


301
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享
OO第一单元的任务是表达式展开,通过三次迭代的开发,去满足逐渐增加的需求,在每一次的开发中我们除了要满足当前的需求,同时还要考虑程序是否做到了高内聚、低耦合,方便我们进行下一次的拓展。
代码规模

代码复杂度
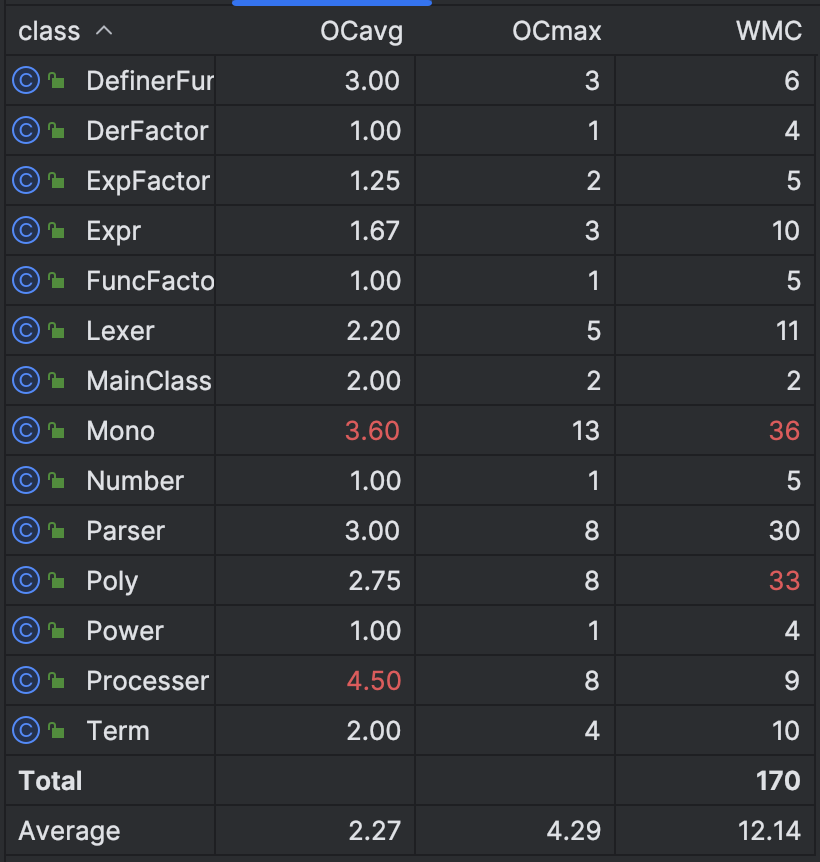
指标解释
OCavg : 每个类中所有非抽象方法的平均圈复杂度(继承的方法不计算在内)。
OCmax : 每个类中非抽象方法的最大圈复杂度(继承的方法不计算在内)。
WMC : 每个类中方法的总圈复杂度.
复杂度原因分析
Mono的复杂度很高,是因为它承担了很多的任务,比如toString(),derivation()(求导),其中toString()的任务尤为的复杂,因为它需要考虑化简的问题如:exp内的括号消不消去,某些情况下有些地方是不是可以换一个表述形式,该不该提公因子……
这些方法里面包含了大量的条件判断语句,所以复杂度会很高
Poly的复杂度的问题是,它作为Mono的上一层,需要配合Mono的toString()和derivation(),除此之外Poly还负责了表达式的加减乘
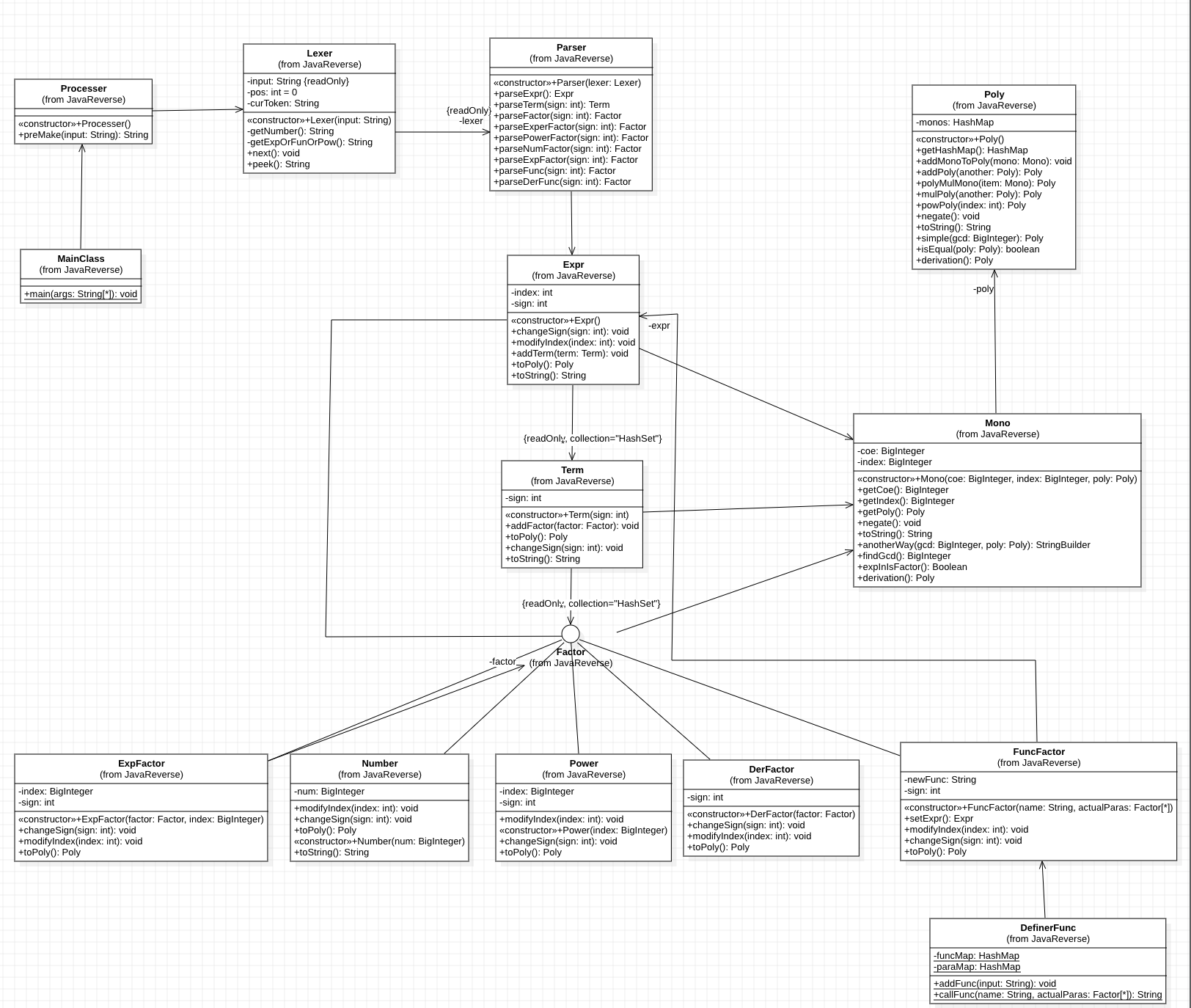
从图中我们可以看出,各部分功能清楚,关系之间很简单,从输入到输出有明显的路径,方便我们在其中进行拓展
Factor作为一个统一的接口,很好的满足了程序中优先factor需要储存其他的factor的这一需求,不需要我们再去重复的定义一个
本次作业我们是对一个包含加、减、乘、乘方以及括号(其中括号的深度至多为 1 层)的单变量表达式,输出恒等变形展开所有括号后的表达式。
对于这样的任务,我们可以把它作如下的分解:
建立预处理类Processor:题设中给的字符串是含有空格和连续加减号的,我们首先要做的是去掉空格和合并连续加减号,对于空格我们可以直接采用java中的replaceAll()的函数来解决,而对于合并连续的加减号,我采用的方法是遍历这个字符串,对于非加减号的部分,直接添加进新字符串中,遇到加减号,用一个值记录正负号,向后遍历直至遇到非加减号,根据正负号向新字符串中添加加减号,并添加非加减号的字符
建立Exper,Term,Factor,Number,Power存储类来存储数据:其中Factor为接口,由Exper,Number,Power来实现它。在这些类中我们按照题意,Exper中存储着Term,Term中存储着Factor,此外我们还在这些类中设置了toPoly()函数,用来生成符合要求的多项式。
建立解析类Praser,lexer:我们选择将解析这个过程单独建类,而不是在存储类中作为函数,是为了将数据结构和行为结构分开来。其中Lexer类作为词法解析,用来提取字符串中一个个token,Praser则是解析类,通过praseExper,praseTerm,praseFactor三个函数的递归调用来实现字符串的解析
Praser展式
public class Parser {
public Parser(Lexer lexer)
public Expr parseExpr()
public Term parseTerm()
public Factor parseFactor(int sign) { //解析表达式因子
if (lexer.peek().equals("(")) {
return parseExperFactor(sign);
} else if (lexer.peek().equals("+") || lexer.peek().equals("-")) {
Factor newOne;
if (lexer.peek().equals("+")) {…} else {
lexer.next();
newOne = parseFactor(-1);
}
newOne.changeSign(sign);
return newOne;
} else if (lexer.peek().equals("x")) { //解析power因子
return parsePowerFactor(sign);
} else if (lexer.peek().equals("exp")) { //解析ExpFactor
return parseExpFactor(sign);
} else if (lexer.peek().equals("f") ||
lexer.peek().equals("g") || lexer.peek().equals("h")) {
return parseFunc(sign);
} else if (lexer.peek().equals("dx")) {
return parseDerFunc(sign);
} else {
return parseNumFactor(sign);
}
}
public Factor parseExperFactor(int sign)
public Factor parsePowerFactor(int sign)
public Factor parseNumFactor(int sign)
public Factor parseExpFactor(int sign)
}
建立多项式类Poly,Mono:如果我们直接由存储类来输出最终的字符串这是一个有难度的事,因为Exper因子需要被展开和合并Term需要做乘法,很明显我们需要新的结构来存储这些东西,其中Poly类存储着Mono类, Poly类中内置着多项式的加减乘除运算,存储类中都有toPoly()来实现向Poly类的转换,很明显toPoly()也是递归调用的,可以把toPoly()看成逆解析过程
poly展示
public class Poly {
private HashMap<String, Mono> monos;
public Poly() {
this.monos = new HashMap<>();
}
public HashMap<String, Mono> getHashMap() {
return this.monos;
}
public void addMonoToPoly(Mono mono) {
this.monos.put(mono.toString(), mono);
}
public Poly addPoly(Poly another) {…}
public Poly polyMulMono(Mono item) {…}
public Poly mulPoly(Poly another) {…}
public Poly powPoly(int index) {…}
public String toString() {…}
}
第二次作业比之前增加了自定义函数和指数函数,自定义函数通过先建立模版类,然后向其传递实参,来替换形参进行解析
而exp的解析就比较复杂了,我们需要把括号内的内容作为一个poly存在exp,这就涉及到一个问题是,如果我们要比较俩个exp的大小,那么我们就需要比较poly,比较poly有三种方案
一是我们用arraylist存mono,双重for循环,比较mono,但这设计到一个问题是,mono里面也是含有poly,也就是我们需要递归的去比较,这样感觉十分复杂
二是我们如果用hashmap存mono的话,我们可以直接去比较hashmap是否相等,但这个就涉及了我们需要重写hashmap的equal的方法
三是我们在将mono加入到poly时就调用它的tostring方法,来作为mono的键值,之后,我们poly的tostring,我们只需要把键值按照字典序加起来,就可以得到poly的最简string,我们只需要比较两个poly的string即可
poly的展示
public class Poly {
private HashMap<String, Mono> monos;
public Poly() {
this.monos = new HashMap<>();
}
public HashMap<String, Mono> getHashMap() {
return this.monos;
}
public void addMonoToPoly(Mono mono) {
this.monos.put(mono.toString(), mono);
}
public boolean isEqual(Poly poly) {
String thisOne = this.toString();
String anoOne = poly.toString();
if (thisOne.equals(anoOne)) {
return true;
} else {
return false;
}
}
public String toString() {…}
}
第三次作业的任务是求导,初看时还感觉挺复杂的,但是仔细想一想,我们把求导的任务交给mono来作的话事情就会变得简单多了,因为每一个因子最后都会转化成一个mono,所以实际上我们只用写一次的求导,而不需要对每一个因子都写它的求导方法
求导展示
public class Poly {
public Poly derivation() {
Poly newOne = new Poly();
for (Mono one : this.getHashMap().values()) {
Poly mmp = one.derivation();
newOne = newOne.addPoly(mmp);
}
return newOne;
}
}
public class Mono {
Poly newOne = new Poly();
BigInteger polyCoe = this.coe;
BigInteger polyIndex = this.index;
if (!poly.toString().equals("0")) {…}
BigInteger thisCoe = this.coe.multiply(this.index);
BigInteger thisIndex = this.index.add(BigInteger.ONE.negate());
if (!this.index.equals(BigInteger.ZERO)) {
Mono coeMono = new Mono(thisCoe, thisIndex, this.poly);
Poly coePoly = new Poly();
coePoly.addMonoToPoly(coeMono);
newOne = newOne.addPoly(coePoly);
} else {
Mono ccMono = new Mono(thisCoe, BigInteger.ZERO, this.poly);
Poly ccPoly = new Poly();
ccPoly.addMonoToPoly(ccMono);
newOne = newOne.addPoly(ccPoly);
}
return newOne;
}
本次实验我未经历重构,如果考虑拓展的话,我认为有如下两点
首先是像上一届学长一样,添加三角函数,我只需要添加三角函数因子,在mono中再添几个变量来存三角函数内的内容,三角函数的计算我只需要修改poly中的加减乘方法,而两个poly是否相等比较,依然可以沿用之前的方法,我们可以直接打印poly的string来比较
其次是函数定义中可以定义导数,这里我修改的地方就比较多了,因为我需要对函数模版求偏导,这意味着我需要解析函数模版,而不是仅用简单的字符串替换来处理
本单元,我于第二单元被强测测出了一个bug,互测测出一个bug,两个bug十分神奇,强测的bug评测机的结果与本地结果不一样,互测的bug是调试的结果与运行的结果不同,我幸运的修复了这两个bug,虽然并不清楚背后的原因,我的bug修复十分简单,在我原来的程序中,如果我的两个mono运算后如果为0,那么我就不将其加入到作为结果的poly中,我仅仅将这个条件注释掉,就成功修复了bug,我猜测背后的原因是,我原本的行为可能导致hashmap为空,,从而触发什么异常
测试:本单元我的测试分为两个部分
单元测试:我用单元测试是来测我的优化功能的,本单元我们需要对输出的结果进行优化,而我的负责输出字符串和优化的模块恰好都是mono模块,所以我就对mono写了单元测试,来看我的程序是否会按照我所预料的那样优化
普通的测试,我于第一次作业时按照学长的博客建了自己的评测机,后两次用的是同学的评测机,我自己搭建评测机的思路是,用python内置的解析字符串的函数来解析生成的表达式,和我程序化简的表达式,来看看他们是否相同
对于互测,我的方法就是用评测机不断的去跑别人的程序,看看是否会问题,有问题就去化简一下评测机的数据来提交
指数为0是输出1
系数为+-1时,不输出系数
尽量让第一项不为负
计算指数函数内的最大公因子,并将其提出,与不化简的长度作对比,再决定是否输出
每一次优化我都会做好单元测试,保证优化的正确性
我觉得本次任务,让我明白了,我面对一个任务时,首先要想好这个任务的需求,根据需求设计合适的数据结构与方法结构,想好操作的对象进行编程。
同时在这里也感谢,往届学长们写的博客,让我面对这个任务时,不至于茫然无措,能对我有个思路上的引导
希望互测的cost再扩大些,也希望强测的结果能想我展示一个最简的优化1形式



