


301
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享总体来说,代码整体的规模,设计和耦合程度较为合理。
类代码行数较为平均,充分考虑了面向对象设计思想
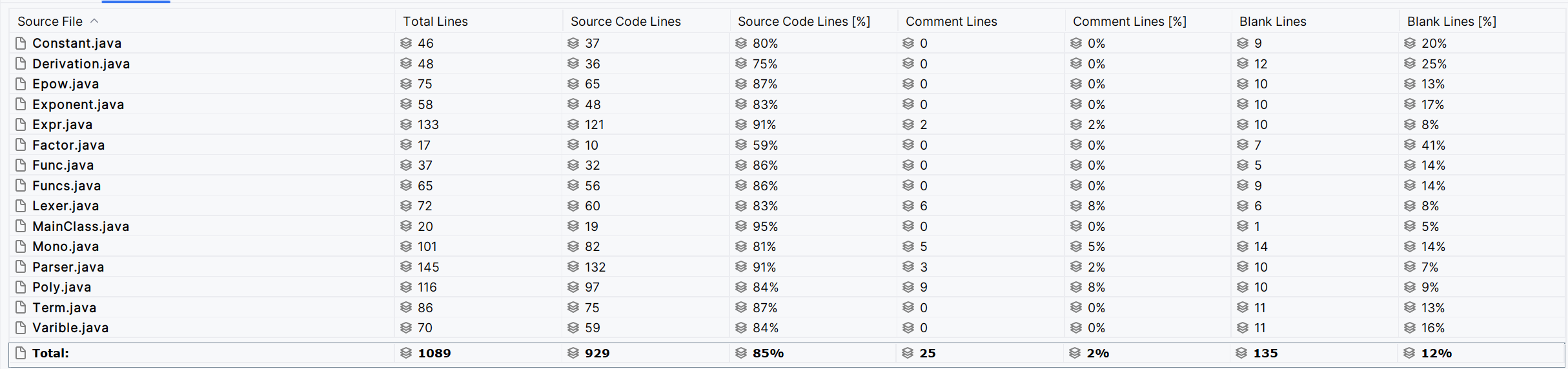
Poly类的耦合度较高,这是因为输出时会递归调用不同类的toPoly方法,使得formulation包中的所有类都包含toPoly方法。
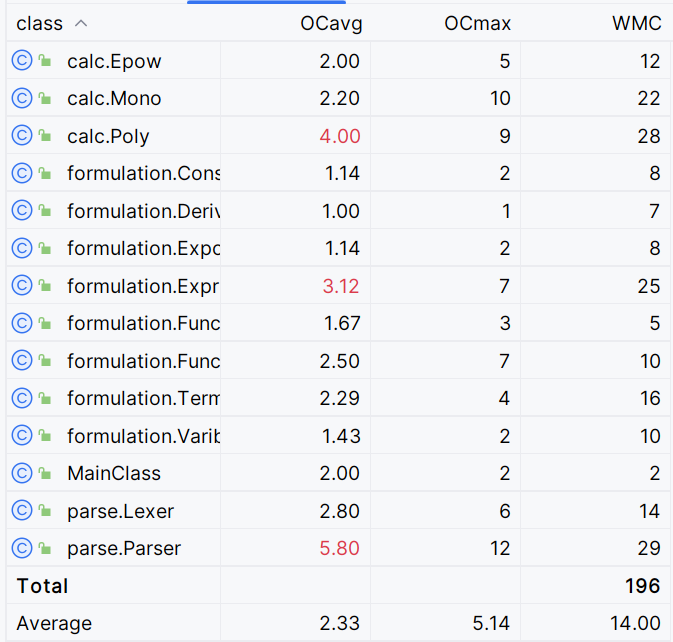
几个度量比较大的函数:
| name | CogC | ev(G) | iv(G) | v(G) |
|---|---|---|---|---|
| Mono.toString | 16 | 1 | 10 | 10 |
| Poly.equals | 16 | 9 | 5 | 5 |
| Funcs.parseFunc | 19 | 5 | 5 | 8 |
| Parser.parseFactor | 14 | 5 | 8 | 8 |
| Parser.parseVarible | 18 | 1 | 8 | 11 |
Mono.toString 为了满足化简,对于系数进行了多次特判导致较为复杂
Poly.equals 使用的相互包含的判断方法
Funcs.parseFunc 中处理嵌套括号,使用了栈的思想,使得复杂度较高
类图:
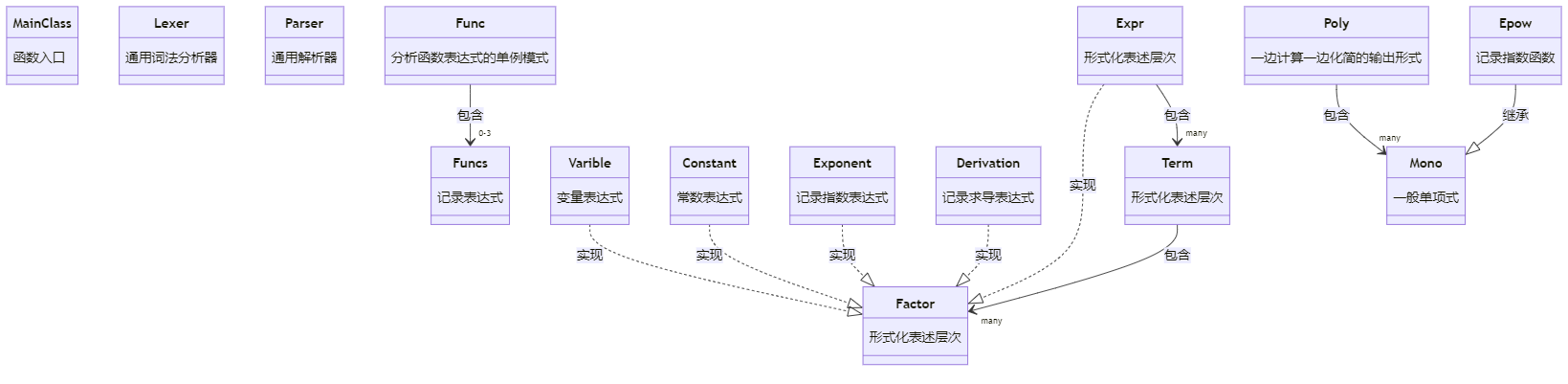
lexer、 parser 设计: 常见设计,将字符串的分析和解析分开
Expr、 Term 、 Factor等: 符合形式化表述,方便parser进行梯度下降解析。加入新因子时只需实现Factor接口便可保证行为正确
Func, Funcs: 自身调用单独的parser, 由于函数不会更改,且使用位置不确定,单例模式无需传入。Func 和parser 有些耦合,这样的设计可以原生支持函数定义中调用已经定义的函数。
Poly, Mono, Epow:Poly为最终的输出形势, 在构建poly时便会进行化简。Poly的乘法实现比较复杂,拆分成多个Mono的乘积较为简洁,故构建Mono层次。Epow的考虑是增加新的函数时,不应该修改Mono类。但是这里应该使用组合,而不能使用继承。这是设计时的考虑失误。
架构设计体验
第一次作业:
利用梯度下降算法解析表达式,存在Expr中。之后递归调用toPoly方法,将整个表达式转化并化简为输出形式。
第二次作业:
加入指数函数,实现Factor接口即可。而指数函数的输出与其他结构不同。故构建Epow类继承Mono。事实证明这是个错误的决定。继承关系使得同类项的判断存在困难,导致嵌套exp的表达式无法化简。当时思维有些不够活跃,正确的做法是通过组合来实现功能的增加,还可以保证不用修改Mono类。
自定义函数,使用单例模式,使用正则表达式初步处理,利用栈处理嵌套括号,提取出string后复用parser和lexer进行解析,直接得到函数的Expr存储形式。在后面的解析调用时,将varible中的变量替换为参数,可直接加入解析式中(需要深克隆)
第三次作业:
作业的架构自然支持函数定义时调用已经定义的函数->因为复用可以解析函数的parser和lexer方法。
求导因子存储简单比较简单。输出化为Poly时先递归调用Drive方法,得到新Expr后再转化为Poly 输出
这三次作业的实现中基本没有修改上一次的代码,而是增加新的代码进行实现,便可以满足迭代的需求。能够增加新类解决的,便不在原始代码中增加。一些方法例如Drive方法,则只能在原有类中增加。
自定一个新的迭代情景
例如,新增cos,sin函数。在解析中,新增sin,cos两个类,实现Factor方法,类中组合Expr即可。但是需要修改lexer和parser,增加switch语句。
calc包中增加Msin和Mcos类,组合Mono,参照Epow的实现方式,实现乘法、同类项识别等。
分析自己程序的bug
三次作业中出现了4次bug。
一是嵌套括号bug。由于使用递归的梯度下降可以原生解决嵌套括号,故在自定义函数解析时也想着使用递归解决。然而自定义函数解析时由于特殊的形式使用正则表达式初步解析,无法递归调用,思维没有转换过来,导致书写出了错误的代码。后改为栈处理解决。
二是关于exp化简时的需要对Poly进行相等判断。采用了互相包含的判断方法。然而实际写代码时只写了一个方向的包含,而我使用容器hashMap的特性影响,不同情况下存储顺序不同,导致equals的判断不同,返回的相等判断也不同。而本地环境正好完美错过,故本地测试并未发现这个问题。
三是常见的index爆int错误
四是自定义函数的字符串替换。第二次作业中只有要解析的表达式中存在自定义函数,故只存在x一个自变量,采用依次替换的方式解决。第三次作业中分析可以原生支持,便没有更改。然而自定义函数中包含x, y,z 三个变量,依次替换时便会出现问题。更改为一次替换全部变量之后解决
发现别人bug
我写了一个bat批处理程序用于把一次输入将所有人的代码都进行一次运行,之后通过瞪眼法发现别人程序执行正确与否。构造样例的方法是“如果我在这个地方出现过问题,那么别人可能也会存在问题”和大海捞针的手动构造样例。
在hw1中我尝试使用Junit单元测试进行测试,然而我发现我使用单元测试时希望能够测得所有的分支。然而许多的bug是我本身的思路就存在问题。如果这个时候只专注于分支,那么并不能保证程序的正确性。我认为Junit的正确打开方式是用于将正确的代码重构后的测试。
由于Epow的错误继承关系,一步错步步错,导致在化简中有心无力。如果修改了这一点,我认为可以在poly中再加入一个化简方法,最后调用这个方法。虽然复杂度会很高,但是不会影响已经完成的部分。



