


301
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享在这一部分,我将主要对比1、3两次的代码,以展示不足与改进
因为在后文需要对比分析,所以我先来介绍一下代码设计思路:
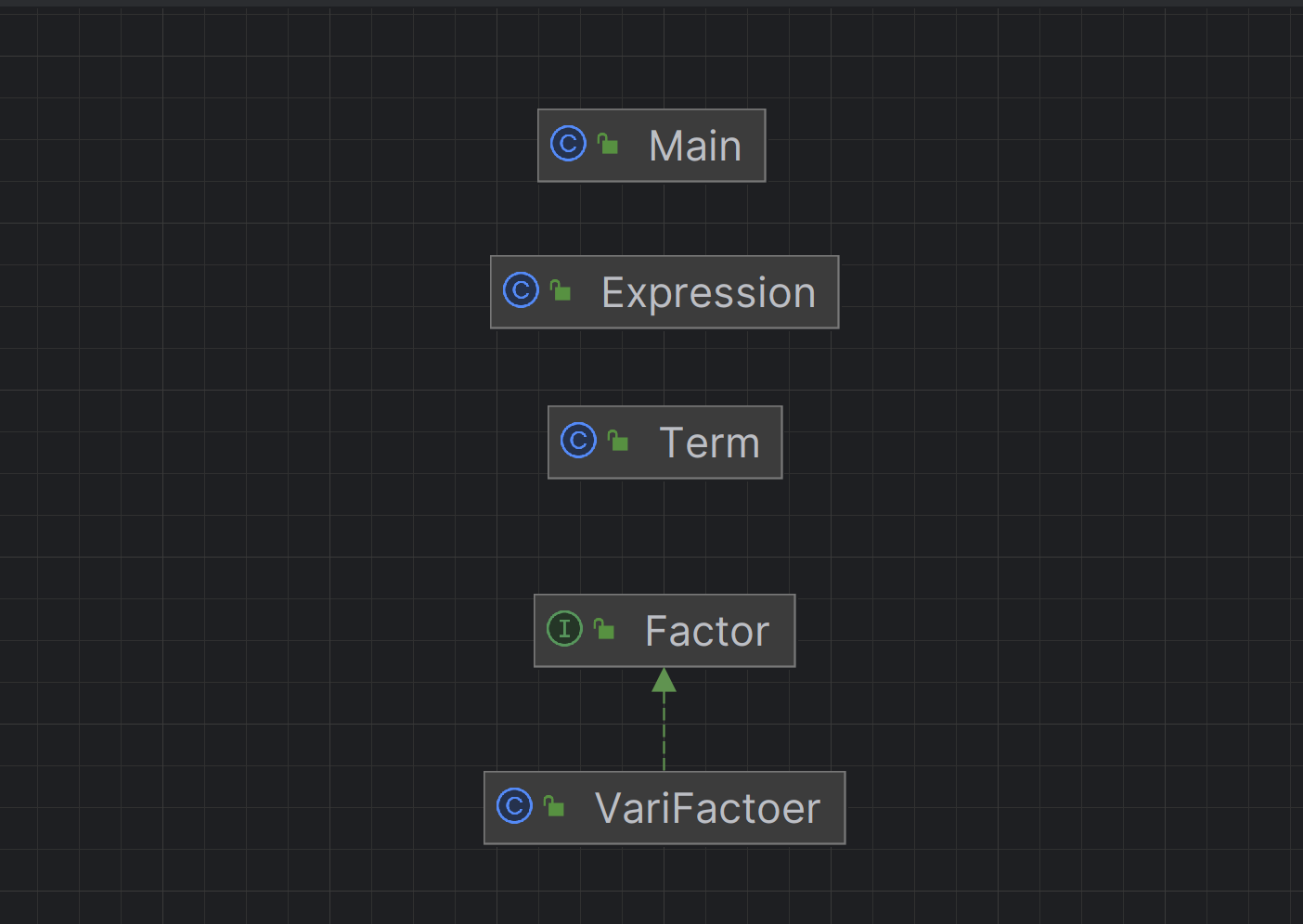
第一次作业:天才般的史山
在第一次作业中,我的想法很简单:直接写一个while循环,寻找括号,并对括号里面的东西重新调用该循环,之后用字符串操作的方式拆掉括号,任务结束。主打一个简单粗暴
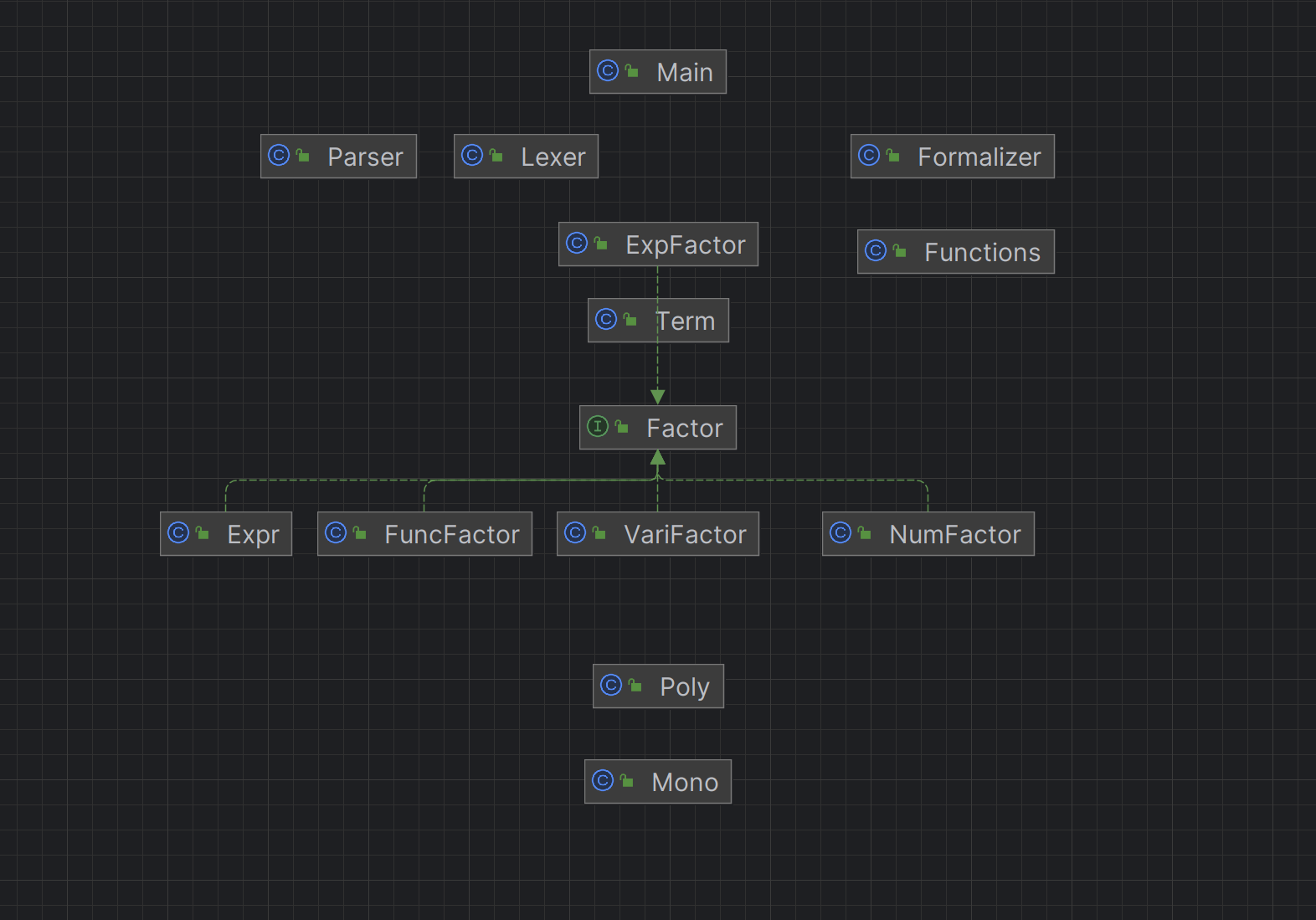
第2&3次:标准化递归下降 + 单多项式
设计了poly与mono,将建树与计算分开来,先建立表达式树,然后调用poly,最后再将poly转化为string
关于复杂度分析方法的复杂度分析主要基于循环复杂度的计算。循环复杂度是一种表示程序复杂度的软件度量,由程序流程图中的“基础路径”数量得来。
CogC 认知复杂度: 表示程序中的独立路径数目
ev(G) 基本复杂度:是用来衡量程序非结构化程度的,非结构成分降低了程序的质量,增加了代码的维护难度,使程序难于理解。因此,基本复杂度高意味着非结构化程度高,难以模块化和维护。实际上,消除了一个错误有时会引起其他的错误。
iv(G) 模块设计复杂度:设计复杂度是用来衡量模块判定结构,即模块和其他模块的调用关系。软件模块设计复杂度高意味模块耦合度高,这将导致模块难于隔离、维护和复用。模块设计复杂度是从模块流程图中移去那些不包含调用子模块的判定和循环结构后得出的圈复杂度,因此模块设计复杂度不能大于圈复杂度,通常是远小于圈复杂度。
v(G) 圈复杂度:是用来衡量一个模块判定结构的复杂程度,数量上表现为独立路径的条数,即合理的预防错误所需测试的最少路径条数,圈复杂度大说明程序代码可能质量低且难于测试和维护,经验表明,程序的可能错误和高的圈复杂度有着很大关系。
HW3
| Method | CogC | ev(G) | iv(G) | v(G) |
|---|---|---|---|---|
| DxFactor.DxFactor(Expr) | 0 | 1 | 1 | 1 |
| DxFactor.toPoly() | 0 | 1 | 1 | 1 |
| ExpFactor.ExpFactor(String) | 2 | 1 | 1 | 2 |
| ExpFactor.toPoly() | 0 | 1 | 1 | 1 |
| Expr.Expr() | 0 | 1 | 1 | 1 |
| Expr.addToterms(Term) | 0 | 1 | 1 | 1 |
| Expr.toPoly() | 1 | 1 | 2 | 2 |
| Formalizer.Formalizer(HashMap<Character, String>, String, ArrayList) | 0 | 1 | 1 | 1 |
| Formalizer.addFunc(char, String) | 0 | 1 | 1 | 1 |
| Formalizer.call(char) | 0 | 1 | 1 | 1 |
| FuncFactor.FuncFactor(Expr) | 0 | 1 | 1 | 1 |
| FuncFactor.toPoly() | 0 | 1 | 1 | 1 |
| Functions.Functions(ArrayList, String) | 0 | 1 | 1 | 1 |
| Functions.operate() | 6 | 4 | 5 | 6 |
| Lexer.Lexer(String) | 0 | 1 | 1 | 1 |
| Lexer.getNextToken() | 0 | 1 | 1 | 1 |
| Lexer.next() | 14 | 2 | 10 | 16 |
| Main.main(String[]) | 4 | 2 | 5 | 5 |
| Main.stringProduce(String) | 0 | 1 | 1 | 1 |
| Mono.DxMono(Mono) | 9 | 5 | 7 | 7 |
| Mono.Mono(String, String, String) | 0 | 1 | 1 | 1 |
| Mono.changeNum(BigInteger) | 0 | 1 | 1 | 1 |
| Mono.generateString() | 35 | 10 | 11 | 16 |
| Mono.getExpIndex() | 0 | 1 | 1 | 1 |
| Mono.getIndex() | 0 | 1 | 1 | 1 |
| Mono.getNum() | 0 | 1 | 1 | 1 |
| Mono.monoMult(Mono, Mono) | 5 | 4 | 5 | 5 |
| NumFactor.NumFactor(String) | 0 | 1 | 1 | 1 |
| NumFactor.toPoly() | 0 | 1 | 1 | 1 |
| Parser.Parser(Lexer) | 0 | 1 | 1 | 1 |
| Parser.parserDx() | 7 | 1 | 3 | 6 |
| Parser.parserExpFactor() | 9 | 2 | 4 | 8 |
| Parser.parserExpr() | 1 | 1 | 2 | 2 |
| Parser.parserFactor() | 33 | 8 | 16 | 20 |
| Parser.parserFuncFactor() | 15 | 1 | 9 | 12 |
| Parser.parserNum(int) | 2 | 1 | 2 | 2 |
| Parser.parserTerm() | 1 | 1 | 2 | 2 |
| Parser.parserVari() | 2 | 1 | 2 | 2 |
| Poly.Poly() | 0 | 1 | 1 | 1 |
| Poly.addToPoly(Mono) | 6 | 1 | 4 | 4 |
| Poly.generateString() | 3 | 1 | 3 | 3 |
| Poly.polyAdd(Poly, Poly) | 3 | 1 | 3 | 3 |
| Poly.polyDx() | 3 | 1 | 3 | 3 |
| Poly.polyMult(Poly, Poly) | 10 | 1 | 5 | 5 |
| Poly.polyPower(Poly, Integer) | 4 | 2 | 3 | 3 |
| Term.Term() | 0 | 1 | 1 | 1 |
| Term.addToFactor(Factor) | 0 | 1 | 1 | 1 |
| Term.toPoly() | 1 | 1 | 2 | 2 |
| VariFactor.VariFactor(String) | 0 | 1 | 1 | 1 |
| VariFactor.toPoly() | 0 | 1 | 1 | 1 |
HW1
| Expression.Expression(String) | 0 | 1 | 1 | 1 |
|---|---|---|---|---|
| Expression.deleteBracket(int, int, String) | 14 | 7 | 10 | 12 |
| Expression.extending(String) | 19 | 2 | 7 | 8 |
| Expression.findAdd(String) | 3 | 3 | 2 | 3 |
| Expression.findIndex(String) | 3 | 1 | 2 | 3 |
| Expression.findLeftBracket(String) | 3 | 3 | 2 | 3 |
| Expression.findOperation(String) | 4 | 3 | 4 | 5 |
| Expression.findRespondBracket(String) | 8 | 5 | 3 | 5 |
| Expression.getStr() | 0 | 1 | 1 | 1 |
| Expression.rebuild(String) | 8 | 4 | 4 | 6 |
| Main.findAdd(String) | 3 | 3 | 2 | 3 |
| Main.main(String[]) | 1 | 1 | 1 | 2 |
| Term.Term(String) | 0 | 1 | 1 | 1 |
| Term.changeNum(BigInteger) | 0 | 1 | 1 | 1 |
| Term.findIndex(String) | 3 | 1 | 2 | 3 |
| Term.findMul(String) | 3 | 3 | 2 | 3 |
| Term.findName(String) | 5 | 3 | 5 | 6 |
| Term.getName() | 0 | 1 | 1 | 1 |
| Term.getNumber() | 0 | 1 | 1 | 1 |
| Term.getProduced() | 0 | 1 | 1 | 1 |
| Term.initializeName() | 2 | 2 | 2 | 2 |
| Term.operate() | 51 | 5 | 21 | 24 |
| Term.refreshProduced() | 6 | 1 | 3 | 4 |
| Term.returnForm() | 0 | 1 | 1 | 1 |
| VariFactoer.VariFactoer(String, String) | 0 | 1 | 1 | 1 |
| VariFactoer.changeIndex(String) | 0 | 1 | 1 | 1 |
| VariFactoer.getIndex() | 0 | 1 | 1 | 1 |
| VariFactoer.getName() | 0 | 1 | 1 | 1 |
| VariFactoer.gettype() | 0 | 1 | 1 | 1 |
| VariFactoer.operate() | 0 | 1 | 1 | 1 |
现在,让我们对两次作业的核心方法进行分析:
可以明显看出,两次作业的核心方法复杂度都不低,但是可以看出,hw1中数值相当集中,比如Term.operate()方法。这是由于暴力计算违反了职责单一化原则,并且与其他方法关系紧密,作为核心很容易出现难以检查的错误,这也正是hw1可扩展性差最终导致第二周重构的原因
这种C-style的编程方式其实并不是一无是处,在处理简单问题时,这类方式可以大大降低代码量和思维量,但在多次迭代开发中可维护性太差,所以这次重构算一次深刻教训了
而对于HW3,其中依然有复杂度高的方法,这类方法通常是出口过多,分类太多导致的,比如poly.generateString 这个方法,我为了可以生成常数、变量、exp三种因子各种组合的字符串而设计了8个出口,而poly本身又需要两层hashmap,导致了复杂度过高。这里其实可以考虑进一步封装并细化职责
先简单介绍一下
| Class | Cyclic | Dcy | Dcy* | Dpt | Dpt* | PDcy | PDpt |
|---|---|---|---|---|---|---|---|
| Expression | 0 | 2 | 3 | 1 | 1 | 1 | 1 |
| Main | 0 | 1 | 4 | 0 | 0 | 1 | 0 |
| Term | 0 | 1 | 2 | 1 | 2 | 1 | 1 |
| VariFactoer | 0 | 1 | 1 | 2 | 3 | 1 | 1 |
| Interface | Cyclic | Dcy | Dcy* | Dpt | Dpt* | PDcy | PDpt |
| Factor | 0 | 0 | 0 | 1 | 4 | 0 | 1 |
HW3
| Class | Cyclic | Dcy | Dcy* | Dpt | Dpt* | PDcy | PDpt |
|---|---|---|---|---|---|---|---|
| DxFactor | 9 | 3 | 12 | 1 | 11 | 1 | 1 |
| ExpFactor | 9 | 3 | 12 | 1 | 11 | 1 | 1 |
| Expr | 9 | 4 | 12 | 5 | 11 | 1 | 1 |
| Formalizer | 0 | 0 | 0 | 2 | 12 | 0 | 1 |
| FuncFactor | 0 | 3 | 13 | 0 | 0 | 1 | 0 |
| Functions | 0 | 0 | 0 | 1 | 12 | 0 | 1 |
| Lexer | 0 | 0 | 0 | 3 | 12 | 0 | 1 |
| Main | 0 | 5 | 13 | 0 | 0 | 1 | 0 |
| Mono | 9 | 4 | 12 | 7 | 11 | 1 | 1 |
| NumFactor | 9 | 3 | 12 | 1 | 11 | 1 | 1 |
| Parser | 9 | 12 | 12 | 2 | 11 | 1 | 1 |
| Poly | 9 | 1 | 12 | 11 | 11 | 1 | 1 |
| Term | 9 | 3 | 12 | 2 | 11 | 1 | 1 |
| VariFactor | 9 | 3 | 12 | 1 | 11 | 1 | 1 |
| Interface | Cyclic | Dcy | Dcy* | Dpt | Dpt* | PDcy | PDpt |
| Factor | 9 | 1 | 12 | 8 | 11 | 1 | 1 |
这里出现了一件很有意思的事情:作为一坨*山的第一次作业代码依赖度反而低得多,这其实是因为当时代码构筑思路过于简单,除了主类之外,每个类只会与一个上级与一个下级交换数据。但这种构筑模式违反了单一职责原理,使得每个类都有许多事要做,其实反而不便于理解与debug
在hw3中,可以看到,越是核心的类,比如parser,依赖度就不可避免的高。这确实对debug造成了一定影响,在单步调试时反复横跳十分麻烦,所以我认为仍存在优化空间。应该可以对一些类实现进一步包装,放在同一个接口下,合并依赖,来降低依赖度,这将有利于阅读
话不多说,直接上图(快端上来罢)
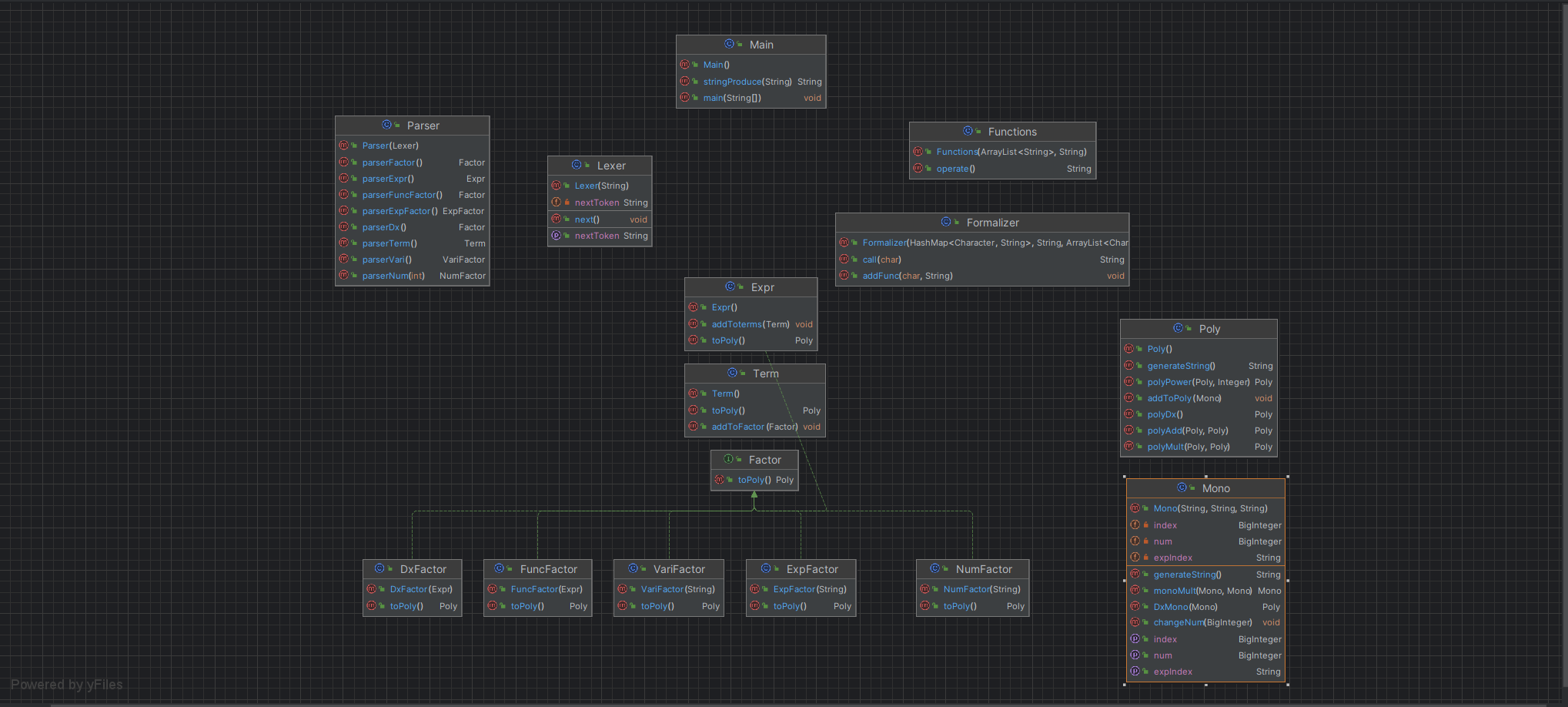
这里我想说一说文法分析器的重要性。一位不愿透露姓名的岳某雨学长曾说,lexer就是一个提取器,它根本不知道自己读的是什么,它只做匹配,读什么就弹出什么。那么我为什么一定要写他呢?因为这个lexer更底层的作用是控制程序进程。这就好像我把字符串放在一个箱子里,按一下按钮就弹出来一个碎片,parser看见碎片,把碎片拼在表达式树合适的位置。有些碎片是负责定位的,比如“)”就说明该回到上一层了,有些碎片是数据,比如“1268162”这种数据,但这和我lexer没关系,lexer只知道把最小单元切下来。那么什么时候就知道树建好了呢?当然是按按钮吐不出来东西的时候。这种程序控制分担了职责,独立于递归之外,无论在那一层递归都使用同一个lexer返回的碎片,进行信息分析。这便是lexer的优越性。
另一个好处就是debug很方便。当你发现某个地方读不下去了,那必然是没有按按钮,就是没有读下一个token,其他括号对不上或者数据读不全的bug在原理上就不可能存在
这个其实是我很得意的一个设计,但很遗憾在重构之后没有勇气能进一步实现,只进行了一些小尝试
我在读入字符串后,用大量replace进行了字符串标准化,比如连续符号替换,以及把“-”替换为“+-1*”
后者是一个很有意思的设计:用这样的方式替换使得项之间的运算只剩下了加法,使得分割与生成都十分方便,BigInt这个类也能识别负号,所以只需要最后输出时候替换回来就好了
更神奇的是我第一次的设计,我将“-”替换成了“+i*”,i是一个符号标记,最后在合并时候将偶数个i替换为+,奇数个替换为-,这样处理后表达式中只剩下了+ * ^ 更加有利于字符串操作,但可惜在后续的迭代中并没有使用,显得有些鸡肋
关于可扩展性,由于在第一次吃了大亏,第二次就进行了全面调整与布局,主要体现在两个方面:基本项与因子。基本项由不可拆解因子组成,如变量、常数、exp;而因子则是各类新增功能
当加入一个新功能时,如果是不可拆解的,就多一个就基本项的成员,如果是运算类,比如求导,就多一个因子。基本不需要修改其他代码
目前代码不存在bug,但优化不怎么多,这可能是将来可以改进的地方
至于底层逻辑的问题,我认为还是基本项的扩展性:当修改基本项时,不可避免会对多项式的运算与存储造成影响。目前已经是两层hashmap,如果加入更多因子,会导致进一步的嵌套,不是很美观,需要进一步考虑
我在互测的主要想法其实很简单,测试歪门邪道的数据点。比如单个常数,变量,比如计算结果是0但是过程极其复杂的式子。其实我没有评测机,所以在这个部分我并没有多少发言权QAQ
毕竟也是第一次互测,问题也真不少,只能说之后再慢慢思考慢慢解决
技术性的东西已经说完了,这里其实只是一些习惯上的思考。先抛出一个问题:
究竟什么时候应该开始写代码?
这并不是说周二或者周三的问题,而是在准备到哪一步开始动手的问题:袁老师在第一节课就说,不能直接写,也不应该全想明白再动手期望写出一个“perfect code”
先叠甲,袁老师的建议是对的,但问题在于这个回答太模糊了,就好比让你从0到1之间挑选一个数字,然后说0和1是错的,剩下的范围还是很大。
我想在这里给出我的思考:写出一个底层逻辑,然后动手
什么是底层逻辑?其实就是实现方法,它包括具体的类大概有几种,每种承担什么职责,以及,可扩展性怎么样。这个并不是说“貌似可以扩展就行”,而是一定要思考代码量与可读性,可读性低 = 不可扩展
当然这是我给出的建议,各位看官如果觉得“这不是是个人都知道?”或者“荒谬至极根本没用”就当看个笑话吧
这次作业总体来说感觉真的不错,能学到不少东西,有一点点体验差的地方就是重构的那周。重构真的很需要勇气,也很需要时间,但这大概是学习所必须经历的罢(笑)
关于未来方向,我觉得其实没什么需要提升的,这个单元真的很不错了
(或许可以在课上深入讲讲递归下降?以免让我这类看不懂的蒟蒻走弯路?或许诸位大佬不需要所以课程组没加吧mol2333)



