


301
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
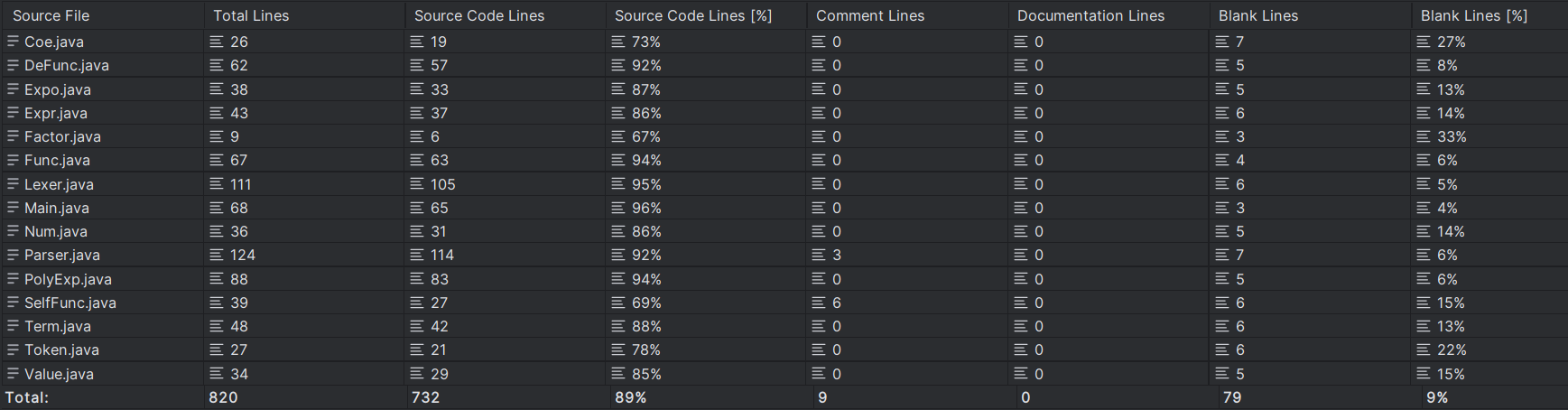
分享OO第一单元主要要求将一个表达式展开、化简,同时要求化简结果正确而且不能带有不必要的括号。迭代逐步扩展功能的实现。
第一次作业总体难度不高,只有加减乘乘方运算,并且只有一层括号,也只有数字和x这两种底层因子。

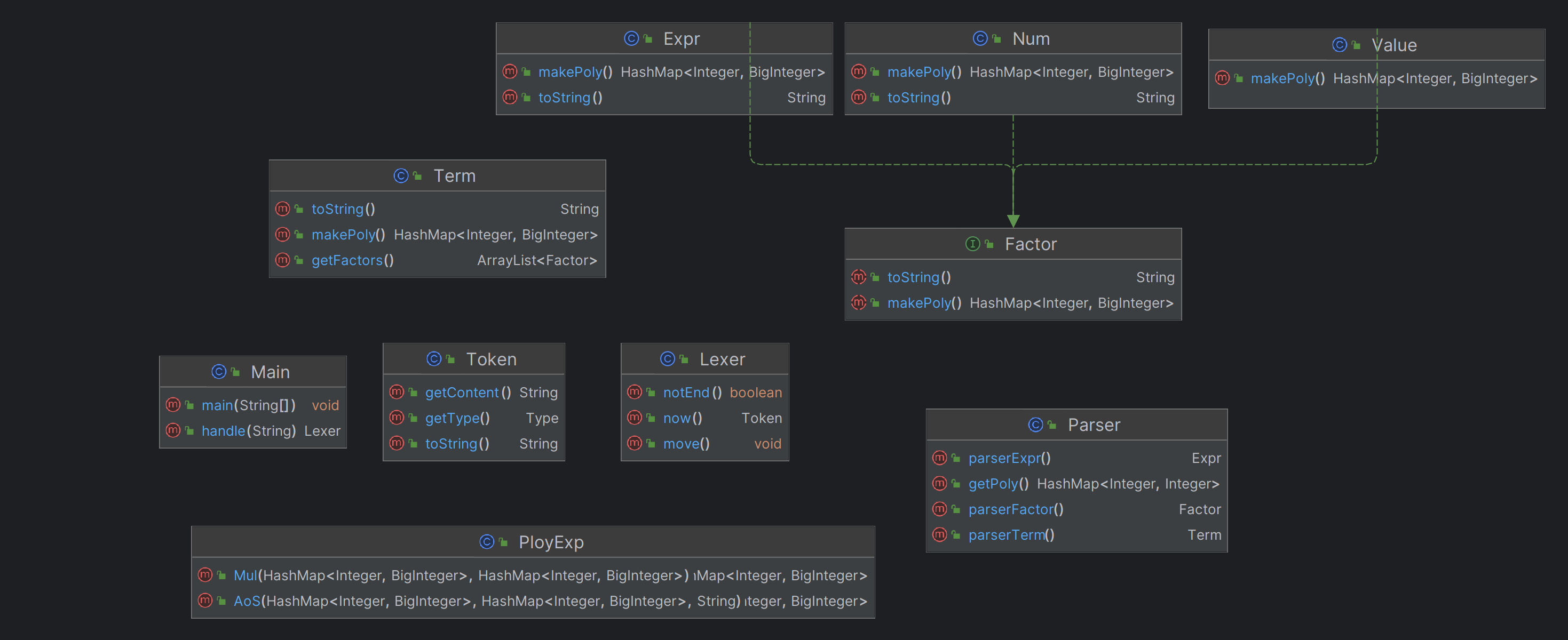
代码将近500行,其中用于储存表达式的类都未超过40行,进行主要的解析和运算的类都未超过100行。

参数解释
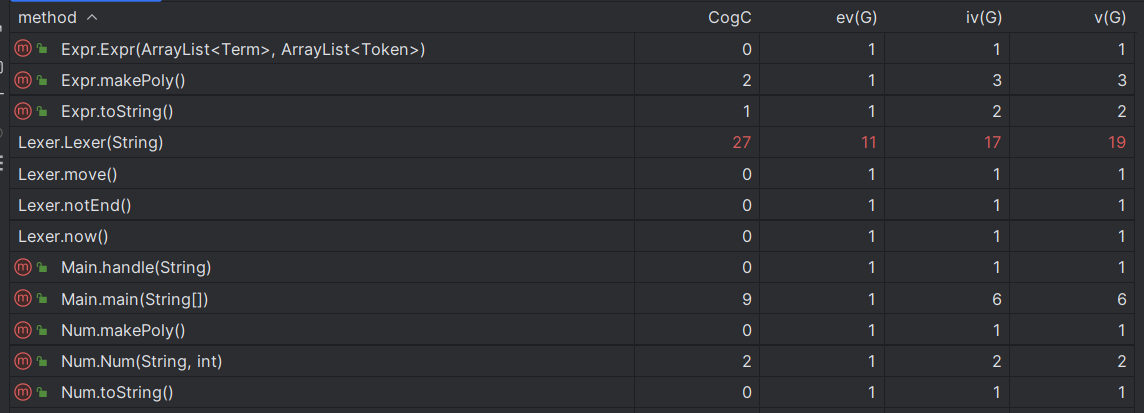
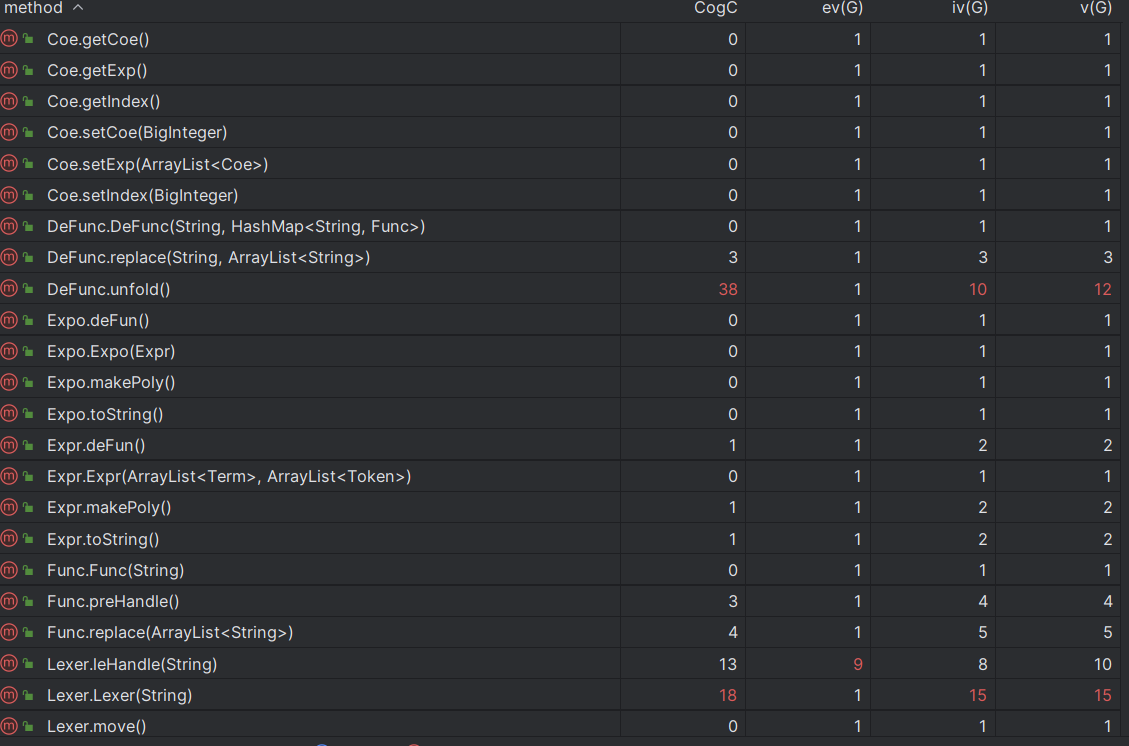
cogC(cognitive complexity): 方法的认知复杂度是指方法的实现难度和理解难度。这包括方法中的控制流程、数据结构、算法和逻辑等方面。认知复杂度高的方法可能需要更多的时间和精力来理解和实现,同时也可能更容易出错。因此,在设计和编写方法时,需要考虑其认知复杂度,以便提高代码的可读性和可维护性。
ev(G): 基本复杂度是用来衡量程序非结构化程度的,非结构成分降低了程序的质量,增加了代码的维护难度,使程序难于理解。因此,基本复杂度高意味着非结构化程度高,难以模块化和维护。实际上,消除了一个错误有时会引起其他的错误。
iv(G): 模块设计复杂度是用来衡量模块判定结构,即模块和其他模块的调用关系。软件模块设计复杂度高意味模块耦合度高,这将导致模块难于隔离、维护和复用。模块设计复杂度是从模块流程图中移去那些不包含调用子模块的判定和循环结构后得出的圈复杂度,因此模块设计复杂度不能大于圈复杂度,通常是远小于圈复杂度。
v(G): 是用来衡量一个模块判定结构的复杂程度,数量上表现为独立路径的条数,即合理的预防错误所需测试的最少路径条数,圈复杂度大说明程序代码可能质量低且难于测试和维护,经验表明,程序的可能错误和高的圈复杂度有着很大关系。
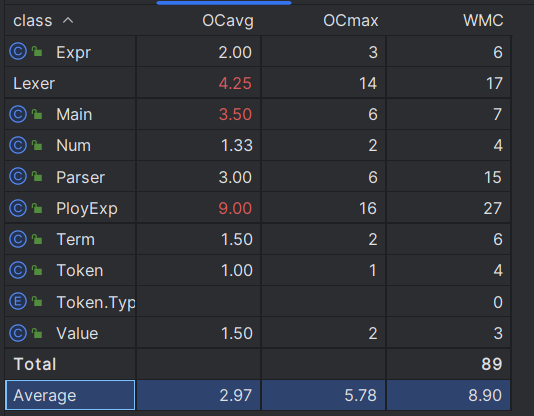
可以看到,我写的程序在自己定义的关于过程的函数复杂度较高,而直接调用已存在的函数的复杂度则较低。
第一次作业难点有两个重要的地方。
第一个在于对于表达式的预处理,即处理连续的符号和去空格等操作。
第二个在于如何对表达式进行递归解析,递归下降法起到了非常重要的作用。
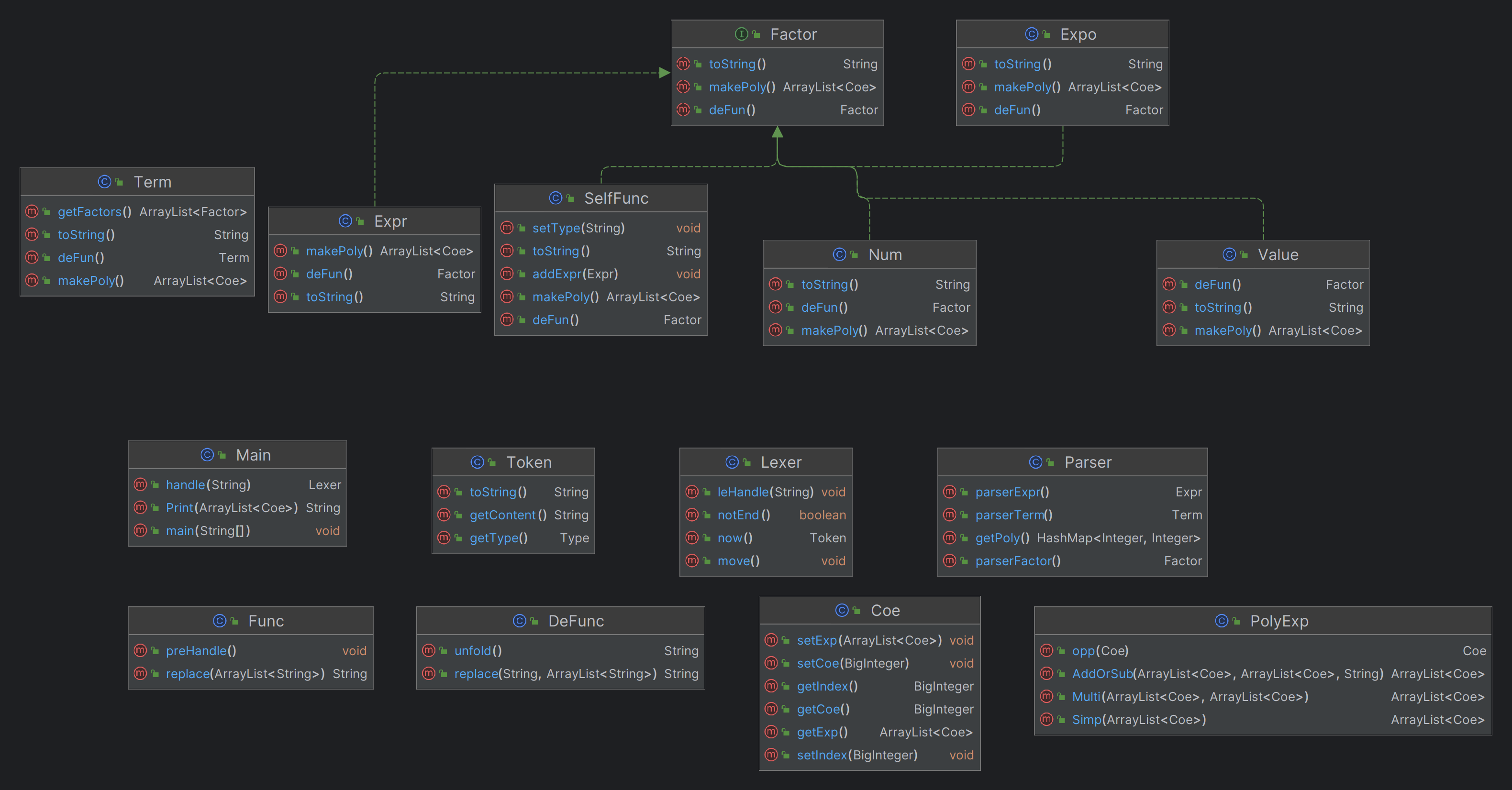
我的架构主体分为三部分,分别为预处理部分,解析并生成表达式树部分和运算化简部分。
这一部分的主体思路就是去除空格,然后把连续出现的运算符进行一个化简,达到两个项中间只有一个运算符的结果。最后把字符存入Token类中。
解析部分对Tokens的数组进行处理,按Expr-Term-Factor-Expr的顺序递归解析,生成一个以类为主体的树。顶层是一个Expr类,Expr类中存有Term类的数组,Term类中存有Factor的数组。Factor是一个接口,可以扩展为Expr类,Num类,Value类,从而实现将表达式存在一颗树内。
在这一部分只需要定义一个运算函数,然后对表达式树顶层的Expr进行该方法的调用即可完成。在这里我使用的是HashMap的形式,因为在该次作业只有num和x的n次幂。所以可以用n做key、num做value进行储存和运算,这样会比较方便。但是问题是可扩展性差,在后面会提到。
在hw1我出了一个bug,在预处理部分。我在预处理部分没有考虑到"("后会直接跟一个"+"的情况,导致运算顺序错位,加减法运算多执行一次,直接把第一个乘法因子进行了一次相加。
优点:类的封装比较充分,每个储存类只负责一种储存内容和其具有的功能,运算类也只有运算功能和其具体实现方式。具有高内聚、低耦合的特点
缺点:没有考虑预留用于扩展的地方,也没有考虑到方法的通用性,导致后面的迭代必须重构。
第二次作业新增了括号嵌套和指数函数,我在指数函数处理的时候吃了大亏。

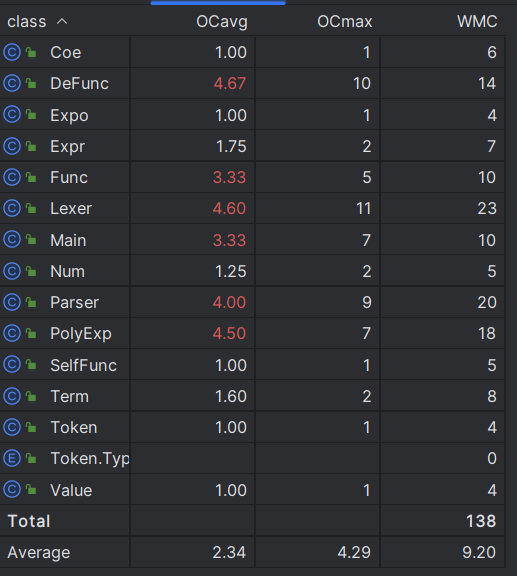
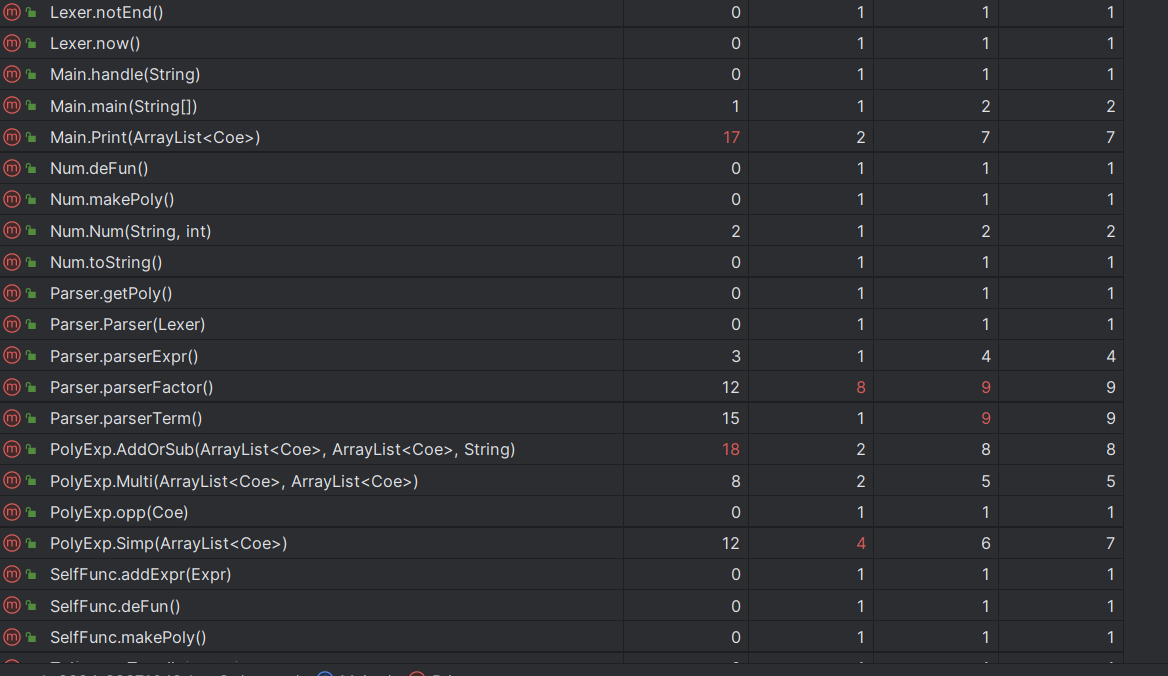
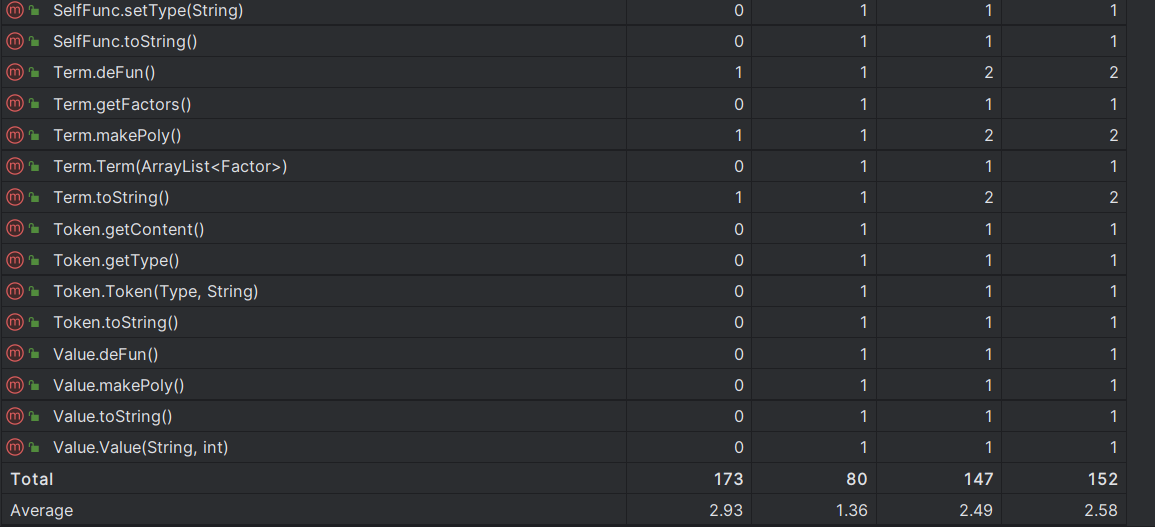
总体来说自定义的运算方式复杂度就比较高,比如用于储存自定义函数的Func类,用于替换自定义函数的Defunc类、用于解析的Lexer类和Paser类,定义化简运算的PolyExpr类。
本次作业有两个难点,第一个是如何进行自定义函数的替换,第二个是指数函数如何储存和表示。
第一个我的处理方式是在字符串层面进行替换。这样做的好处是不需要对lexer类和paser类进行大改,缺点是处理的过程比较复杂,需要考虑到各种情况,容易出错。
第二个我的处理方式是新建Coe类,里面有BigIntege用于储存系数和x的指数,有ArrayList用于储存指数函数。这样就形成了一个递归调用的方式来解决这指数函数问题。
本次架构新增了exp、func、defunc、coe四个类,其中func类用于储存自定义函数,defunc类用于对表达式做字符串层面的替换,exp为factor的接口之一,用于定义指数的运算。coe是项类,用于储存一项的系数、幂和指数,本次项的存储方式为ArrayList,运算也以数组遍历的方式进行。
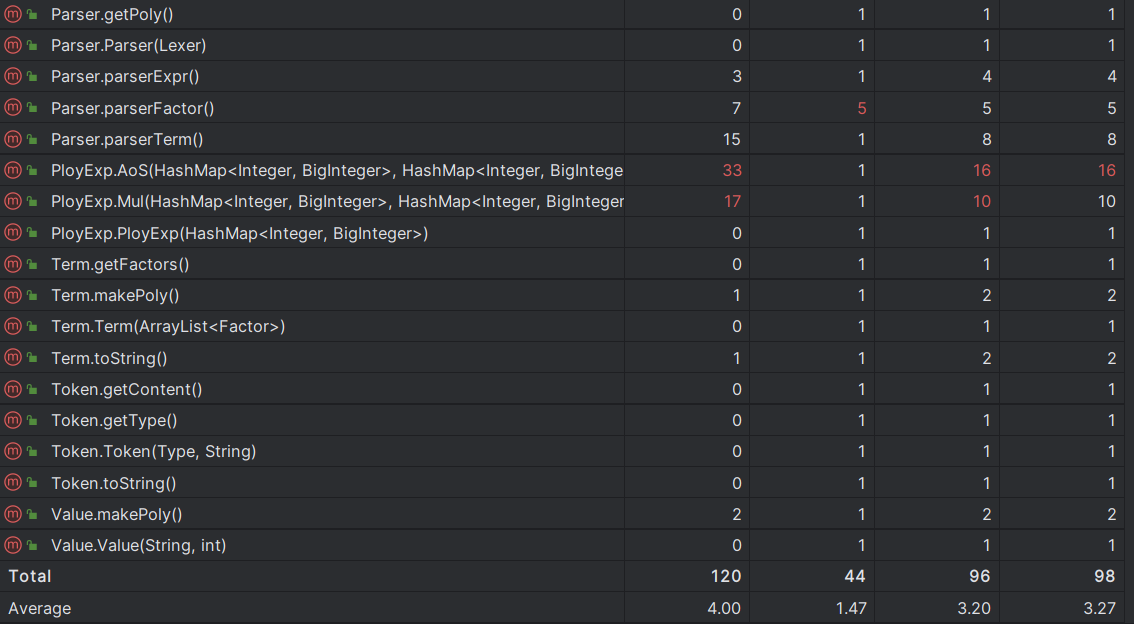
由于我采用了乘方在token级别的降维运算,所以会出现运算时间很长的问题,本次测试有一个问题是x^8叠加11次,我的算法相应的运算时间也会指数增长,最终超时,经过我自己的计算该测试数据需要5个小时左右才能完成运算。实际上是由于压力测试出现的bug,属于算法架构问题。
优点:方法的经过修改之后可扩展性强,实现方式仍然高内聚,低耦合,易于理解和使用。
缺点:算法的时间复杂度仍然较高,容易被压力测试使程序崩溃。同时输出优化算法也有问题,输出的长度比较长。
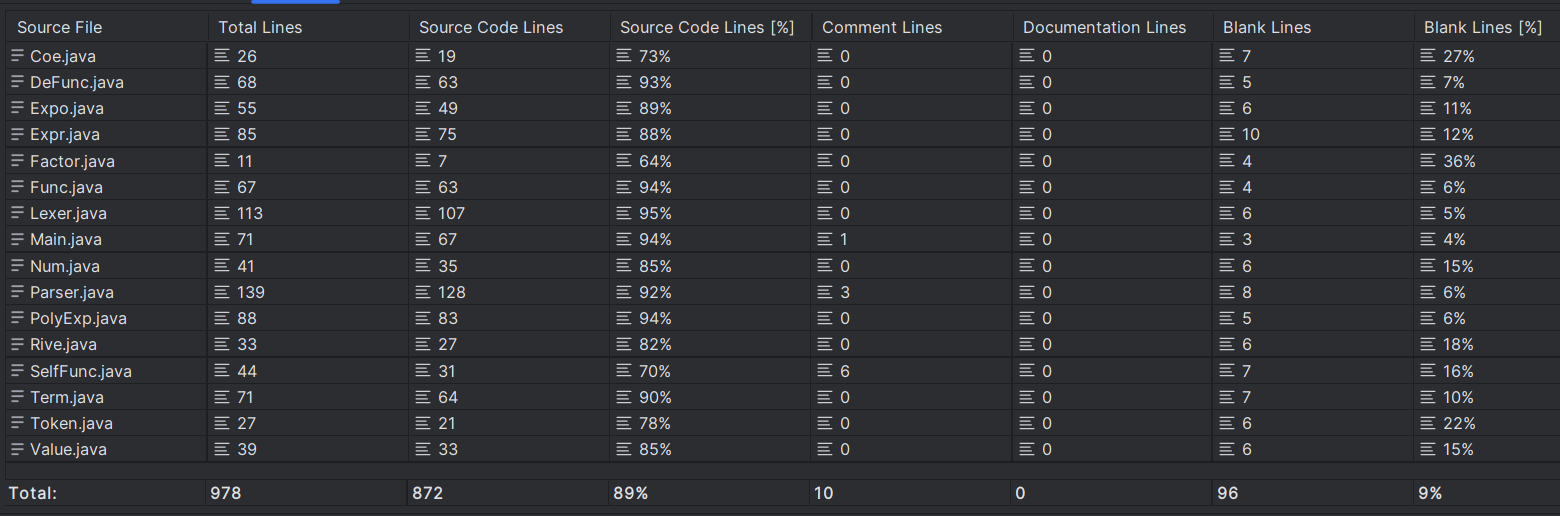
本次代码增量不多,只新增了导数类,求导功能,并对储存的式子加入了求导运算。
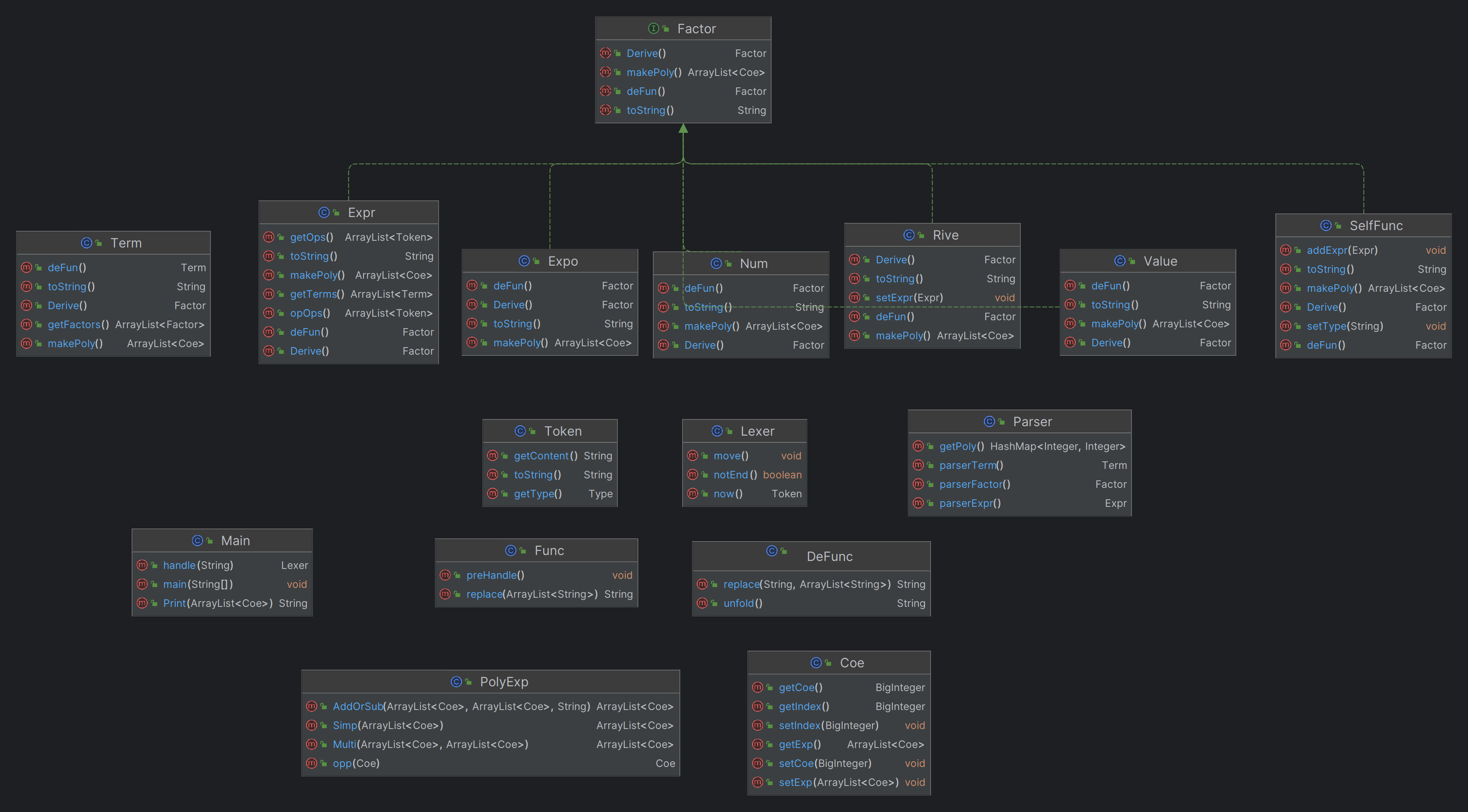

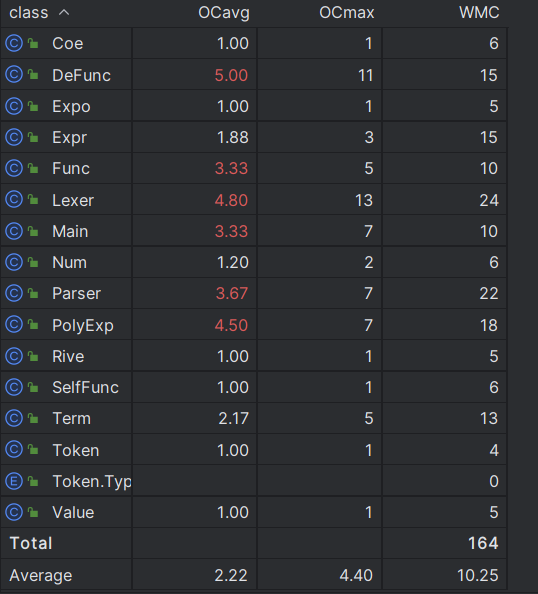
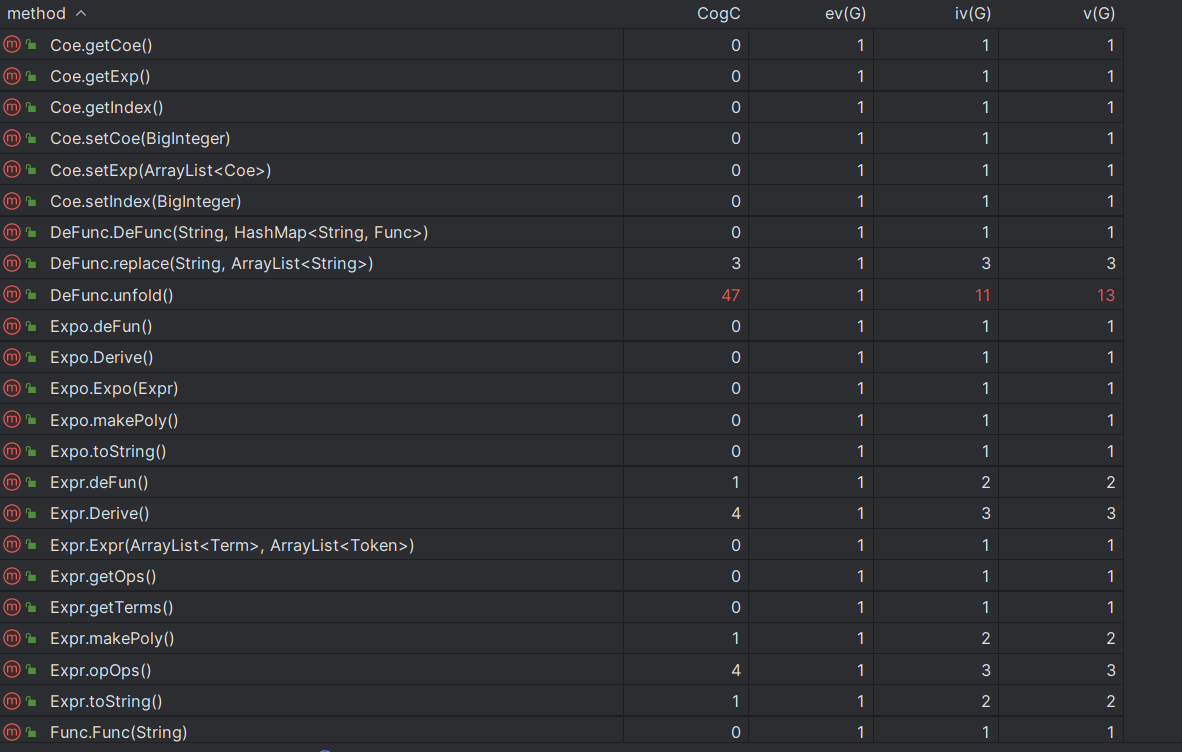
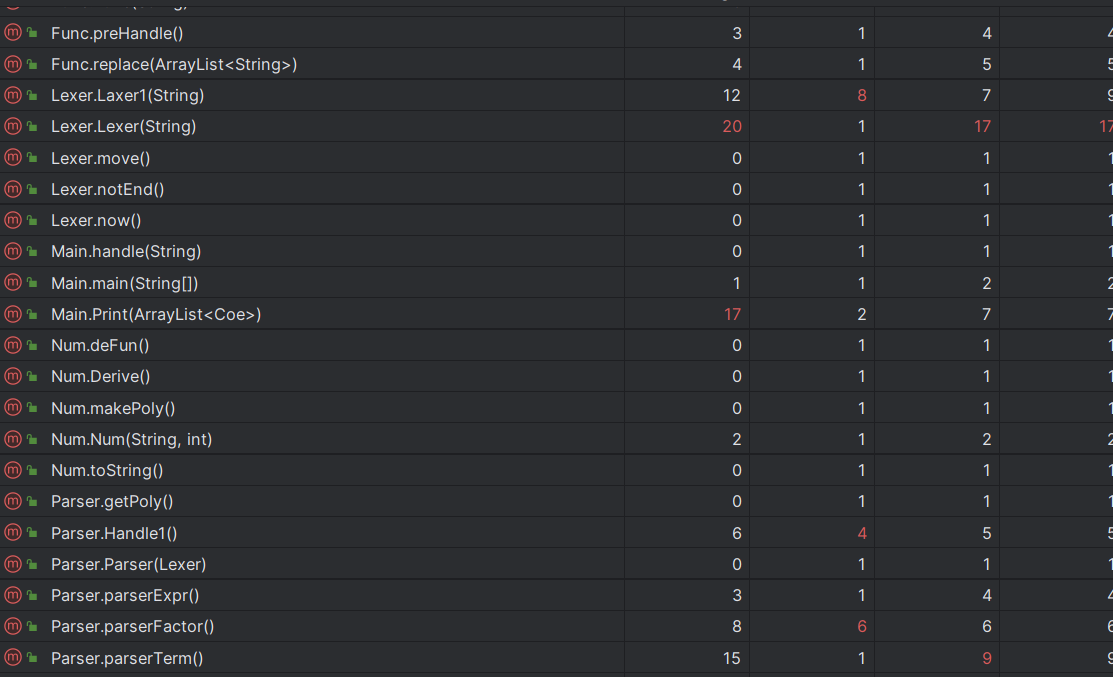
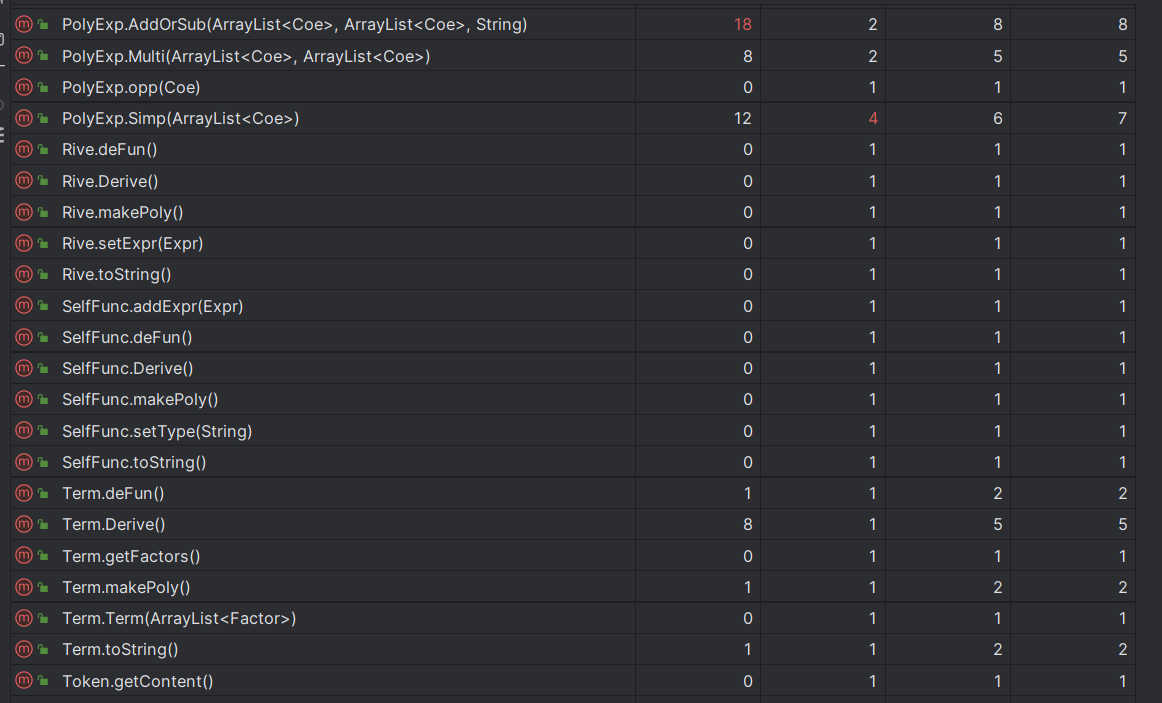
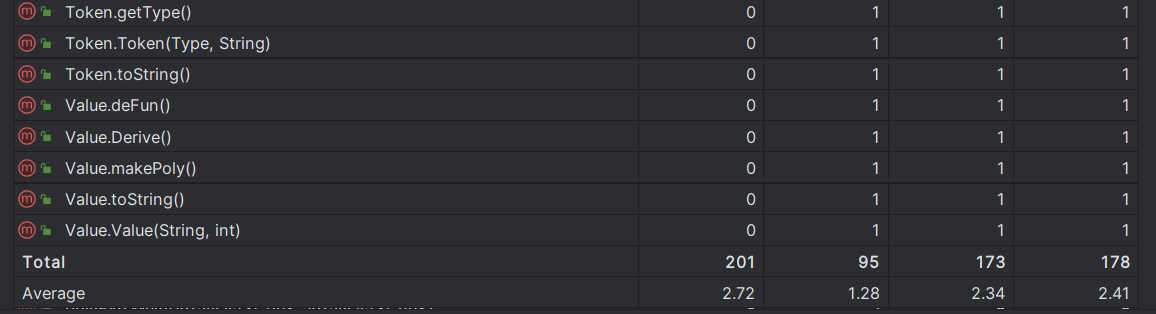
新增的类和方法复杂度都较低,本次开发实际上效果良好。
本次作业的难点主要在于求导的实现。我的实现方法是在Token级别实现一个求导方法,所有顶层求导都返回Expr,底层求导Num、Value、Exp分别返回0、1、Term,然后再生成多项式并运算。
在Token级别实现一个求导方法,所有顶层求导都返回Expr,底层求导Num、Value、Exp分别返回0、1、Term。这样当遇到求导算子时就直接调用求导算子内部的式子的求导的生成多项式算法,这样就直接把一个导数项返回了多项式。
我采用了比较简单的算法,在进行自定义函数的替换时,只需要循环对整个式子调用替换自定义函数三遍,就可以完成全部的替换。我想到的其他方法还有在自定义函数储存时先调用替换自定义函数的方法,从而保障每个自定义函数无嵌套定义。
本次作业仍是时间复杂度的问题,bug均为压力测试被卡爆。
优点:采用的算法易于理解,可扩展性好,同时具有高内聚低耦合的特点。
缺点:算法的时间复杂度较高。
本次互测我主要采用了两种方式,第一种方式是理解对方代码之后手动构造对面思维盲点的bug,第二种方式是采用评测机进行暴力查找。我认为如果锻炼自己的思维能力可以采用第一种方法,如果时间紧张可以采用第二种方法速通互测。
本次作业我的优化实际上是缺失的。我每次的优化都是在下一次作业对上一次作业不兼容的部分进行算法的优化。我的优化本质上是对于算法的替换。我的优化需要一定的测试才能保障正确性,因为我不能保障我写的代码没有误区和盲点,但性能总是提升的。
OO第一单元应该算是一个练手,让我们对迭代开发和测试修改进行一定的熟悉。我的心得体会就是在进行架构和算法时一定要仔细想想本次算法和架构的扩展性,留下一定的扩展空间,我就是因为hw1没有考虑到后续的功能导致算法的不支持导致最后进行大改。我的幂函数替换也是如此。所以我认为在下手之前一定要多想,多想总比多写要轻松一些。
我认为现在unit1的三次作业难度适中,对于接口的考察也比较充分全面,但是对于继承的考察有一定的缺失,后续可以考虑在第三次在作业中考虑加入部分的继承。



