换。
- 如此进行设计主要有以下考虑:
- 分离解析过程与计算(化简)过程,即程序分为两步,先把输入字符串解析为表达式、项、因子的树结构;再对这个树结构进行化简,得到最简表达式的结构。即$$scanner\xrightarrow{lexer \quad & \quad parse} Expr\xrightarrow{Operator}Poly$$下文将把前者称为Expr树,后者称为Poly树。
- 确保类的单一职责,虽然对表达式/多项式等类的计算和化简可以直接写在类当中,但是可能导致类过于复杂以及维护困难等问题,因此将Add/Mul等操作单独写成类,继承了Operator接口。但是在后续迭代过程中,这一考虑似乎没有被完美实现,反而逐渐废弃了(留下一些历史遗留产物)。即在求导操作加入后我没有新增求导方法类,而是将其纳入实体类中,这主要是因为如果新增求导类对每个对象操作的话,它会要求过大的权限,使各个实体类的属性不得不全部暴露在外。
- 如此设计的优缺点:
- 思考难度较低。Expr树和Poly树分别代表计算前和计算后的状态,分工明确;并且Poly相当于一个规范,能够指导化简。
- 类相对简洁。整个程序分解析/计算两步处理确保了类的简洁性,同时也让debug更加容易,发现bug时能以解析结果为界限较快定位到bug出现的位置。下图展示了较复杂类(OCavg顺序)的圈复杂度。
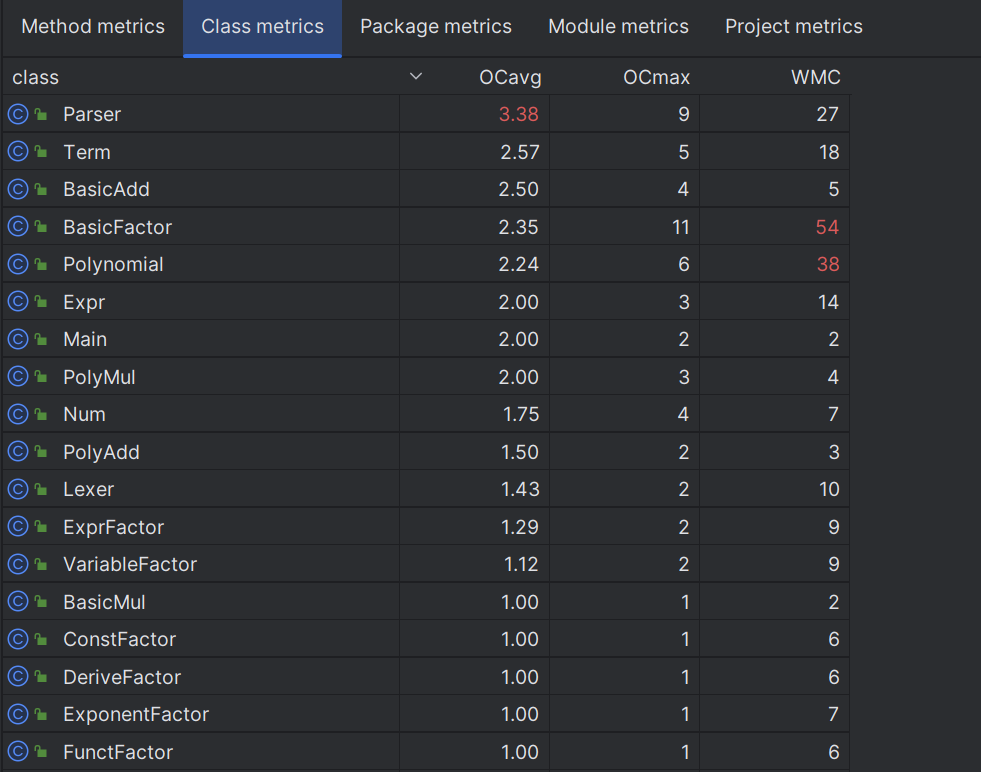
可以看出,大多数类的平均复杂度和最高复杂度较低(average OCavg = 1.75, average LOC = 51.09),部分类的指标略高,进一步分析如下。下面展示了复杂方法(CogC顺序)的圈复杂度等(average CogC = 1.24)
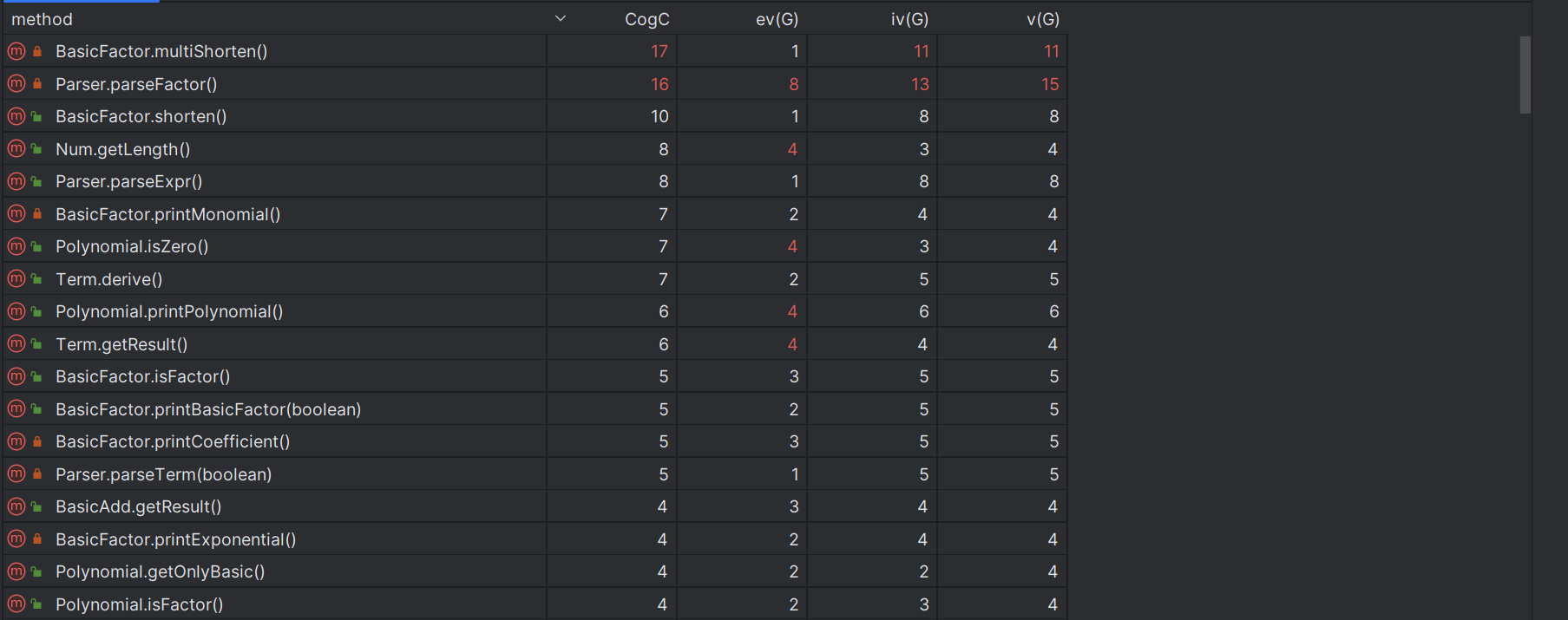
可以看出,parse类的复杂性主要集中在parseFunct方法中,该方法将较多分支集合在一起,如果将各个分支(各种因子)拆分为独立方法处理,则可以降低复杂度;另外‘shorten’方法复杂度较高,这是因为优化方法基本上使用了面向过程的风格进行编程。 - 类的耦合不高。
- 由于上述分离机制,大多数类间耦合程度较低。
- 但是Poly/BasicFacotr类同Operator存在协作关系,前者的属性不得不被传递给后者,实现时的一个补丁是后者只能看到而不能修改前者的状态,而是返回一个新的对象,保证了前者的安全性。
- 仅支持单次映射,这是本设计中最大的缺陷。这具体是指仅支持这种形式的操作$$Operator:= Expr \rightarrow Poly \ expr \rightarrow poly $$并且后者Poly定义为已经简化完的、完美的表达式(已经最简,没有定义化简方法)。但是现实需求很可能是已经简化的表达式有可能不得不再经过某种Operator变成待化简的形式。例如第三次作业会出现的嵌套求导操作。面对这种需求,我采用的方法是 将得到的待求导Poly类再转换为Expr(状态:已经化简->未化简),以便调用Expr/Operator已经实现的方法进行Operation。虽然说此设计也可以用这种这种补丁实现多次映射的需求,但是这样将Poly树重新转化成Expr类会导致效率降低,这启示也许一开始将表达式人为构建成已化简和尚未化简的两棵树是存在一定问题的。理由除了上述已化简可以变成未化简这一点之外,还有一点,即Poly的规格是随着需求变化,这样BasicFactor(Mono)类就得每次都修改。从$ax^b$变成$ax^b*exp(c)^d$,也许之后还要继续修改,修改量较大;也许只使用Expr一棵树实现能解决这个问题。
架构设计迭代
- 第一次作业
- 递归:这是我在第一次作业时遇到的主要难点,即如何设计好操作类使得上层计算方法可以递归调用下层方法实现计算。事实上,正是出于对递归的正确实现的考虑让我建模了一个Poly类作为对Expr/Term/Factor计算(化简)的统一返回值,现在看来直接将Expr作为返回值也并无不妥。
- 层次化与分离机制:基于以上考虑,建模了Expr树和Poly树,他们用Arraylist容器维护下层对象。另外分离出计算操作,建立了Operation接口作为操作的统一标志,这三者也成为了后面数次作业的核心结构。
- 第二次作业
- 分步实现:本次作业可看作有实现exp和实现自定义函数两个需求,两步相对独立,通过分两步增量开发,中间进行一定测试的方法,防止了增量过多导致后续bug无法找到的难题。
- 接口:在第一次作业的简单结构当中,我使用VariableFactor作为常数和变量的统一因子,本次作业因子类型更为复杂,因此建立了Factor接口,实现常数、变量、表达式、指数、函数多个类。
- 替换机制与单例模式:基于之前复用潜力较高的架构,我采用了对象替换的方式解析自定义函数,即将函数当作表达式解析成树结构,再通过替换方法将树结构中的形参变量替换成实参。这意味着在Expr树的各个类当中实现一个Substitute方法。由于函数随时都会出现,因此我设置了FunctionMap的单例维护Hashmap<Name,FunctionDef>。
- 深克隆机制:在上述替换过程中最为重要的部分是替换过程并不能够将全局的functionDef修改了,而是应该依葫芦画瓢地将function的树结构复刻一份返回,这其中就涉及到深克隆问题,我的方法是对Expr的全体对象都递归实现深克隆方法。
- 递归、循环与空指针:本次作业出现的一大问题是同类项的比较问题,为了判断两个BasicFactor是同类项,需要知道其中exp中的Poly是不是相等,而判断两者是不是相等又要判断对应BasicFactor的相等关系,这就形成了循环调用的结构。那么调用的终点在哪里呢?也就是Poly为零多项式的时候。存储零多项式有多种方法,考虑到在代码的许多地方已经不检查地使用了对象,不使用null来表示零多项式,以避免NullPointerException。我使用的递归终点是维护空容器的Poly。
- 第三次作业
- 向下引入新类 第三次作业所需要进行的扩展较少,基于之前的架构,上层的类其实不需要修改,而只需要对下层进行细化。自定义函数的调用定义要求让我建立了Variable类,以便于记录变量名和变量类型。
- 引入新操作:求导的实现方法上面已经简要说明,没能像理想的那样接入Operator接口,而是看作Operator的一个平行操作,对Expr的每个类递归实现了。
- 进一步扩展
- 现在加入表达式要新增sin/cos函数,那么如何修改能够满足需求呢?正如上面提到的那样,比较大的改变即重写BasicFactor(Mono)类,将sin/cos作为其属性即可。其他的改动包含添加新类实现Factor接口。
Bug分析
- 思路:整体而言,发现bug的方法是先手动测试多种条件数据和边界数据,再用自动生成的数据进行测试。对自动生成的复杂数据,若测试出bug,先进行化简,用足够简单的测试点逐行调试。
- 自身bug发现
- 在公测正确性测试和互测中没有发现Bug,但实际上在第二次作业中,存在期望优化目标和实际优化结果不同的问题(即用于优化的shorten相关方法存在bug),此问题出现一方面是不影响正确性,因此并未在公测前测试出来;另一方面则是因为优化方法也写得比较复杂,具有较多分支,圈复杂度较高,导致不容易看出问题。
- 互测中所发现的别人的bug
- 互测的思路同自己测试的思路类似,通过自动测试发现bug,再简化数据逐行调试,发现bug所在。期间发现了一些比较有趣的bug。
- 其中一位同学会将$2^{32}$的倍数解析成0,经过调试,发现原因是在输出表达式时判断BigInteger是否是0时,用了$BigInteger.intValue() == 0$这直接导致只能识别系数的后32位(二进制),导致出现bug。这启示我们慎用类型转化。
- 另一位同学在最终表达式同时存在$x^{16*t}$和正常数的时候会少输出一个‘+’。如将$x^{16}+1$输出成$x^{161}$。这主要是由于在输出是误将HashMap的key当作有序排列的,实际上确定key顺序的机制比较复杂,正好key在计算hash并进一步处理时会忽略后四位,因此指数是16的倍数的key可能在迭代器中出现在正常数前,导致bug。
优化分析
- 对表达式长度做了如下优化
- 合并同类项,即对$ax^bexp(c)$,当b,c相同时合并两项。
- 不输出零项,有正项时先输出正项。
- 类似$exp((a*x^b))$的项当a>0的时候可将a提出变成$exp(x^b)^a$
- 对于$exp((\Sigma_{i=0}^na_i*x^{b_i}))$项,可以将$a_i$的公因子t提出变成$exp((\Sigma_{i=0}^n\frac{a_i}{t}x^{b_i}))^t$,需要注意的是最短的表达式可能是原始表达式、提出最大公因子$gcd$的表达式以及提出某个较大公因子$\frac{gcd}{num}$$(num \in {2,3,…,10})$的表达式(如果$num >= 10$,和提出gcd的表达式相比,假设外部减少了$s$个字符,exp内部将会增加$2s$个以上字符,将更长)
- 前几个优化对架构影响不大,但是最后一个优化实现起来比较复杂,直接导致了一个比较复杂的方法的出现,使得类也不那么简洁。尽管如此还是可以进行一定程度的简化,比如我引入Numlist-Num类分担一定的工作(长度计算等)。
心得体会
- 在第一单元的设计中,最为关键的是radeoff的过程。
- 例如,设计过程始终要处理好抽象和易实现性的关系。一方面,各个类要尽可能单一职责,当出现细化的功能需求时,要尽可能进行抽象,设计新的类来具体实现;但是有时候一个类虽然未必职责完全单一,但是已经比较简单,这个时候再进行过度抽象可能导致整体架构和代码过分冗长,也无助于提高可维护性和可扩展性。甚至预先的抽象还可能不能概括将来的需求,以至于出现没有食之无味弃之可惜的接口,如上面的Operator。
- 再比如,确保正确性和提升性能两者要进行一定的权衡。后者需要比较谨慎推进,防止错误格式输出等问题;并且也要防止过分优化可能带来的程序运行超时问题。我同样采用先确保正确性再新增优化方法的方式把两者分开,防止后者损害前者。
- 另外,良好的代码风格(包括微观方法设计以及良好命名等)能增加debug的耐心,有利于提升正确性和效率,也方便迭代。
未来方向
- 课程总体设计比较合理,能够感到明显的进步。个人有如下建议:
- 对于博客作业中的静态代码分析度量,可以在前面的作业中适当介绍,以便于在设计时当作参考。
- 个人感觉研讨课的讨论时间不够充裕,常常来不及弄清楚他人的具体想法,可以适当压缩展示部分的时间。



 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享