


301
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享本文将包含以下内容:
总述: 包括类设计分析, 代码规模等度量, 以及类图.
迭代开发设计体验
bug与hack
优化
心得体会与未来方向.
总行数873,代码行数779.
| 类名 | 属性个数 | 方法个数 | 类规模(LINES) | 循环依赖(CYCLIC) | 该类直接依赖(DCY) | 直接依赖该类(DPT) | 方法平均复杂度(OCAVG) |
|---|---|---|---|---|---|---|---|
| MainClass | 0 | 1 | 30 | 0 | 4 | 0 | 6.00 |
| Token | 2 | 2 | 31 | 0 | 1 | 2 | 1.00 |
| ReadTokens | 2 | 3 | 72 | 0 | 2 | 2 | 5.25 |
| Parser | 1 | 3 | 109 | 0 | 8 | 1 | 6.75 |
| Var | 2 | 7 | 46 | 5 | 3 | 4 | 1.25 |
| Num | 1 | 8 | 68 | 5 | 3 | 5 | 1.56 |
| Factor | 0 | 1 | 5 | ||||
| Term | 3 | 13 | 108 | 5 | 5 | 6 | 1.73 |
| Expr | 1 | 16 | 177 | 5 | 4 | 4 | 2.95 |
| Function | 0 | 1 | 5 | ||||
| FunCustom | 3 | 4 | 106 | 0 | 1 | 1 | 4.80 |
| FunExpon | 1 | 10 | 116 | 5 | 6 | 3 | 2.09 |
复杂度:
| 项 | 圈复杂度COGC | 本质复杂度EV(G) | 内在复杂度IV(G) | 程序体积V(G) |
|---|---|---|---|---|
| Total | 264 | 132 | 221 | 257 |
| Average | 3.34 | 1.67 | 2.80 | 3.25 |
大部分方法复杂度较低, toString() parseTerm() parseFactor()及ReadTokens()方法复杂度较高 复杂度过高会增加调试的难度, 同时容易出现bug, 也可能会造成运行时间过长.
最终结构如图. 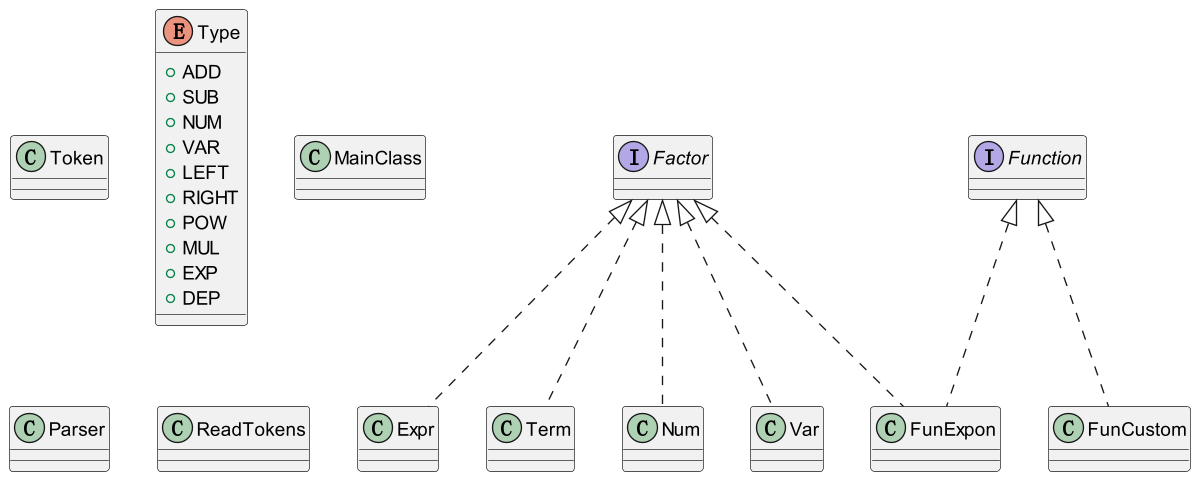
MainClass类为程序的入口.
Token类定义了输入数据中的基本语素类型Type.
ReadTokens类用于将读取到的输入解析成为一列Token.
Parser类提供了对表达式, 项, 因子的解析方法, 被主类调用, 获取表达式结果.
Expr、Term、Num、Var、FunExpon类为基本的数据存储和处理类, 用来实现基本的业务功能, 它们实现了Factor接口.
FunCustom、FunExpon类实现了Function接口, 用来进行函数的相关处理.
优点:
将输入处理与业务功能分离, 减小模块之间的耦合度.
按照数据逻辑构建基本类, 便于理解和搭建.
缺点:
业务功能类中包含输出处理, 可以进一步拆分.
Function接口某种意义上并不必要, 有待进一步调整.
读入一个包含加、减、乘、乘方以及括号(不允许括号嵌套)的单变量表达式,输出恒等变形并且展开所有括号后的表达式。
数据要求
带符号整数 支持前导0的十进制带符号整数(若为正数、正号可以省略)
因子
变量因子:幂函数x^指数, 其中指数为一个非负带符号整数. 特别地, 当指数为1时, 可以省略指数符号^和指数, 如: x.
常数因子 包含一个带符号整数.
表达式因子 用一个小括号包裹起来的表达式, 可以带指数, 且指数为一个非负带符号整数.
项 由乘法运算符连接若干因子组成. 此外, 在第一个因子之前, 可以带一个正号或负号. 空串不属于合法的项.
表达式 由加法和减法运算符连接若干项组成, 在第一项之前,可以带一个正号或者负号,表示第一个项的正负. 空串不属于合法的表达式.
空白字符 仅包含空格和水平制表符.
性能要求
在输出与输入表达式等价, 且输出满足合法性要求的前提下, 使输出的字符数尽可能短.
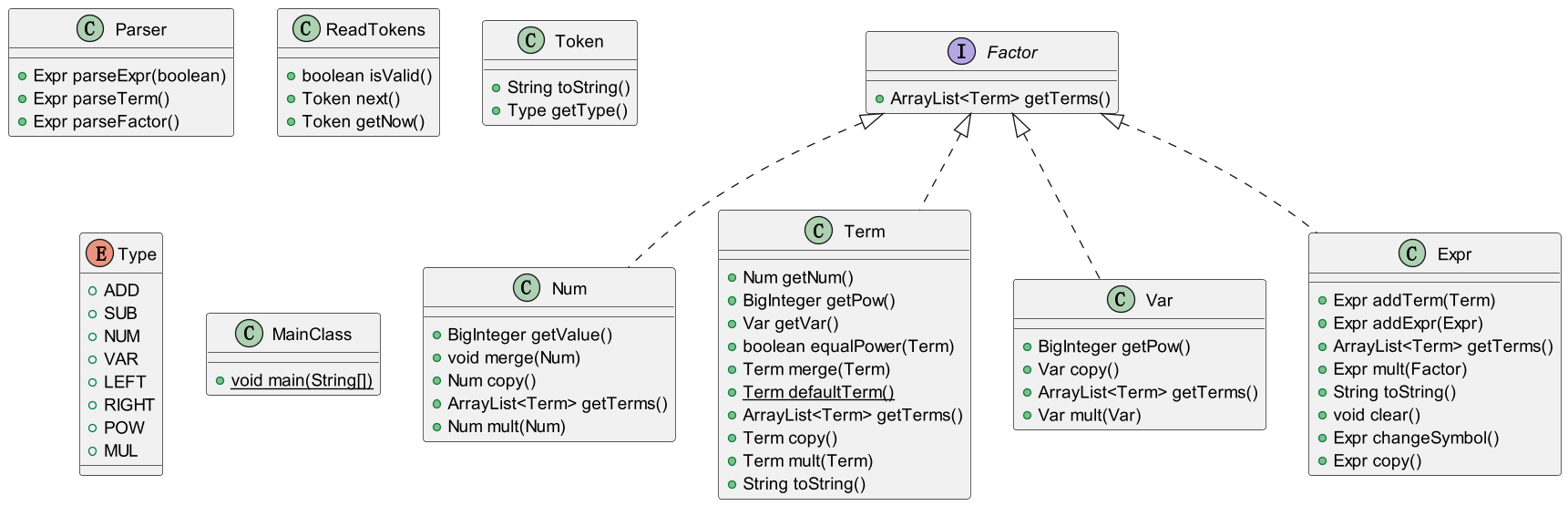
本次设计共包含8个类, 其中MainClass为主类, 提供程序入口函数void main(String[]).
输入处理
利用Token ReadTokens两个类来实现对输入的处理.
在Token类中, 定义了Type用来区分不同的字符串所代表的类型, 如幂函数, 括号, 加号等, 并且可以通过toString函数获得这个Token存储的字符串.
对从标准读入中获取的字符串, 通过实例化一个ReadToken对象, 将其转化成一个Token对象的序列. 在ReadToken类中, 封装了检测可用性, 获取当前Token和光标下移等成员函数, 减少对外暴露细节, 增强可用性. 同时, 对于连续的+/-号, 记录-号的个数, 仅保存一个化简后的结果.
解析读入的表达式: 采用递归下降, 建立专门的类Parser进行解析. 类中提供了parseExpr() parseTerm() parseFactor()三个方法, 分别用来解析表达式、项和因子. 根据递归下降法的原则, 其调用关系如下图所示:
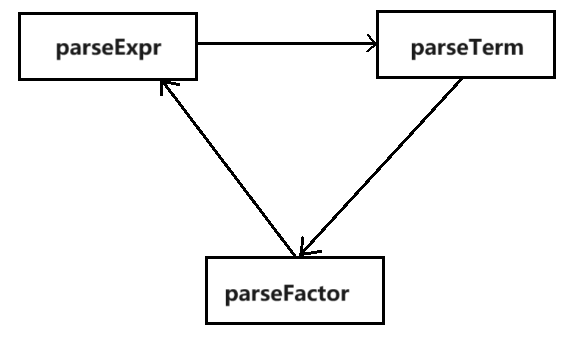
可以归纳为以下几条原则:
遇到左括号解析表达式.
解析表达式时, 调用parseTerm, 遇到+/-号解析表达式; 遇到右括号结束解析; 返回一个Expr, 为解析结果.
解析项时, 调用parseFactor, 遇到*号继续解析因子; 遇到^号, 读取幂次, 并将前个因子的copy放进factors队列(若为0, 删除前面一个因子); 对符号的解析在此处进行(即若为-, 放进一个-1的因子); 返回一个Expr, 为因子相乘的结果.
解析因子均以一个Expr包装返回, 方便进行乘法运算.
业务功能
结合作业具体要求, 从数据组织结构角度出发, 构建了一系列类.
Expr: 表达式类, 维护一个Term类构成的ArrayList, 此表达式即为该数组中Term之和. 为实现性能要求, 提供addTerm方法, 将新的项加入表达式中, 会进行同类项合并.
Term: 项(单项式)类, 维护一个单项. 为整合方法, 实现基础功能, 每个Term对象中存储一个形为a*x^b的项, 其中a, b为带符号整数.
Num: 数字类, 维护一个BigInteger对象.
Var: 变量类, 维护一个变量名name及其幂次(为一个BigInteger对象).
Factor: 因子, 为接口类, 被上述四个类所实现. 提供getTerms方法, 可以将自身封装到一个由Term类构成的可变数组中, 以方便实现乘法/加法功能.
输出部分
没有单独的输出类, 输出功能由Expr和Term类中提供的toString()方法实现.
此处实现存在隐患, 详见bug修复.
为解决深浅拷贝可能带来的问题, 将所有对象设置为不可变对象, 即Expr Term等类中提供的addTerm() mult()等方法, 均返回一个新的对象.
为方便上述方法的实现, 各类提供copy()方法, 返回信息相等的新对象.
实现基础方法, 如两个表达式相加/相乘, 便于拓展功能; 结合Factor接口提供的getTerms()方法, 可以实现封装的因子相乘.
合并同类项, 考虑在表达式中增添新的项时, 遍历合并. 合并时调用Term类的merge()方法.
空的表达式, 含有一个defaultTerm项, 内容为0, 封装在Term类中的静态方法. 这一行为为了统一调用输出方法toString().
本次作业新增内容主要包括三部分: 支持对于多层嵌套括号的解析, 支持自定义函数(最多3个)与指数函数.
嵌套括号
允许多层括号嵌套, 包括exp调用时产生的多层嵌套, 以及三则运算中存在的多层括号, 函数替换时的多层括号(见后)等.
自定义函数
给定自定义函数的个数(0~3)个, 仅允许用f g h表示自定义函数, 形参可以有x y z, 支持对于它们的解析, 并能在最终表达式中进行化简.
指数函数
形如exp()的函数, 调用时最外面一层括号不可省略, 内层为单因子(幂函数, 数字, 函数因子)时不必带括号, 否则应增加一层括号. 如exp(x^5) exp((x^4 + exp(x))).
输入解析
输入解析增加两个新功能: 对自定义函数的处理 & 对exp的读入
对exp的读入, 增加Token.Type.EXP, 并在ReadToken类中支持对其的读入.
对自定义函数的处理: 采用字符串替换的方法进行, 即将函数名称、参数列表、函数体分别存储下来, 如果需要化简的表达式中出现了此函数名, 则将对应实参替换到形参的位置处.
具体实现: 建立FunCustom类实现Function接口中提供的hasFunc() replaceFunc()方法, 前者用来判断一个字符串中是否含有该函数名, 后者用来实现对字符串中该函数的替换.
注意事项: 每一次替换时先对exp字段进行保护, 如先将里面所有的exp均替换成#, 防止将其中的x当作形参; 注意替换顺序, 先替换形参为x的位置, 否则可能出现错误替换; 替换时注意, 每个形参的位置要加括号, 替换后整体也要加括号.
业务功能
业务功能的修改主要体现在: 基本项的定义(即Term的基础形式)发生改变, 如何判断两个项是否能合并. 加入指数函数后, 基本项的形式转变为a*x^b*exp(Expr), 其中a b为常数, Expr为一个表达式. 为了支持判断两个项是否相等, 做了如下改变:
支持空表达式对象, 并且多态化构造方法以适应该要求.
Expr类中增添equals()方法, 若两者都为空, 返回true; 若一个为空, 比较另外一个与new Expr(); 否则枚举检查每一项是否在另一个表达式中出现, 以及另一个表达式中未被配对的项是否为空.
Term类中增添equals()方法, 比较两Term对象的var与expon是否相等.
FunExpon类中实现equals()方法, 比较其括号内的表达式是否相等.
输出部分
输出部分要求仅保留必要的括号, 其余括号全部展开. 由于基本的类建构已经在第一次中实现, 此次迭代主要考虑如何优化到最短长度. 详见优化部分.
记录一个第二次作业调试过程中出现的"灵异现象".
调试与运行结果不同
原因分析: 调试时显示一些监视对象的信息, 自动调用了toString()方法, 而该方法中改变了对象的内部状态(比如清空expr中值为0的项).
经验总结: 命令查询分离原则---Bertrand Meyer 一个方法或函数应该被划分为两个不同的部分:
命令操作(Command):指那些具有副作用的操作,即会修改对象状态或系统状态的操作。命令操作通过改变系统的状态来达到其目的,例如修改数据库、修改对象属性等。命令操作应该返回void,并且不应该返回任何结果。
查询操作(Query):指那些用于获取对象状态或系统状态的操作,它们不会有任何副作用,只是简单地返回结果。查询操作不会修改对象状态,只是对现有数据进行读取和计算,例如获取对象属性、执行某种计算等。查询操作应该返回一个结果,不应该产生任何副作用。
允许函数嵌套定义, 即在定义时可以调用已定义的函数, 不允许含有求导算子.
增加求导算子dx(), 意为括号里的表达式对x求导.
输入解析
嵌套定义: 允许函数定义时调用已定义的函数, 因此可以重复利用第二次作业中的替换方法, 即在处理后续函数定义时, 考虑是否含有已定义函数, 并进行替换操作.
解析求导算子: 增加Token.Type.Dep, 在ReadToken类里面新增dx的解析.
业务功能
在Expr和Term类中新增求导方法departure().
Expr求导 <=> 对其中每个项求导后相加, 若为空, 返回空.
Term求导 <=> 对a*x^b*exp(expr), 结果为a*b*x^{max(b-1,0)}*exp(expr) + a*x^b*exp(expr)
新迭代需求?
考虑最终表达式中可能含有新的变量(如y z ans), 则相应的修改isEquals()方法, 调用equalPower()方法时, 对不同的变量分别判断是否等幂次. 同时, Var类型应该增添一个容器(如HashMap), 用来管理该对象中所有的变量名以及对应幂次. 读入则无需更改, 因为前面已经实现不同变量名的读入.
第三次作业的互测环节中, 出现了一个bug.
类型: TLE
数据:
2
g(z)=exp(exp(exp(exp(z))))
f(y)=exp(exp(exp(exp(g(y)))))
f(g(exp(exp(exp(exp(x^8))))))
bug定位: 利用IDEA方法运行时间相关数据, 定位到超时的原因在于对toString()方法的不当调用.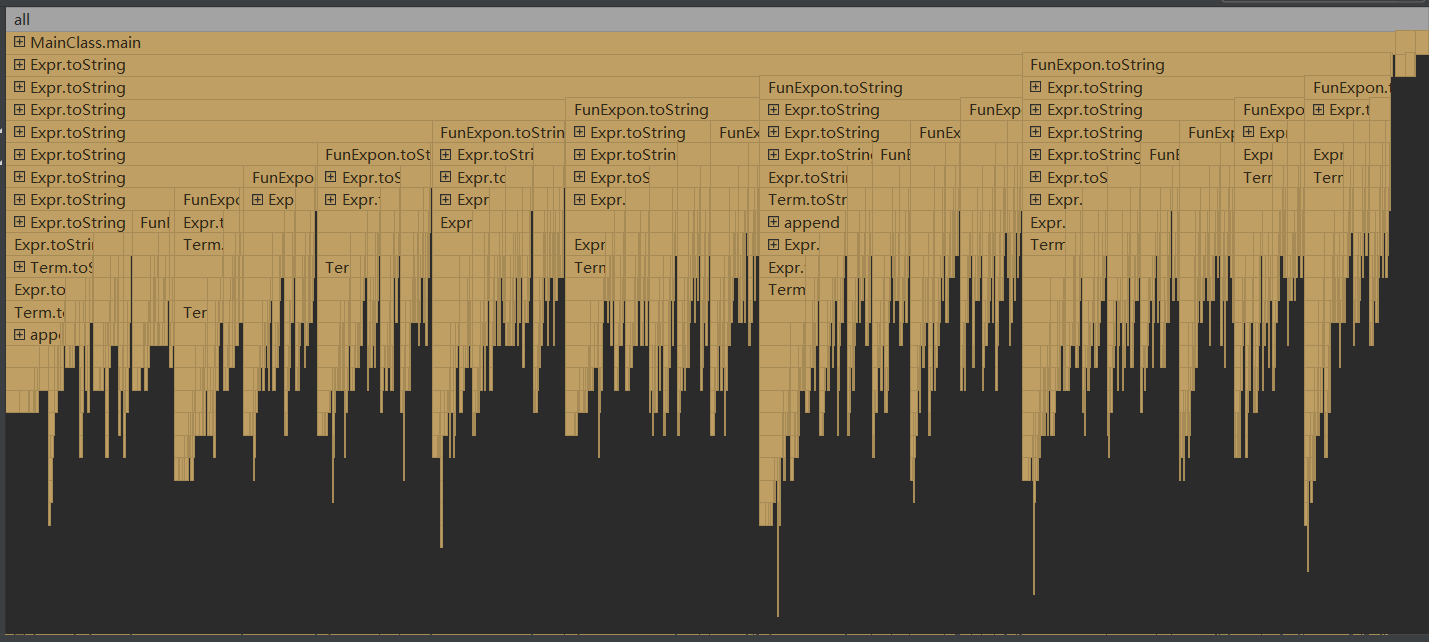
解决方法: 定义一个临时变量存储Term.toString()的返回结果, 减少反复调用带来的时间损耗.
更改前:
更改后: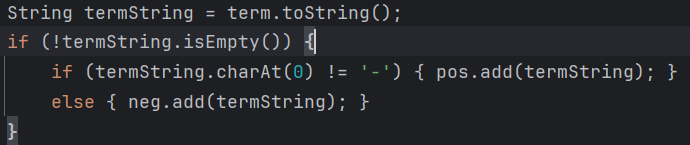
复杂度分析: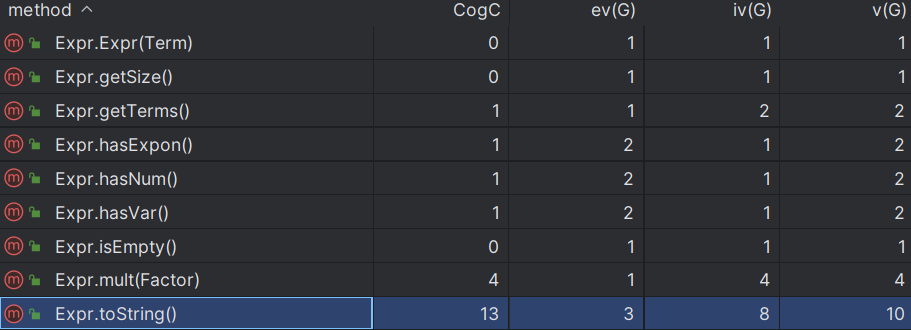 相较于其他方法来说, 此处代码较为复杂, 出现错误的概率大, 运行时间可能会更长.
相较于其他方法来说, 此处代码较为复杂, 出现错误的概率大, 运行时间可能会更长.
边界测试 + 强度测试 + 代码分析
边界测试: 选用具有特殊意义的样例, 检测程序是否能够正确处理边界情况. 如第二次作业中选用的hack数据(考虑0的处理):
0
exp((exp(x)+exp((x-x-x)))) + exp((x-x))+exp(-1)
强度测试: 使用数据生成器大量生成具有一定强度的数据, 如果对拍结果不一致, 对代码进行分析, 对发现问题的数据进行化简, 以达到hack的目的. 如第三次作业中选用的hack数据, 原始数据为:
1
f(z )= +z^8*z^ +2 *z^3 -+-11*z^+2 * 19 + z^02* exp(z^ +0)* z^7
exp(x^+2) *f (-7 )*dx(exp(f( x^3)) )
exp(x^+2) *h (x^3, exp (19))*f (-7 )*dx(exp(f( x^3)) ) ++9*dx(x^ 8 )*dx(+9) * x^ +2- exp(( + dx(x ^4)) )*h (+18, x ^3 )* exp(8)*dx(x^ +2
经过代码分析, 发现问题出在乘法合并同类项有问题, 于是将数据点化简为:
1
f(z)=z+z*exp(z^0)
exp(x^2)*f(7)*dx(f(x))
代码分析: 通过分析代码, 找到可能遗漏的情况, 从而针对性发起hack. 如第三次作业中, 发现有些同学处理求导算子时, 递归层数过多, 可能引发超时, 于是针对性设计数据点:
0
dx(exp(exp(exp(exp(exp(exp(exp(exp(x^2)))))))))
总的来说, hack时一定要结合源代码, 这样能够分析bug的成因, 进而进行有针对性地hack, 减少对同质bug进行反复hack.
在充分合并同类项之后, 将正项在负项前输出, 能够减少一个正号的长度. 如1-x比-x+1短一个字符. 因此, 在输出时, 将正负项分别存储, 先输出正项, 即可使长度变短.
version1: 减少exp输出时的括号层数, 可以判断exp里面是否只是一个因子.
一定能化简长度, 事实证明越简单的越有效.
version2: 提最大公因数, 并与不提的情况比较.
不一定最优, 如exp((20*x^2 + 30)), 最优为exp((4*x^2+6))^5, 而不是exp((2*x^2+3))^10
version3: 提公因数, 并取输出长度最短的.
基于上述反例给出的解决方法. 上述反例告诉我们, 最优的情况其实与提出公因数的位数及里面减少的位数有关.
即: 在提出公因数位数相同的情况下, 只需要里面减少的位数最多.
换句话说, 提出9一定比提出4要好, 因为提出9后, 里面减少的位数不小于提出4的情况.
所以只需要找到同样长度的因子中最大的那个, 计算提出后的长度即可.
作者注: 有大佬对下述例子做了优化: exp((3*x+2*x^2+2*x^3+2*x^4+2*x^5)) ----> exp((x+x^2+x^3+x^4+x^5))^2*exp(x)
在优化的过程中,采用版本递进的方式。即保证正确性的前提下,进行下一步的优化;在进行下一步优化时,(尽量)不去修改业务功能,而只针对输出进行优化,这样能够最大程度地保证代码块的正确性,也减小了测试的难度(即每次只需要对新增优化部分进行测试)。
OO Unit1 完结撒花!
第一次作业工作量较大, 需要综合考虑必要的功能以及后续可能的扩展, 为后续工作提供一个良好的架构; 同时, 一些重复代码(或者后续可能重复利用的代码)最好新建方法, 以便后续利用. 第二次作业增加的功能较为复杂, 输出时的优化难度也提高了. 第三次作业改动较小, 如果前两次轮子造的好, 总体工作量将在半小时以内.



