


301
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享基于度量来分析自己的程序结构
第三次作业的类共有以下x项:
Expr
| 属性 | 方法 | 总代码行数 |
|---|---|---|
| 5 | 12 | 185 |
| 方法平均CogC | ev(G) | iv(G) | v(G) |
|---|---|---|---|
| 2.58 | 1.17 | 2.5 | 2.58 |
Expr用于储存表达式或表达式因子,在表达式因子里实现表达式的存储和部分表达式运算功能,以及表达式最简形式的输出。
Factor
| 属性 | 方法 | 总代码行数 |
|---|---|---|
| 0 | 0 | 2 |
Factor作为接口,统一Expr,Number和Variable。
Function
| 属性 | 方法 | 总代码行数 |
|---|---|---|
| 6 | 8 | 88 |
| 方法平均CogC | ev(G) | iv(G) | v(G) |
|---|---|---|---|
| 2.38 | 1.25 | 2.38 | 2.62 |
Function用于储存函数表达式,对函数表达式进行分析并返回函数实参代入结果。这个过程是封闭于内部的,发生函数调用时只需要传入形参,实现了比较好的封装。
Lexer
| 属性 | 方法 | 总代码行数 |
|---|---|---|
| 2 | 11 | 130 |
方法Lexer(String)使用if-else分析字符串,复杂度都很高。
| 方法平均CogC | ev(G) | iv(G) | v(G) |
|---|---|---|---|
| 2.26 | 1.36 | 3.00 | 3.36 |
将字符串转为Token串,便于程序随指针分析字符串。
Main
| 属性 | 方法 | 总代码行数 |
|---|---|---|
| 2 | 3 | 34 |
| 方法平均CogC | ev(G) | iv(G) | v(G) |
|---|---|---|---|
| 0.33 | 1.00 | 1.33 | 1.33 |
程序入口,输入字符串,输出最简表达式。
Math
| 属性 | 方法 | 总代码行数 |
|---|---|---|
| 0 | 5 | 89 |
| 方法平均CogC | ev(G) | iv(G) | v(G) |
|---|---|---|---|
| 4.40 | 1.60 | 3.80 | 3.80 |
本意是将运算操作从类中剥离,实现运算操作的封装和统一,但有部分运算操作只需要在类中完成,调用内部数据也不存在风险,所以还是有部分运算函数分散在Expr、Term和Variable类中,造成了代码逻辑的混乱。此外,将表达式函数中的运算函数剥离到Math类时,出现了修改对象数据的Bug,属于设计上的缺憾。 内部存在大量循环嵌套和数组深拷贝,复杂度高。
Number
| 属性 | 方法 | 总代码行数 |
|---|---|---|
| 2 | 6 | 40 |
| 方法平均CogC | ev(G) | iv(G) | v(G) |
|---|---|---|---|
| 0.67 | 1.00 | 1.33 | 1.33 |
在第一次作业中用于储存常数,但由于Variable充当最简因子,所以在设计逻辑上覆盖了Number意义,正确做法应该是将Number与Variable、Exp()等并列,并另设最简因子类。
Parser
| 属性 | 方法 | 总代码行数 |
|---|---|---|
| 3 | 15 | 256 |
extratArgument(int)和parserFactor()复杂度高,这是由于在extratArgument(int)中使用了字符串处理的方法分割形参,代码行数大,且内部有许多if-else判断和字符串拼接操作,以及不同情况下分类讨论带来的代码复用,是整个项目中最晦涩的函数。 parserFactor()中讨论了多种情况,且未抽象出函数来简化对Factor的分析过程,复杂度高,但并不难理解。
| 方法平均CogC | ev(G) | iv(G) | v(G) |
|---|---|---|---|
| 4.33 | 1.60 | 4.20 | 4.53 |
整个项目的核心类,用于解析字符串。
Pre
| 属性 | 方法 | 总代码行数 |
|---|---|---|
| 1 | 6 | 65 |
| 方法平均CogC | ev(G) | iv(G) | v(G) |
|---|---|---|---|
| 2.67 | 1.00 | 2.00 | 2.33 |
Pre用于预处理字符串,使用正则表达式去除空格,去除多余正负号并去除0指数。
Term
| 属性 | 方法 | 总代码行数 |
|---|---|---|
| 5 | 8 | 93 |
由于循环和深拷贝,cal()复杂度高。
| 方法平均CogC | ev(G) | iv(G) | v(G) |
|---|---|---|---|
| 4.88 | 1.00 | 3.00 | 3.12 |
Term类用于储存项,内部储存所有的Factors,并返回最简形式的最简因子给Expr。
Token
| 属性 | 方法 | 总代码行数 |
|---|---|---|
| 3 | 5 | 31 |
| 方法平均CogC | ev(G) | iv(G) | v(G) |
|---|---|---|---|
| 0.00 | 1.00 | 1.00 | 1.00 |
用于在Lexer中分析字符串。
Variable
| 属性 | 方法 | 总代码行数 |
|---|---|---|
| 5 | 18 | 181 |
| 方法平均CogC | ev(G) | iv(G) | v(G) |
|---|---|---|---|
| 2.44 | 1.56 | 1.94 | 2.33 |
Variable类同时作为变量项和最简因子,这是第一次作业中设计缺憾的遗留。实际上充当了指数函数因子,变量因子等内容。这导致其中包含大量构造函数,以及在解析过程和计算过程中的调用混杂不清,产生理解上的障碍,同时每一次迭代都要修改大量类似内容。本应在第二次作业中修改,但最终保留到了第三次作业中。
类图如下: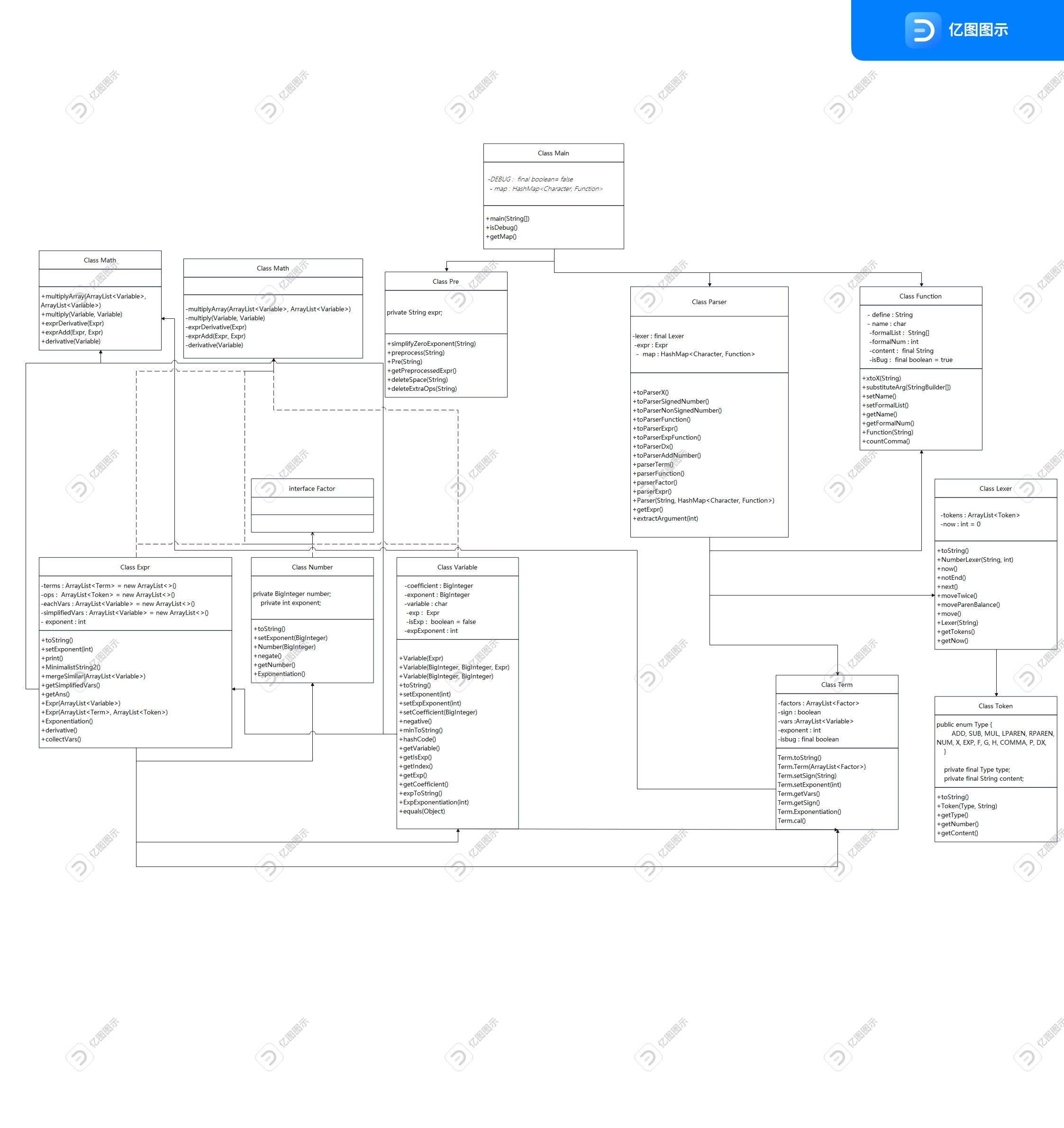
评价:
优点:使用递归结构,对因子建类分析;设置了分析器类,Math类,将方法集中起来易于管理。
缺点:1.没有对每一种因子都进行建类处理,而是将Variable当做最简因子。
架构设计体验
结合三次作业的迭代介绍自己的架构如何逐步成型
作业成型过程:
第一次作业完成了递归结构,并建立了Expr,Number和Variable类共同实现Factor,但由于第一次作业中变量Variable类比较简单,所以将Number的内容一并合入Variable中实现,使用Variable来作为最简因子。这一点也影响了后面的代码扩展。同时第一次作业中选择在预处理时使用字符串处理的方法展开指数,这一点在后面的作业中难以适用。
第二次作业中修改了指数的实现方式,将符号^作为一种运算符,在Lexer中读取并在Parser中进行了解析,放弃了第一次作业中通过字符串运算进行展开。
第三次作业相对简单,没有架构上的调整,只需要新增求导函数,然后在读到求导符号时令Expr进行运算即可。最大的困难是忘记求导规则在设计求导函数时写出大量Bug。
假设:需要新增cos,sin类,形如sin(<表达式因子>),cos(<表达式因子>)
扩展性:需要修改Variable类,将sin与cos加入其中,然后修改构造函数,避免在读取数据时没有对sin与cos赋值。这一点是使用Variable的弊端,因为最简因子只需要在计算时使用,与读取分析是分开的,但使用Variable作为最简因子就会导致每次最简因子的改变都会需要大规模重新修改代码。
分析自己程序的bug
分析未通过的公测用例和被互测发现的bug:特征、问题所在的类和方法,为什么会出现这样的问题?你能否通过更好的设计避免这样的问题?
第一次作业Bug:由于采用了字符串运算展开指数运算符,导致考虑上的不周全带来了代码设计的缺憾,即遇到0指数时带来的字符串长度缩短会导致记录处理指数的指针跳过未处理字段,令指数运算符保留到主函数处理时,产生了bug。不应该图省事采取字符串展开。
第二次作业Bug:忘记字符的指数可能存在超过int范围的情况,所以忘记修改指数的数据类型,在遇到强测数据点时爆int产生错误。
第二次作业调试发现Bug:在进行表达式乘法和Variable乘法时,没有考虑返回值是否会修改原对象的问题,导致运算中原表达式数值也因为乘法而多次倍增,产生运算错误。在跟踪后发现原表达式值改变,修改为更安全的返回方法后修复。不清楚Java函数的内部实现方式导致了错误。
对比分析出现了bug的方法和未出现bug的方法在代码行和圈复杂度上的差异,并思考可以通过怎样的方式来降低方法的复杂度
方法对比:出现Bug的代码通常出现在需要依靠字符串运算的位置。代码行数大,复杂度高,多采用if-else结构,从而容易出现未曾考虑到的边界情况,导致Bug。而未出现Bug的方法通常是通过考虑成熟的数据结构来实现,比如使用递归来处理字符串,使用HashMap来合并表达式,不易出现考虑不周的现象。
方法对比2:出现Bug的代码通常依赖于某些隐含条件。如在解析函数表达式时默认了没有函数定义嵌套,导致隐含条件发生变化时未注意到,原代码在现有条件时不再有效。而依靠基础定义,考虑普遍情况写出的代码通常不容易因为条件变化而出现Bug。
分析自己发现别人程序bug所采用的策略
列出自己所采取的测试策略及有效性,并特别指出是否结合被测程序的代码设计结构来设计测试用例
在测试时,主要依赖于自己写程序时发现的可能存在的Bug而进行测试,这是基于同学出现的问题可能是普遍的。没有结合每个人的具体程序进行考虑。
分析自己进行的优化 - 你做了什么优化,怎么做到的? - 你的优化能否保证你代码的简洁性与正确性?如果能,为什么。如果不能,思考可能的解决方案
在优化方面,主要是对于0、1、-1出现的情况进行优化。在Term中完成优化,而在Expr中实现Term返回字符串的连接和输出。而Term中将系数为0、1的变量,指数为0、1的变量和Exp(0)进行简化,全部依靠if-else判断。缺点是代码较长,代码复用率较高,但优点是能够考虑全部情况,并针对性设计输出,容易发现Bug,容易修改,容易阅读。
心得体会
我认为这个单元的学习让我进一步深入体会了递归思维,更清楚地理解了何为每层只解决当前事项,对于遇到类似情形下使用递归结构更有信心。此外,这一单元的学习很好地让我了解了Java语言的基本语法,因为每单元新增部分内容,可以循序渐进地学习部分新知识。最后,这一单元的迭代开发让我认识到设计的重要性,好的结构可以省下50%以上的精力,所以重要的是应该先将结构思考清楚再下笔。设计的结构应当足够完备,留出迭代需要的位置,避免在新增需求后需要将大量函数重写,而是应当保证通过泛用的构造来实现。
未来方向
我认为目前第三次作业内容相对简单,新增内容少,可以新增sin\cos增加单元开发内容。



