


301
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享目录
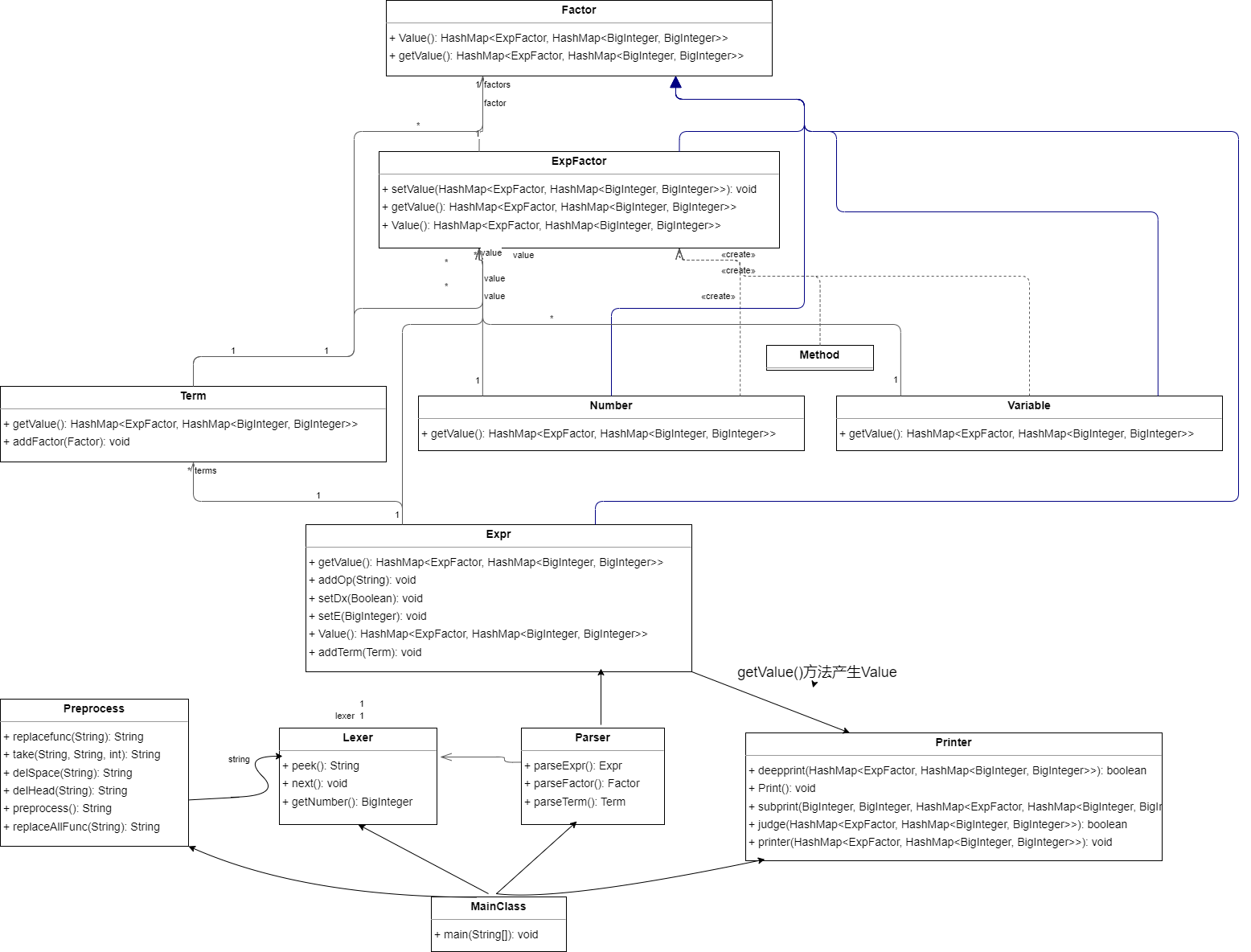
代码中构造了Main, Preprocess(预处理),Lexer(读取),Parser(生成表达式的层次结构),Printer(专营打印的类)几个在表达式解析过程中分别负责不同作用的类,又构造了Factor(父类),Expr,Term,Number,Variable,ExpFactor 几个不同的数据类。最后是表达式中加法,乘法,乘方等方法所在的Method类,用于存储静态的方法。
首先在Main中调用Preprocess类对输入字符串进行处理,调用preprocess()方法并在其中调用delSpace()删除空格,delHead()删除函数头,replaceAllFunc()和replaceFunc()方法替换函数和最终表达式中存在的函数,这里采用了字符串替换,方法是先将f(x,y,z)中的x,y,z分别换成不同的字母以免与exp冲突,然后将函数的形参替换成实参并得到一个新的字符串扩上括号之后直接替换到表达式中,这种方法看似比较简单实际上很容易出现bug。Lexer中仅仅涉及到对于已经处理好的字符串的读取工作不必多言。Parser是根据Lexer的读取结果构造一个层次化的整体表达式结构。之后对parser产生的Expr调用getValue()方法,调用主表达式的getValue()方法进而按照层次调用其它子类的getValue()方法。其返回值为一个嵌套的HashMap,类型是HashMap<ExpFactor,HashMap<BigInteger, BigInteger>>。其中的ExpFactor表示这一项所乘的指数因子,以这种方式将整个表达式解析为exp(expr)*n(系数)*x^k(指数)的形式并根据此来对同类项进行合并化简。
在这里ExpFactor作为HashMap的key,存在一些难以解决的问题,比如在合并时,同样是exp(x)的两个ExpFactor不会作为同一个key存在,因为这是两个ExpFactor,其仅仅是具有相同的Value,因此需要使用Method类中的equal()方法进行判断,判断其Value的HashMap是否表示同一个表达式,然而这个HashMap仍然以ExpFactor为key,这时又需要递归调用equal()方法进行判断,直到遇到ExpFactor的Value为空递归停止。这使得这个equal()方法极为复杂,存在很大的不合理性(后续有数据分析)。而且在进行判断之前,有必要使用Method中的clean()方法对进入的两个表达式中的0项进行清理,防止其干扰判断结果。对于HashMap<ExpFactor,HashMap<BigInteger, BigInteger>>之间的加减法,调用Method.merge()方法对于同类项进行合并,乘法则需要生成一个新的ExpFactor作为key对新的exp(expr)中的expr进行表示,这无法通过parser生成,只能引入setValue()方法对新ExpFactor的value进行强行规定。求导部分调用Method.dx()方法递归得到结果。由此程序的主体部分已经解决。
最后调用Printer中的方法对已经处理好的表达式进行输出。Printer中为了更大的可操作性先使用了StringBuilder构建输出表达式(主要是容易对前文进行删除更改)。首先对总体HashMap<ExpFactor,HashMap<BigInteger, BigInteger>> Value调用printer方法,因为存在大量的代码复用,因此构建了subprint方法(负责打印多项式部分)和deepPrint方法(判断是否需要更深层的打印,如果需要则继续调用printer方法)。最后调用Print方法将整个stringBuilder输出。
观察了互测其他同学的代码,大多采用toString()方法将表达式分化瓦解之后表示为相同的字符串然后根据字符串相同的方式合并同类项,很少采用嵌套HashMap方式对整个表达式进行完整的存储然后再整个转化为字符串输出。我认为我的方式有优势也有劣势。方法的优势体现在其思路上清晰,整体逻辑十分简单,仅仅是先构建表达式层次结构,然后调用getValue()方法生成完整的表示value的HashMap,然后对其进行整体输出。这样清晰的结构无疑是很有利于扩展的,实际上在第三次作业扩展的求导部分仅仅加入了一个很简短的求导函数,并在expr中加入了一个求导标记。劣势体现在各个步骤之间看似互相独立,这样划分没有问题,实则存在很强的耦合。还有就是因为存在嵌套的HashMap,方法的实现时常非常复杂。
对于总的面向对象程度的分析,采用了idea中的Metrics插件对Chidamber和Kemerer指标进行了计算。
WMC、CBO、RFC、LCOM、DIT、NOC - “Chidamber 和 Kemerer 指标”
类别识别 - WMC、DIT、NOC
类的语义 - WMC、RFC、LCOM
类之间的关系 - RFC、CBO
CBO - 对象之间的耦合
CBO 应该尽可能低,原因有三:
增加的耦合增加了类间的依赖性,使代码的模块化程度降低,不太适合重用。换句话说,如果你想打包代码以供重用,你最终可能不得不包含对核心功能来说并不是真正基础的代码。 更多的耦合意味着代码变得更加难以维护,因为对一个区域的代码进行更改会冒着更高的风险影响另一个(链接)区域中的代码。 类之间的链接越多,代码就越复杂,测试的难度就越大
DIT - 继承树的深度
继承树的深度 (DIT) 是特定类从中继承的类的计数。C&K 根据继承的深度提出了以下后果:
一个类在层次结构中的位置越深,它可能继承的方法数量就越多,从而使得预测其行为变得更加复杂 更深的树构成更大的设计复杂性,因为涉及更多的方法和类 特定类在层次结构中的位置越深,继承方法的潜在重用就越大
LCOM - 缺乏方法的凝聚力
较低的 LCOM 值表明该类更具凝聚力,并且被视为更好。
NOC - 子类数
子类的数量越多,重用的程度就越高,因为继承是重用的一种形式。 子类的数量越多,父类不当抽象的可能性就越大。如果一个类有大量子类,则可能是滥用子类的情况。 孩子的数量可以了解一个班级对设计的潜在影响。如果一个类有大量子项,则可能需要对该类中的方法进行更多测试。
RFC - 类的响应
如果可以调用大量方法来响应消息,则类的测试和调试将变得更加复杂
WMC - 类总圈复杂度
方法的数量和所涉及的方法的复杂性是开发和维护该类需要多少时间和精力的预测指标 类中的方法数量越多,对子类的潜在影响就越大,因为子类将继承类中定义的所有方法 具有大量方法的类可能更特定于应用程序,从而限制了重用的可能性。
概述
那么,C&K 指标给我们留下了什么?总而言之——
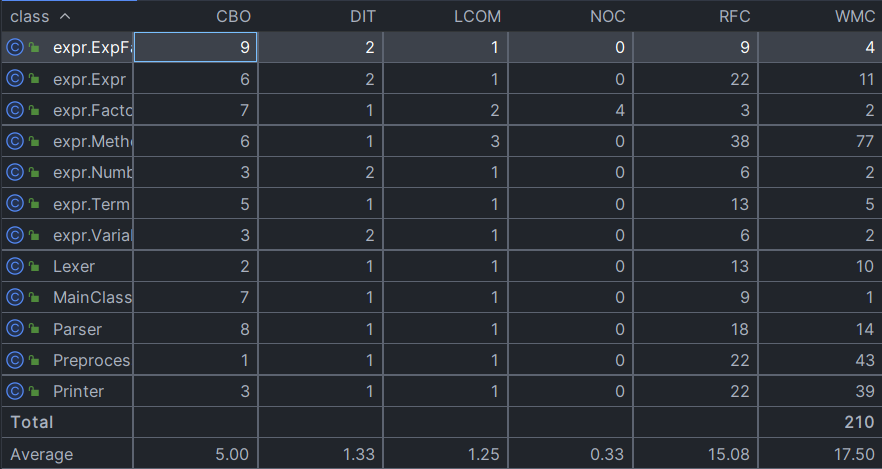
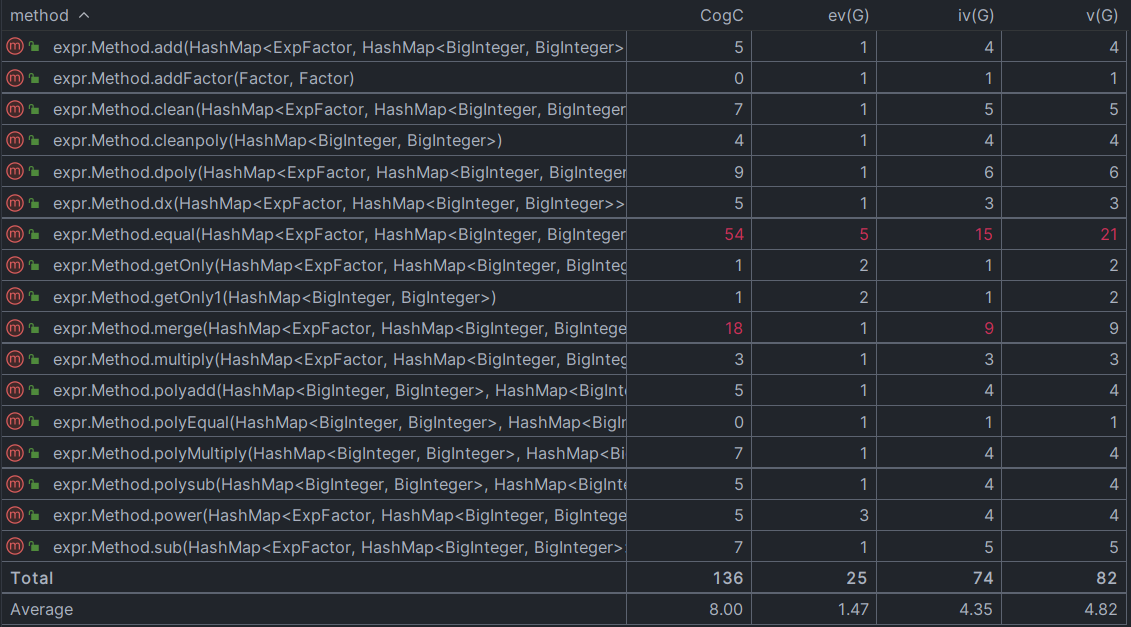
上图为对程序中所有的类的C & K指标计算结果, 根据上述对架构的描述,ExpFactor作为一个因子类,其设计无疑是失败的,它没有达到想要的目标,也就是做一个真正的因子,而是一定程度上充当了用于存放Value的容器,也因其是key而被大量的new出来,浪费了大量的时间空间。它与其他类的耦合度非常高(CBO高),是一个逾越其职权的类。其实本可以用Factor来代替。Method方法的RFC非常高,因为其中的方法实现方式非常丑陋,尤其是在equal方法的递归使用之中,无数次调用clean方法,滥用次数简直不可想象。equal方法存在的问题最大。clean的使用并不应该在equal之中,且HashMap<ExpFactor,HashMap<BigInteger, BigInteger>>的表达方式可能导致了equal极度复杂,但目前没有想到更好的解决方式。
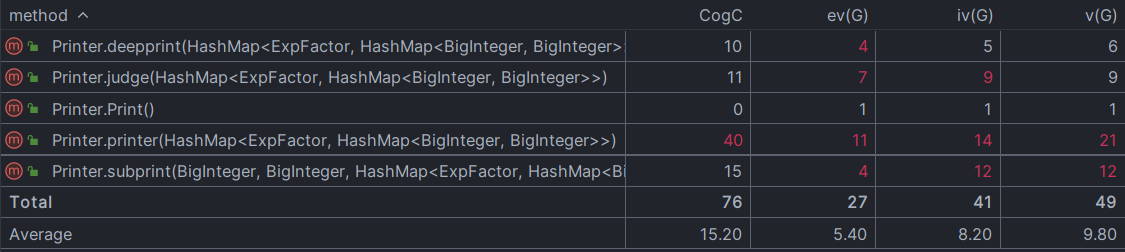
负责预处理和函数替换的preprocess类,lexer类和最后的printer类之间的耦合度很小,很好的实现了各司其职的设计初衷。preprocess类、Method类、printer类的内部逻辑均比较复杂,对其中方法的复杂度分析如下
采用了complexity metrics分析,
cogC(Cyclomatic Complexity):圈复杂度,表示程序中的独立路径数目。
EV(Essential Complexity):本质复杂度,表示程序中必须要有的控制流程数目。如果减少程序中任何一条路径,则程序将不完整。
IV(Inherent Complexity):内在复杂度,程序本质上的复杂度。表示程序在没有框架、库、编译器等支持时的复杂度。
V(Volume):程序体积,表示程序中的独立语句数目。
圈复杂度的大小对应的代码状况如图所示:
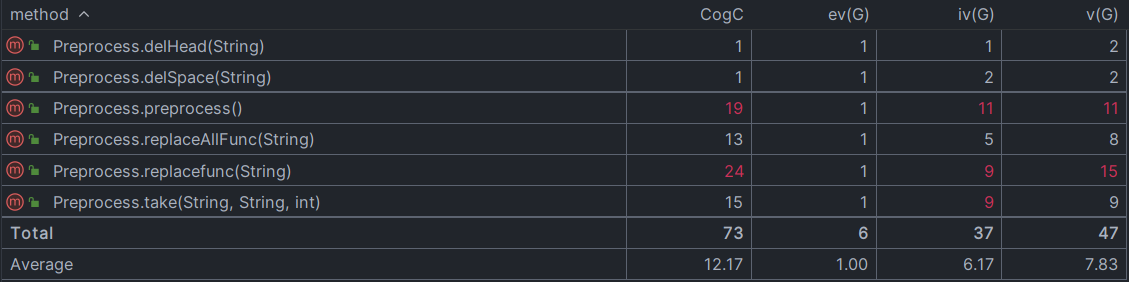
Preprocess的方法分析如下,其中preprocess方法和replacefunc方法都属于非常复杂的方法,可测性低且维护成本高,本人作业两次bug均出现在preprocess方法里。
Method类的方法中equal方法的圈复杂度达到了惊人的54(大于30即为不可读)。还有很大的完善空间。
printer方法也被认为是完全不可读的,这可能因为我想要把整个输出过程集中在一个类里。
第一次作业比较简单, 基本采用了train的架构,
类:expr, term, factor, number, variable, lexer, parser ,mainclass,method.
因子类具有getValue()方法。
第二次作业对架构有大的改动
加入了ExpFactor类用于表达exp(expr)类的因子。
加入了preprocess类用于预处理和函数替换。
Method类中的加减乘等方法有大的改变,加入了equal判断,clean清理,merge合并
第三次作业整体架构保持不变。
Method中加入了dx方法和dpoly方法。
一共出现了4个bug,其中第一次作业1个,在互测中发现;第二次作业2个,强测中发现(根本没有进互测);第三次作业1个,强测前自行发现。
第一次作业的bug出现在不与x相乘的正整数之前没有‘+’号,导致了x^16+70会被表达为x^1670,而在自己测试和强测时,因为会选择一个正项并将其放到最前方输出并且不带+号,这导致了这个弱智级别的bug迟迟没有被发现。
第二次作业的bug出现一个出现在preprocess方法之中,因为空白项没有第一时间去除,导致对存在空白项的函数的解析完全错误,强测中痛失6个数据点。还有就是负数*x^i被认为是因子了,exp(负数*x^i)少了一层括号。
第三次作业的bug出现在字符串替换方式存在问题,将replaceAllFunc方法用在后续读入的函数之中直接替换掉其中已经定义好的函数,但是问题在于将所有的函数中的形参都统一为三个字母r,s,t,而被替换函数和被调用函数都统一后就相当于没做任何改变,还是出现替换次序的问题,而这一开始没有被考虑到。导致对于多变量多函数的输入,出现函数定义中对已定义函数进行调用时,结果往往是错的。
采用了半自动的测试。python脚本将手动构造的有清晰目的的数据输入到程序之中并将输出合并方便观察。
手动数据不断积累,最后数据规模比较可观,并且对各个细节有精准的测试,有不错的测试效果。
采用了几种优化方式。



